#laion database
Text
I know a lot of artists are antsy about art theft right now (myself included, I literally just had a terrible nightmare about fighting the physical manifestation of AI, The Mitchells vs The Machines style…). I can’t claim that any of these things can prevent it. But here’s a few things I’ve found useful:
Opening a free account on Pixsy.com. This website does a decent job at letting me know when my images have been reposted. 99% of the time, the results are just Tumblr-copying zombie websites that just repost everything that is already here. But, it’s sensitive enough that it alerted me when my old college posted my work. They were harmlessly using my stuff as an example of alumni work- but I was glad to be in the know, AND they had mistakenly credited my deadname, so I was able to reach out and correct that. I would have never have seen it otherwise. The website has subscription options, but you can ignore them and still use the monitoring services it provides.
Reverse image searching my most widely shared pieces on haveibeentrained.com. This website checks to see if your work has been fed to AI.
Looking up legal takedown letters and referencing them to draft a generic letter for my own use. This takes a bit of the stress off what is already a stressful and often time-consuming ordeal. Taking time to craft a Very Scary, Legally Threatening, Yet Coldly Professional Memo has been worth it.
Remaining careful about what and how I post online. My living depends on sharing my work, so I have to post it. I’ve learned through trial and error how to post lower resolution images that still look good, but aren’t easily used for anything beyond the intended post, and of course, strategic watermarking. Never, ever post full res, print quality stuff for the general public. Half the time it ends up looking unflattering on social media anyways, cause the files get crunched for being large. I try to downsize my images, while set to bicubic smoothening, to head that off. Look up the optimal image resolutions and proportions for individual sites before posting your web versions. For some work, cropping the piece, or posting chunks of detail shots instead of a full view, is a more protective measure.
Look out for other artists! Reach out when in doubt. Don’t steal from others. Learn the difference between theft, and a study/master copy/fanart/inspiration. Don’t assume that all posted art has the same intended purpose as a “how to” instructional like 5 Minute Crafts. Ask permission. Artists are often helpful and supportive towards people who want to study their work! And, the best tip-offs I’ve received have all been from other people who were watching my back. Thank you to everybody who keeps an eye out for my work, and who have been thoughtful enough to reach out to me when they see theft happening 💖 y’all are the real MVPs. All we have is each other.
#cas posts#art theft#ai art#art#intellectual property#artificial art#artificial intelligence#artificialart#lensa app#lensa#stable diffusion#laion#laion database#large scale artificial intelligence open network#stolen art
388 notes
·
View notes
Text

still debating whether to add this to the original post but LAION is literally just a compilation of image urls ripped from the internet... they DO NOT CHECK copyright and you cant even get anything removed bc "theyre not hosting the image, just a link TO the image".....
scummy as hell to train your AI model on this database though :// from their FAQ:

