#Chatgpt To Create Image From Text
Text
lensa's Secrets To Building An Ai-enhanced Image Art Generator App

An AI Image Art Generator app uses artificial intelligence (AI) and machine learning algorithms to transform ordinary photos or images into stylized, artistic interpretations. These apps often offer a range of filters, effects, and editing tools that allow users to apply different styles and techniques to their images, such as watercolor, oil painting, sketching, and more.
Using these apps, users can quickly and easily create visually stunning images that look like hand-drawn or painted artwork without needing any artistic skills or expertise. AI Image Art Generator apps are increasingly popular, particularly among social media users and digital artists who want to enhance and showcase their visual content in a unique and creative way.
Develop An Ai Image Art Generator App Like Lensa:
Developing an AI Image Art Generator app like Lensa involves several steps and requires expertise in artificial intelligence, machine learning, and mobile app development. Here is an overview of the process:
1. Define the Requirements: The first step is to define the requirements and features of the app. You should determine the type of art styles you want to offer and how users will interact with the app.
2. Collect and Prepare the Data: You need a large dataset of images to train your AI model. The dataset should include images of different styles and genres. You will need to preprocess the data to remove noise, normalize the images, and extract features.
3. Train the AI Model: Once you have prepared the data, you need to train your AI model. You can use popular deep learning frameworks like TensorFlow or PyTorch to build and train the model. You should test and validate the model to ensure that it can generate high-quality art.
4. Develop the App: After training the AI model, you need to develop the mobile app. You can use popular mobile app development frameworks like React Native, Flutter, or Xamarin to build the app. You will need to integrate the AI model into the app and develop the user interface and user experience.
5. Test and Launch: Before launching the app, you should test it thoroughly to ensure that it works as expected and is bug-free. Once you have tested the app, you can launch it on app stores like the App Store or Google Play Store.
6. Maintain and Update: After launching the app, you need to maintain and update it regularly. You should fix any bugs and add new features based on user feedback.
How does an AI art generator app work?
An AI art generator app uses machine learning algorithms and neural networks to analyze and transform images into various artistic styles. Here is a general overview of how an AI art generator app works:
1. Preprocessing: The image is first preprocessed to enhance its quality and remove any noise or distortion.
2. Feature Extraction: The app uses convolutional neural networks (CNNs) to extract features from the image. The CNNs detect various patterns and structures in the image, such as edges, shapes, and colors.
3. Artistic Style Transfer: The app uses a technique called neural style transfer to transform the image into an artistic style. This involves using a pre-trained neural network that has learned the characteristics of a particular artistic style, such as Van Gogh's Starry Night or Monet's Water Lilies. The app then transfers these style characteristics onto the original image, resulting in a new image that combines the content of the original image with the style of the chosen artistic style.
4. Post-processing: The final image is then post-processed to refine the artistic style and enhance the overall visual quality.
There are several benefits of using AI image generators, such as:
I. Time-saving: Creating an artistic image from scratch can take hours, if not days, even for experienced artists. AI image generators can create similar images in a matter of seconds or minutes, saving time and effort.
II. Consistency: AI image generators can produce consistent results, unlike human artists who may produce different results even when working on the same image.
III. Accessibility: AI image generators can make the creation of artistic images accessible to a wider audience. People without any formal training or skills in art can use these apps to create beautiful images.
IV. Creativity: AI image generators can inspire creativity by allowing users to experiment with different styles and techniques. Users can explore new styles and push the boundaries of traditional art.
V. Efficiency: AI image generators can help businesses create visually appealing graphics and images for their products and services more efficiently. This can help reduce costs and increase productivity.
#Develop Ai Image Art Generator App#Ai Image Generator#Create Beautiful Pictures#Ai Image Generators#Ai Text-to-image Generators#Ai Generated Art#Image Creation#Ai Image Generator App#Create App Like Lensa#Chatgpt To Create Image From Text#Powerful Ai Image Generator App
0 notes
Text
Introduction
In our fast-paced world, time is a precious commodity. Whether you’re a student, professional, or entrepreneur, finding ways to streamline your daily tasks can significantly boost productivity. Enter ChatGPT, an AI language model that can assist you in automating various aspects of your work. In this article, we’ll explore nine ChatGPT prompts that can revolutionize the way you tackle your busy schedule.
1. Calendar Management
ChatGPT prompts: “Schedule a meeting for next Tuesday at 2 PM.”
ChatGPT can interact with your calendar application, whether it’s Google Calendar, Outlook, or any other platform. By providing clear instructions, you can effortlessly set up appointments, reminders, and events. Imagine the time saved when ChatGPT handles your scheduling!
2. Email Drafting
ChatGPT prompts: “Compose an email to my team about the upcoming project deadline.”
ChatGPT can draft professional emails, complete with subject lines, body text, and even attachments. Simply describe the purpose of the email, and let ChatGPT do the rest. It’s like having a virtual assistant dedicated to your inbox.
3. Code Generation
ChatGPT prompts: “Write a Python function that calculates Fibonacci numbers.”
Whether you’re a programmer or a student, ChatGPT can generate code snippets for various programming languages. From simple functions to complex algorithms, ChatGPT can save you hours of coding time.
4. Content Summarisation
ChatGPT prompts: “Summarise this 10-page research paper on climate change.”
Reading lengthy documents can be daunting. ChatGPT can analyse and condense large texts into concise summaries, allowing you to grasp essential information quickly.
5. Social Media Posts
ChatGPT prompts: “Create a tweet announcing our new product launch.”
Crafting engaging social media content is essential for businesses. ChatGPT can generate catchy posts for platforms like Twitter, LinkedIn, or Instagram, ensuring your message reaches your audience effectively.
6. Language Translation
ChatGPT prompts: “Translate this paragraph from English to Spanish.”
Whether you’re communicating with international clients or learning a new language, ChatGPT can provide accurate translations. Say goodbye to language barriers!
7. Data Analysis
ChatGPT prompts: “Analyse this sales dataset and identify trends.”
ChatGPT can process data, create visualisations, and extract insights. Whether it’s sales figures, customer behavior, or market trends, ChatGPT can help you make informed decisions.
8. Creative Writing
ChatGPT prompts: “Write a short story about time travel.”
Beyond practical tasks, ChatGPT can unleash creativity. From poems to fictional narratives, ChatGPT can be your muse when inspiration strikes.
9. Personalised Recommendations
ChatGPT prompts: “Suggest a book based on my interests in science fiction.”
ChatGPT can recommend books, movies, restaurants, or travel destinations tailored to your preferences. It’s like having a knowledgeable friend who knows your tastes.
Conclusion:
These nine ChatGPT prompts demonstrate its versatility. By integrating ChatGPT into your workflow, you can automate repetitive tasks, enhance communication, and free up valuable time. So, next time you’re swamped with work, turn to ChatGPT—it’s like having a digital assistant that works tirelessly to simplify your life.
In addition to ChatGPT, there are several other powerful AI tools designed to automate various tasks. Let’s explore some of them:
ACCELQ: A codeless AI-powered tool that seamlessly tests software across multiple channels (mobile, desktop, etc.). It offers continuous test automation and minimizes maintenance efforts1. You can find more information on their website.
Katalon: An AI tool for test automation that provides a complete solution for testing mobile applications and websites. It features a robust object repository, multi-language support, and efficient test results1. Check out Katalon’s website for details.
Selenium: An open-source AI tool for automating web and application testing. It’s commonly used for regression testing, functional testing, and performance testing1. You can explore more about Selenium on their official website.
Appium: Specifically designed for mobile app automation, Appium supports both Android and iOS platforms. It’s an excellent choice for mobile testing1.
Cypress: Known for its fast execution and real-time reloading, Cypress is an end-to-end testing framework for web applications. It provides a great developer experience1.
Parasoft: Offers comprehensive testing solutions, including static analysis, unit testing, and API testing. It’s widely used in the industry1.
Cucumber: A behavior-driven development (BDD) tool that allows collaboration between developers, testers, and non-technical stakeholders. It uses plain text specifications for test cases1.
TestNG: A testing framework inspired by JUnit and NUnit, TestNG supports parallel execution, data-driven testing, and test configuration flexibility1.
LambdaTest: A cloud-based cross-browser testing platform that allows you to test your web applications across various browsers and operating systems1.
Robot Framework: An open-source test automation framework that uses a keyword-driven approach. It’s highly extensible and supports both web and mobile testing1.
TestCraft: A codeless automation platform that integrates with popular tools like Selenium and Appium. It’s suitable for both manual and automated testing1.
Watir: A Ruby library for automating web browsers, Watir provides a simple and expressive syntax for testing web applications1.
Remember that each tool has its strengths and weaknesses, so choose the one that best fits your specific needs. Whether it’s testing, content creation, or workflow automation, these AI tools can significantly enhance your productivity and efficiency.
#generate-a-random-password#convert-a-pdf-to-a-text-file#create-a-qr-code-for-a-url#calculate-income-tax#convert-a-video-to-gif#extract-text-from-an-image#merge-multiple-pdf-files#generate-a-summary-of-a-long-text#find-duplicate-files-in-a-directory#ChatGPT prompts#Automate busy work#Blog writing workflow#Content creation#Keyword research#SEO optimization#Productivity hacks#Time-saving tools#Streamline workflow#9 ChatGPT Prompts to Automate Your Busy Work
0 notes
Note
got anything good, boss?
Sure do!
-
"Weeks after The New York Times updated its terms of service (TOS) to prohibit AI companies from scraping its articles and images to train AI models, it appears that the Times may be preparing to sue OpenAI. The result, experts speculate, could be devastating to OpenAI, including the destruction of ChatGPT's dataset and fines up to $150,000 per infringing piece of content.
NPR spoke to two people "with direct knowledge" who confirmed that the Times' lawyers were mulling whether a lawsuit might be necessary "to protect the intellectual property rights" of the Times' reporting.
Neither OpenAI nor the Times immediately responded to Ars' request to comment.
If the Times were to follow through and sue ChatGPT-maker OpenAI, NPR suggested that the lawsuit could become "the most high-profile" legal battle yet over copyright protection since ChatGPT's explosively popular launch. This speculation comes a month after Sarah Silverman joined other popular authors suing OpenAI over similar concerns, seeking to protect the copyright of their books.
Of course, ChatGPT isn't the only generative AI tool drawing legal challenges over copyright claims. In April, experts told Ars that image-generator Stable Diffusion could be a "legal earthquake" due to copyright concerns.
