#acoustics
Text
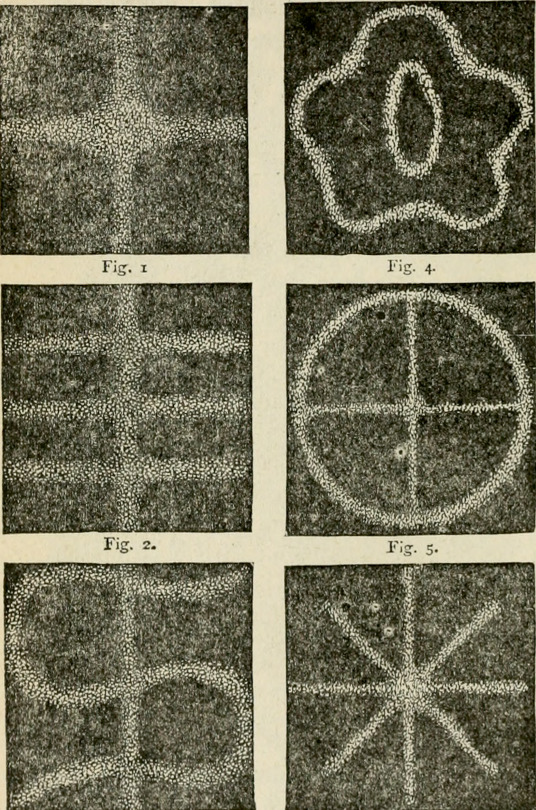
"Marvelous sound forms." Marvelous wonders of the whole world. 1886.
Internet Archive
650 notes
·
View notes
Quote
It has been said since ancient times that the nature of reality is much closer to music than to a machine, and this is confirmed by many discoveries in modern science. The essence of a melody does not lie in its notes; it lies in the relationships between the notes, in the intervals, frequencies, and rhythms. When a string is set vibrating we hear not only a single tone but also its overtones—an entire scale is sounded. Thus each note involves all the others, just as each subatomic particle involves all the others, according to current ideas in particle physics.
Fritjof Capra, foreword to The World Is Sound: Nada Brahma: Music and the Landscape of Consciousness by Joachim-Ernst Berendt
#quote#Fritjof Capra#Capra#Joachim-Ernst Berendt#Berendt#sound#music#consciousness#spirituality#Nada Brahma#Brahman#Vedas#Hinduism#reality#science#physics#particle physics#acoustics
592 notes
·
View notes
Text
How Moths Confuse Bats

When your predators use echolocation to locate you, it pays to have an ultrasonic deterrence. So, many species of ermine moths have structures on their wings known as tymbals. (Image credit: Wikimedia/entomart; research credit: H. Mendoza Nava et al.; via APS Physics)
Read the full article
#acoustics#aeroelasticity#biology#buckling instability#fluid dynamics#moths#physics#science#ultrasound
109 notes
·
View notes
Text
As any percussionist or fidgety pen-tapper can tell you, different materials make different noises when you hit them. Researchers at Drexel University hope this foundational acoustic phenomenon could be the key to the speedy removal of lead water lines that have been poisoning water supplies throughout the country for decades. A recent study conducted with geotechnical engineering consultant Seaflower Consulting Services, showed that it is possible to discern a buried pipe's composition by striking it and monitoring the sound waves that reach the surface. This method could guide water utility companies before they break ground to remove lead service lines.
In the aftermath of the 2014 water crisis in Flint, Michigan, many utility companies have been diligently working to verify the materials of their service lines. These efforts have become increasingly urgent in the last two years due to the Biden Administration's Bipartisan Infrastructure Act and the Environmental Protection Agency's Lead Service Line Replacement Accelerators initiative mandating the removal of all lead pipes, serving an estimated 9.2 million American households -- putting utilities on the clock to finish the job by 2033.
Read more.