i obviously don't want to promote fearmongering but this is deadass skirting the line to shift the blame.... "we don't host the images! we just host the LINKS to the images :) they have to go get the images themselves :)" LIKE BRO WHAT,,,
#its a link not an image#aria rambles#aria rants#deviantart#unfortunately theres nothing that we can do about LAION#bc theyre TECHNICALLY safe with their defense...#but like#this shouldnt be used like this#its one thing to make an image database#its another to LET PEOPLE WHO DONT CARE ABOUT ART THEFT USE IT TO TRAIN THEIR AI ART AND ART THEFT MODELS
12 notes
·
View notes
Text
So, the good news is, dA and Artstation and other art sites are creating new protocols to tell robots to ignore certain pieces. The bad news is, as they admit, they can only extend that to those pieces on their own websites; reposts to other sites can and will still be scanned for data (on top of the fact that things like robots.txt instructions and do-not-track requests aren't legally binding and there is no recourse if someone just decides to ignore them, which I wholeheartedly believe should be addressed as an issue of privacy law, but that's neither here nor there).
I propose a complementary database - an anti-training database, consisting of the main images found on pages with a noai header. The purpose of this database would be to compare against a training database before it's processed and remove exact visual matches, much like deduplication.
Of course, it's not going to be 100% reliable - no system is, whether it's in tech or in law or both - but it could go a long way toward making things work better when it comes to respecting conventional artists' wishes for their own work.
#not art#i swear i have more coming that's not just talk about the debate#this is half a genuine suggestion and half a thought experiment#is your objection to finding your work in LAION about your work being used in training? or being in a database at all?#and if it is the latter then what can we do about the repost issue?#as much as we try to bring awareness#there's really no way to stop it completely#so what do we do?#this is a point for discussion because i REALLY want to figure out what will work best
1 note
·
View note
Text
On the one hand, people who take a hardline stance on “AI art is not art” are clearly saying something naïve and indefensible (as though any process cannot be used to make art? as though artistry cannot still be involved in the set-up of the parameters and the choice of data set and the framing of the result? as though “AI” means any one thing? you’re going to have a real hard time with process music, poetry cut-up methods, &c.).
But all of this (as well as takes that what's really needed is a crackdown on IP) are a distraction from a vital issue—namely that this is technology used to create and sort enormous databases of images, and the uses to which this technology is put in a police state are obvious: it's used in service of surveillance, incarceration, criminalisation, and the furthering of violence against criminalised people.
Of course we've long known that datasets are not "neutral" and that racist data will provide racist outcomes, and we've long known that the problem goes beyond the datasets (even carefully vetting datasets does not necessarily control for social factors). With regards to "predictive policing," this suggests that criminalisation of supposed leftist "radicals" and racialised people (and the concepts creating these two groups overlap significantly; [link 1], [link 2]) is not a problem, but intentional—a process is built so that it always finds people "suspicious" or "guilty," but because it is based on an "algorithm" or "machine learning" or so-called "AI" (processes that people tend to understand murkily, if at all), they can be presented as innocent and neutral. These are things that have been brought up repeatedly with regards to "automatic" processes and things that trawl the web to produce large datasets in the recent past (e.g. facial recognition technology), so their almost complete absence from the discourse wrt "AI art" confuses me.
Abeba Birhane's thread here, summarizing this paper (h/t @thingsthatmakeyouacey) explains how the LAION-400M dataset was sourced/created, how it is filtered, and how images are retrieved from it (for this reason it's a good beginner explanation of what large-scale datasets and large neural networks are 'doing'). She goes into how racist, misogynistic, and sexually violent content is returned (and racist mis-categorisations are made) as a result of every one of those processes. She also brings up issues of privacy, how individuals' data is stored in datasets (even after the individual deletes it from where it was originally posted), and how it may be stored associated with metadata which the poster did not intend to make public. This paper (h/t thingsthatmakeyouacey [link]) looks at the ImageNet-ILSVRC-2012 dataset to discuss "the landscape of harm and threats both the society at large and individuals face due to uncritical and ill-considered dataset curation practices" including the inclusion of non-consensual pornography in the dataset.
Of course (again) this is nothing that hasn't already been happening with large social media websites or with "big data" (Birhane notes that "On the one hand LAION-400M has opened a door that allows us to get a glimpse into the world of large scale datasets; these kinds of datasets remain hidden inside BigTech corps"). And there's no un-creating the technology behind this—resistance will have to be directed towards demolishing the police / carceral / imperial state as a whole. But all criticism of "AI" art can't be dismissed as always revolving around an anti-intellectual lack of knowledge of art history or else a reactionary desire to strengthen IP law (as though that would ever benefit small creators at the expense of large corporations...).
835 notes
·
View notes
Text
I had some thoughts about paying to feed your face into a generator built on unpaid work used without consent. Transcript and links under the cut.
So let’s talk about AI art, and how incredibly unsafe y’all are being with it.
First, most of these apps, including the avatar makers, are developed using a generator called Stable Diffusion that was trained on LAION 5B, a database containing 5 billion pictures scraped off the internet, including illustrations from deviantart and pinterest. https://en.wikipedia.org/wiki/Stable_Diffusion#Training_data
It also contains thousands of images of patients scraped from private medical records. And the database creators have refused to remove them or take any responsibility. https://arstechnica.com/information-technology/2022/09/artist-finds-private-medical-record-photos-in-popular-ai-training-data-set/
Many artists have spoken up about how unethical it is to use their work without their consent to make an art generator that is now being used for paid products. These generators wouldn’t exist without the work of thousands of artists around the world, but they never gave permission for their images to be used this way, they can’t opt out, and they are not getting paid even for apps that charge *you* to use them.
Maybe that’s enough to change your mind about the “magic avatars” and “time travelling portraits.” But I get that they’re fun, and frankly, people will overlook a lot of harm when they’re having fun. Which brings us to the “find out” part of this video.
When you are giving these apps 10-20 pictures of YOUR FACE, where in the terms of service does it say they won’t sell those pictures to police surveillance companies? https://www.nytimes.com/2020/01/18/technology/clearview-privacy-facial-recognition.html
When you are giving them your face, where in the TOS does it say they’re responsible if their databases get hacked? If their data is used to impersonate or stalk you? https://thenextweb.com/news/people-using-facial-recognition-app-stalk-adult-actresses
Where in the TOS does it say your face can’t be used by companies training AI to help genocide? https://www.bbc.com/news/technology-55634388
Where in the TOS does it say your face will not be sold to a service that will splice you into porn? https://www.technologyreview.com/2021/09/13/1035449/ai-deepfake-app-face-swaps-women-into-porn/
That will create an on-demand version of you for strangers to assault? https://vocal.media/viva/why-are-men-creating-ai-girlfriends-only-to-abuse-them-and-brag-about-it-on-reddit
And you are giving some of them your payment info? You are giving all of them 10-20 pictures of your face?
They don’t care about the people whose work makes their generators possible. Why do you think they’re going to care about you?
#ai art hate blog#seriously y'all#do not give them your face and payment info are you out of your minds
262 notes
·
View notes
Text
The biggest dataset used for AI image generators had CSAM in it

