#AI
Text
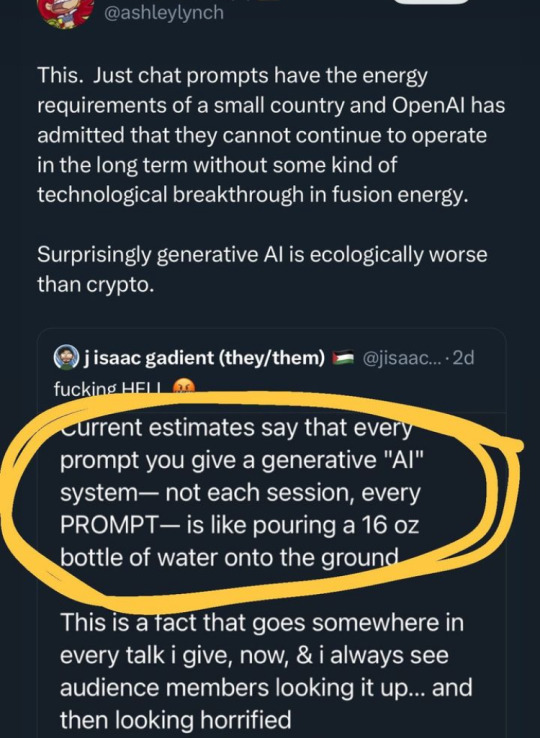
#ai#ai art#climate change#ecology#ecocide#water rights#land back#respect water treaties with First Nations#wasteland#waste#waste fraud and abuse#desertification
9K notes
·
View notes
Text
1K notes
·
View notes
Text
A computer science student named Priyanjali Gupta, studying in her third year at Vellore Institute of Technology, has developed an AI-based model that can translate sign language into English.
543 notes
·
View notes
Text
AI is a WMD

I'm in TARTU, ESTONIA! AI, copyright and creative workers' labor rights (TOMORROW, May 10, 8AM: Science Fiction Research Association talk, Institute of Foreign Languages and Cultures building, Lossi 3, lobby). A talk for hackers on seizing the means of computation (TOMORROW, May 10, 3PM, University of Tartu Delta Centre, Narva 18, room 1037).