43 notes
·
View notes
Text
you know about musical tuning right? harmonics? equal temperament? pythagoras shit? of course you do (big big nerd post coming)
(i really dont know if people follow me for anything in particular but im pretty sure its mostly not this)
most of modern western music is built around the 12-EDO (12 equal divisions of the octave, the 12 tone equal temperament), where we divide the octave in 12 exactly equal steps (this means that there are 12 piano keys per octave). we perceive frequency geometrically and not arithmetically, as in that "steps" correspond to multiplying the frequency by a constant amount and not by adding to the frequency
an octave is a doubling of the frequency, so a step in 12-EDO is a factor of a 12th root of 2. idk the exact reason why we use 12-EDO, but two good reasons why 12 is a good number of steps are that
12 is a nice number of notes: not too small, not too big (its also generally a very nice number in mathematics)
the division in 12 steps makes for fairly good approximations of the harmonics
reason 2 is a bit more complex than reason 1. harmonics are a naturally occurring phenomena where a sound makes sound at the multiples of its base frequency. how loud each harmonic (each multiple) is is pretty much half of what defines the timbre of the sound
we also say the first harmonics sound "good" or "consonant" in comparison to that base frequency or first harmonic. this is kinda what pythagoras discovered when he realized "simple" ratios between frequencies make nice sounds
the history of tuning systems has revolved around these harmonics and trying to find a nice system that is as close to them while also avoiding a bunch of other problems that make it "impossible" to have a "perfect tuning". for the last centuries, we have landed on 12 tone equal temperament, which is now the norm in western music
any EDO system will perfectly include the first and second harmonics, but thats not impressive at all. any harmonic that is not a power of 2 is mathematically impossible to match by EDO systems. this means that NONE of the intervals in our music are "perfect" or "true" (except for the octave). theyre only approximations. and 12 steps make for fairly close approximations of the 3rd harmonic (5ths and 4ths), the 5th harmonic (3rds and 6ths) and some more.
for example, the 5th is at a distance of 7 semitones, so its 12-EDO ratio is 2^(7/12) ~= 1.4983, while a perfect 5th would be at 3/2=1.5 (a third harmonic reduced by one octave to get it in the first octave range), so a 12-EDO fifth sounds pretty "good" to us
using only 12-EDO is limiting ourselves. using only EDO is limiting ourselves. go out of your way, challenge yourself and go listen to play and write some music outside of this norm
but lets look at other EDO systems, or n-EDO systems. how can we measure how nicely they approximate the harmonics? the answer is probably that there is no one right way to do it
one way we could do it is by looking at the first k harmonics and measuring how far they are to the closest note in n-EDO. one way to measure this distance for the rth harmonic is this:
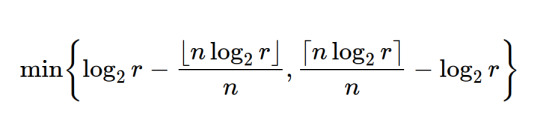
adding up this distance for the first k harmonics we get this sequence of measures:
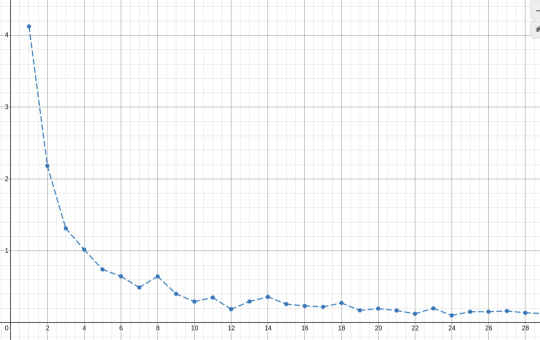
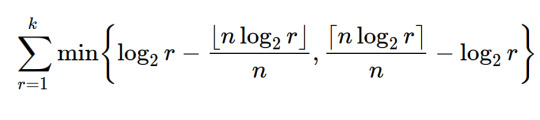
(this desmos graph plots this formula as a function of n for k=20, which seems like a fair amount of harmonics to check)
the smallest this measure, the "best" the n-EDO approximates these k harmonics. we can already see that 12 seems to be a "good" candidate for n since it has that small dip in the graph, while n=8 would be a pretty"bad" one. we can also see that n=7 is a "good" one too. 7-EDO is a relatively commonly used system