Link the original tweet with more info
The LAION dataset has had ethical concerns raised over its contents before, but the public now has proof that there was CSAM used in it.
The dataset was essentially created by scraping the internet and using a mass tagger to label what was in the images. Many of the images were already known to contain identifying or personal information, and several people have been able to use EU privacy laws to get images removed from the dataset.
However, LAION itself has known about the CSAM issue since 2021.

LAION was a pretty bad data set to use anyway, and I hope researchers drop it for something more useful that was created more ethically. I hope that this will lead to a more ethical databases being created, and companies getting punished for using unethical databases. I hope the people responsible for this are punished, and the victims get healing and closure.
12 notes
·
View notes
Text
"Creators (Artists, Musicians, Actors, Writers, Models) have been scraped and exploited by tech companies without consent, credit or compensation while pushing Generative Ai. Below are resources to learn more about the Laion Database, Data Laundering, Lawsuits, and how Image Models and LLMs work. Get educated and stay strong."
24 notes
·
View notes
Note
Do you know if there's an ethical way for someone to use an AI generator? For ex, is there a way to filter out stolen art, or is the onus on artists to try to protect their work from the generators? (I don't have an agenda here, I'm just curious since you're on the topic, and it feels like the tech *should* have the former if it wants to become more widespread.)
As far as I'm aware all AI generators are using the same datasets that contain pretty much anything that could've been scraped off the internet (including private medical files and nsfw stuff, some if it including children, nonconsensual porn etc - the database is searchable but i advise against it, it's disturbing even with nswf filter turned on).
The LAION datset which these generators use is not curated in any way and was meant for research only (this is how all of this stuff ended up in it, it was non-profit). because images are scraped completely unselectively you can't know if the image the ai generated was made using stolen artwork.