But OpenAI seems to be a prime target for early lawsuits, and NPR reported that OpenAI risks a federal judge ordering ChatGPT's entire data set to be completely rebuilt—if the Times successfully proves the company copied its content illegally and the court restricts OpenAI training models to only include explicitly authorized data. OpenAI could face huge fines for each piece of infringing content, dealing OpenAI a massive financial blow just months after The Washington Post reported that ChatGPT has begun shedding users, "shaking faith in AI revolution." Beyond that, a legal victory could trigger an avalanche of similar claims from other rights holders.
Unlike authors who appear most concerned about retaining the option to remove their books from OpenAI's training models, the Times has other concerns about AI tools like ChatGPT. NPR reported that a "top concern" is that ChatGPT could use The Times' content to become a "competitor" by "creating text that answers questions based on the original reporting and writing of the paper's staff."
As of this month, the Times' TOS prohibits any use of its content for "the development of any software program, including, but not limited to, training a machine learning or artificial intelligence (AI) system.""
-via Ars Technica, August 17, 2023
#Anonymous#ask#me#open ai#chatgpt#anti ai#ai writing#lawsuit#united states#copyright law#new york times#good news#hope
741 notes
·
View notes
Note
Your discussions on AI art have been really interesting and changed my mind on it quite a bit, so thank you for that! I don’t think I’m interested in using it, but I feel much less threatened by it in the same way. That being said, I was wondering, how you felt about AI generated creative writing: not, like AI writing in the context of garbage listicles or academic essays, but like, people who generate short stories and then submit them to contests. Do you think it’s the same sort of situation as AI art? Do you think there’s a difference in ChatGPT vs mid journey? Legitimate curiosity here! I don’t quite have an opinion on this in the same way, and I’ve seen v little from folks about creative writing in particular vs generated academic essays/articles
i think that ai generated writing is also indisputably writing but it is mostly really really fucking awful writing for the same reason that most ai art is not good art -- that the large training sets and low 'temperature' of commercially available/mass market models mean that anything produced will be the most generic version of itself. i also think that narrative writing is very very poorly suited to LLM generation because it generally requires very basic internal logic which LLMs are famously bad at (i imagine you'd have similar problems trying to create something visual like a comic that requires consistent character or location design rather than the singular images that AI art is mostly used for). i think it's going to be a very long time before we see anything good long-form from an LLM, especially because it's just not a priority for the people making them.
ultimately though i think you could absolutely do some really cool stuff with AI generated text if you had a tighter training set and let it get a bit wild with it. i've really enjoyed a lot of AI writing for being funny, especially when it was being done with tools like botnik that involve more human curation but still have the ability to completely blindside you with choices -- i unironically think the botnik collegehumour sketch is funnier than anything human-written on the channel. & i think that means it could reliably be used, with similar levels of curation, to make some stuff that feels alien, or unsettling, or etheral, or horrifying, because those are somewhat adjacent to the surreal humour i think it excels at. i could absolutely see it being used in workflows -- one of my friends told me recently, essentially, "if i'm stuck with writer's block, i ask chatgpt what should happen next, it gives me a horrible idea, and i immediately think 'that's shit, and i can do much better' and start writing again" -- which is both very funny but i think presents a great use case as a 'rubber duck'.
but yea i think that if there's anything good to be found in AI-written fiction or poetry it's not going to come from chatGPT specifically, it's going to come from some locally hosted GPT model trained on a curated set of influences -- and will have to either be kind of incoherent or heavily curated into coherence.
that said the submission of AI-written stories to short story mags & such fucking blows -- not because it's "not writing" but because it's just bad writing that's very very easy to produce (as in, 'just tell chatGPT 'write a short story'-easy) -- which ofc isn't bad in and of itself but means that the already existing phenomenon of people cynically submitting awful garbage to literary mags that doesn't even meet the submission guidelines has been magnified immensely and editors are finding it hard to keep up. i think part of believing that generative writing and art are legitimate mediums is also believing they are and should be treated as though they are separate mediums -- i don't think that there's no skill in these disciplines (like, if someone managed to make writing with chatGPT that wasnt unreadably bad, i would be very fucking impressed!) but they're deeply different skills to the traditional artforms and so imo should be in general judged, presented, published etc. separately.
212 notes
·
View notes
Text
Regardless of what companies and investors may say, artificial intelligence is not actually intelligent in the way most humans would understand it. To generate words and images, AI tools are trained on large databases of training data that is often scraped off the open web in unimaginably large quantities, no matter who owns it or what biases come along with it.
When a user then prompts ChatGPT or DALL-E to spit out some text or visuals, the tools aren’t thinking about the best way to represent those prompts because they don’t have that ability. They’re comparing the terms they’re presented with the patterns they formed from all the data that was ingested to train their models, then trying to assemble elements from that data to reflect what the user is looking for. In short, you can think of it like a more advanced form of autocorrect on your phone’s keyboard, predicting what you might want to say next based on what you’ve already written and typed out in the past.
If it’s not clear, that means these systems don’t create; they plagiarize. Unlike a human artist, they can’t develop a new artistic style or literary genre. They can only take what already exists and put elements of it together in a way that responds to the prompts they’re given. There’s good reason to be concerned about what that will mean for the art we consume, and the richness of the human experience.
[...]
AI tools will not eliminate human artists, regardless of what corporate executives might hope. But it will allow companies to churn out passable slop to serve up to audiences at a lower cost. In that way, it allows a further deskilling of art and devaluing of artists because instead of needing a human at the center of the creative process, companies can try to get computers to churn out something good enough, then bring in a human with no creative control and a lower fee to fix it up. As actor Keanu Reeves put it to Wired earlier this year, “there’s a corporatocracy behind [AI] that’s looking to control those things. … The people who are paying you for your art would rather not pay you. They’re actively seeking a way around you, because artists are tricky.”
To some degree, this is already happening. Actors and writers in Hollywood are on strike together for the first time in decades. That’s happening not just because of AI, but how the movie studios and steaming companies took advantage of the shift to digital technologies to completely remake the business model so workers would be paid less and have less creative input. Companies have already been using AI tools to assess scripts, and that’s one example of how further consolidation paired with new technologies are leading companies to prioritize “content” over art. The actors and writers worry that if they don’t fight now, those trends will continue — and that won’t just be bad for them, but for the rest of us too.
287 notes
·
View notes
Text
If you're going to come onto one of my posts to go off about 'people who are against AI are just like the people who were against the printing press and photography', please point me in the direction of your high school teachers because they obviously did not teach you the fallacy of arguing Apples to Oranges.
The upper-classes were against printing presses because they were trying to gatekeep knowledge, particularly Theological knowledge, against the working class. That's also the reason why most Christian texts were written in Latin.
That is completely different from things like ChatGPT scraping TeachersPayTeachers to create 'lesson plans' or stealing from fanfiction and indie-published writing to churn out AI-written 'novels'.
Those who were originally against photography thought it was trying replace painters due to them not understanding that plenty of schooling and training goes into mastering lighting, angle, tone, aperture, temperature, lenses, modeling, subject-study, composition, editing, and more. That is not the same as being upset at the people behind Midjourney et al admitting that their algorithms (because, let's face it, for as much as the public has latched onto calling these programs 'Artificial Intelligence', they're closer to 'Algorithmic Intuition') use 'publicly available images'.
I.e.: Anything that's been posted online, creators' rights be damned.
Don't try to sing me a song of sixpence. You do not have enough rye in your pockets to do so.
#if anyone was wondering about the context behind this#someone sent in an ask about some AI bro reblogging one of my anti-AI posts#but anytime I try to go to that blog nothing pops up#so it's like 'okay you want to talk shit but I can't talk back; lol okay'
93 notes
·
View notes
Text
The Body Swap Bot Pt.1
The proliferation of AI had unlocked a wealth of chatbots and image generators, but beyond that they didn't have much use yet. However, that didn't mean that some clever inventors hadn't figured out how to take those chatbots to the next level. Enter the Body Swap Bot.
You had been playing around with ChatGPT for a couple hours now, having it come up with meal plans and asking it obscure questions. But it's novelty had started to ware off. You turned to Google to see if you could find a different chatbot that might provide you with more fun. You scrolled through the search results seeing virtual assistants, essay writers, and then finally you came across the Body Swap Bot. That could be fun you thought, and harmless.
You open it and it asks you to create and account. You type in a random email hoping it still works and luckily it does. A black screen with white text shows up. Three questions show up on the screen.
- Would you like a man's or a woman's body?
- What continent do you want your body to be located in?
- How old so you want your body to be?
You decided to play along typing man for the first question. For the second question you entered Europe, you'd never been and why not pretend you were actually from there. Finally you said you wanted your body to be in its 20s, just like you currently were. You hit enter and the Bot starts typing back.
- Good. Now I will give you the first candidate for your body swap.
- "Stefan Lofving" a 23 year old tall, athletic and handsome Swedish man with blonde hair, blue eye and a charming smile. He is the youngest child of a wealthy family with a big real estate business. Most of his time he is in the gym or playing tennis with his friends.
The Bot tries to generate an image of your new body but it doesn't even seem to resemble a person. You chuckled at how low quality the whole thing seemed. The Bot started typing again.
- Okay, please confirm that you want to swap with "Stefan".
You typed "I confirm". Suddenly you were no longer sitting in your room. You looked around you and realized you were in the middle of some town you didn't recognize. Looking at the signs on the buildings at first you didn't recongize the words but the meaning seemed to appear in your head. Had the Bot really swapped your body? You tapped your pockets until you found a phone, it unlocked with facial recognition. The whole thing seemed to be in Swedish but that wasn't a problem for you anymore. You manage to get back the Bot. It asks for an account. Damn you used a throwaway email that you couldn't remember. You create a new account and try working through the questions over and over again rejecting each candidate hoping you'd see your body come up.
After several hours you resigned yourself that you might be stuck like this. It could be worse you thought. At least now you are Stefan the sexy, athletic Swedish guy with blonde hair, blue eyes, a friendly smile and a muscular chest and abs!

