#ai discourse
Text
people often use the term "ethical AI" to describe AI that avoids training on any copyrighted material without permission from the copyright holder
given that this idea is based around protecting existing investments and would primarily serve to benefit large companies that own massive media libraries, I propose instead describing it as "capitalist AI"
34 notes
·
View notes
Text
The AI issue is what happens when you raise generation after generation of people to not respect the arts. This is what happens when a person who wants to major in theatre, or English lit, or any other creative major gets the response, "And what are you going to do with that?" or "Good luck getting a job!"
You get tech bros who think it's easy. They don't know the blood, sweat, and tears that go into a creative endeavor because they were taught to completely disregard that kind of labor. They think they can just code it away.
That's (one of the reasons) why we're in this mess.
18K notes
·
View notes
Text
all the frothing-at-the-mouth posts about how "don't you dare put a fic writer's work into chatGPT or an artist's work into stable diffusion" are. frustrating
that isn't how big models are made. it takes an absurd amount of compute power and coordination between many GPUs to re-train a model with billions of parameters. they are not dynamically crunching up anything you put into a web interface.
chances are, if you have something published on a fanfic site, or your art is on deviantart or any publicly available repository, it's already in the enormous datasets that they are using to train. and if it isn't in now, it will be in future: the increases in performance from GPT 2 to 3 to 4 were not gained through novel machine-learning architectures or anything but by ramping up the amount of data they used to train by orders of magnitude. if it can be scraped, just assume it will be. you can prevent your stuff from being used with Glaze, if you're an artist, but for the written word there's nothing you can do.
not to be cynical but the genie is already far more out of the bottle than most anti-AI people realize, i think. there is nothing you can do to stop these models from being made and getting more powerful. only the organizing power of labor has a shot at mitigating some of the effects we're all worried about
10K notes
·
View notes
Text

11K notes
·
View notes
Note
How exactly do you advance AI ethically? Considering how much of the data sets that these tools use was sourced, wouldnt you have to start from scratch?
a: i don't agree with the assertion that "using someone else's images to train an ai" is inherently unethical - ai art is demonstrably "less copy-paste-y" for lack of a better word than collage, and nobody would argue that collage is illegal or ethically shady. i mean some people might but i don't think they're correct.
b: several people have done this alraedy - see, mitsua diffusion, et al.
c: this whole argument is a red herring. it is not long-term relevant adobe firefly is already built exclusively off images they have legal rights to. the dataset question is irrelevant to ethical ai use, because companies already have huge vaults full of media they can train on and do so effectively.
you can cheer all you want that the artist-job-eating-machine made by adobe or disney is ethically sourced, thank god! but it'll still eat everyone's jobs. that's what you need to be caring about.
the solution here obviously is unionization, fighting for increased labor rights for people who stand to be affected by ai (as the writer's guild demonstrated! they did it exactly right!), and fighting for UBI so that we can eventually decouple the act of creation from the act of survival at a fundamental level (so i can stop getting these sorts of dms).
if you're interested in actually advancing ai as a field and not devils advocating me you can also participate in the FOSS (free-and-open-source) ecosystem so that adobe and disney and openai can't develop a monopoly on black-box proprietary technology, and we can have a future where anyone can create any images they want, on their computer, for free, anywhere, instead of behind a paywall they can't control.
fun fact related to that last bit: remember when getty images sued stable diffusion and everybody cheered? yeah anyway they're releasing their own ai generator now. crazy how literally no large company has your interests in mind.
cheers
2K notes
·
View notes
Text
head up if you don’t want tumblrs partnered ai companies automatically scraping your blog for image datasets, you need to manually opt out.
You can’t do this in the app rn (apparently you can but I couldn’t find it so you might have to update), only the desktop version or web browser on your phone. It will also need to be done for every sideblog you have.
