#algoritmo
Text
El algoritmo de [tumblr] conspira para ponerme horny siempre jsjsjjs.
— G'
#algoritmo#[tumblr]#noches#conspiraciones#textos cortos#frases cortas#notas cortas#citas cortas#cuando fingí quererte
193 notes
·
View notes
Text
Io vorrei sapere se sono l'unico ad avere certi problemi con Tumblr.
Mi sembra che da qualche tempo l'algoritmo di visibilità sia folle.
Mi spiego meglio.
Vado sulla dashboard e vedo un post.
Due ore dopo vado sulla dashboard e vedo quel post.
Due giorni dopo vado sulla dashboard e vedo di nuovo quel post.
Da un mese l'aggiornamento della dashboard va "a scatti", con post che rimangono visibili per giorni e altri che vengono oscurati.
E per carità, il post che vedo da due giorni per fortuna è ben scritto. Ma ormai potrei recitarlo a memoria.
Non so, mi semba che ci sia qualcosa da aggiustare.
[L'Ideota]
16 notes
·
View notes
Text

Redes sociais, banshees e o desespero – Parte 1: Facebook
Eu sou da última geração que passou um tempo da vida sem saber o que era Internet, sem fazer parte de alguma rede social virtual.
Quando surgiram os blogs, flogs e Orkuts da vida, na condição de pessoa introvertida que adorava ler e escrever e desenhar, eu vi uma chance de finalmente conseguir me expressar, conseguir conversar com as pessoas e mostrar que eu não era só aquela criatura esquisita, gaguejante, que não conseguia concatenar as ideias oralmente sob a pressão dos olhares externos — coisa que, aliás, eu muitas vezes ainda não consigo.
As redes sociais, em especial, eram uma ideia cheia de potencial. Quase 20 anos depois, a rede já não se parece quase nada com aquilo. Vou considerar a possibilidade de ter uma certa nostalgia infundada nessa impressão, mas nem tanto assim; a Internet realmente mudou para pior em alguns pontos, acompanhando algumas tendências do mundo não virtual (e capitalista)... isso é fato.

Primeiro, tem a questão dos algoritmos e essa insistência insuportável de cada espaço online em querer pensar e prever TUDO por você — pelo precinho camarada de $Todas As Suas Informações Pessoais.
O Facebook, por exemplo, afoga todas as postagens de amigos num mar de vídeos e páginas de grupos que você nunca teve a intenção de seguir. Por exemplo, por ser da geração millennial, o site presumiu durante um bom tempo que eu quisesse ver um milhão de grupos de H*rry P*tter, coisa na qual eu não tenho mais o mínimo interesse.
Durante a pandemia, começaram a aparecer transmissões ao vivo de cultos evangélicos de todo tipo na minha página. Horrorizada com esse assédio, fui nas configurações ver por que cargas d'água estavam sugerindo aquilo pra mim, e encontrei uma lista de palavras-chave bem assustadora, com algumas informações MUITO específicas que eu nunca havia fornecido diretamente à plataforma.
(Para quem tiver curiosidade, acesse o menu do Facebook -> Configurações e privacidade -> seção "Suas informações" -> Acessar suas informações -> Informações registradas -> Interesses em anúncios -> Ver todos os interesses *ufa*. Daí é só se apavorar.)
Bom, isso também rendeu um momento engraçado em que eu descobri que o Facebook achava que "Estresse" e "Fracasso" eram meus interesses...