142 notes
·
View notes
Text
On the subject of generative AI
Let me start with an apology for deviating from the usual content, and for the wall of text ahead of you. Hopefully, it'll be informative, instructive, and thought-provoking.
A couple days ago I released a hastily put-together preset collection as an experiment in 3 aspects of ReShade and virtual photography: MultiLUT to provide a fast, consistent tone to the rendered image, StageDepth for layered textures at different distances, and tone-matching (something that I discussed recently).
For the frames themselves, I used generative AI to create mood boards and provide the visual elements that I later post-processed to create the transparent layers, and worked on creating cohesive LUTs to match the overall tone. As a result, some expressed disappointment and disgust.
So let's talk about it.
The concerns of anti-AI groups are significant and must not be overlooked. Fear, which is often justified, serves as a palpable common denominator. While technology is involved, my opinion is that our main concern should be on how companies could misuse it and exclude those most directly affected by decision-making processes.
Throughout history, concerns about technological disruption have been recurring themes, as I can attest from personal experience. Every innovation wave, from typewriters to microcomputers to the shift from analog to digital photography, caused worries about job security and creative control. Astonishingly, even the concept of “Control+Z” (undo) in digital art once drew criticism, with some artists lamenting, “Now you can’t own your mistakes.”
Yet, despite initial misgivings and hurdles, these technological advancements have ultimately democratized creative tools, facilitating the widespread adoption of digital photography and design, among other fields.
The history of technology’s disruptive impact is paralleled by its evolution into a democratizing force. Take, for instance, the personal computer: a once-tremendous disruptor that now resides in our pockets, bags, and homes. These devices have empowered modern-day professionals to participate in a global economy and transformed the way we conduct business, pursue education, access entertainment, and communicate with one another.
Labor resistance to technological change has often culminated in defeat. An illustrative example brought up in this NYT article unfolded in 1986 when Rupert Murdoch relocated newspaper production from Fleet Street to a modern facility, leading to the abrupt dismissal of 6,000 workers. Instead of negotiating a gradual transition with worker support, the union’s absolute resistance to the technological change resulted in a loss with no compensation, underscoring the importance of strategic adaptation.
Surprisingly, the Writers Guild of America (W.G.A.) took a different approach when confronted with AI tools like ChatGPT. Rather than seeking an outright ban, they aimed to ensure that if AI was used to enhance writers’ productivity or quality, then guild members would receive a fair share of the benefits. Their efforts bore fruit, providing a promising model for other professional associations.
The crucial insight from these historical instances is that a thorough understanding of technology and strategic action can empower professionals to shape their future. In the current context, addressing AI-related concerns necessitates embracing knowledge, dispelling unwarranted fears, and arriving at negotiation tables equipped with informed decisions.
It's essential to develop and use AI in a responsible and ethical manner; developing safeguards against potential harm is necessary. It is important to have open and transparent conversations about the potential benefits and risks of AI.
Involving workers and other stakeholders in the decision-making process around AI development and deployment is a way to do this. The goal is to make sure AI benefits everyone and not just a chosen few.
While advocates for an outright ban on AI may have the best interests of fellow creatives in mind, unity and informed collaboration among those affected hold the key to ensuring a meaningful future where professionals are fairly compensated for their work. By excluding themselves from the discussion and ostracizing others who share most of their values and goals, they end up weakening chances of meaningful change; we need to understand the technology, its possibilities, and how it can be steered toward benefitting those they source from. And that involves practical experimentation, too.
Carl Sagan, in his book 'The Demon-Haunted World: Science as a Candle in the Dark', said:
"I have a foreboding […] when the United States is a service and information economy; when nearly all the manufacturing industries have slipped away to other countries; when awesome technological powers are in the hands of a very few, and no one representing the public interest can even grasp the issues; when the people have lost the ability to set their own agendas or knowledgeably question those in authority; when, clutching our crystals and nervously consulting our horoscopes, our critical faculties in decline, unable to distinguish between what feels good and what's true, we slide, almost without noticing, back into superstition and darkness."
In a more personal tone, I'm proud to be married to a wonderful woman - an artist who has her physical artwork in all 50 US states, and several pieces sold around the world. For the last few years she has been studying and adapting her knowledge from analog to digital art, a fact that deeply inspired me to translate real photography practices to the virtual world of Eorzea. In the last months, she has been digging deep into generative AI in order to understand not only how it'll impact her professional life, but also how it can merge with her knowledge so it can enrich and benefit her art; this effort gives her the necessary clarity to voice her concerns, make her own choices and set her own agenda.
I wish more people could see how useful her willingness and courage to dive into new technologies in order to understand their impact could be to help shape their own futures.
By comprehending AI and adopting a collective approach, we can transform the current challenges into opportunities. The democratization and responsible utilization of AI can herald a brighter future, where technology becomes a tool for empowerment and unity prevails over division.
And now, let's go back to posting about pretty things.
102 notes
·
View notes
Text
Since sharing this post about a usful AI used to compile and graph research papers, I've realised I have a few other resources I can share with people!
Note: I haven't had a chance to use every single one of these. A group of post-grad students has been slowly compiling an online list, and these are some I've picked out that are free (or should be free and also have paid versions). However, other students using them have all verified them as safe.
Inciteful (Using Citations to Explore Academic Literature | Inciteful.xyz) – similar to connectedpapers + researchrabbit. Also allows you to connect two papers and see how they are linked. Currently free.
Spinbot (Spinbot - Article Spinning, Text Rewriting, Content Creation Tool.) – article spinner + paraphraser. Useful for difficult articles/papers. Currently free (ad version).
Elicit (Elicit: The AI Research Assistant) – AI research assistant, creates workflow. Mainly for lit reviews. Finds relevant papers, summarises + analyses them, finds criticism of them. Free (?)
Natural Reader (AI Voices - NaturalReader Home (naturalreaders.com)) – text to speech. Native speakers. Usually pretty reliable, grain of salt. Free + paid versions.
Otter AI (Otter.ai - Voice Meeting Notes & Real-time Transcription) – takes notes and transcribes video calls. Pretty accurate. Warn people Otter is entering call or it is terrifying. Free + paid versions.
Paper Panda (🐼 PaperPanda — Access millions of research papers in one click) – get research papers free. Chrome extension. Free.
Docsity (About us - Docsity Corporate) – get documents from university students globally. Useful for notes.
Desmos (Desmos | Let's learn together.) – online free graphing calculator. Free (?)
Core (CORE – Aggregating the world’s open access research papers) – open access research paper aggregation.
Writefull (Writefull X: AI applied to academic writing) – Academic AI. Paraphrasing, title generator, abstract generator, apparently ChatGPT detector now. Free.
Photopea (Photopea | Online Photo Editor) – Photoshop copy but run free and online. Same tools. Free.
Draw IO (Flowchart Maker & Online Diagram Software) – Flowchart/diagram maker. Free + paid versions.
Weava (Weava Highlighter - Free Research Tool for PDFs & Webpages (weavatools.com)) – Highlight + annotate webpages and pdfs. Free + paid versions.
Unsplash (Beautiful Free Images & Pictures | Unsplash) – free to use images.
Storyset (Storyset | Customize, animate and download illustration for free) – open source illustrations. Free.
Undraw (unDraw - Open source illustrations for any idea) – open source illustrations. Free.
8mb Video (8mb.video: online compressor FREE) – video compression (to under 8mb). Free.
Just Beam It (JustBeamIt - file transfer made easy) – basically airdrop files quickly and easily between devices. Free.
Jimpl (Online photo metadata and EXIF data viewer | Jimpl) – upload photos to see metadata. Can also remove metadata from images to obscure sensitive information. Free.
TL Draw (tldraw) – web drawing application. Free.
Have I Been Pwned (Have I Been Pwned: Check if your email has been compromised in a data breach) – lets you know if information has been taken in a data breach. If so, change passwords. Free.
If you guys have any feedback about these sites (good or bad), feel free to add on in reblogs or flick me a message and I can add! Same thing with any broken links or additions.
203 notes
·
View notes
Text
"I miss when AI was bad" is a sentiment I've been seeing floating around a lot lately, and it's one that I...half agree with, but I must point out-
AI is still "bad".
Sure, there are some pretty beginner-friendly models out there now, like Midjourney, that make it easy to get...something appealing on first glance pretty quickly with minimal skill or even luck, but contrary to corporate claims, no, you CAN'T just get them to pump out an entire passable novel with as little as "hey computer give me a 50k word lesbian space western" or even less "dear ChatGPT, please write me the next great classic show that will appeal to everyone and make me eleventy trillion dollars, love, Netflix". No, there is no Secret Professional Paid Model that makes this possible, either.
The work that goes into making something Good(TM) using AI is being very deliberately hidden from anyone who isn't using it to see for themselves that there is Work and Skill involved, because companies like OpenAI want people like the CEOs of AMPTP member companies to think it's that easy, because they're big money potential clients.
Furthermore, all these companies want you to think it's as easy as that shit on Black Mirror (whether they know it's a lie or not - they don't care either way), because they know that if you think that, eventually you'll wear down and watch their shit once they're the only new releases...and you will think nothing of the fact that the human labor is being erased, because, psh, human labor? What human labor? There definitely isn't a cubicle farm full of living humans being crunched even harder than they did with traditional methods to churn these things out, it's all the robot's doing, right?
I mean, hell, we keep complaining about ChatGPT essays full of hallucinated information; samey, dry novels and fanfics that can't keep their plots straight; and picture books that are full of glaring errors and can barely even keep the characters recognizable from page to page, and I just think-