now, we might want to penalize bigger values of n, since a keyboard with 1000 notes per octave would be pretty awful to play, so we can multiply this measure by n. playing around with the value k we see that this measure grows in direct proportion to k, so we could divide by k too to keep things "normalized":
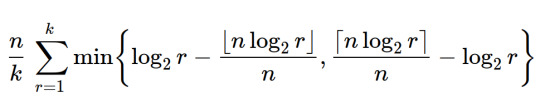
plotting again, we get this

we can see some other "good" candidates are 24, 31, 41 and 53, which are all also relatively commonly used systems (i say relatively because they arent nearly as used as 12-EDO by far)
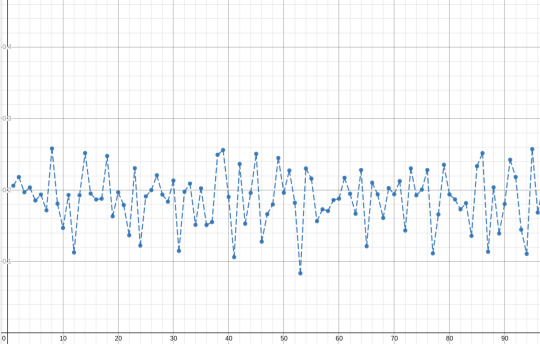
increasing k we notice something pretty interesting

(these are the same plots as before but with k=500 and k=4000)
the graph seems to flatten, and around 0.25 or 1/4. this is kinda to be expected, since this method is, in a very weird way, measuring how far a particular sequence of k values is from the extremes of an interval and taking the average of those distances. turns out that the expected distance that a random value is from the extremes of an interval it is in is 1/4 of the interval's length, so this is not that surprising. still cool tho
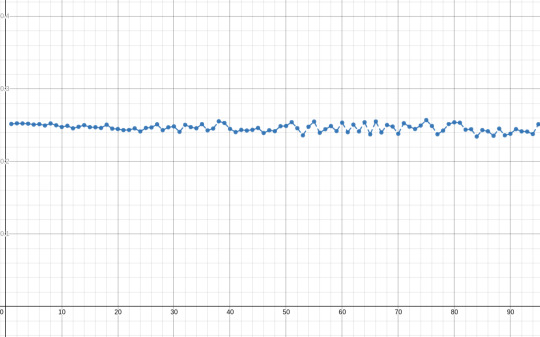
this way, we can define a more-or-less normalized measure of the goodness of EDO tuning systems:

(plot of this formula for k=20)
this score s_k(n) will hover around 1 and will give lower scores to the "best" n-EDO systems. we could also use instead 1-s_k(n), which will hover around zero and the best systems will have higher scores
my conclusion: i dont fucking now. this was complete crankery. i was surprised the candidates for n this method finds actually match the reality of EDO systems that are actually used
idk go read a bit about john cage and realize that music is just as subjective as any art should be. go out there and fuck around. "music being a thing to mathematically study to its limits" and "music being a meaningless blob of noise and shit" and everything in between and beyond are perfectly compatible stances. dont be afraid to make bad music cause bad music rules
most importantly, make YOUR music
73 notes
·
View notes
Text
Physics Friday #14: Sound (Part 2/2)
Preamble: Let's get straight into it
Education Level: Primary School (Y5/6)
Topic: Sonic Physics (Mechanics)
The previous part 1 of my sound post is here.
Pitch and Frequency
Pitch and frequency are related to eachother, the only difference being that frequency is a physical interpretation of sound and pitch is our own mental interpretation of it.
But what exactly is frequency?
Go back to last time's example of a tick sound occurring at regular intervals ... because this sound is repeating, we can describe it's behaviour by measuring mathematical properites:
How much time passes in-between each tick (Period)
How many ticks occur every second (Frequency)
These two ideas are related to eachother, in fact Frequency is 1/Period. If you have a tick every half-second, then you can say the tick occurs twice every second.
We measure sound in Hertz, which is effectively a measure of ticks per second.
Most sounds, however, don't work this way, with repeated ticks. They act as proper waves. With zones of high pressure (peaks), and low pressure (troughs). This is where we have to introduce another variable into our equation:
The physical difference separating each peak (Wavelength)
Since these waves travel forward in the air, a detector (like our ears) will pick up the peaks and troughs as they reach our ear. We can measure frequency or period by recording the speed at which our peaks reach our ear.
But we also can relate frequency to wavelength. After all, the further apart the waves are separated, the more time it'll take for a peak to reach us after the previous one.
We quantify this relationship using c = fλ. Where c is the speed of the wave, f is the frequency, and λ is the wavelength.