Mas, claro, o pior não são as suposições erradas, e sim as certas, e todo o cálculo acertadíssimo para nos viciar no caça-níqueis de conteúdo e nos colocar em bolhas.
O problema em si é essa fórmula de dar ainda mais destaque a coisas que deveriam ser ignoradas, enterradas, mantidas no sétimo círculo do inferno — mas que, por serem tão atrozes, provocam uma reação visceral, um desejo de bater boca e xingar até a ducentésima geração de quem produziu e postou o absurdo, o que viraliza o conteúdo na base do ódio.
Pra mim, o grande divisor de águas do Facebook foram as eleições de 2018, período em que virou um sofrimento qualquer forma de interação por lá. Notícias falsas pra todo lado, discursos de ódio viralizando e se fortalecendo... E amigos e pessoas sensatas claramente cansados e desesperados com toda a tragédia anunciada.
Se a ideia de uma rede agregando parentes, ex-professores, ex-colegas, ex-chefes etc. já estava se mostrando um ponto fraco da plataforma, quando juntou-se a isso a possibilidade de ficar debatendo com todo esse pessoal sobre supostas mamadeiras de piroca e o escambau, daí que desandou tudo de vez.
Hoje em dia, com a promessa de alimentar a máquina das IAs com as nossas fotos e textos, a situação não parece muito mais animadora.
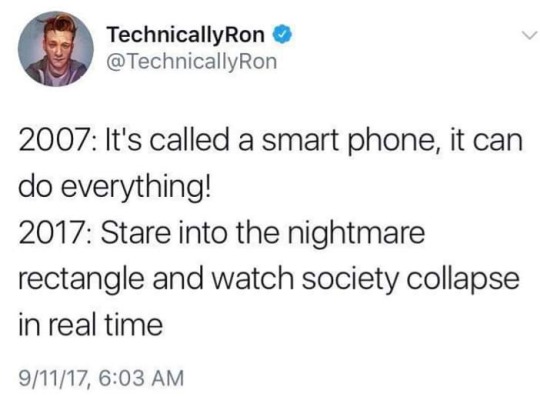
Eu continuo usando o Facebook de vez em quando para manter contato com pessoas queridas e ver o que elas andam fazendo, e para acompanhar grupos dos quais eu participo por interesses comuns: gatos, Animal Crossing etc.
Ainda mais de vez em quando, posto algum textão próprio para a minha audiência cativa de duas pessoas; mas é uma rede que eu decidi manter só para amigos e conhecidos do mundo e, por minha conta ser trancada, ela tem bem menos alcance e potencial de conversa.
7 notes
·
View notes
Text

¡El algoritmo de Google ha cambiado! Descubre cómo la actualización de Marzo 2024 redefine la calidad del contenido y cómo puedes optimizar tu sitio web para obtener mejores resultados.
https://mediazaragoza.blogspot.com/2024/03/nuevo-algoritmo-de-google-marzo-2024.html
#google#seo#algoritmos#algoritmo#actualizacion#marzo2024#ultimahora#marketingdigital#emprendimiento#zaragoza#publicidad en línea#online business#website#socialmediamarketing#marketing digital#robots#onlinemarketing
4 notes
·
View notes
Text
Atarassia #02 - Magico algoritmo - Entity N° 16022
Pennarelli e biro su carta A4 (21 x 29,7 cm , 350 gr.)Disponibile sul mio art shop: bananartista.etsy.com

View On WordPress
2 notes
·
View notes

Text

Moon in Virgo ♍️ virgo compilation

We love virgos

Virgo men at home 🏠 not getting in the way of their screen time
#me#pisces#zodiac signs#astrology#zodiac#virgo moon#virgo mars#virgo mercury#virgo guy#virgo traits#astrology humor#astrology blog#AstroMatrix#astrology app#zodiac gif#zodiac traits#zodiac stuff#funny compilation#algoritmo#astrology love#dating a Virgo be like#virgo men in the bedroom#virgo quotes#virgo and pisces#virgo horoscope#virgo do you relate#virgo the clown#🤡🤡🤡#me rn: 🤡🤡🤡
5 notes
·
View notes
Link
#musica#tech#tech house#techno#housemusic#deephouse#music#house#technomusic#djlife#rave#dance#producer#ibiza#minimal#minimaltech#groovy#hit#compartir#algoritmo#top#top10#españa#argentina#inglaterra#uk#ucrania#russia#rusia#europa
2 notes
·
View notes
Text
Mais perfis sobre arte e menos perfis de fofoca é a fórmula que uso para treinar o algoritmo do Instagram; para que o explorer me ofereça pinturas famosas, maquiagens bonitas, dicas de literatura, vídeos de gatinhos e informação sobre moda. Parei de seguir gente que se diz influencer, mas não influencia nem quem mora no próprio bairro. Passei a seguir museus, galerias, gatos fofos, perfis de cinema e de análises fashion também. Isso tem mais de um ano e ainda funciona. Toda rede social é legal e inspiradora se você souber usar.
2 notes
·
View notes
Text