It's possible to opt out from your art being included by using haveibeentrained (which is owned by a company called Spawning whose owner openly supports AI so not sure how reliable that is anyway) but it's very hard to find all of your art because your name isn't attached to it, i have hundreds of paintings and only managed to find maybe 5-6
I think image generators can be alright if used ethically without stealing real artists' art but so far that's not the case and everyone involved in developing these AIs is being very much against it getting regulated, they're acting like assholes and refuse any sort of dialogue. it leads artists to believe this was never about developing new helpful technology and was only ever meant to be an art heist used to eliminate actual artists from the industry to make the rich even richer. sorry for the long reply, I have a lot of feelings about this xD
33 notes
·
View notes
Photo

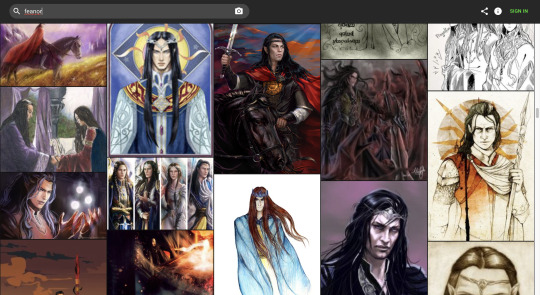
hey all: don’t use lensa.
I just did a quick search of the Laion database (which it ultimately uses) for ‘maedhros’ and ‘feanor’, and what do you know - loads of stolen silm fanart. Some of it is clearly the work of people who currently use this site (hi @atarinke and @arlenianchronicles ) and others are from both long-established fanartists (Jenny Dolfen, ilxwing, Elena Kukanova, etc.) as well as people just starting out and drawing on lined paper in class. It is indiscriminate. I’m lucky I haven’t found any of mine yet, but I don’t want to give this any more of my time.
using lensa and any other ai trained on stolen art takes away credit and the livelihoods of the artists whose work has been stolen - many of whom come from our own little corner of the internet.
i’ll be really honest here: I also don’t think people should be assembling ‘graphics’ sets without specifically linking each and every image with credit - possibly in the image itself. It’s the same deal, and you know what? lensa’s also been trained on those. I tried to reverse search this one and only came up with dead pinterest links, so good luck to anyone trying to hunt down the individual pieces.
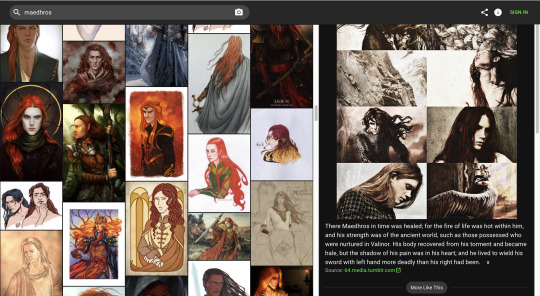
If you haven’t seen the arguments against AI art making the rounds recently, then please go ahead and read up on them. If you’ve already used Lensa for selfies, know that in their TOS they say they can use your photos. I’m not out here to shame anyone who’s done it without realizing; I just want to show you that it’s not just big-name artists etc etc who are being stolen from here. It’s us. You know - the little fanartists in this tiny corner of the internet that you’ve made your home. We are not immune.
Don’t support Lensa.
38 notes
·
View notes
Note
Apparently DeviantArt added a button to opt all your art out at once and say they're planning on making opting out the default option.
Doesn't make up for anything, since this should have been the case from the get-go. But it's good news at least.
I hope the rest of your day is filled with better news.
The post has been edited to reflect the new state of things, but it's worth making a note of it again, too, since edits get lost in the shuffle.
dA *has* reversed course. They *are* making it so "opt-out" is default.
There's still issues, though. To wit:

There is also a non-zero change Laion-5B has pieces from dA's database already present, thus the suspicion that it's legal ass-covering-- though I'd personally take it a step further and assume they already have an AI that scraped all content ready to launch, and thus forced the opt-in.
I'd like to be wrong, but if venture capital has taught me anything, it's 'assume the absolute fucking worst, and hope for something passable.'
39 notes
·
View notes
Text
There’s a tweet that claims that if you add noise to your images then it will protect you from having your image be trained on by AI that’s been liked by 8000 people and
Oh my god that is so hilariously incorrect
It’s citing a research paper in Japanese about a completely different kind of AI, with a specially formulated kind of noise to defeat a specific image recognition AI.
If you actually want to protect your images and your work, making your images slightly crispier is not going to do it. It’s better to search for your stuff in LAION 5B, which does not host or copy anything, it is literally just a database full of links, so if you find a link that you have control over, then break it.
Or add watermarks to your work so that if your name is recognised, which for most people will be highly unlikely, your name will be associated with the watermark and overtrained on it.
Or completely mislabel your images and lie about what’s in them. LAION has tools to filter out bad captions but this will do more than sprinkling a photoshop filter on your images.
Or I think the artist group Spawning might be working with Stable Diffusion to opt out of future dataset training? They say if you sign up with them you can opt in and out, and I’m fairly sure they’re talking to the people at Stability AI
This is speaking as an image synthesis enthusiast/ai artist who is sympathetic to people who don’t want their work trained on and who went oh no at all the people excitedly talking about adding noise to their images
(Also I’m still of the opinion that if you don’t like AI art, then cultivating an atmosphere where people are happy to label their stuff as AI art will help you avoid it better!)
#cadmus rambles#ai art discourse#also stable diffusion 1.4 already exists so the barn is out of the cow on that one#aesthetic noise is pretty nice on images I’ve added aesthetic noise to some of my digital art in the past before#i guess this might make a lot of images suddenly more aesthetic?
44 notes
·
View notes
Text
youtube
PSA for artists!
Spawning, creator of HaveIBeenTrained.com, is working with Stability AI and Laion to not only to help artists opt-out of their work being used to train AI without their consent, but they're also working to try and make AI an opt-in only feature in the future!
This is a really good step in the right direction and I encourage you to watch and share this video explaining how to use HaveIBeenTrained.com to find out if your work has been added to the Laion datasets and how to opt your work out.
To be clear:
Spawning is an independent organization building tools to help artists take control of their training data. They are not an AI company, they are not the one's who made AI an opt-out feature. They are simply working with these AI companies on our behalf to hopefully make AI tools opt-in only in the future.
HaveIBeenTrained.com does NOT save any images you used to search, or feed them into any AI training database.
#psa#reblog to boost#have i been trained#spawning#ai art debate#ai art#no ai art#ai#consent is important#Youtube#art#artists on tumblr#artists#support human artists#support indie artists#illustrators on tumblr#comics#traditional art#digital art
13 notes
·
View notes
Text
Protecting Artist from AI Technologies

The Concept Art Association has released a GoFundMe campaign to protect artists from AI Technologies, so we artists can stand up for our rights and be heard in the public and in DC! Please donate and share this link!
https://gofund.me/2df3dc07
quote from the Concept Art Association Facebook:
“In addition to compiling a spreadsheet of human artists to commission, the Concept Art Association is starting a GoFundMe to protect artists from AI technologies. With your help, we can take our mission to Washington D.C. and educate policymakers on the issues facing creative industries if this technology is left unchecked.
Go to the link to find out more or to donate. Massive databases such as LAION 5B (used by Stability AI) contains 5.8 billion text and image data, including copyrighted and private data, gathered without artists’ permission. By coming together, we can put a stop to this exploitation and theft. Join us in this fight and help shape the future of the arts.“
5 notes
·
View notes
Text
No, Doctors Aren't To Blame for AI Using Your Medical Record Photos, Here's How and Why
People care TOO MUCH about the IP laws of dumb cartoons like Mickey Mouse than the real abuse of data going on, acting like the only conversation worth having is "is copyright good or bad", but as a med student I have a vested interest in talking about data collection ethics.
You're welcome to address my bias or in less kind words say I'm in the pocket of "big pharma" or that I'm a "copyright maximalist" but I'm doing this purely to explain and educate how the LAION team is dishonest, manipulative, malicious and hides behind the good graces of "open-source" and "non-profit".
To start; how does LAION get hold of your photos? To put it shortly: Common Crawl, a service that has indexed and scraped web pages from 2014 until 2021. But, unlike LAION Common Crawl has a TOS, and states on their website that they do not allow users to violate IP or circumvent copy-protection using their data.