Notice that we can also say cT = λ, where T is the period. This demonstrates that the physical wavelength is proportional to the amount of time between each peak.
So where does pitch come in?
As mentioned in part 1, if we continue to decrease the time between each tick, or increase the frequency, at some point we'll begin to hear a sound.
This is our brain playing a trick on us. It's like frames-per-second but for our ears. Below some fps threshold, we can see the individual pictures of a video, but above the threshold, it looks like a continuous film. Notice that fps is also another form of frequency.
When we reach this level, our brain can't distinguish between each tick and sees it as one sound. We begin to hear our first sound.
At this point, frequency becomes tied to pitch. The more rapid the ticking becomes, the higher of a pitch we hear. This is a choice that our brain makes - it's purely psychological.
Mixing different pitches
Combining different pitches allows us to create a foundation for music. In western music, our source of harmonics comes from Pythagoras, who kinda fucked it up by not using irrational numbers.
An octave is defined as a higher sound that has twice the frequency of the lower sound i.e. a ratio of 2:1. One octave above middle C (at about 262 Hz) gives us C5 (at about 524 Hz).
We can create further subdivisions like a perfect fifth, where frequencies form a 3:2 ratio. Or a perfect fourth, which has a ratio of 4:3.
Volume, Intensity, and the Inverse Square Law
Volume is directly related to the amplitude of a sound wave. Effectively, how strongly is the air being compressed at each peak?
Again, volume is just another psychological interpretation of a physical phenomena. Similar to how our eyes see brightness.
Amplitude isn't just interpreted as volume, it is also the power that the sound waves carry. Smaller amplitudes correspond to less energy contained within the moving particles.
We measure intensity logarithmically, because that's what our ears here. Effectively a wave sounds twice as loud only if the wave is 100 times as amplified. It's a similar effect to pitch, where we multiply frequencies instead of adding them.
That's where the decibel scale comes in. 1 dB = a 10x increase in the sound's power output. The decibel scale is used generally for a lot of measurements of wave/power intensity. However it just so happens that our ears behave in very similar ways.
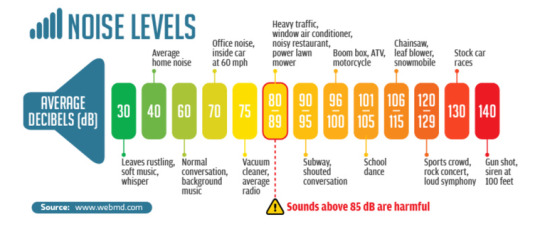
Image credit: soundear.com
Notice that louder sounds are more likely to damage our ear. That's because when loud sounds reach our ear, it causes the inner components to vibrate. This vibration amplitude generally is proportional to the amplitude of the waves.
Too loud of a sound means that our eardrums are vibrating with too great of a physical movement. This can create tears in tissue that damage our ears' sensitivity to sound.
Sound looses power over distance
If you stand far away enough from a sound source, it sounds fainter, eventually becoming unhearable.
This is because of the inverse square law. As sound spreads out over distance, it has to emanate in the form of a sphere, going outward in every direction, in order to maintain consistency of direction.
The same amount of power gets spread thinner and thinner over the bubble that it creates. The surface area of a sphere increases to the square of it's radius.
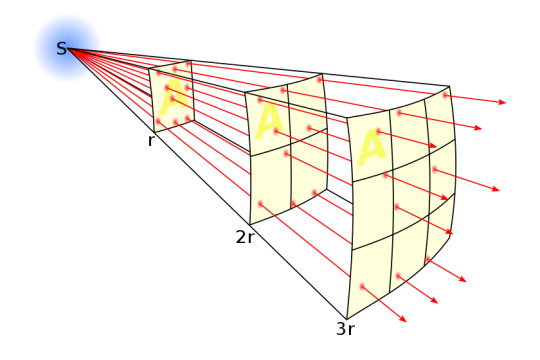
Image Credit: Wikipedia
Thus we get a decrease in volume over time.
What the Actual Fuck is Timbre, and how do you pronounce it? (also Texture too)
Unfortunately I still don't know how to pronounce it.
Timbre is defined as the quality and the colour of the sound we hear. It also includes the texture of the sound. It's sort of the catch-all for every other phenomena of sound.