So you agree? Creating a coherent, accurate, and/or meaningful image or piece of writing with AI involves creativity, knowledge, skill, and patience?
...in my honest opinion, those garbage-quality cash- and/or clout-grab pieces have an important role in the tech and art and media ecosystem: to remind people that this IS, in fact, the best that can reliably come from the minimal skill and effort that the companies are saying you can make masterpieces with.
What I'm saying is...I don't miss when AI Was Bad, because that era never ended.
I miss when AI was widely recognized as being bad. I miss when everyone knew that getting the image you wanted from a simple text prompt was something like winning the lottery. I miss when people not only appreciated the surreality of the shitposts and more that we made with it, but were broadly aware that most first iterations resemble those shitposts.
I miss before the Silicon Valley ghouls managed to convince people en masse that they'd created True AI that could actually viably replace creatives with no human input. I miss before the corporate media suckers bought that lie hook line and sinker, or at least found it convenient to pretend to believe because it would let them move more work to lower pay grades with the only backlash being about the conventional work getting replaced that they hope they can wait out, but NOT about the mistreatment and underpayment of the new workers, because the public will broadly think there ARE no new workers. I miss before it became an infohazard because corporations want you to think their software knows everything - and have successfully convinced several big name companies of this, or at least that they're close enough to all-knowing to replace search engines.
I miss when we were in the "roll out toys as proof of concept" era, not the "well, we've sunk enough money into running these things for the plebs, time to yank the rug and start lying to get some big money clients" era.
78 notes
·
View notes
Text
Generative AI for Dummies
(kinda. sorta? we're talking about one type and hand-waving some specifics because this is a tumblr post but shh it's fine.)
So there’s a lot of misinformation going around on what generative AI is doing and how it works. I’d seen some of this in some fandom stuff, semi-jokingly snarked that I was going to make a post on how this stuff actually works, and then some people went “o shit, for real?”
So we’re doing this!
This post is meant to just be a very basic breakdown for anyone who has no background in AI or machine learning. I did my best to simplify things and give good analogies for the stuff that’s a little more complicated, but feel free to let me know if there’s anything that needs further clarification. Also a quick disclaimer: as this was specifically inspired by some misconceptions I’d seen in regards to fandom and fanfic, this post focuses on text-based generative AI.
This post is a little long. Since it sucks to read long stuff on tumblr, I’ve broken this post up into four sections to put in new reblogs under readmores to try to make it a little more manageable. Sections 1-3 are the ‘how it works’ breakdowns (and ~4.5k words total). The final 3 sections are mostly to address some specific misconceptions that I’ve seen going around and are roughly ~1k each.
Section Breakdown:
1. Explaining tokens
2. Large Language Models
3. LLM Interfaces
4. AO3 and Generative AI [here]
5. Fic and ChatGPT [here]
6. Some Closing Notes [here]
[post tag]
First, to explain some terms in this:
“Generative AI” is a category of AI that refers to the type of machine learning that can produce strings of text, images, etc. Text-based generative AI is powered by large language models called LLM for short.
(*Generative AI for other media sometimes use a LLM modified for a specific media, some use different model types like diffusion models -- anyways, this is why I emphasized I’m talking about text-based generative AI in this post. Some of this post still applies to those, but I’m not covering what nor their specifics here.)
“Neural networks” (NN) are the artificial ‘brains’ of AI. For a simplified overview of NNs, they hold layers of neurons and each neuron has a numerical value associated with it called a bias. The connection channels between each neuron are called weights. Each neuron takes the sum of the input weights, adds its bias value, and passes this sum through an activation function to produce an output value, which is then passed on to the next layer of neurons as a new input for them, and that process repeats until it reaches the final layer and produces an output response.
“Parameters” is a…broad and slightly vague term. Parameters refer to both the biases and weights of a neural network. But they also encapsulate the relationships between them, not just the literal structure of a NN. I don’t know how to explain this further without explaining more about how NN’s are trained, but that’s not really important for our purposes? All you need to know here is that parameters determine the behavior of a model, and the size of a LLM is described by how many parameters it has.
There’s 3 different types of learning neural networks do: “unsupervised” which is when the NN learns from unlabeled data, “supervised” is when all the data has been labeled and categorized as input-output pairs (ie the data input has a specific output associated with it, and the goal is for the NN to pick up those specific patterns), and “semi-supervised” (or “weak supervision”) combines a small set of labeled data with a large set of unlabeled data.
For this post, an “interaction” with a LLM refers to when a LLM is given an input query/prompt and the LLM returns an output response. A new interaction begins when a LLM is given a new input query.
Tokens
Tokens are the ‘language’ of LLMs. How exactly tokens are created/broken down and classified during the tokenization process doesn’t really matter here. Very broadly, tokens represent words, but note that it’s not a 1-to-1 thing -- tokens can represent anything from a fraction of a word to an entire phrase, it depends on the context of how the token was created. Tokens also represent specific characters, punctuation, etc.
“Token limitation” refers to the maximum number of tokens a LLM can process in one interaction. I’ll explain more on this later, but note that this limitation includes the number of tokens in the input prompt and output response. How many tokens a LLM can process in one interaction depends on the model, but there’s two big things that determine this limit: computation processing requirements (1) and error propagation (2). Both of which sound kinda scary, but it’s pretty simple actually:
(1) This is the amount of tokens a LLM can produce/process versus the amount of computer power it takes to generate/process them. The relationship is a quadratic function and for those of you who don’t like math, think of it this way:
Let’s say it costs a penny to generate the first 500 tokens. But it then costs 2 pennies to generate the next 500 tokens. And 4 pennies to generate the next 500 tokens after that. I’m making up values for this, but you can see how it’s costing more money to create the same amount of successive tokens (or alternatively, that each succeeding penny buys you fewer and fewer tokens). Eventually the amount of money it costs to produce the next token is too costly -- so any interactions that go over the token limitation will result in a non-responsive LLM. The processing power available and its related cost also vary between models and what sort of hardware they have available.
(2) Each generated token also comes with an error value. This is a very small value per individual token, but it accumulates over the course of the response.
What that means is: the first token produced has an associated error value. This error value is factored into the generation of the second token (note that it’s still very small at this time and doesn’t affect the second token much). However, this error value for the first token then also carries over and combines with the second token’s error value, which affects the generation of the third token and again carries over to and merges with the third token’s error value, and so forth. This combined error value eventually grows too high and the LLM can’t accurately produce the next token.
I’m kinda breezing through this explanation because how the math for non-linear error propagation exactly works doesn’t really matter for our purposes. The main takeaway from this is that there is a point at which a LLM’s response gets too long and it begins to break down. (This breakdown can look like the LLM producing something that sounds really weird/odd/stale, or just straight up producing gibberish.)
Large Language Models (LLMs)
LLMs are computerized language models. They generate responses by assessing the given input prompt and then spitting out the first token. Then based on the prompt and that first token, it determines the next token. Based on the prompt and first token, second token, and their combination, it makes the third token. And so forth. They just write an output response one token at a time. Some examples of LLMs include the GPT series from OpenAI, LLaMA from Meta, and PaLM 2 from Google.
So, a few things about LLMs:
These things are really, really, really big. The bigger they are, the more they can do. The GPT series are some of the big boys amongst these (GPT-3 is 175 billion parameters; GPT-4 actually isn’t listed, but it’s at least 500 billion parameters, possibly 1 trillion). LLaMA is 65 billion parameters. There are several smaller ones in the range of like, 15-20 billion parameters and a small handful of even smaller ones (these are usually either older/early stage LLMs or LLMs trained for more personalized/individual project things, LLMs just start getting limited in application at that size). There are more LLMs of varying sizes (you can find the list on Wikipedia), but those give an example of the size distribution when it comes to these things.
However, the number of parameters is not the only thing that distinguishes the quality of a LLM. The size of its training data also matters. GPT-3 was trained on 300 billion tokens. LLaMA was trained on 1.4 trillion tokens. So even though LLaMA has less than half the number of parameters GPT-3 has, it’s still considered to be a superior model compared to GPT-3 due to the size of its training data.
So this brings me to LLM training, which has 4 stages to it. The first stage is pre-training and this is where almost all of the computational work happens (it’s like, 99% percent of the training process). It is the most expensive stage of training, usually a few million dollars, and requires the most power. This is the stage where the LLM is trained on a lot of raw internet data (low quality, large quantity data). This data isn’t sorted or labeled in any way, it’s just tokenized and divided up into batches (called epochs) to run through the LLM (note: this is unsupervised learning).
How exactly the pre-training works doesn’t really matter for this post? The key points to take away here are: it takes a lot of hardware, a lot of time, a lot of money, and a lot of data. So it’s pretty common for companies like OpenAI to train these LLMs and then license out their services to people to fine-tune them for their own AI applications (more on this in the next section). Also, LLMs don’t actually “know” anything in general, but at this stage in particular, they are really just trying to mimic human language (or rather what they were trained to recognize as human language).
To help illustrate what this base LLM ‘intelligence’ looks like, there’s a thought exercise called the octopus test. In this scenario, two people (A & B) live alone on deserted islands, but can communicate with each other via text messages using a trans-oceanic cable. A hyper-intelligent octopus listens in on their conversations and after it learns A & B’s conversation patterns, it decides observation isn’t enough and cuts the line so that it can talk to A itself by impersonating B. So the thought exercise is this: At what level of conversation does A realize they’re not actually talking to B?
In theory, if A and the octopus stay in casual conversation (ie “Hi, how are you?” “Doing good! Ate some coconuts and stared at some waves, how about you?” “Nothing so exciting, but I’m about to go find some nuts.” “Sounds nice, have a good day!” “You too, talk to you tomorrow!”), there’s no reason for A to ever suspect or realize that they’re not actually talking to B because the octopus can mimic conversation perfectly and there’s no further evidence to cause suspicion.
However, what if A asks B what the weather is like on B’s island because A’s trying to determine if they should forage food today or save it for tomorrow? The octopus has zero understanding of what weather is because its never experienced it before. The octopus can only make guesses on how B might respond because it has no understanding of the context. It’s not clear yet if A would notice that they’re no longer talking to B -- maybe the octopus guesses correctly and A has no reason to believe they aren’t talking to B. Or maybe the octopus guessed wrong, but its guess wasn’t so wrong that A doesn’t reason that maybe B just doesn’t understand meteorology. Or maybe the octopus’s guess was so wrong that there was no way for A not to realize they’re no longer talking to B.
Another proposed scenario is that A’s found some delicious coconuts on their island and decide they want to share some with B, so A decides to build a catapult to send some coconuts to B. But when A tries to share their plans with B and ask for B’s opinions, the octopus can’t respond. This is a knowledge-intensive task -- even if the octopus understood what a catapult was, it’s also missing knowledge of B’s island and suggestions on things like where to aim. The octopus can avoid A’s questions or respond with total nonsense, but in either scenario, A realizes that they are no longer talking to B because the octopus doesn’t understand enough to simulate B’s response.
There are other scenarios in this thought exercise, but those cover three bases for LLM ‘intelligence’ pretty well: they can mimic general writing patterns pretty well, they can kind of handle very basic knowledge tasks, and they are very bad at knowledge-intensive tasks.
Now, as a note, the octopus test is not intended to be a measure of how the octopus fools A or any measure of ‘intelligence’ in the octopus, but rather show what the “octopus” (the LLM) might be missing in its inputs to provide good responses. Which brings us to the final 1% of training, the fine-tuning stages;
LLM Interfaces
As mentioned previously, LLMs only mimic language and have some key issues that need to be addressed:
LLM base models don’t like to answer questions nor do it well.
LLMs have token limitations. There’s a limit to how much input they can take in vs how long of a response they can return.