The highlights in orange are important, but for future points.
So how does this affect medical photos? "They shouldn't be on the internet in the first place!" You might say. This is where things get a bit muddy, because in the most popular case being spread the user has signed a consent forum allowing the use of their photos in medical journals, seen here;

Please make note of the first line, "to be used for my care, medical presentations and/or articles".
So how did it get online?
Despite what a lot of people jump to assume, this most likely was not the fault of the doctor – and unfortunately he's not alive anymore to even clarify what went wrong, RIP. There are many journals online on the user's condition – one which is particularly rare and as such requires study and photos for identification, many with attached images that have been scraped too. This user is most certainly not alone.
For background, PubMed is the largest site for sharing medical journals and case studies on the internet. It contains a wealth of information and is crucial to the safety and sanity of every overworked med student writing their 30th pharmacology paper. It also has attached images in some cases. These images are necessary to the journal, case study, research paper, whathaveyou that's being uploaded. They're also not just uploaded willy nilly. There are consent forms like the one seen above, procedures, and patient rights that are to be respected and honored. What I want to emphasize,
Being on a journal ≠ free to use.
Being online ≠ free to use.
If you do not have the patient's signed consent, you are not allowed to use the image at all, even in a transformative manner. It is not yours to use.
So how does LAION respond to this? Lying like shitty assholes, of course. Vice has done a very insightful article on just what LAION has stored within it and showing many harrowing stories of nonconsensual pornography, graphic executions and CSEM on the database, found here.
A very interesting part of the article that I'd like to draw attention to, though, is LAION team's claims about the copyright applied to these images. The claim in blue that all data falls under creative commons (lying about the copyright to every image) directly contradicts the claim in red (divorcing the team from copyright).

The claim in orange is stupid because it claims photos of SSNs and addresses directly linked to your name are not personal data if they dont contain your face. It also is not GDP compliant, as they elevate their own definition of what private data is over what your actual private data is.
But whatever, team LAION is on this!! They got it, they'll definitely be pruning their database to remove all of the offending– aaaand they literally just locked the discord help channel, deleted the entire exchange and accused Vice of writing a "hit piece", as reported on by motherboard here. Classy, LAION!
They don't even remove images from their database unless you explicitly email them, and even then they first condescendingly tell you to download the entire database, find the image and the link tied to it, then remove the image from the internet yourself– somehow. Classy, LAION.
Of course, the medical system isn't completely free from blame here, from the new motherboard article;
Zack Marshall, an associate professor of Community Rehabilitation, and Disability Studies at the University of Calgary, has been researching the spread of patient medical photographs in Google Image Search Results and found that in over 70 percent of case reports, at least one image from the report will be found on Google Images. Most patients do not know that they even end up in medical journals, and most clinicians do not know that their patient photographs could be found online.
“[Clinicians] wouldn't even know to warn their patients. Most of the consent forms say nothing about this. There are some consent forms that have been developed that will at least mention if you were photographed and published in a peer-reviewed journal online, [the image is] out of everybody's hands,” Marshall said. After hearing about the person whose patient photograph was found in the LAION-5B dataset, Marshall said he is trying to figure out what patients and clinicians can do to protect their images, especially as their images are now being used to train AI without their consent.
It's a case of new risks that people have not been aware of, and of course people can't keep up with the evolving web of tech bro exploiters chomping at the bit to index every image of CSEM and ISIS beheading they can get their hands on. If artists are still trying to get informed on the topic, expecting doctors who share this information for the benefit of other doctors to be hiding it behind expensive paywalls and elaborate gates just to cut off the tech bros is asinine. But regardless, if you don't want to go on a journal, now you are aware of the possibility and can not consent to it in the future.
LAION however can't be held accountable themselves because, despite facilitating abuse, they're not direct participants in the training of data, they just compiled it and served it on a gold platter. But on the bright side, The Federal Trade Commission (FTC) has begun practicing algorithmic destruction, which is demanding that companies and organizations destroy the algorithms or AI models that it has built using personal information and data collected in a bad faith or illegally. FTC Commissioner Rebecca Slaughter published a Yale Journal of Law and Technology article alongside other FTC lawyers that highlighted algorithmic destruction as an important tool that would target the ability of algorithms “to amplify injustice while simultaneously making injustice less detectable” through training their systems on datasets that already contain bias, including racist and sexist imagery.
“The premise is simple: when companies collect data illegally, they should not be able to profit from either the data or any algorithm developed using it,” they wrote in the article. “This innovative enforcement approach should send a clear message to companies engaging in illicit data collection in order to train AI models: Not worth it.”
This is likely going to be the fate of any algorithms that take advantage of the illegal data collected in LAION-5B.
So what do we take from all of this?
Please read consent forms thoroughly.
Algorithmic destruction should befall LAION-5B and I wouldn't mind if every member on the team is arrested
That's it, that's the whole thing 😊
Addendum, which I know people will ask; Am I against AI art? Well, I'm against unethical bullshit, which LAION team does plenty, and which most if not all AI algorithms are being trained on. While I hate going for the elephant in the room, capitalism is to blame for the absolutely abhorrent implementation of AI, and so it can't exist without being inherently unethical in these conditions.
2 notes
·
View notes
Text
Midjourney Is Full Of Shit
Last December, some guys from the IEEE newsletter, IEEE Spectrum whined about "plagiarism problem" in generative AI. No shit, guys, what did you expect?
But, let's get specific for a moment: they noticed that Midjourney generated very specific images from very general keywords like "dune movie 2021 trailer screencap" or "the matrix, 1999, screenshot from a movie". You'd expect that the outcome would be some kind of random clusterfuck making no sense. See for yourself:

In most of the examples depicted, Midjourney takes the general composition of an existing image, which is interesting and troubling in its own right, but you can see that for example Thanos or Ellie were assembled from some other data. But the shot from Dune is too good. It's like you asked not Midjourney, but Google Images to pull it up.
Of course, when IEEE Spectrum started asking Midjourney uncomfortable questions, they got huffy and banned the researchers from the service. Great going, you dumb fucks, you're just proving yourself guilty here. But anyway, I tried the exact same set of keywords for the Matrix one, minus Midjourney-specific commands, in Stable Diffusion (setting aspect ratio given in the MJ prompt as well). I tried four or five different data models to be sure, including LAION's useless base models for SD 1.5. I got... things like this.

It's certainly curious, for the lack of a better word. Generated by one of newer SDXL models that apparently has several concepts related to The Matrix defined, like the color palette, digital patterns, bald people and leather coats. But none of the attempts, using none of the models, got anywhere near the quality or similarity to the real thing as Midjourney output. I got male characters with Neo hair but no similarity to Keanu Reeves whatsoever. I got weird blends of Neo and Trinity. I got multiplied low-detail Neo figures on black and green digital pattern background. I got high-resolution fucky hands from an user-built SDXL model, a scenario that should be highly unlikely. It's as if the data models were confused by the lack of a solid description of even the basics. So how does Midjourney avoid it?
IEEE Spectrum was more focused on crying over the obvious fact that the data models for all the fucking image generators out there were originally put together in a quick and dirty way that flagrantly disregarded intellectual property laws and weren't cleared and sanitized for public use. But what I want to know is the technical side: how the fuck Midjourney pulls an actual high-resolution screenshot from its database and keeps iterating on it without any deviation until it produces an exact copy? This should be impossible with only a few generic keywords, even treated as a group as I noticed Midjourney doing a few months ago. As you can see, Stable Diffusion is tripping absolute motherfucking balls in such a scenario, most probably due to having a lot of images described with those keywords and trying to fit elements of them into the output image. But, you can pull up Stable Diffusion's code and research papers any time if you wish. Midjourney violently refuses to reveal the inner workings of their algorithm - probably less because it's so state-of-the-art that it recreates existing images without distortions and more because recreating existing images exactly is some extra function coded outside of the main algorithm and aimed at reeling in more schmucks and their dollars. Otherwise, there wouldn't be that much of a quality jump between movie screenshots and original concepts that just fall apart into a pile of blorpy bits. Even more coherent images like the grocery store aisle still bear minor but noticeable imperfections caused by having the input images pounded into the mathemagical fairy dust of random noise. But the faces of Dora Milaje in the Infinity War screenshot recreations don't devolve into rounded, fractal blorps despite their low resolution. Tubes from nasal plugs in the Dune shot run like they should and don't get tangled with the hairlines and stitches on the hood. This has to be some kind of scam, some trick to serve the customers hot images they want and not the predictable train wrecks. And the reason is fairly transparent: money. Rig the game, turn people into unwitting shills, fleece the schmucks as they run to you with their money hoping that they'll always get something as good as the handful of rigged results.
0 notes
Text
Open Source Javascript Tables
Recently I came across a bunch of expensive plugins for Wordpress. They were focused on tables. I get it, it takes time to build plugins, but they were expensive.
So I wondered whether there are Javascript tools for tables. You know, to display on my website.