Maurizio sei un folle
12 notes
·
View notes
Text

13 notes
·
View notes
Text
Enfermo de mí mismo
La identidad algorítmica es un medio de control y consuelo.
Según la historia común sobre nuestra caída en la posmodernidad, ser uno mismo se ha convertido en un trabajo duro. Antes, la gente nacía en situaciones relativamente estables en las que la identidad se prescribía en función del lugar de nacimiento y de quién era. Había pocas opciones en cuanto al tipo de vida que uno llevaría, y poca movilidad social o geográfica. Las categorías sociales -clase, género, etnia, religión- que determinaban las posibilidades de la propia vida eran esencialmente fijas, al igual que la forma en que se definían esas categorías. Pero la industrialización y la llegada de los medios de comunicación de masas desbarataron esas categorías con el paso del tiempo y convirtieron las normas sociales en algo más fluido y maleable. La identidad dejó de ser asignada y se convirtió en un proyecto que los individuos debían realizar. Se convirtió en una oportunidad y una responsabilidad, una carga. Ahora se puede dejar de ser alguien.

Algunos sociólogos y psicólogos etiquetan esta condición como "inseguridad ontológica". En The Divided Self (El yo dividido), R.D. Laing lo define como cuando uno carece de "la experiencia de su propia continuidad temporal" y no tiene "un sentido primordial de consistencia o cohesión personal". Sin este sentido estable del yo, sostiene Laing, toda interacción amenaza con abrumar al individuo con el temor de perderse en el otro o de ser borrado por su indiferencia. "Puede sentirse más insustancial que sustancial, e incapaz de asumir que la materia de la que está hecho es genuina, buena, valiosa", escribe Laing sobre los ontológicamente inseguros. "Y puede sentir su yo como parcialmente forzado desde su cuerpo".
Un sentido estable del yo a través del tiempo hace que la vida tenga sentido; nos permite experimentar y transmitir un sentido de "autenticidad". Pero este yo estable y auténtico tiende a representarse como el medio para su propio fin: El yo se consigue siendo uno mismo y encontrándose a sí mismo. Esta tautología nos aboca al fracaso y al interminable trabajo de intentar expresarnos y realizarnos. El sociólogo Alain Ehrenberg (en un pasaje que cita Byung-Chul Han en The Burnout Society) relaciona esta carga con el auge de la depresión como enfermedad mental: "La depresión comenzó su ascenso cuando el modelo disciplinario de los comportamientos, las reglas de autoridad y la observancia de los tabúes que daban a las clases sociales, así como a ambos sexos, un destino específico, rompieron con las normas que nos invitaban a emprender la iniciativa personal ordenándonos ser nosotros mismos... El individuo deprimido es incapaz de estar a la altura; está cansado de tener que llegar a ser él mismo".
Puede que no sean sólo las personas deprimidas las que estén cansadas de tener que llegar a ser ellas mismas. En unas condiciones económicas en las que la maximización de nuestro "capital humano" es primordial, nos vemos sometidos a una presión incesante para sacar el máximo partido de nosotros mismos y de nuestras conexiones sociales y exponerlo todo para mantener nuestra viabilidad social. Somos perpetuamente "incapaces de estar a la altura": debemos, como cualquier otra empresa capitalista, demostrar la capacidad de mantener el crecimiento o quedarnos obsoletos. La exigencia neoliberal de que convirtamos nuestras vidas en capital y lo hagamos crecer se apodera sistemáticamente del ideal de la autoexpresión y lo despoja de su dignidad y encanto.
Pero no ser nadie no es todavía una gran alternativa.