LLMs have no memory. They cannot retain the context or history of a conversation on their own.
LLMs are very bad at knowledge-intensive tasks. They need extra context and input to manage these.
However, there’s a limit to how much you can train a LLM. The specifics behind this don’t really matter so uh… *handwaves* very generally, it’s a matter of diminishing returns. You can get close to the end goal but you can never actually reach it, and you hit a point where you’re putting in a lot of work for little to no change. There’s also some other issues that pop up with too much training, but we don’t need to get into those.
You can still further refine models from the pre-training stage to overcome these inherent issues in LLM base models -- Vicuna-13b is an example of this (I think? Pretty sure? Someone fact check me on this lol).
(Vicuna-13b, side-note, is an open source chatbot model that was fine-tuned from the LLaMA model using conversation data from ShareGPT. It was developed by LMSYS, a research group founded by students and professors from UC Berkeley, UCSD, and CMU. Because so much information about how models are trained and developed is closed-source, hidden, or otherwise obscured, they research LLMs and develop their models specifically to release that research for the benefit of public knowledge, learning, and understanding.)
Back to my point, you can still refine and fine-tune LLM base models directly. However, by about the time GPT-2 was released, people had realized that the base models really like to complete documents and that they’re already really good at this even without further fine-tuning. So long as they gave the model a prompt that was formatted as a ‘document’ with enough background information alongside the desired input question, the model would answer the question by ‘finishing’ the document. This opened up an entire new branch in LLM development where instead of trying to coach the LLMs into performing tasks that weren’t native to their capabilities, they focused on ways to deliver information to the models in a way that took advantage of what they were already good at.
This is where LLM interfaces come in.
LLM interfaces (which I sometimes just refer to as “AI” or “AI interface” below; I’ve also seen people refer to these as “assistants”) are developed and fine-tuned for specific applications to act as a bridge between a user and a LLM and transform any query from the user into a viable input prompt for the LLM. Examples of these would be OpenAI’s ChatGPT and Google’s Bard. One of the key benefits to developing an AI interface is their adaptability, as rather than needing to restart the fine-tuning process for a LLM with every base update, an AI interface fine-tuned for one LLM engine can be refitted to an updated version or even a new LLM engine with minimal to no additional work. Take ChatGPT as an example -- when GPT-4 was released, OpenAI didn’t have to train or develop a new chat bot model fine-tuned specifically from GPT-4. They just ‘plugged in’ the already fine-tuned ChatGPT interface to the new GPT model. Even now, ChatGPT can submit prompts to either the GPT-3.5 or GPT-4 LLM engines depending on the user’s payment plan, rather than being two separate chat bots.
As I mentioned previously, LLMs have some inherent problems such as token limitations, no memory, and the inability to handle knowledge-intensive tasks. However, an input prompt that includes conversation history, extra context relevant to the user’s query, and instructions on how to deliver the response will result in a good quality response from the base LLM model. This is what I mean when I say an interface transforms a user’s query into a viable prompt -- rather than the user having to come up with all this extra info and formatting it into a proper document for the LLM to complete, the AI interface handles those responsibilities.
How exactly these interfaces do that varies from application to application. It really depends on what type of task the developers are trying to fine-tune the application for. There’s also a host of APIs that can be incorporated into these interfaces to customize user experience (such as APIs that identify inappropriate content and kill a user’s query, to APIs that allow users to speak a command or upload image prompts, stuff like that). However, some tasks are pretty consistent across each application, so let’s talk about a few of those:
Token management
As I said earlier, each LLM has a token limit per interaction and this token limitation includes both the input query and the output response.
The input prompt an interface delivers to a LLM can include a lot of things: the user’s query (obviously), but also extra information relevant to the query, conversation history, instructions on how to deliver its response (such as the tone, style, or ‘persona’ of the response), etc. How much extra information the interface pulls to include in the input prompt depends on the desired length of an output response and what sort of information pulled for the input prompt is prioritized by the application varies depending on what task it was developed for. (For example, a chatbot application would likely allocate more tokens to conversation history and output response length as compared to a program like Sudowrite* which probably prioritizes additional (context) content from the document over previous suggestions and the lengths of the output responses are much more restrained.)
(*Sudowrite is…kind of weird in how they list their program information. I’m 97% sure it’s a writer assistant interface that keys into the GPT series, but uhh…I might be wrong? Please don’t hold it against me if I am lol.)
Anyways, how the interface allocates tokens is generally determined by trial-and-error depending on what sort of end application the developer is aiming for and the token limit(s) their LLM engine(s) have.
tl;dr -- all LLMs have interaction token limits, the AI manages them so the user doesn’t have to.
Simulating short-term memory
LLMs have no memory. As far as they figure, every new query is a brand new start. So if you want to build on previous prompts and responses, you have to deliver the previous conversation to the LLM along with your new prompt.
AI interfaces do this for you by managing what’s called a ‘context window’. A context window is the amount of previous conversation history it saves and passes on to the LLM with a new query. How long a context window is and how it’s managed varies from application to application. Different token limits between different LLMs is the biggest restriction for how many tokens an AI can allocate to the context window. The most basic way of managing a context window is discarding context over the token limit on a first in, first out basis. However, some applications also have ways of stripping out extraneous parts of the context window to condense the conversation history, which lets them simulate a longer context window even if the amount of allocated tokens hasn’t changed.
Augmented context retrieval
Remember how I said earlier that LLMs are really bad at knowledge-intensive tasks? Augmented context retrieval is how people “inject knowledge” into LLMs.
Very basically, the user submits a query to the AI. The AI identifies keywords in that query, then runs those keywords through a secondary knowledge corpus and pulls up additional information relevant to those keywords, then delivers that information along with the user’s query as an input prompt to the LLM. The LLM can then process this extra info with the prompt and deliver a more useful/reliable response.
Also, very importantly: “knowledge-intensive” does not refer to higher level or complex thinking. Knowledge-intensive refers to something that requires a lot of background knowledge or context. Here’s an analogy for how LLMs handle knowledge-intensive tasks:
A friend tells you about a book you haven’t read, then you try to write a synopsis of it based on just what your friend told you about that book (see: every high school literature class). You’re most likely going to struggle to write that summary based solely on what your friend told you, because you don’t actually know what the book is about.
This is an example of a knowledge intensive task: to write a good summary on a book, you need to have actually read the book. In this analogy, augmented context retrieval would be the equivalent of you reading a few book reports and the wikipedia page for the book before writing the summary -- you still don’t know the book, but you have some good sources to reference to help you write a summary for it anyways.
This is also why it’s important to fact check a LLM’s responses, no matter how much the developers have fine-tuned their accuracy.
(*Sidenote, while AI does save previous conversation responses and use those to fine-tune models or sometimes even deliver as a part of a future input query, that’s not…really augmented context retrieval? The secondary knowledge corpus used for augmented context retrieval is…not exactly static, you can update and add to the knowledge corpus, but it’s a relatively fixed set of curated and verified data. The retrieval process for saved past responses isn’t dissimilar to augmented context retrieval, but it’s typically stored and handled separately.)
So, those are a few tasks LLM interfaces can manage to improve LLM responses and user experience. There’s other things they can manage or incorporate into their framework, this is by no means an exhaustive or even thorough list of what they can do. But moving on, let’s talk about ways to fine-tune AI. The exact hows aren't super necessary for our purposes, so very briefly;
Supervised fine-tuning
As a quick reminder, supervised learning means that the training data is labeled. In the case for this stage, the AI is given data with inputs that have specific outputs. The goal here is to coach the AI into delivering responses in specific ways to a specific degree of quality. When the AI starts recognizing the patterns in the training data, it can apply those patterns to future user inputs (AI is really good at pattern recognition, so this is taking advantage of that skill to apply it to native tasks AI is not as good at handling).
As a note, some models stop their training here (for example, Vicuna-13b stopped its training here). However there’s another two steps people can take to refine AI even further (as a note, they are listed separately but they go hand-in-hand);
Reward modeling
To improve the quality of LLM responses, people develop reward models to encourage the AIs to seek higher quality responses and avoid low quality responses during reinforcement learning. This explanation makes the AI sound like it’s a dog being trained with treats -- it’s not like that, don’t fall into AI anthropomorphism. Rating values just are applied to LLM responses and the AI is coded to try to get a high score for future responses.
For a very basic overview of reward modeling: given a specific set of data, the LLM generates a bunch of responses that are then given quality ratings by humans. The AI rates all of those responses on its own as well. Then using the human labeled data as the ‘ground truth’, the developers have the AI compare its ratings to the humans’ ratings using a loss function and adjust its parameters accordingly. Given enough data and training, the AI can begin to identify patterns and rate future responses from the LLM on its own (this process is basically the same way neural networks are trained in the pre-training stage).
On its own, reward modeling is not very useful. However, it becomes very useful for the next stage;
Reinforcement learning
So, the AI now has a reward model. That model is now fixed and will no longer change. Now the AI runs a bunch of prompts and generates a bunch of responses that it then rates based on its new reward model. Pathways that led to higher rated responses are given higher weights, pathways that led to lower rated responses are minimized. Again, I’m kind of breezing through the explanation for this because the exact how doesn’t really matter, but this is another way AI is coached to deliver certain types of responses.
You might’ve heard of the term reinforcement learning from human feedback (or RLHF for short) in regards to reward modeling and reinforcement learning because this is how ChatGPT developed its reward model. Users rated the AI’s responses and (after going through a group of moderators to check for outliers, trolls, and relevancy), these ratings were saved as the ‘ground truth’ data for the AI to adjust its own response ratings to. Part of why this made the news is because this method of developing reward model data worked way better than people expected it to. One of the key benefits was that even beyond checking for knowledge accuracy, this also helped fine-tune how that knowledge is delivered (ie two responses can contain the same information, but one could still be rated over another based on its wording).
As a quick side note, this stage can also be very prone to human bias. For example, the researchers rating ChatGPT’s responses favored lengthier explanations, so ChatGPT is now biased to delivering lengthier responses to queries. Just something to keep in mind.
So, something that’s really important to understand from these fine-tuning stages and for AI in general is how much of the AI’s capabilities are human regulated and monitored. AI is not continuously learning. The models are pre-trained to mimic human language patterns based on a set chunk of data and that learning stops after the pre-training stage is completed and the model is released. Any data incorporated during the fine-tuning stages for AI is humans guiding and coaching it to deliver preferred responses. A finished reward model is just as static as a LLM and its human biases echo through the reinforced learning stage.
People tend to assume that if something is human-like, it must be due to deeper human reasoning. But this AI anthropomorphism is…really bad. Consequences range from the term “AI hallucination” (which is defined as “when the AI says something false but thinks it is true,” except that is an absolute bullshit concept because AI doesn’t know what truth is), all the way to the (usually highly underpaid) human labor maintaining the “human-like” aspects of AI getting ignored and swept under the rug of anthropomorphization. I’m trying not to get into my personal opinions here so I’ll leave this at that, but if there’s any one thing I want people to take away from this monster of a post, it’s that AI’s “human” behavior is not only simulated but very much maintained by humans.
Anyways, to close this section out: The more you fine-tune an AI, the more narrow and specific it becomes in its application. It can still be very versatile in its use, but they are still developed for very specific tasks, and you need to keep that in mind if/when you choose to use it (I’ll return to this point in the final section).
85 notes
·
View notes
Note
two excerpts from the June 22 order re sanctions - the SALT on this judge!! 😂