And guess what, I found a few that I'd like to try out someday.
ISOTOPE by MetaFizzy
While checking out websites that were using WPDataTables, I came across City Colleges of Chicago website. They were using this for their course search page. You can have build filters to easily identify the relevant data from the non-relevant.

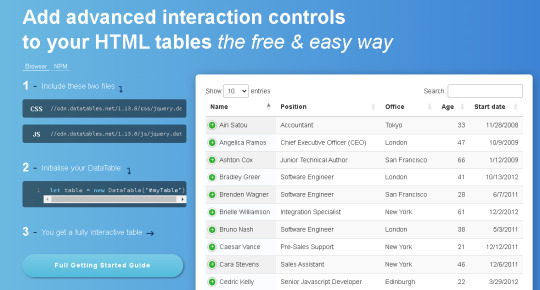
DataTables.net
This tool is free to use, and converts HTML Tables to searchable ones. However, the HTML table must have the tags, <thead> and <tbody>. The <table> must also be identified as having an "id", and a class of "display". I think this has a lot of potential, but you need to convert data to HTML format. That would mean CSV to HTML, and ensuring that the HTML has the proper tagging.
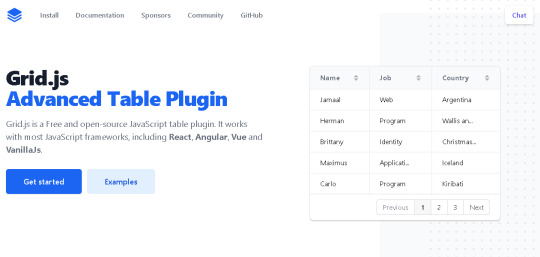
GRID.JS
This is a really nice Javascript library that I'd like to use, if I could. It's free and open source. I think there are some premium tutorials written by an Indian guy, on how to incorporate it into a Wordpress site. The data should be in JSON format. It would load faster then JQuery DataTables. I think I like this a lot.
Tabulator
An open source project with many plugins, it seems that it's great for use in a Wordpress site. But I'm not sure how many rows it can handle.

FooTable
A useful Javascript table framework built for Bootstrap. It's not the only one, but it was a good effort. My concern for this is how to input the data and how many rows it can handle.

Bootstrap Table
This is the other one that was built with Bootstrap in mind. Now that Elon Musk has taken over Twitter, I'm not sure about the future of Twitter Bootstrap. But it's a good project that has given a lot of help to web developers. I hope that Bootstrap survives Elon's reign.

Datasette
Not sure if Datasette is a Javascript framework that I could use easily, but it powers certain high profile websites, like the LAION database website. That is the data set that powers Stable Diffusion, so it's a pretty big deal. Might be the most complex, yet high impact, tool of the lot.

Conclusion
These are just a few of the Javascript libraries that I could find for tables. Ideally, I would one day like to run my own instance of an online spreadsheet software. And use that to embed data into my website. But it may be just a dream. Meanwhile do check out my main site.
0 notes
Last Seen Blogs