Este es el contexto en el que los medios sociales han prosperado: Resuelven el problema del yo bajo el neoliberalismo, ampliando una plataforma para el desarrollo del capital humano al tiempo que ofrecen una base aparentemente estable para la "seguridad ontológica". Podría parecer que los medios de comunicación social, al hacer que la interacción social sea asíncrona, al trasladar una parte de ella en línea a un espacio "virtual" indefinido y al someterla toda a un seguimiento, una medición y una evaluación constantes, no serían una receta para producir una sensación de continuidad personal. La forma en que nuestra autoexpresión se clasifica en "me gusta" y "compartidos" en las redes sociales parece subordinar la identidad a la competencia por la atención cuantificada, dividiendo a los compañeros en ganadores y perdedores. Y la creación de la identidad en forma de archivo de datos parecería moldear no un yo fundamentado sino un doble siempre incompleto e inadecuado: un "yo parcialmente forzado desde el cuerpo". Uno siempre corre el peligro de enfrentarse a su incoherencia, a la evidencia de un yo pasado que ahora se rechaza o a una versión mal interpretada y mal procesada del propio archivo que se distribuye como el verdadero yo.
Si Laing tiene razón sobre la inseguridad ontológica, las redes sociales parecen estar diseñadas para generarla: Imponen sistemáticamente una sensación de insustancialidad a los usuarios, convirtiendo la identidad en incoherencia al asimilar y exigir constantemente más datos sobre nosotros, haciendo de nuestro yo un vacío que nunca se llena, por mucho que se vierta. Nuestra identidad es recalibrada y recalculada constantemente, y podemos intentar siempre "corregirla" con más fotos, más actualizaciones, más posts, más datos.
Pero esta misma desestabilización abre la posibilidad de que se produzcan reaseguros compensatorios: los placeres en serie de comprobar los "me gusta" y otras formas de micro reconocimiento que cobran sentido de repente por la aguda inseguridad. Incluso cuando las redes sociales desestabilizan la experiencia vivida de la continuidad de nuestro yo, abordan la disolución de la identidad con un sistema dinámico de captura de la misma. Registran todo lo que hacemos en línea e insisten en su importancia, registrándolo en bases de datos relacionales en las que se analizará su contribución esencial a nuestra personalidad general y, en última instancia, se expresará en algún contenido específico más adelante.
Proporcionan un punto focal, un perfil de identificación único en torno al cual se puede organizar toda la recopilación de datos y la puntuación de la reputación que permanece con nosotros a través de todos nuestros cambios ostensibles. Si todas las normas sociales que rodean a un individuo cambian, el perfil de las redes sociales no lo hace.
El perfil sustituye a los antiguos estabilizadores de la identidad (familia, geografía, religión, etc.) y se convierte en la robusta pizarra en blanco en la que se pueden inscribir diversos papeles mientras permanecemos abiertos a la saturación de tantas influencias diferentes como sea posible. Puede sostener nuestras vidas mientras estamos ocupados reinventándonos constantemente para los mercados laborales. Los medios de comunicación social exacerban la inseguridad ontológica a la vez que se hacen pasar por su cura.
Las burbujas algorítmicas que los medios sociales construyen a nuestro alrededor son parte fundamental del consuelo que proporcionan las plataformas. Su presencia constante y fiable nos permite consumir una sensación de seguridad ontológica que las plataformas están erosionando.