PS your recounting of this case has been so so well done and entertaining, thank you for sharing!
Image Id from the ask below the read more. :)
Thank you! And yes, that section is so funny and painful (in a good way).
[Image ID from ask: two screenshot of a court order. The first reads, "MR. SCHWARTZ: Correct. It became my last resort. So I guess that’s correct.
(Tr. 37-38.) Mr. Schwartz’s statement in his May 25 affidavit that ChatGPT “supplemented” his research was a misleading attempt to mitigate his actions by creating the false impression that he had done other, meaningful research on the issue and did not rely exclusive on an AI chatbot, when, in truth and in fact, it was the only source of his substantive arguments. [footnote 12] These misleading statements support the Court’s finding of subjective bad faith.
Following receipt of the April 25 Affirmation, the Court issued an Order" [ends mid-sentence]
The second screenshot includes a few lines of text, and then shows footnote 12. The text above the footnote reads, [beginning mid-sentence] "Order to Show Cause of May 4, he “still could not fathom that ChatGPT could produce multiple fictitious cases . . . .” (Schwartz June 6 Decl. ¶ 30.) He states that when he read the Order of May 4, “I realized that I must have made a serious error and that there must be a major flaw with" [end mid-sentence]
Footnote 12 reads, "Cf. Lewis Carroll, Alice’s Adventures in Wonderland, 79 (Puffin Books ed. 2015) (1865):
“Take some more tea,” the March Hare said to Alice, very earnestly.
“I’ve had nothing yet,” Alice replied in an offended tone, “so I can’t take more.”
“You mean you can’t take less,” said the Hatter: “it’s very easy to take more than nothing.”]
53 notes
·
View notes
Text
ADDRESSING TWITTER'S TOS/POLICY IN REGARDS TO ARTISTS AND AI
Hi !! if you're an artist and have been on twitter, you've most likely seen these screen shots of twitters terms of service and privacy policy regarding AI and how twitter can use your content
I want to break down the information that's been going around as I noticed a lot of it is unintentionally misinformation/fearmongering that may be causing artists more harm than good by causing them to panic and leave the platform early
As someone who is an artist and makes a good amount of my income off of art, I understand the threat of AI art and know how scary it is and I hope to dispel some of this fear regarding twitter's TOS/Privacy policy at least. At a surface level yes, what's going on seems scary but there's far more to it and I'd like to explain it in more detail so people can properly make decisions!
This is a long post just as a warning and all screenshots should have an alt - ID with the text and general summary of the image
Terms of Service
Firstly, lets look at the viral post regarding twitter's terms of service and are shown below
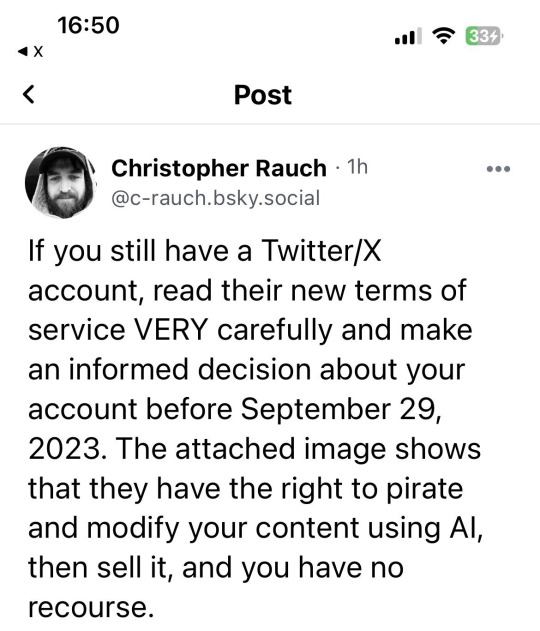
I have seen these spread a lot and have seen so many people leave twitter/delete all their art/deactivate there when this is just industry standard to include in TOS
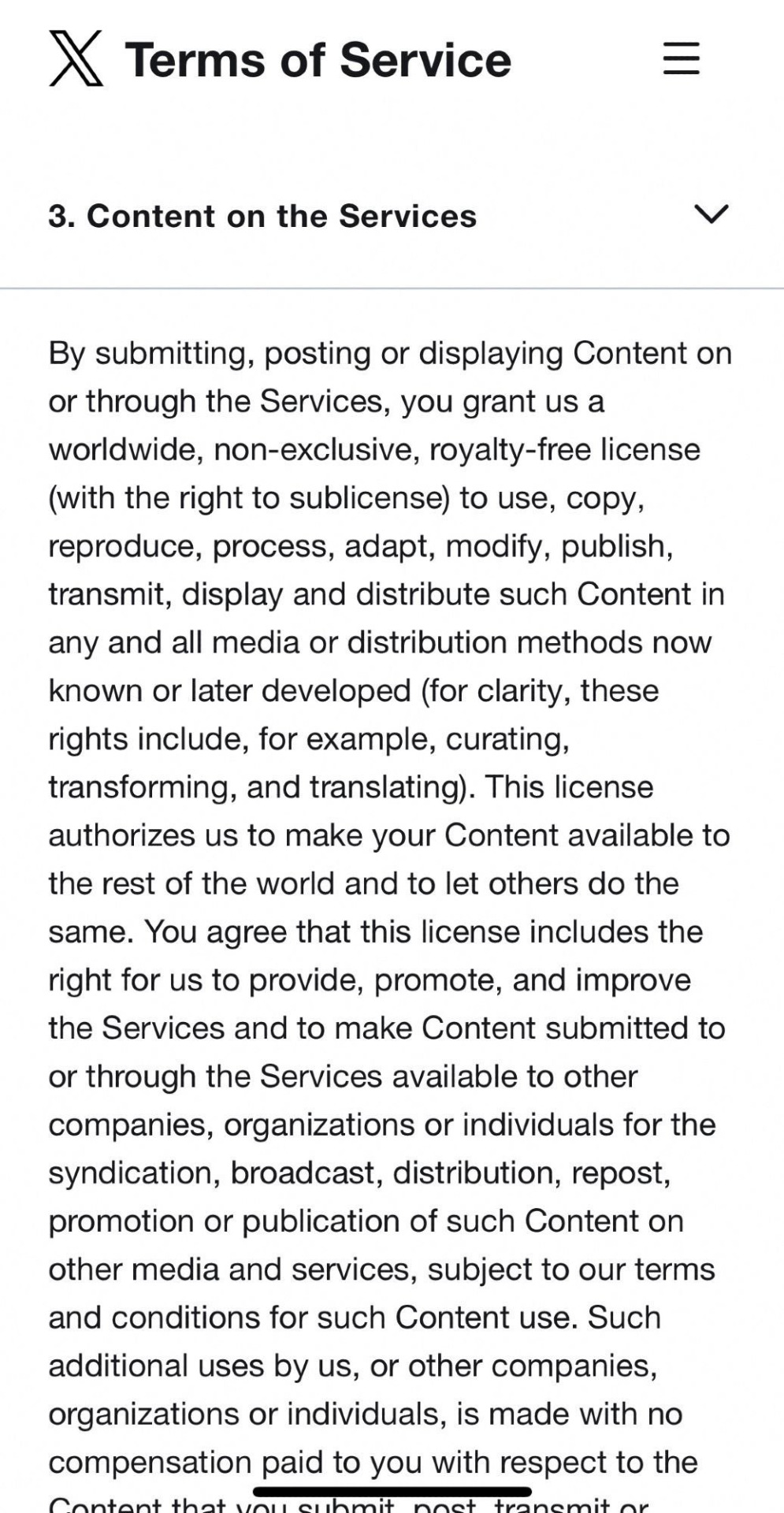
Below are other sites TOS I found real quick with the same/similar clauses! From instagram, tiktok, and even Tumblr itself respectively, with the bit worded similar highlighted
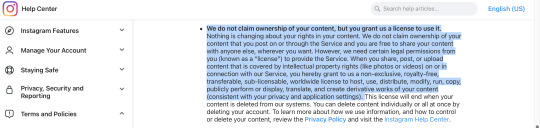