Timbre is a bit more complex of a phenomena. In that, it combines basically everything else we know about how we hear sound. So I'll go one by one and explain each component of what makes Timbre Timbre.
Interference
Wave interference is an important property that needs to be understood before we actually talk about timbre. Sound waves often can overlap eachother in physical space, normally caused by multiple sound sources being produced at different locations.
These sound sources often will create new shapes in their waveform, via interference.
Constructive interference is when the high-pressure zones of two sound waves combine to produce an even-higher-pressure zone of wave. Effectively pressure gradient add onto eachother.
Destructive interference is when a high-pressure zone overlaps with a low-pressure zone, causing the pressure to average out to baseline, or something close to the baseline.
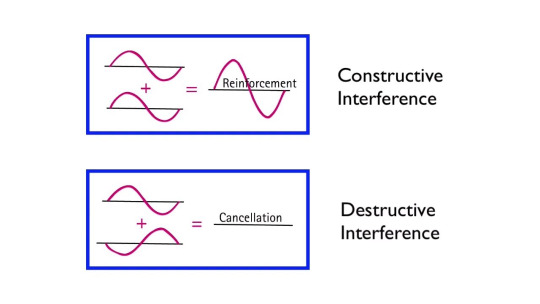
Image Credit: Arbor Scientific (Youtube)
We can look at multiple waves acting continuously over a medium to see how their amplitudes will add up together using interference. This is the origin of more unique wave patterns.
The shape of a wave
Sound waves can come in different varieties. While the most basic shape is the sine wave. We can add different intensities, frequencies and phases of sine waves to produce more complex patterns.
I won't go into how this combination works because that's better left for a Fourier series topic. Just know that pretty much any sound can be broken down into a series of sine waves.
These patterns have a different texture, as they combine multiple different monotone sounds. Take a listen to a sawtooth wave vs a sine wave:
Warning: the sawtooth wave will sound a lot louder than the sine wave.
This gives us a different sound texture.
Resonance
When you play a musical instrument at a particular frequency, the instrument is often resonating.
Say you produce sound within an enclosed box. Producing it at one end. Eventually the sound will reach the end of the box and bounce back from reflection (as we'll see later).
The sound will bounce back and forth, combining itself with the previous waves to produce more and more complex waveforms.
But there is a particular frequency, at which, the waves will perfectly interfere with eachother to produce what's known as a standing wave.
A standing wave will oscillate, but it will appear as if it's not moving forward. Of course, power is still moving throughout the wave, as we'll still be able to hear something.
This standing wave can only occur at a particular frequency, one in which the wave perfectly interferes with it's reflection within the box.
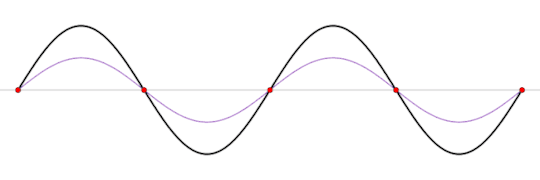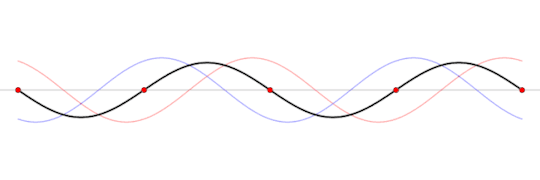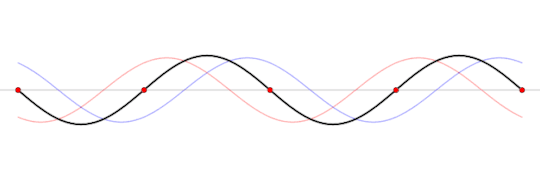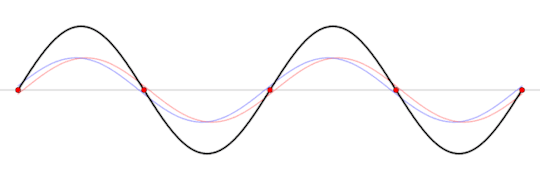
A standing wave (black) that is produced by two sine waves (blue and red) moving in opposite directions
Image source: Wikipedia
This frequency is called the resonant frequency of the box. This frequency depends on several factors like the speed of the wave, the material inside the box, the shape of the box, and the length of the box.