La burbuja de filtros no es un desafortunado accidente, como sugirió Mark Zuckerberg en su manifiesto de la "comunidad global", sino una fuente esencial del atractivo de las redes sociales, el aspecto que les permite contrarrestar el vértigo posmodernista. Si todos los contenidos de Facebook se adaptan a la construcción de la empresa sobre quiénes somos, consumirlos es como consumir una versión coherente de nosotros mismos.
También refuerza la idea de que el mejor lugar para vislumbrar nuestra identidad social estable es Facebook. El compromiso con las redes sociales indica entonces nuestra aceptación de esta figura algorítmica del yo, una identidad en la que entramos cuando accedemos a las plataformas y que se siente como si siempre hubiera estado dentro de nosotros de alguna manera.
Entonces, ¿cómo sabe un sistema algorítmico quién eres? ¿Y qué hace que este conocimiento sea lo suficientemente eficaz como para mantener los niveles de participación en las redes sociales? ¿Por qué nos reconocemos a nosotros mismos en las muchas formas oscuras e indirectas en que nos saluda una plataforma de medios sociales, aunque este reconocimiento no sea consciente, aunque sólo se produzca a nivel de no aburrirse? ¿Por qué la clasificación algorítmica de contenidos funciona en todas las plataformas en las que se prueba, a menudo en contra de las protestas de los usuarios, que inevitablemente llegan a tolerarla o amarla?
El libro We Are Data, del profesor de estudios digitales John Cheney-Lippold, publicado hace varios meses, explora la identidad algorítmica, pero no en términos de la seguridad subjetiva o el placer que puede proporcionar. Le preocupa más el control que imponen los sistemas algorítmicos a través de la forma en que los agregadores de datos estructuran diversas categorías sociales. Describe el modo en que las empresas de redes sociales, los vendedores y las instituciones estatales utilizan nuestros rastros de datos para calcular las probabilidades de nuestra edad, raza, género, clase, nacionalidad, etc., y cómo esas probabilidades se utilizan para remodelar nuestras realidades individualizadas.
A medida que los teléfonos, las plataformas de redes sociales, los rastreadores de actividad física, el software de reconocimiento facial y otras formas de vigilancia capturan más información sobre nosotros, los algoritmos nos asignan marcadores de identidad y nos colocan en categorías basadas en correlaciones con patrones extraídos de conjuntos de datos masivos, independientemente de que éstos se correspondan con la idea que tenemos de nosotros mismos. Nos convertimos, hasta cierto punto, en lo que hacen otras personas, ya que sus datos contribuyen a la interpretación de los nuestros. El sistema inferirá nuestra identidad, de acuerdo con las categorías que defina o invente, y las utilizará para dar forma a nuestros entornos y guiar aún más nuestro comportamiento, afinar la forma en que hemos sido clasificados y hacer que los datos sobre nosotros sean más densos, más profundos. A medida que estos sistemas positivistas saturan la existencia social, anulan la idea de que hay algo sobre la identidad que no puede ser capturado como datos.
Dado que lo que los sistemas algorítmicos calculan como raza, género, edad o afiliación política es una selección de marcadores de datos que puede no tener ninguna relación con los indicadores sociales utilizados para determinar esas categorías -puede incluso ignorar cómo se autoidentifican los individuos-, Cheney-Lippold los diferencia: raza frente a "raza" estimada algorítmicamente, género frente a "género", etc. Estos pares son analíticamente distintos, pero se alimentan mutuamente a través de la forma en que las categorías probabilísticas se despliegan para anticipar lo que la gente hará o querrá ver, dando forma a cómo se les trata y qué oportunidades se les ofrecen. Puedes encontrarte en una lista de vigilancia de terroristas o en cuarentena por una gripe que no tienes, simplemente por las asociaciones de datos. No importa si la "raza" coincide con la raza, o si la "edad" se aproxima con exactitud a la edad: esto suele ser irrelevante para el diseño de estos sistemas. Por lo general, tratan de maximizar la participación de los usuarios o de captar las tendencias de grandes poblaciones, más que de simular a un usuario concreto.