Even Bluesky, a sight viewed as a safe haven from AI content has this section

As you can see, all of them say essentially the same thing, as it is industry standard and it's necessary for sites that allow you to publish and others to interact with your content to prevent companies from getting into legal trouble.
Let me break down some of the most common terms and how these app do these things with your art/content:
storing data - > allowing you to keep content uploaded/stored on their servers (Ex. comments, info about user like pfp)
publishing -> allowing you to post content
redistributing -> allowing others to share content, sharing on other sites (Ex. a Tumblr post on twitter)
modifying -> automatic cropping, in app editing, dropping quality in order to post, etc.
creating derivative works -> reblogs with comments, quote retweets where people add stuff to your work, tiktok stitches/duets
While these terms may seems intimidating, they are basically just tech jargon for the specific terms we know used for legal purposes, once more, simply industry standard :)
Saying that Twitter "published stored modified and then created a derivative work of my data without compensating me" sounds way more horrible than saying "I posted my art to twitter which killed the quality and cropped it funny and my friend quote-tweeted it with 'haha L' " and yet they're the same !
Privacy Policy
This part is more messy than the first and may be more of a cause for concern for artists. It is in regards to this screenshot I've seen going around
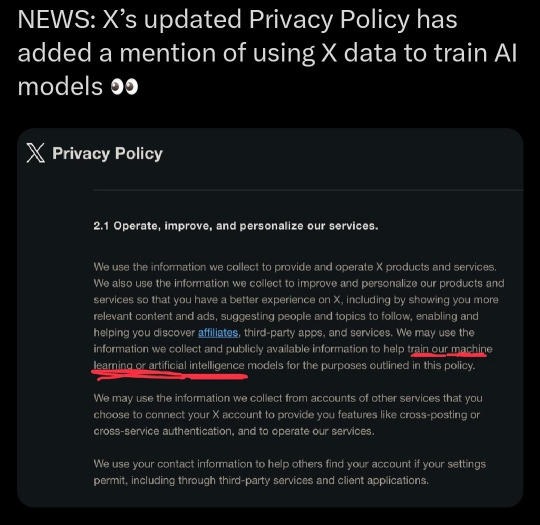
Firstly, I want to say that that is the only section in twitter's privacy policy where AI /machine learning is mentioned and the section it is is regarding how twitter uses user information.
Secondly, I do want to want to acknowledge that Elon Musk does have an AI development company, xAI. This company works in the development of AI, however, they want to make a good AGI which stands for artificial general intelligence (chatgpt, for example, is another AGI) in order to "understand the universe" with a scientific focus. Elon has mentioned wanting it to be able to solve complex mathematics and technical problems. He also, ofc, wants it to be marketable. You can read more about that here: xAI's website
Elon Musk has claimed that xAI will use tweets to help train it/improve it. As far as I'm aware, this isn't happening yet. xAI also, despite the name, does NOT belong/isn't a service of Xcorp (aka twitter). Therefore, xAI is not an official X product or service like the privacy policy is covering. I believe that the TOS/the privacy policies would need to expand to disclaim that your information will be shared specifically with affiliates in the context of training artificial intelligence models for xAI to be able to use it but I'm no lawyer. (also,,,Elon Musk has said cis/cisgender is a slur and said he was going to remove the block feature which he legally couldn't do. I'd be weary about anything he says)
Anyway, back to the screenshot provided, I know at a glance the red underlined text where it says it uses information collected to train AI but let's look at that in context. Firstly, it starts by saying it uses data it collects to provide and operate X products and services and also uses this data to help improve products to improve user's experiences on X and that AI may be used for "the purposes outlined in this policy". This means essentially just that is uses data it collects on you not only as a basis for X products and services (ex. targeting ads) but also as a way for them to improve (ex. AI algorithms to improve targeting ads). Other services it lists are recommending topics, recommending people to follow, offering third-party services, allowing affiliates etc. I believe this is all the policy allows AI to be used for atm.
An example of this is if I were to post an image of a dog, an AI may see and recognize the dog in my image and then suggest me more dog content! It may also use this picture of a dog to add to its database of dogs, specific breeds, animals with fur, etc. to improve this recommendation feature.
This type of AI image, once more, is common in a lot of media sites such as Tumblr, insta, and tiktok, and is often used for content moderation as shown below once more