You find it by opening up your blog settings > scroll down to visibility > prevent third party sharing
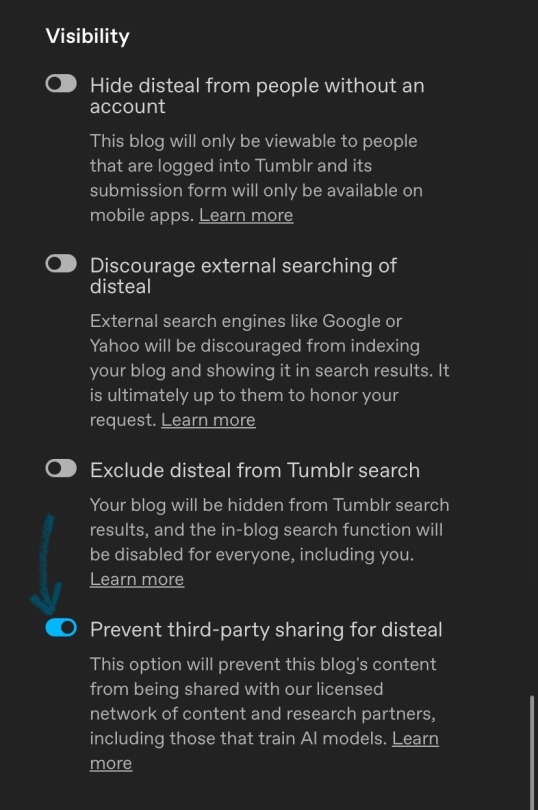
As an aside, I’d thoroughly recommend opting out of having your blog scraped, even if you’re not an artist. Afaik Tumblr hasn’t explicitly stated which companies they’ll be partnering with, but the vagueness of that wording is really alarming.
These datasets use a lot of selfies for photorealistic results, moderation of who has access to these datasets is notoriously ass, and a lot of AI engines are being used to generate pornography and racist imagery (you can see this rn with the rise of ai generated propaganda). While ‘your likeness is used in an awful generated image without your consent’ IS a worst case scenario, it’s a really upsetting one. Protect yourselves.
#dis.txt#ai discourse#ik this is all on tumblr faq but i can’t stomach reblogging their ridiculous staff post#it’s not staffs fault bc matt has been salivating at the chance for this for months now apparently#but the language rly cushions from how shit this is#faq
1K notes
·
View notes
Note
nightshade is basically useless https://www.tumblr.com/billclintonsbeefarm/740236576484999168/even-if-you-dont-like-generative-models-this
I'm not a developer, but the creators of Nightshade do address some of this post's concerns in their FAQ. Obviously it's not a magic bullet to prevent AI image scraping, and obviously there's an arms race between AI developers and artists attempting to disrupt their data pools. But personally, I think it's an interesting project and is accessible to most people to try. Giving up on it at this stage seems really premature.
But if it's caption data that's truly valuable, Tumblr is an ... interesting ... place to be scraping it from. For one thing, users tend to get pretty creative with both image descriptions and tags. For another, I hope whichever bot scrapes my blog enjoys the many bird photos I have described as "Cheese." Genuinely curious if Tumblr data is actually valuable or if it's garbage.
That said, I find it pretty ironic that the OP of the post you linked seems to think nightshade and glaze specifically are an unreasonable waste of electricity. Both are software. Your personal computer's graphics card is doing the work, not an entire data center, so if your computer was going to be on anyway, the cost is a drop in the bucket compared to what AI generators are consuming.
Training a large language model like GPT-3, for example, is estimated to use just under 1,300 megawatt hours (MWh) of electricity; about as much power as consumed annually by 130 US homes. To put that in context, streaming an hour of Netflix requires around 0.8 kWh (0.0008 MWh) of electricity. That means you’d have to watch 1,625,000 hours to consume the same amount of power it takes to train GPT-3. (source)
So, no, I don't think Nightshade or Glaze are useless just because they aren't going to immediately topple every AI image generator. There's not really much downside for the artists interested in using them so I hope they continue development.
973 notes
·
View notes
Text
So, there's a dirty little secret in indie publishing a lot of people won't tell you, and if you aren't aware of it, self-publishing feels even scarier than it actually is.