Pero mientras tenemos alguna idea (aunque poco control) de lo que conforman estas categorías en la vida social fuera de Internet, no sabemos cómo los algoritmos determinan las probabilidades sobre nuestra identidad dentro de ella: se basan en estereotipos estadísticos más que sociales, como señala Cheney-Lippold. Para un sistema algorítmico, es posible que tengas un 45% de probabilidades de ser mujer y un 45% de probabilidades de ser hombre al mismo tiempo. Cada categoría social puede subdividirse infinitamente en la práctica, y cada combinación de probabilidades constituye un pseudo género propio. "Como el género de Google es de Google, no mío, no puedo ofrecer una crítica de ese género, ni puedo practicar lo que podríamos llamar una política de género de primer orden que cuestione lo que significa el género de Google, cómo distribuye los recursos y cómo llega a definir nuestras identidades algorítmicas", escribe Cheney-Lippold.
También podríamos preguntarnos en qué momento el "género" de Google deja de ser tratado como género y se convierte en otra cosa dentro de sus sistemas, dado que para el sistema, la etiqueta de "género" para ese particular es totalmente arbitraria. Las máquinas no dan el paso adicional que dan los humanos de naturalizar las categorías y hacerlas absolutas. Las categorías algorítmicas pueden comprender cualquier número de categorías sociales discretas y, en la forma en que se despliegan, se alejan por completo de la forma en que se utilizan socialmente o interpersonalmente.
Esto haría pensar que los sistemas rechazan las definiciones esencialistas de las categorías de identidad, permitiendo identidades fluidas producidas de forma contingente, situación a situación. Pero la fluidez dentro de las categorías es menos importante que el hecho de que los sistemas pueden estar entrenados para asociar ciertos datos con categorías específicas y socialmente cargadas, reforzando su significado percibido para la participación social. Se pide al sistema que calcule la probabilidad de tu raza porque, en parte, está diseñado para reproducir el significado de esa distinción. Por tanto, aunque un día te considere de una raza determinada y al siguiente de otra diferente, o vuelva a calcular tu probabilidad de ser blanco con cada nueva página web que visites, sigue contribuyendo a reproducir las condiciones en las que ser blanco tiene un valor determinado, tiene ciertas ramificaciones, crea ciertas posibilidades.
El sistema algorítmico amplía el significado de esas categorías más allá de contextos contingentes específicos a la clase de situaciones que pueden darse en cualquier momento y en cualquier lugar en línea, incluso sin presencia humana: la discriminación se produce siempre que se consulta la base de datos, con sistemas que generan lo que Cheney-Lippold llama "identidades justo a tiempo... hechas, ad hoc". Proyectan interpretaciones jerárquicas de las categorías en escenarios en los que a los agentes humanos ni siquiera se les ocurriría discriminar.
No hay nada que impida, por ejemplo, que los minoristas en línea ejerzan una discriminación de precios basada en quién sabe qué base. Uno puede imaginarse a los bancos o a los agentes inmobiliarios operando en líneas similares, donde los propios representantes no pueden explicar por qué
ciertos candidatos han sido rechazados. (Frank Pasquale detalla este tipo de "puntuación de caja negra" en The Black Box Society).
Las probabilidades calculadas algorítmicamente también pueden convertirse en instrumentos para engatusar un comportamiento más normativo de los individuos para los que las categorías sociales recibidas son importantes, anclando su sentido personal de identidad. Los algoritmos pueden utilizarse para establecer lo que, por ejemplo, se supone que es el comportamiento masculino o el comportamiento saludable y animar indirectamente a los sujetos interesados en cumplir esas expectativas a reorientar su comportamiento en consecuencia, incluso cuando esos objetivos en sí mismos siguen siendo dinámicos. A medida que se persiguen los objetivos -con nuevos datos que se introducen para tratar de ajustar el perfil- este mismo comportamiento alimenta y refuerza la forma en que el sistema ha empezado a definir la categoría. El algoritmo hace surgir el comportamiento que simplemente debía identificar, convirtiéndose en "un motor, no una cámara", según la frase del sociólogo Donald Mackenzie. Esto es ideal para las empresas y organismos que administran los modelos, ya que hace que los sistemas de datos sean más eficaces, aunque menos "precisos". Pueden crear el tipo de temas que buscan.

