#Text classification
Text
LLMs and their impact: using language models to advance data science
In the ever-evolving landscape of data science, language models have emerged as powerful tools that hold the potential to revolutionize how we process and interpret vast amounts of textual data. Among these language models, Large Language Models (LLMs) have emerged as the forefront of cutting-edge technology, enabling us to tackle complex natural language processing tasks with unprecedented accuracy and efficiency. In this blog, we will explore how LLMs have impacted data science and how they continue to shape the future of the field.
What are Large Language Models (LLMs)?
Large Language Models, or LLMs, are advanced artificial intelligence models that can understand, generate, and manipulate human language. These models are typically trained on massive datasets, containing billions of words, enabling them to learn intricate patterns and structures of language. They employ deep learning techniques, such as the Transformer architecture, to process text and make predictions with exceptional proficiency.
Applications of LLMs in Data Science
Natural Language Understanding (NLU): LLMs excel in NLU tasks, such as sentiment analysis, named entity recognition, and text classification. With their ability to comprehend context, they can infer the intended meaning of a sentence or document more accurately than traditional methods.
Language Generation: LLMs can generate human-like text, including articles, stories, and poetry. This capability finds application in content creation, chatbots, and virtual assistants.
Machine Translation: LLMs have significantly improved machine translation systems, allowing for more accurate and contextually appropriate translations across multiple languages.
Text Summarization: With LLMs, data scientists can develop robust automatic summarization algorithms that extract key information from lengthy documents, improving efficiency and comprehension.
Question-Answering Systems: LLMs enable the development of advanced question-answering systems that can comprehend complex queries and provide accurate responses.
Enhancing Data Science with LLMs
Pre-trained Models: LLMs are often pre-trained on vast datasets, making them a valuable resource for data scientists. Pre-trained models can be fine-tuned on specific tasks, saving time and computational resources.
Improved Feature Extraction: LLMs can extract high-level features from text data, offering more informative representations for downstream tasks, such as sentiment analysis or image captioning.
Data Augmentation: Data augmentation techniques using LLMs can generate synthetic data to enhance the robustness and generalization of machine learning models.
Domain-Specific Applications: LLMs can be fine-tuned on domain-specific datasets, making them adaptable to specialized industries, such as healthcare, finance, and law.
Challenges and Ethical Considerations
While LLMs have significantly advanced data science, they are not without challenges and ethical implications:
Data Bias: Pre-training on large datasets can lead to inherent biases present in the data, potentially perpetuating societal prejudices.
Overfitting: LLMs may overfit to the training data, leading to unrealistic outputs or incorrect predictions.
Model Size and Resource Requirements: Large LLMs demand substantial computational power and memory, making them inaccessible to many researchers.
Misinformation and Fake Content: Language models can inadvertently generate false information, which can be exploited to spread misinformation or create fake content.
Conclusion
Language models, particularly Large Language Models (LLMs), have revolutionized data science by providing powerful tools to process, understand, and generate human language. Their applications are diverse and continually expanding, with promising opportunities to enhance various NLP tasks and other data science applications. However, to fully realize the potential of LLMs, addressing challenges related to bias, overfitting, and ethical considerations is essential. As we move forward, it is crucial to use these models responsibly and transparently, ensuring that their impact on data science and society at large remains positive and transformative.
#Language models#LLMs (Large Language Models)#Natural language processing#Data science#Machine learning#Text generation#AI applications#Text analysis#Data processing#Information extraction#Knowledge representation#Semantic understanding#Text classification#Sentiment analysis#Data-driven insights#Predictive modeling#Text summarization#Feature extraction
0 notes
Text
In this tutorial, we will learn how to implement Naive Bayes for text classification in Python using the scikit-learn library.
#data science#machine learning#python#tutorial#coding#text classification#Naive Bayes#computer science#natural language processing#medium#medium writers#data analysis#programming#artificial intelligence#ai
1 note
·
View note
Text
Natural Language Processing (NLP) is a part of artificial intelligence that allows computers to recognize natural language – the words and sentences that humans use to communicate – to generate value. While machines are excellent at operating with and understanding structured data (such as spreadsheets and database tables), they’re not so great at deciphering unstructured data, for instance, raw text in English, Polish, Chinese, or any other human language. To know more about browse: https://teksun.com/ Contact us ID: [email protected]
#Deep Learning#Machine Translation#Sentiment Analysis#Text Classification#Text Summarization#Word Embeddings#Chatbots#Speech Recognition#product engineering services#product engineering company#iot and ai solutions#digital transformation#technology solution partner#product engineering solutions#Teksun Teksuninc
0 notes
Link
#text annotation#Text Classification#Natural Language Processing Services#document annotation#text annotation machine learning#NLP Services
0 notes
Text
my dashboard simulator is just:
mutual 1: I am SO normal [is demonstrably not]
mutual 2: i am so weird [is demonstrably not]
mutual 3: i am normal [arguably is, but only in lab conditions. where they need a pressure of 1 atmosphere and 25°C to be 'normal' and even then....arguably]
979 notes
·
View notes
Text
Page 1: The Basics of Magic & Classification