Fun fact: "The Tragedy Of the Commons" is a hoax created by the white nationalist Garrett Hardin to justify stealing land from colonized people and moving it from collective ownership, "rescuing" it from the inevitable tragedy by putting it in the hands of a private owner, who will care for it properly, thanks to "rational self-interest":
https://pluralistic.net/2023/05/04/analytical-democratic-theory/#epistocratic-delusions
Get that? If control over a key resource is diffused among the people who rely on it, then (Garrett claims) those people will all behave like selfish assholes, overusing and undermaintaining the commons. It's only when we let someone own that commons and charge rent for its use that (Hardin says) we will get sound management.
By that logic, Google should be the internet's most competent and reliable manager. After all, the company used its access to the capital markets to buy control over the internet, spending billions every year to make sure that you never try a search-engine other than its own, thus guaranteeing it a 90% market share:
https://pluralistic.net/2024/02/21/im-feeling-unlucky/#not-up-to-the-task
Google seems to think it's got the problem of deciding what we see on the internet licked. Otherwise, why would the company flush $80b down the toilet with a giant stock-buyback, and then do multiple waves of mass layoffs, from last year's 12,000 person bloodbath to this year's deep cuts to the company's "core teams"?
https://qz.com/google-is-laying-off-hundreds-as-it-moves-core-jobs-abr-1851449528
And yet, Google is overrun with scams and spam, which find their way to the very top of the first page of its search results:
https://pluralistic.net/2023/02/24/passive-income/#swiss-cheese-security
The entire internet is shaped by Google's decisions about what shows up on that first page of listings. When Google decided to prioritize shopping site results over informative discussions and other possible matches, the entire internet shifted its focus to producing affiliate-link-strewn "reviews" that would show up on Google's front door:
https://pluralistic.net/2024/04/24/naming-names/#prabhakar-raghavan
This was catnip to the kind of sociopath who a) owns a hedge-fund and b) hates journalists for being pain-in-the-ass, stick-in-the-mud sticklers for "truth" and "facts" and other impediments to the care and maintenance of a functional reality-distortion field. These dickheads started buying up beloved news sites and converting them to spam-farms, filled with garbage "reviews" and other Google-pleasing, affiliate-fee-generating nonsense.
(These news-sites were vulnerable to acquisition in large part thanks to Google, whose dominance of ad-tech lets it cream 51 cents off every ad dollar and whose mobile OS monopoly lets it steal 30 cents off every in-app subscriber dollar):
https://www.eff.org/deeplinks/2023/04/saving-news-big-tech
Now, the spam on these sites didn't write itself. Much to the chagrin of the tech/finance bros who bought up Sports Illustrated and other venerable news sites, they still needed to pay actual human writers to produce plausible word-salads. This was a waste of money that could be better spent on reverse-engineering Google's ranking algorithm and getting pride-of-place on search results pages:
https://housefresh.com/david-vs-digital-goliaths/
That's where AI comes in. Spicy autocomplete absolutely can't replace journalists. The planet-destroying, next-word-guessing programs from Openai and its competitors are incorrigible liars that require so much "supervision" that they cost more than they save in a newsroom:
https://pluralistic.net/2024/04/29/what-part-of-no/#dont-you-understand
But while a chatbot can't produce truthful and informative articles, it can produce bullshit – at unimaginable scale. Chatbots are the workers that hedge-fund wreckers dream of: tireless, uncomplaining, compliant and obedient producers of nonsense on demand.
That's why the capital class is so insatiably horny for chatbots. Chatbots aren't going to write Hollywood movies, but studio bosses hyperventilated at the prospect of a "writer" that would accept your brilliant idea and diligently turned it into a movie. You prompt an LLM in exactly the same way a studio exec gives writers notes. The difference is that the LLM won't roll its eyes and make sarcastic remarks about your brainwaves like "ET, but starring a dog, with a love plot in the second act and a big car-chase at the end":
https://pluralistic.net/2023/10/01/how-the-writers-guild-sunk-ais-ship/
Similarly, chatbots are a dream come true for a hedge fundie who ends up running a beloved news site, only to have to fight with their own writers to get the profitable nonsense produced at a scale and velocity that will guarantee a high Google ranking and millions in "passive income" from affiliate links.
One of the premier profitable nonsense companies is Advon, which helped usher in an era in which sites from Forbes to Money to USA Today create semi-secret "review" sites that are stuffed full of badly researched top-ten lists for products from air purifiers to cat beds:
https://housefresh.com/how-google-decimated-housefresh/
Advon swears that it only uses living humans to produce nonsense, and not AI. This isn't just wildly implausible, it's also belied by easily uncovered evidence, like its own employees' Linkedin profiles, which boast of using AI to create "content":
https://housefresh.com/wp-content/uploads/2024/05/Advon-AI-LinkedIn.jpg
It's not true. Advon uses AI to produce its nonsense, at scale. In an excellent, deeply reported piece for Futurism, Maggie Harrison Dupré brings proof that Advon replaced its miserable human nonsense-writers with tireless chatbots:
https://futurism.com/advon-ai-content
Dupré describes how Advon's ability to create botshit at scale contributed to the enshittification of clients from Yoga Journal to the LA Times, "Us Weekly" to the Miami Herald.
All of this is very timely, because this is the week that Google finally bestirred itself to commence downranking publishers who engage in "site reputation abuse" – creating these SEO-stuffed fake reviews with the help of third parties like Advon:
https://pluralistic.net/2024/05/03/keyword-swarming/#site-reputation-abuse
(Google's policy only forbids site reputation abuse with the help of third parties; if these publishers take their nonsense production in-house, Google may allow them to continue to dominate its search listings):
https://developers.google.com/search/blog/2024/03/core-update-spam-policies#site-reputation
There's a reason so many people believed Hardin's racist "Tragedy of the Commons" hoax. We have an intuitive understanding that commons are fragile. All it takes is one monster to start shitting in the well where the rest of us get our drinking water and we're all poisoned.
The financial markets love these monsters. Mark Zuckerberg's key insight was that he could make billions by assembling vast dossiers of compromising, sensitive personal information on half the world's population without their consent, but only if he kept his costs down by failing to safeguard that data and the systems for exploiting it. He's like a guy who figures out that if he accumulates enough oily rags, he can extract so much low-grade oil from them that he can grow rich, but only if he doesn't waste money on fire-suppression:
https://locusmag.com/2018/07/cory-doctorow-zucks-empire-of-oily-rags/
Now Zuckerberg and the wealthy, powerful monsters who seized control over our commons are getting a comeuppance. The weak countermeasures they created to maintain the minimum levels of quality to keep their platforms as viable, going concerns are being overwhelmed by AI. This was a totally foreseeable outcome: the history of the internet is a story of bad actors who upended the assumptions built into our security systems by automating their attacks, transforming an assault that wouldn't be economically viable into a global, high-speed crime wave:
https://pluralistic.net/2022/04/24/automation-is-magic/
But it is possible for a community to maintain a commons. This is something Hardin could have discovered by studying actual commons, instead of inventing imaginary histories in which commons turned tragic. As it happens, someone else did exactly that: Nobel Laureate Elinor Ostrom:
https://www.onthecommons.org/magazine/elinor-ostroms-8-principles-managing-commmons/
Ostrom described how commons can be wisely managed, over very long timescales, by communities that self-governed. Part of her work concerns how users of a commons must have the ability to exclude bad actors from their shared resources.
When that breaks down, commons can fail – because there's always someone who thinks it's fine to shit in the well rather than walk 100 yards to the outhouse.
Enshittification is the process by which control over the internet moved from self-governance by members of the commons to acts of wanton destruction committed by despicable, greedy assholes who shit in the well over and over again.
It's not just the spammers who take advantage of Google's lazy incompetence, either. Take "copyleft trolls," who post images using outdated Creative Commons licenses that allow them to terminate the CC license if a user makes minor errors in attributing the images they use:
https://pluralistic.net/2022/01/24/a-bug-in-early-creative-commons-licenses-has-enabled-a-new-breed-of-superpredator/
The first copyleft trolls were individuals, but these days, the racket is dominated by a company called Pixsy, which pretends to be a "rights protection" agency that helps photographers track down copyright infringers. In reality, the company is committed to helping copyleft trolls entrap innocent Creative Commons users into paying hundreds or even thousands of dollars to use images that are licensed for free use. Just as Advon upends the economics of spam and deception through automation, Pixsy has figured out how to send legal threats at scale, robolawyering demand letters that aren't signed by lawyers; the company refuses to say whether any lawyer ever reviews these threats:
https://pluralistic.net/2022/02/13/an-open-letter-to-pixsy-ceo-kain-jones-who-keeps-sending-me-legal-threats/
This is shitting in the well, at scale. It's an online WMD, designed to wipe out the commons. Creative Commons has allowed millions of creators to produce a commons with billions of works in it, and Pixsy exploits a minor error in the early versions of CC licenses to indiscriminately manufacture legal land-mines, wantonly blowing off innocent commons-users' legs and laughing all the way to the bank:
https://pluralistic.net/2023/04/02/commafuckers-versus-the-commons/
We can have an online commons, but only if it's run by and for its users. Google has shown us that any "benevolent dictator" who amasses power in the name of defending the open internet will eventually grow too big to care, and will allow our commons to be demolished by well-shitters:
https://pluralistic.net/2024/04/04/teach-me-how-to-shruggie/#kagi
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/05/09/shitting-in-the-well/#advon
Image:
Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0
https://creativecommons.org/licenses/by/3.0/deed.en
--
Catherine Poh Huay Tan (modified)
https://www.flickr.com/photos/68166820@N08/49729911222/
Laia Balagueró (modified)
https://www.flickr.com/photos/lbalaguero/6551235503/
CC BY 2.0
https://creativecommons.org/licenses/by/2.0/
#pluralistic#pixsy#wmds#automation#ai#botshit#force multipliers#weapons of mass destruction#commons#shitting in the drinking water#ostrom#elinor ostrom#sports illustrated#slop#advon#google#monopoly#site reputation abuse#enshittification#Maggie Harrison Dupré#futurism
254 notes
·
View notes
Text