Los sistemas de identidad basados en datos perpetúan el significado social de las categorías al tiempo que eliminan la negociación de lo que significa cualquier categoría de la esfera social e interpersonal, colocándolas en su lugar en sistemas opacos y privados. Los usuarios que intentan cumplir las normas de estas categorías no tienen más remedio que proporcionar más datos para intentar cumplir los objetivos móviles. Y, como sostiene Cheney-Lippold, "no hay fidelidad a las nociones de nuestra historia individual y nuestra autoevaluación" en la forma en que los algoritmos de caja negra nos clasifican. La forma en que nos clasifican se mantiene clasificada, y cambia dependiendo del contexto y de lo que se le pida al sistema algorítmico. Lo que somos depende de lo que se haga con nosotros.
Al igual que no sabemos cómo estos sistemas calculan nuestra identidad y la clasifican para diversos fines, a menudo tampoco sabemos por qué. Esto significa que pueden utilizarse a nuestras espaldas para marcarnos como personas de interés para la policía y los agentes fronterizos, o para señalarnos como un riesgo para el seguro o para otras formas categóricas de discriminación sin que ningún agente humano tenga conocimiento directo. Pueden hacer que ciertas concatenaciones de datos sean normales y otras sean desviadas y socialmente descalificadoras. Estos prejuicios aprendidos por las máquinas pueden no tener siquiera nombres humanos, lo que hace más difícil que las personas se unan y luchen contra ellos. Las etiquetas no pueden reclamarse como principios de solidaridad.
Inconformes con cualquier categoría social preexistente, estas identidades sumergidas e invisibles en teoría pueden ser empujadas al mundo social y hacerlas reflexivas allí. En otras palabras, los sistemas pueden inventar razas y perpetuar la lógica del racismo: que es "racional" buscar patrones de datos sobre las poblaciones y hacerlos manifiestos y socialmente salientes, definitivos para los así identificados. A nivel individual, la discriminación a medida por algoritmo puede hacer imposible saber cuándo y por qué se está excluyendo o señalando a alguien. "Quién somos y qué significa quiénes somos en Internet nos viene dado", afirma Cheney-Lippold. "Nos vemos obligados a existir en un 'territorio del yo' a la vez extraño y desconocido, una base de integridad subjetiva que es estructuralmente desigual".
De manera más mundana, el análisis algorítmico puede simplemente buscar formas de aprovechar la información sobre los usuarios en su contra, haciendo que la identidad no sea tan fluida como más precaria. La recopilación de datos se utiliza para crear marcadores de identidad sobre nosotros que no vemos ni controlamos, a los que no podemos evaluar ni acceder ni modificar directamente. Las empresas saben más de nosotros como consumidores que nosotros mismos, en la medida en que limitamos nuestra identidad al comportamiento de consumo. Pero no necesariamente nos controlan ocultando cómo nos categorizan; pueden beneficiarse revelando cómo nos ven, pintando una versión aspiracional de nosotros mismos que mantiene el compromiso con los sistemas que nos perfilan. Si los sistemas algorítmicos funcionasen principalmente "obligándonos a existir" en escenarios que no nos aportarán ningún beneficio tangible, pronto encontraríamos formas de eludirlos.
Desde el principio, no nos autoinventamos.
Nacemos en un contexto social que constituye el marco y las limitaciones de nuestro autoconocimiento. Conocernos a nosotros mismos significa comprender este contexto inmutable que no hemos elegido. Los sistemas algorítmicos modelan ese contexto, concretando las formas en que la identidad sustituye a los cuerpos individuales y emerge entre personas y grupos, dentro de las instituciones y las posibilidades tecnológicas.