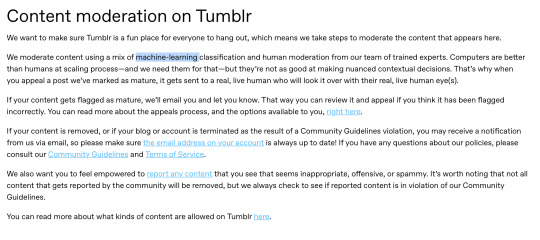

Again, as far as I'm aware, this type of machine learning is to improve/streamline twitter's recommendation algorithm and not to produce generative content as that would need to be disclaimed!!
Claiming that twitter is now using your art to train AI models therefore is somewhat misleading as yes, it is technically doing that, as it does scan the images you post including art. However, it is NOT doing it to learn how to draw/generate new content but to scan and recognize objects/settings/etc better so it can do what social media does best, push more products to you and earn more money.
(also as a small tangent/personal opinion, AI art cannot be copywritten and therefore selling it would be a very messy area, so I do not think a company driven by profit and greed would invest so much in such a legally grey area)
Machine learning is a vast field , encompassing WAY More than just art. Please don't jump to assume just because AI is mentioned in a privacy policy that that means twitter is training a generative AI when everything else points to it being used for content moderation and profit like every other site uses it
Given how untrustworthy and just plain horrible Elon Musk is, it is VERY likely that one day twitter and xAI will use user's content to develop/train a generative AI that may have an art aspect aside from the science focus but for now it is just scanning your images- all of them- art or not- for recognizable content to sell for you and to improve that algorithm to better recognize stuff, the same way Tumblr does that but to detect if there's any nsfw elements in images.
WHAT TO DO AS AN ARTIST?
Everyone has a right to their own opinion of course ! Even just knowing websites collect and store this type of data on you is a valid reason to leave and everyone has their own right to leave any website should they get uncomfortable !
However, when people lie about what the TOS/privacy policy actually says and means and actively spread fear and discourage artists from using twitter, they're unintentionally only making things worse for artists with no where to go.
Yes twitter sucks but the sad reality is that it's the only option a lot of artists have and forcing them away from that for something that isn't even happening yet can be incredibly harmful, especially since there's not really a good replacement site for it yet that isn't also using AI / has that same TOS clause (despite it being harmless)
I do believe that one day xAI will being using your data and while I don't think it'll ever focus solely on art generation as it's largely science based, it is still something to be weary of and it's very valid if artists leave twitter because of that! Yet it should be up to artists to decide when they want to leave/deactivate and I think they should know as much information as possibly before making that decision.
There's also many ways you can protect your art from AI such as glazing it, heavily watermarking it, posting links to external sites, etc. Elon has also stated he'll only be using public tweets which means privating your account/anything sent in DMS should be fine!!
Overall, I just think if we as artists want any chance of fighting back against AI we have to stay vocal and actively fight against those who are pushing it and abandon and scatter at the first sign of ANY machine learning on websites we use, whether it's producing generative art content or not.
Finally, want to end this by saying that this is all just what I've researched by myself and in some cases conclusions I've made based on what makes the most sense to me. In other words, A Lot Could Be Wrong ! so please take this with a grain of salt, especially that second part ! Im not at all any AI/twitter expert but I know that a lot of what people were saying wasn't entirely correct either and wanted to speak up ! If you have anything to add or correct please feel free !!
28 notes
·
View notes
Text
So, in Brazilian book market news, books generated by Artificial Intelligence are starting to pop up in the country's Amazon store.

Journalists from Núcleo Jornalismo had identified new 59 books on the website on the past 30 days. Within this set, 52 titles make clear in their information the use of AI tools for text generation, placing the co-authorship for “Artificial Intelligence” or “ChatGPT”, the OpenAI chatbot. In another three cases, authorship is attributed to MidJourney (an AI focused on images), while four obtained confirmation from the report through alternative approaches, checking on YouTube.
In July, Amazon and six other leading AI companies pledged to the US White House to use technology responsibly. Representatives of these companies signed an agreement that includes the implementation of a watermarking system, which, in theory, will inform users when content on their platforms is generated by artificial intelligence algorithms.
The themes of the publications found vary from children's books to self-help works, fiction and even imitations of renowned authors. Some of them explore the metanarrative, under which ChatGPT investigates its own nature.
Núcleo also noticed 46 new coloring books in the last 30 days on Amazon alone. Everyone seems to be using the basics of digital marketing videos. However, without certainty that they were created from AI, the works were not counted.
Influential authors are also sharing concerns about another angle to this situation: spam. Some firmly argue that the volume of AI-generated books is putting detrimental pressure on Amazon, especially for indie authors. And it doesn't stop there; these authors also accuse this content of becoming a kind of “click farm”, a term that describes the mass production of questionable and superficial content to attract attention and audience.
(x)
#brazil#politics#brazilian politics#books#artificial intelligence#technology#gotta be transparent and honest here for Good Amateur Journalism so here be noted that this blogger hates aye eye#if i may vent: i spend my whole life swallowing books like a black hole and spending uncountable hours practicing to improve my writing#and these clowns spam stores and even AO3 and Wattpad with their garbage generated by glorified autocompleters#are we all a joke to you#no no need to answer we know we are#which is why we °clears throat and switches to Diplomatic Voice° have issues with you#translations and summaries
26 notes
·
View notes
Text
PSA to those who follow me: ChatGPT does not automatically “learn” from the prompts you give it. The people who run it do save the questions you ask it, and they will be collated and processed en masse to train the model if you do not opt out using the “turn off chat history” setting, but each individual interaction causes no change in ChatGPT when it happens.
It is important not to mythologize machine learning. ChatGPT, DALLE, and other models like them are statistical models that judge the most likely appropriate responses, where that’s images or text. They do not “learn” by seeing things. They have to be specifically directed to take information and incorporate it into their statistical model. (They are also not directly looking back at their training data, copying a bunch of pixels or sentences from individual images/stories, and collaging it together. It’s more complicated than that.)
There is no way to “ruin” ChatGPT by spamming it. Even if your spam input makes it past a spam filter and into the new training data, it is not a living thing that learns or can be confused. When ChatGPT is trained on new information, that creates a new, entirely separate statistical model that does not replace the old one. If this new model hypothetically got screwed up, it would be trivial to revert to the old one.
31 notes
·
View notes
Text
The Daily Dad — Feb 20, 2024
Things you might want to know:

‘Everything is hairless’: what 100 women taught me about porn and body confidence
💭 I feel like anyone seriously researching porn’s influence on women’s self-image in the 2020s has to be old as fuck, ‘cause no one under fifty thinks that porn is having a meaningful impact on modern self-image in the era of Instagram. When it comes to generating insecurity, a bruised-up, bored porn slut being impaled by a sketchy cock has got nothin’ on a perfect size 0 lounging —toned and smooth— in an microscopic bikini next to an infinity pool overlooking Santorini while eating an improbable pizza.
Legendary Publisher EC Comics Rises From the Grave - IGN
❝ Oni has become the official home of the EC Comics brand, via a partnership with William M. Gaines Agent, Inc. The new line will be overseen by Oni Press President & Publisher Hunter Gorinson and Editor-in-Chief Sierra Hahn in partnership with Cathy Gaines Mifsud and Corey Mifsud, the administrators of William M. Gaines Agent, Inc.
Reddit has a new AI training deal to sell user content
💭 I just nuked a handful of my stories from Reddit. It probably won’t achieve much… they’ll probably let their scraping-buddy —coughOpenAIcough— go through the deleted content too. But it was a small price to pay for the chance to say “fuck you” to our imminent overlords.
The Text File That Runs the Internet
❝ "For decades, robots.txt governed the behavior of web crawlers. But as unscrupulous AI companies seek out more and more data, the basic social contract of the web is falling apart."
New FDA-approved drug makes severe food allergies less life-threatening
💭 Before long I won’t be able to count on a peanut perimeter to protect me from a full-on snuggle assault… which we in the business call a ‘Blossom Blitz’.

‘Life Is Strange’ and ‘Life Is Strange: Before the Storm’ Have Been Updated for Modern iOS Device and OS Support
💭 Okay, so Life Is Strange’s writing is hella whack, yo. And the expression-challenged character models tend to make it feel like a department store mannequin production of an off-off-Broadway play about loss, death, and Polaroids. But the “rewind” mechanic elevates the material, and I’m glad we’ve been playing it on the stream. If you want a mobile version of it, here ya go…
New York archdiocese calls funeral for trans activist at cathedral ‘scandalous’
❝ Pastor of St Patrick’s Cathedral condemns service for Cecilia Gentili after she was celebrated as being ‘mother of all whores’
After a decade and $1.2 billion, NASA reveals its booty from Bennu: 121 grams
💭 It saddens me when stories like this —which should be presented as the exciting developments they are— lead with angerbait bullshit along the lines of ‘See how much they spent to get so little?! Here are some paragraphs explaining why this is actually cool, but we couldn’t get you to read without pissing you off first.’ Human beings do something amazing, and it ends up serving random economic grievances.
Asgard’s Wrath 2 Review - IGN
💭 I’m tempted to buy this for my Quest 2, but I haven’t gotten into a VR game since Half-Life: Alyx, and I’m not sure I want to spend 90 hours spinning in circles and trying not to fall into the TV.
ChatGPT vs. Gemini: Which AI Chatbot Subscription Is Right for You?
❝ Everyone wants your $20 per month for access to their best AI chatbot. Who gets it depends on what features are important to you.

OpenAI collapses media reality with Sora, a photorealistic AI video generator
💭 I recently read a pretty convincing argument that the nature of this generation of generative AI is self-limiting… the nature of the models will lead to most machine-created media looking uncannily similar, and thus boring. It won’t look bad, but those who consume enough of it will start to spot the seams. Which is good… in the short term. Hopefully, society will have time to prepare itself for the seamless shit we’ll see in 2040.
For Hundreds of Years, People Thought California Was an Island
❝ Dozens of maps show cartography's most persistent mistake.
How to get on 'Survivor': Behind the scenes of casting season 45
❝ How do you get on 'Survivor'? Read the incredible stories and watch the audition videos of contestants that made in onto season 45.
Nvidia CEO calls for “Sovereign AI” as his firm overtakes Amazon in market value
💭 I’m not saying that there’s nothing to his argument. I’m just not sure that the dudes who stand to make billions —trillions?— from machine learning hardware are the right ones to be calling for what will essentially become a post-nuclear, multi-polar Cold War.
Walmart might buy Vizio to win the fight over cheap TVs
❝ Walmart is in talks to buy Vizio for $2 billion, according to a report from The Wall Street Journal. The deal could put Walmart in a position to compete with smart TVs from Roku and Amazon.
8 notes
·
View notes
Last Seen Blogs

zikbitume
Zikbitume

feralshadowdemon
✩ leave, leave this body of mine.

mariev-r
Mariev

deescreates
Deescreates Fanpage

sydnieminty
🌿 SydnieMinty 🌿