The resonant frequency can be activated by our voices, as our voices or just blowing air is already a combination of different sound frequencies. The non-resonant frequencies will eventually loose all of their power as they destructively interfere, leaving only the resonant frequency, which gets amplified by what we put in
For example, you can fill a glass bottle halfway with some water, blow in it, and it will produce a particular sound. Fill it with more water, and the pitch increases - i.e. by adding the water we increase the resonant frequency.
All instruments have one or more resonant frequencies based on their material and shape (I say multiple because some instruments can me modelled as multiple boxes. Like a violin will have the inside of the wood, the wood itself, the strings, etc.).
Instruments also allow us to alter the resonant frequency by playing it differently (like putting a finger over your recorder's hole (phrasing)).
These differences in how we obtain resonance can also affect the quality of the sound.
Overtones
Resonance is not just generated with a single resonant frequency, we can create resonance with higher multiples of the the same fundamental frequency.
This is because in our box model, multiplying the fundamental frequency will allow us to create a standing wave, just with a shorter wavelength:
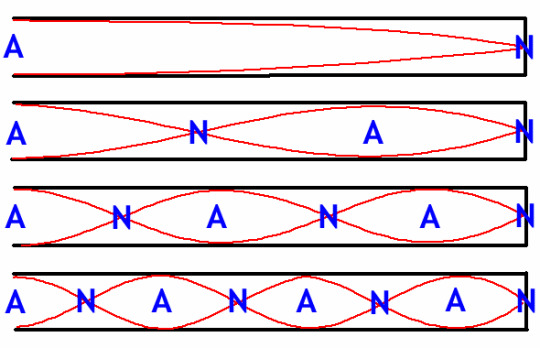
The A's stand for antinodes, which vibrate in the standing wave with the maximum amplitude. The N's stand for nodes, which do not move at all.
Image Credit: Macquarie University
Direct multiples of the fundamental frequency are called harmonics. Instruments can also produce other frequencies not directly harmonic depending on the structure of the 'box' they utilise.
These additional frequencies, ones which come often in fractional multiples of the fundamental are called partials. Both partials and harmonics represent the overtones of an instrument.
Overtones are what give sound additional character, as they allow instruments to not just resonate at the note they play, but at other combined frequencies. In some instruments, the overtones dominate over the fundamental - creating instruments that can play at much higher pitches.
Envelopes and Beats
Say we add two sine waves together (red and blue), each with slightly different frequencies, what we get is this:
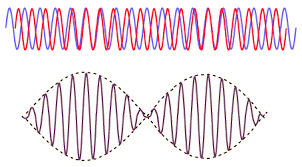
Image Credit: HyperPhysics Concepts
We can see that the brown wave has a singular oscillation frequency, but also it's amplitude continuously scales with reference to this hidden envelope frequency, called the beat frequency (dotted line).
This difference between the actual wave's real frequency and the wave's overall frequency envelope. Is another source of timbre.
Notes, and the way we play them will often generate unique and different envelopes depending on how they are played. For example a staccato quarter-note will have a different envelope to a softly played quarter-note.
Other properties of Sound
Reflection
Different mediums mean different speeds of sounds e.g. molecules in wood (solid) are harder to move than molecules in air (gas).
These different speeds create several effects. Including the reflection of waves. Often waves require a bit of power in order to physically overcome the resistances to vibration of a particular medium.
Often this leads to sound waves bouncing back off harder-to-traverse surfaces.
Say that a sound wave travels through the air and reaches a wooden wall. The atoms vibrating in the air will hit against the wooden wall, transferring only some of their energy to the resistant wood.
The wood atoms on the border of the wall will bounce back, as expected. But this time they will transfer energy back into the air at a much greater magnitude due to newton's third law.
Thus while some of the sound wave ends up going deeper into the wood, the wood will push back and cause the air to vibrate in the opposite direction, creating a reflected wave.
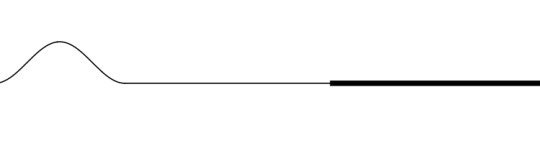
Image credit: Penn State
We characterise the amount of power being reflected versus transmitted versus absorbed using portions:
A + R + T = 1
A = Power absorbed into the material (e.g. warms up the material)
R = Power reflected back
T = Power transmitted into the new medium
This is both an explainer as to why rooms are both very good, and very bad at keeping sound inside them. It really depends on the rigidity and shape of the material they are bordered by.