#technology#giovannachadid#writers on tumblr#cosmotechnics#philosophy#hack the planet#bogotá#malwaremedusa#technique#tech news#technician#technical#algoritmo#fuck the algorithm#google algorithm#algorithmic stablecoin#artificial intelligence#artificial brain#the dark artifices#followme
11 notes
·
View notes
Text
El algoritmo como relación tóxica
Descubro gracias a Arturo Paniagua (si no le sigues en Instagram, Twitter o TikTok ya estáis tardando), la campaña de Muyaio para presentar su último single: El Algoritmo. Con la excusa de este lanzamiento, Muyaio que ha creado una herramienta para ayudar a descubrir nuevos artistas:
un algoritmo justo, que te hará descubrir música de calidad hecha por artistas emergentes, muchos de ellos difícilmente recomendados en las plataformas de streaming (lo sé de buena tinta, trabajo en una y hasta hice un doctorado sobre ello).
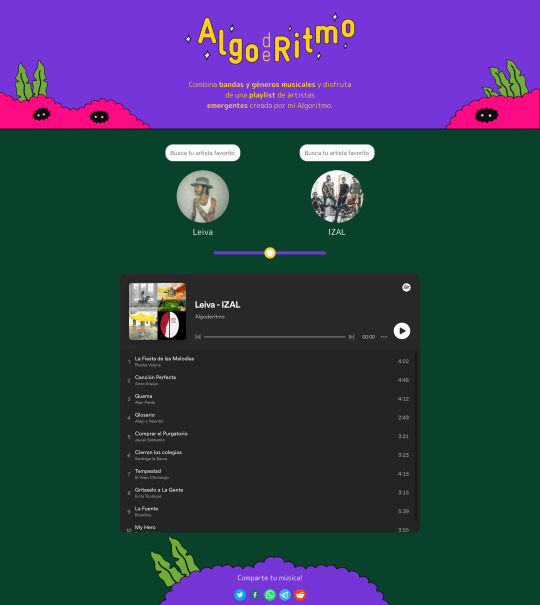
En El Algoritmo, Muyaio compara a la Inteligencia Artificial que nos recomienda música en las plataformas con una relación tóxica. ¿Por qué? Él mismo explica en la web donde está su herramienta app.algoderitmo.com:
Los sistemas de recomendación funcionan de dos maneras, se basan en lo que escuchan en común los usuarios, o en el contenido que se está recomendando, en este caso la música. La gran mayoría de los algoritmos que usamos a diario (para escuchar música, para comprar, para ver series) se basan en la primera manera. El problema es que ésta sólo es capaz de recomendar cosas populares. Por eso mi algoritmo se basa en la segunda forma, analizando el audio de las canciones.
Por ejemplo: seleccionamos dos artistas como Leiva e Izal y, automáticamente, nos crea una playlist con 10 temas de artistas no tan conocidos como Flecha Valona, Anxo Araujo o Alan Pardo:
Una gran idea, ¿no? Pero... ¿por qué un músico canario ha llegado a desarrollar esta tecnología? ¿Cómo lo hace?
Para ello utilizo una gran red neuronal, una especie de GPT de la música, que acabo de publicar en la mayor conferencia mundial de música y tecnología.
Y es que tras el nombre de Muyaio se esconde Sergio Oramas quién, además de músico con una larga trayectoria (Muyaio es solo su último proyecto), es Ingeniero Informático, musicólogo y Doctor en Tecnologías de la Información por la Universidad Pompeu i Fabra de Barcelona, un reconocimiento que obtuvo gracias a su tesis sobre, precisamente, los algoritmos de recomendación musicales: "Knowledge Extraction and Representation Learning for Music Recommendation and Classification". Es más, Sergio trabaja actualmente como Senior Data Scientist en Pandora, la plataforma de streaming que ofrece radios personalizadas a sus usuarios.
Los sistemas de recomendación funcionan de dos maneras, se basan en lo que escuchan en común los usuarios, o en el contenido que se está recomendando, en este caso la música. La gran mayoría de los algoritmos que usamos a diario (para escuchar música, para comprar, para ver series) se basan en la primera manera. El problema es que ésta sólo es capaz de recomendar cosas populares. Por eso mi algoritmo se basa en la segunda forma, analizando el audio de las canciones. Para ello utilizo una gran red neuronal, una especie de GPT de la música, que acabo de publicar en la mayor conferencia mundial de música y tecnología.
Si quieres conocerle más no te pierdas su charla en unas jornadas del Music Technology Group de la UPF en el que hizo su doctorado:
youtube
#Arturo Paniagua#algoritmo#Spotify#Muyaio#Música#tiktok#música#music#algoderitmo#Sergio Oramas#Pandora#relación tóxica#Music Technology Group#Youtube
4 notes
·
View notes
Text
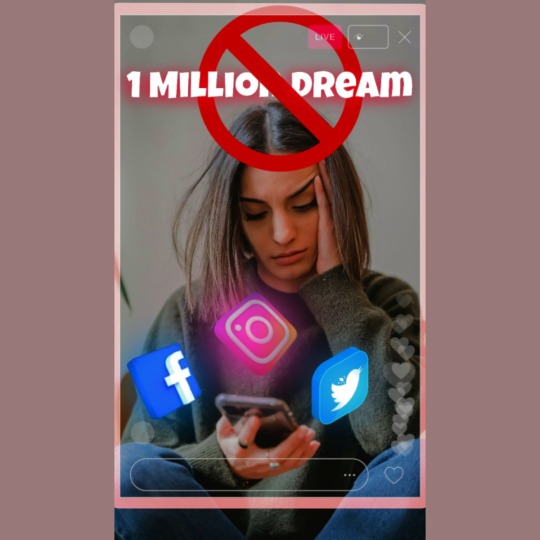
Relevancia de las redes sociales durante crisis económicas
Un título así de específico, merece una explicación detallada. Quizás no es su importancia, sino su relevancia durante cambios sociales o de crisis, como recesión
En la crisis de 2008, Facebook y su algoritmo, evolucionaron como actividades de esparcimiento alternativas a la realidad circundante
En la actualidad, se proyectaron como base para exponer las creaciones y disponibilidad para una…
View On WordPress
#analisis#community#marketing#redessociales#algoritmo#Artículo#blog#capitalismo#commerce#digital#instagram#Internet#mercadeo#online#Opinión#publicidad#Social Media Management#web
3 notes
·
View notes
Text
allora basta mostrarmi il suo profilo come "ti potrebbe piacere" algoritmo ti meno eh
2 notes
·
View notes
Last Seen Blogs

zksjsn64949
上海外围 上海约炮 上海伴游 VX:yueba0925

uxop
ux

xmagik-kingdomx
archived

whyarethedolanssoattractive
I like seeing double