Will be posting part 2 tomorrow and when all of them are done I will post them all together
Bonus: 2 concepts for the sun and moon symbols

#fantasy worldbuilding#fantasy#writing#art#artists on tumblr#worldbuilding#digital art#character concept#fantasy art#writers on tumblr#Cassie#Cassies sketchbook#The Basics on Magic & Classification#should i post a only text version? it would be a super long post though#also opinions om the symbols?
16 notes
·
View notes
Text
every September I think ‘ahh…somewhere right now there are at least 100 Asian Americans who are freshmans trying to get through Said’s Orientalism who are suddenly realizing ‘wait, this isn’t about us’?
#*very* funny that a good amount of the people Said is discussing in that text#in curious US racial classification socially non-white census ‘Caucasian’#and generally considered ‘not Asian’ (he talks about this)
14 notes
·
View notes
Text
GD i forgot how good this shit is. rereading fractions hawkeye run its fixing me.
#genuinely i don't like comics for the most part!! there are a HANDFUL i enjoy!! this is one of them. goes in the same classification as#murderbot. stories that r just. the best shit.#dot text
27 notes
·
View notes
Text
i don't think i make enough silly funny posts about the torture labyrinth
#text#the deathspeaker#joe#he spends about half the entire comic in 2 different torture labyrinths. maybe even 3 depending on your classification#i made a character just to put him in the torture labyrinth fr fr#me looking at this silly man when i was 15 like hmmmm. today i will put him in the torture labyrinth
2 notes
·
View notes
Text
EPISODE 14. ANNA BREWS MAGICAL POTION OF KILL YOURSELF AND FUCKING DIES
#i say this EVERY episode but like favourite this season so far. apart from asterion maybe#the juxtaposition of the various fragments of this one is fucking wild. we have a classic You’ve Inherited The Gothic Ruin case. elaborate#discussions on the nature of free will; of the suffering of God as a being of infinite memory; how every person is omniscient regarding#their past; that is unchangeable and always ending ending ending. fate as a web of a thousand strands#we have the shame and religious guilt and quiet tenderness of the adolescent lesbian; a moment of pure safe kindness in contrast with the#rest. we have an occult library. we have fragments from some kind of 17th century alchemical text and gallows humour and angelological#hierarchy. we have philosophical discourse on the nature of knowledge and classification; whether taxonomising something incomprehensible#is enough to control it. and of course we have actual fucking orpheus euridice r&j ‘genre aware’ moment#mabelpod
6 notes
·
View notes
Note
Your 3d artwork is so nice! What software do you use, and how do you get the models? I'm curious and wanna try it out if my computer can handle it
Ah! Thank you so much!! I’m really glad you like what I make, it means a lot ^-^
I use MMD, MikuMikuDance, to make my renders! There’s.. almost definitely other software that might be better to use, but I am a vocalsynth nerd so I latched onto MMD when I was younger and have since learned its idiosyncrasies somewhat.
It's supposed to be used for making videos - you can even import Vocaloid .vsq files and get compatible models to automatically lip-sync to the song's lyrics! - but I use it more for generating static images. I work with models rather than drawing because that means the anatomy, design, and so on are always consistent (since I'm using the exact same physical models each time).
In terms of what is needed to run MMD, the website LearnMMD should have that information alongside all the download links. But, since MMD as a program has been around since something like 2008, I don't think it's quite as demanding on computers as you might think, especially if you don't use tons of effects or lots of high-poly models in the same project!
When it comes to finding models, MMD can load the .pmd and .pmx formats (.pmx is generally better since it's more recent). There are lots of these models to be found on places like DeviantArt, and they often come in different sorts of "styles", such as Animasa and Tda and Sour - my self-inserts are based on the Tda style. Many pre-existing models from games have also been converted into this format, so it's not all just vocalsynths.
You can edit MMD models, such as to put parts together or add collision physics, using the PMX editor; I probably spend more time in the editor (and an outdated version at that) than in the actual animation software, haha!
Here's an example of what the version of PMXe that I use looks like, with Citri's model as an example:
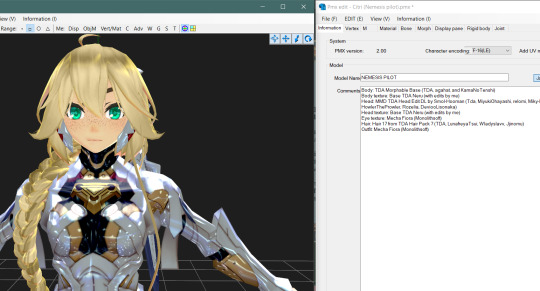
And here's an example of how MMD's interface itself looks while working in it (for me, at least! You can move stuff around, and change interface colours, and make sure your model's display panes are actually all translated unlike mine, and all sorts):