Refraction
Just like light, sound waves can also refract. Refraction is actually a lot simpler to understand once you already realise that waves will both reflect and transmit across medium changes.
Refraction is just combining the results of incomplete reflection (i.e. transmission) with some angle.
I won't go into refraction in too much detail, as it's worth a different topic. But effectively we experience snell's law but modified for sound.
Diffraction
Sound waves, like all waves propagate spherically (or circularly in 2D).
When travelling around corners, sound can often appear louder than if you were further away, looking at the source more directly.
This is because spherical waves will often 'curve' around corners. This is better described by light diffraction. Which is something for another time.
Conclusion
In conclusion, that's how sound works, mostly. This is a topic that is a little less closer to my expertise. Mainly because it delves into more musically-inclined phenomena that I am less familiar with. But I'm sure I did a good job.
Unfortunately, it seems like the plague of the long post is not yet over. Perhaps I need to get into a lot more specific topics to make things better for me and you (the reader).
Anyways, my exams are done. I am done. I do not have to do school anymore. Until I remember to have to get ready for my honours year (a.k.a. a mini-masters degree tacked on after your bachelor's degree).
Until next time, feel free to gib feedback. It's always appreciated. Follow if you wanna see this stuff weekly.
Cya next week where I will probably try another astronomy topic, or something like that.
63 notes
·
View notes

Text
Speak of the devil, or rather hear the devil! University researchers in Finland have uncovered a mysterious resonance at Devils Church cave that may have once echoed the conversations between healers, sages, and the supposed Devil himself.
#cave#acoustics#devil#sound#ceremonies#caverns#Finland#shaman#rituals#ancient#history#ancient origins
29 notes
·
View notes
Text

#puns#punny#punstars#all american punstars#music jokes#music humor#dad jokes#bad jokes#acoustics#pigeon jokes
199 notes
·
View notes
Text
youtube
The Great Organ of York Minster, fully restored to its former glory.
#York Minster#The Great Organ#British cathedrals#Toccata#Church of England#classical music#pipe organ#mediaeval#Gothic architecture#sacred space#acoustics#Christendom
24 notes
·
View notes
Text
i need to sleep why am i trying to learn acoustics
guys this is crazy. recorder harmonics modeled with eigenvectors or something. wuh. this is so cool and mind blowing even though i dont understand most of the math here
youtube
strings and air are the same man. you can just model them as springs. its all springs. so many springs
#physics#math#acoustics#recorder#its 2 am#argh#bye#im so dumb#im supposed to wake up early#yet here i am#Youtube
9 notes
·
View notes
Text
Found some sweet cathedral-esque acoustics at work today.
11 notes
·
View notes
Text
Sound is invisible stuff. Those who have expertise in its properties and potentialities also have a tendency to lack a full understanding of the worlds of tactile matter, visible surfaces, the volume of sound. Sound is a thing and no-thing, like air, money, time or love, complex to infinitude as one of the ungraspable phantoms of life. All these metaphors we use to bring into being the property of sound and the sensation of its hearing: a honeyed voice, a rough voice, a piercing scream; the taste of viscosity, a hand passes over splintered wood, a needle punctures the skin. Think of sound – that high sound of hearing and air – pouring into the volume of a space, translucent block of air like colourless jelly flecked and warped with every passing noise event and its trail of decomposing matter, something like a stiff liquid or intangible runny paste through which the body passes without resistance yet it enfolds and penetrates the body with the insistence of abyssal pressure and the clotted emotions of memories as active entities, in flight like birds, insubstantial as papery moths.