#gay#men#man#muscles#size differences#anime#manga#comic#drawings#lgbt#gay hot#ai gay#gay ai#ai generated#muscular#ai#ai muscle#ai muscle growth#male muscle growth#muscle#muscle men#musclegrowth#stable diffusion
197 notes
·
View notes
Text
"The world’s coral reefs are close to 25% larger than we thought. By using satellite images, machine learning and on-ground knowledge from a global network of people living and working on coral reefs, we found an extra 64,000 square kilometers of coral reefs — an area the size of Ireland.
That brings the total size of the planet’s shallow reefs (meaning 0-20 meters deep) to 348,000 square kilometers — the size of Germany. This figure represents whole coral reef ecosystems, ranging from sandy-bottomed lagoons with a little coral, to coral rubble flats, to living walls of coral.
Within this 348,000 km² of coral is 80,000 km² where there’s a hard bottom — rocks rather than sand. These areas are likely to be home to significant amounts of coral — the places snorkelers and scuba divers most like to visit.
You might wonder why we’re finding this out now. Didn’t we already know where the world’s reefs are?
Previously, we’ve had to pull data from many different sources, which made it harder to pin down the extent of coral reefs with certainty. But now we have high resolution satellite data covering the entire world — and are able to see reefs as deep as 30 meters down.
We coupled this with direct observations and records of coral reefs from over 400 individuals and organizations in countries with coral reefs from all regions, such as the Maldives, Cuba and Australia.
To produce the maps, we used machine learning techniques to chew through 100 trillion pixels from the Sentinel-2 and Planet Dove CubeSat satellites to make accurate predictions about where coral is — and is not. The team worked with almost 500 researchers and collaborators to make the maps.
The result: the world’s first comprehensive map of coral reefs extent, and their composition, produced through the Allen Coral Atlas.
The maps are already proving their worth. Reef management agencies around the world are using them to plan and assess conservation work and threats to reefs...
In good news, these maps are already leading to real world change. We’ve already seen new efforts to conserve coral reefs in Indonesia, several Pacific island nations, Panama, Belize, Kenya and Australia, among others."
-via GoodGoodGood, May 2, 2024
--
Note: You can see the maps yourself by going here!
#coral#coral reef#sea creatures#marine life#underwater#coral reefs#conservation#conservation news#climate change#hope#hope posting#hopepunk#environment#environmental science#environmental news#good news#climate action#climate hope#maldives#cuba#australia#machine learning#ai#this is the kind of shit ai should be used for!!!#indonesia#panama#belize#kenya#it's coral week here at reasonsforhope and it's not even on purpose!
221 notes
·
View notes
Text
Humans now share the web equally with bots, according to a major new report – as some fear that the internet is dying.
In recent months, the so-called “dead internet theory” has gained new popularity. It suggests that much of the content online is in fact automatically generated, and that the number of humans on the web is dwindling in comparison with bot accounts.
Now a new report from cyber security company Imperva suggests that it is increasingly becoming true. Nearly half, 49.6 per cent, of all internet traffic came from bots last year, its “Bad Bot Report” indicates.
That is up 2 per cent in comparison with last year, and is the highest number ever seen since the report began in 2013.
In some countries, the picture is worse. In Ireland, 71 per cent of internet traffic is automated, it said.
Some of that rise is the result of the adoption of generative artificial intelligence and large language models. Companies that build those systems use bots scrape the internet and gather data that can then be used to train them.
Some of those bots are becoming increasingly sophisticated, Imperva warned. More and more of them come from residential internet connections, which makes them look more legitimate.
“Automated bots will soon surpass the proportion of internet traffic coming from humans, changing the way that organizations approach building and protecting their websites and applications,” said Nanhi Singh, general manager for application security at Imperva. “As more AI-enabled tools are introduced, bots will become omnipresent.”
192 notes
·
View notes
Text