Sorry if this was a bit of a ramble, but, I hope it was alright! Thank you again for the ask!~
#a call from the void#not strictly about selfshipping#self‑insert: vessel of nemesis (citri)#thank you for being my model here haha#I like storing the model's credits in the comments area because then they're directly in the model file itself#but since I use MMD in english mode rather than japanese mode I can put descriptive flavour text in the english comments#and then that's what I'll see when I open the model up (this is also why the model name isn't the same in MMD as in PMXe)#(I like hiding alternate names in the other box. for example my PAFL self-insert's model name is ''echo'' when using MMD in english#but it'd be ''MT001-524'' if you switched MMD to japanese because that's what I wrote for that box#because that's her initial classification in the facility)#out of the inbox#spacerebel‑ships‑in‑spaceships#I very very recently found out that it's not ''TDA'' as in ''tee-dee-ay'' but instead ''Tda'' as in ''tee-da''#which is not something I had realised#MMD itself does come with some models to use by default! which I believe are animasa. the metal miku and sakine meiko ones are good#if you want to use effects you need to download an extra program I think but then you just.. use it from within MMD at the top corner
3 notes
·
View notes
Text
raitrolling
Glasya sliding a copy of a report they found in the archives titled “Known Intimate Encounters With Otherworldly Entities” to Argumi with a look on their face like trust me an alien isn’t that weird in the grand scheme of things
Argumi glancing with pain at the title of the report and a cringe at Glasya like “It’s worrying that not only did you find this at all but also this is clearly several pages thick”
#argumi things#raitrolling#ooc as lard#text post terror#Best Friend Glasya 'artfully interpreting' records classification for their friend
6 notes
·
View notes
Text
booty shorts that say TOP SECRET//SCI on the ass
#particularly interested in this whole stolen/leaked documents shit#bc for work i've been working on document classification training#text posts#infosec posting
3 notes
·
View notes
Text
honestly i think part of d+d as a fantasy is just, being something. i think the strict categories are a feature. i’m not an employee of x mercenary company i am a paladin. i get better at life by becoming more paladin. when i hit someone with my sword that action tells me what i am because it is listed under the moves of a paladin and not a rogue. and when i become paladin enough i will become one and only one type of paladin. what peace to be something. i don’t think this is a useful desire but i do experience it
#this is about ‘race’ as well as ‘class’ but someone less white than me could say that better#[vividity.imp]#disclaimer i am not using ‘d+d’ to equal ‘role playing game’ i occasionally fixate on the d+d manuals bc i think they’re fascinating texts#i’m reading the 4th e rulebooks rn and they graciously extend the obsession with classification to 8 ‘primary types of players’ im obsessed.#the gm advice is actually pretty good but like. am i reading into this too much
3 notes
·
View notes
Text
tell me why every man i’ve ever liked has the same taste in music
#no matter the artist! whenever i listen to one of their recommendations#i’m just like 🧍🏼♀️i’ve heard this before#just in a different font classification#eris: text
1 note
·
View note
Text
how do I turn this into a marketable skill

#WHY DID I SPEND SO MUCH TIME ON THIS?????#IT'S NOT EVEN DONE#but it is pretty cool#idk what else I'm gonna add#but I'm sure it'll be extravagant#just (mostly) for future reference#made the file background (including label text + lines) and app icons in photoshop#file number is current time (hhmmss)#classification number is the first letter of the month + the date (mmddyy)#volume number is a countdown to an event#series is the overall day number overall week number overall month number#then the bottom left is upcoming alarms (unfinished) and the right is upcoming calendar events#y'know I had actual plans#and did this instead
1 note
·
View note
Last Seen Blogs

sirencyrusveil
Beauty In Sound

cryo-sky
Jakub Czerwinski

fxxkthisimperfect
my edit's ~

msjinxygirl
HiJinx

esbensen70tierney-blog
Untitled