David Toop, A Piercing Silence: James Richards, from Inflamed Invisible, originally published in James Richards: To Replace a Minute's Silence With a Minute's Applause, Whitechapel Gallery, London, 2015
70 notes
·
View notes
Text
A Better Ear Plug

Ear plugs can be wonderful at blocking outside noise, but they come with a downside: they typically amplify internal bodily sounds, like our heartbeat, breathing, and chewing. (Image and research credit: K. Carillo et al.; via APS Physics)
Read the full article
189 notes
·
View notes
Text

Measuring Length: Transit-Time Measurements
One method of measuring distance, or length, is to emit a signal toward an object and measure the length of time it takes for that signal to return. Any signal can work for this method (sound, light, etc.), so long as the math for the speed of that signal is known (such as the speed of sound in water, or the speed of light in air, etc.). Then, a mathematical calculation can be performed to determine the distance between the signal emitter and the object.
Radar is one example of this method, using radio waves to determine distance. Another example is the global positioning system (GPS), which determines distance based on the time difference between your device and the signals sent from multiple satellites.
Sources/Further Reading: (Image source - University of Illinois) (NIST) (radartutorial.eu) (Wikipedia)
#Materials Science#Science#Radio waves#Electromagnetic spectrum#Light#Sound#MeasurementMonday#Acoustics#2024Daily
21 notes
·
View notes
Text
Archaeoacoustics and 'Songs of the Caves'

Archaeoacoustics is a sub-field of archaeology and acoustics which studies the relationship between people and sound throughout history. It is an interdisciplinary field with methodological contributions from acoustics, archaeology, and computer simulation, and is broadly related to topics within cultural anthropology such as experimental archaeology and ethnomusicology. Since many cultures have sonic components, applying acoustical methods to the study of archaeological sites and artifacts may reveal new information on the civilizations examined.
The importance of sound in ritual practice is well attested by historical and anthropological evidence. Voices and instruments (pipes, drums) will also have played a key role for prehistoric societies, and a number of studies have sought to demonstrate that by measuring the acoustical properties of archaeological spaces and open-air locations. One of the principal difficulties, however, is to establish a robust methodology. Every space or location will have an acoustic signature, but that does not imply that vocal or musical performance was an essential part of ritual practice; nor that those places were specially designed or selected for their acoustical properties.
Palaeolithic painted caves have occupied a special place in this debate since studies in the 1980s suggested that the placement of paintings and murals within the caves might have been guided by the acoustics; that they might be directly correlated with resonance. In 2013, Durham University (Durham, England) archaeologist Chris Scarre joined a team of acousticians, archaeologists and musicians led by Professor Rupert Till (Huddersfield University) in a systematic on-site analysis of acoustic properties and prehistoric motifs in five Upper Palaeolithic painted caves in northern Spain: La Garma, El Castillo, La Pasiega, Las Chimeneas and Tito Bustillo. The Arts and Humanities Research Council funded project was supported by Spanish colleagues Manuel Rojo-Guerra and Roberto Ontañon, with permission from the Gobierno de Cantabria and Gobierno Del Principado de Asturias.
Their methodology in recording the acoustics of these caves was to use a swept-sine (also called a chirp) source signal in conjunction with a set of microphones, adjusting the position of the set-up to provide an overview of the acoustics of specific sections of the caves. In each location that was measured, the position of imagery on the cave walls was also recorded. The fieldwork generated a large body of data that was used to generate acoustic maps of the five caves that could be compared with the distribution of the imagery (paintings or engravings, representational images of animals, or abstract symbols). A Principal Components Analysis (a mathematical method used to reduce a large data set into a smaller one while maintaining most of its variation information) provided an averaged set of acoustical characteristics. This showed that the variance of the acoustic data can be explained by two main components, associated with (a) temporal decay of energy (rate at which it fades to silence) in the cave space and (b) the existence or absence of resonance. Other factors, such as the distance of motifs from the original cave entrances (some of them now blocked) were also recorded.
Statistical analysis concluded that motifs in general, and lines and dots in particular, are statistically more likely to be found in places where reverberation is moderate and where the low frequency acoustic response has evidence of resonant behavior. The results suggest that the location of Palaeolithic motifs might indeed be associated with acoustic features, and that an appreciation of sound could have influenced behavior among Palaeolithic societies using these caves. The study also demonstrated the application of a systematic methodology of recording and analysis to the archaeoacoustics of prehistoric spaces.
9 notes
·
View notes
Last Seen Blogs

cherry-kisu
I'm a rockin' princess!

toughtofind-curiosities
ToughToFind-Curiosities

instability-the-manifesto
Instability

blogsypk
Untitled

marko-level
Marko LeveL