#ai sexy#ai babe#ai art#ai girl#ai model#ai artist#ai illustration#character ai#ai nude#ai#ai hottie#ai waifu#ai woman#ai world#ai women
146 notes
·
View notes
Text








More oversized boyfriends
#oversizedmen#muscle freak#ai muscle#ai muscle growth#ai#size difference#height difference#big biceps#size differences#bodybuilder#big arms#muscle worship#huge muscle#tall people#big bicep#macrophilia#musclegrowth#muscle inflation#weight gain#fat man#gay#gaining weight#muscle#hunk#aigenerated#aihunk#aimuscle#hotmale#maleportrait#stablediffusion
101 notes
·
View notes
Text

Benjamin Benichou / Luxury Shogun – Emerald Edo Dojo – Gucci / Rendering (AI) / 2024
118 notes
·
View notes
Text

#ai girl#ai babe#ai woman#ai beauty#ai hottie#ai art gallery#ai#ai image#ai artwork#ai art#ai generated#ai artist#ai waifu#ai sexy
83 notes
·
View notes
Text

ai art by @special-boi
#@special-boi#anime#art#ai art#girl#kawaii#digitalart#artist#animegirl#artwork#cute#illustration#waifu#sexy#ai
71 notes
·
View notes
Text

https://x.com/atamawatuwatu/status/1788593231082684467
69 notes
·
View notes


Last Seen Blogs

mads-rants
Me talking about whatever :)

soulofsouls
soul of souls @ tumblr

m0uthz
mOuthz

toruslvt
¡𝐆𝐈𝐑𝐋𝐁𝐋𝐎𝐆𝐆𝐈𝐍𝐆!

featherlouise
Just A Constant Cycle Of Hyperfixations