There's a subset of self-published indie authors who write a ludicrous number of books a year, we're talking double digit releases of full novels, and these folks make a lot of money telling you how you can do the same thing. A lot of them feature in breathless puff pieces about how "competitive" self-publishing is as an industry now.
A lot of these authors aren't being completely honest with you, though. They'll give you secrets for time management and plotting and outlining and marketing and what have you. But the way they're able to write, edit, and publish 10+ books a year, by and large, is that they're hiring ghostwriters.
They're using upwork or fiverr to find people to outline, draft, edit, and market their books. Most of them, presumably, do write some of their own stuff! But many "prolific" indie writers are absolutely using ghostwriters to speed up their process, get higher Amazon best-seller ratings, and, bluntly, make more money faster.
When you see some godawful puff piece floating around about how some indie writer is thinking about having to start using AI to "stay competitive in self-publishing", the part the journalist isn't telling you is that the 'indie writer' in question is planning to use AI instead of paying some guy on Upwork to do the drafting.
If you are writing your books the old fashioned way and are trying to build a readerbase who cares about your work, you don't need to use AI to 'stay competitive', because you're not competing with these people. You're playing an entirely different game.
721 notes
·
View notes
Text
Even skipping all of the discourse
I'll never understand why Ai "artists" call themselves artists.
"but I've put the input 🥺"
What the fuck are you saying, if I go and buy a pizza and ask them to make changes that doesn't make me a pizza maker does it?
I don't go around and say "omg look I made this pizza guys" because I didn't make it.
Obviously with ai art is worse because you didn't even pay a human being and it's using stolen informations but.
I just don't see the logic. I'm not a pizza maker. You're not an ai artist
#an ai user if you want#ai discourse#“oh but i put ”generic anime girl playing basketball“ in the bar so i did it” no you didn't#“sorry could you put some potato chips on my pizza” i am a chef
383 notes
·
View notes
Text

There's LITERALLY no excuse to continue using technology that has ruined people's careers and livelihoods just to make a bloody painting.
#ahsoka tano#star wars ahsoka#ahsoka#huyang#star wars#sw ahsoka#ai art#no ai art#support human artists#ai art is not art#ahsoka series#ahsoka show#ai art is theft#fuck ai everything#ai artwork#ai discourse#anti ai art#anti ai#autistic artist#writers strike#hollywood strike
588 notes
·
View notes
Text
AI.
It has now happened twice that Auri's dialogue has been either added to, or entirely replaced with AI-generated dialogue.
Please don't do that.
I have written these lines from my heart, spent hours getting the delivery just right, with the intended amount of emotion. I know it's annoying that there are unvoiced lines, I'm doing my best to get to them eventually. I know Auri doesn't have as many lines as the other followers, I'm a slow worker and not very skilled at writing "filler" dialogue. Using AI to patch these things makes me feel very sad and disrespected. I'm doing my best.
Thank you.
291 notes
·
View notes
Text

Hey, you know how I said there was nothing ethical about Adobe's approach to AI? Well whaddya know?
Adobe wants your team lead to contact their customer service to not have your private documents scraped!
This isn't the first of Adobe's always-online subscription-based products (which should not have been allowed in the first place) to have sneaky little scraping permissions auto-set to on and hidden away, but this is the first one (I'm aware of) where you have to contact customer service to turn it off for a whole team.
Now, I'm on record for saying I see scraping as fair use, and it is. But there's an aspect of that that is very essential to it being fair use: The material must be A) public facing and B) fixed published work.
All public facing published work is subject to transformative work and academic study, the use of mechanical apparatus to improve/accelerate that process does not change that principle. Its the difference between looking through someone's public instagram posts and reading through their drafts folder and DMs.
But that's not the kind of work that Adobe's interested in. See, they already have access to that work just like everyone else. But the in-progress work that Creative Cloud gives them access to, and the private work that's never published that's stored there isn't in LIAON. They want that advantage.
And that's valuable data. For an example: having a ton of snapshots of images in the process of being completed would be very handy for making an AI that takes incomplete work/sketches and 'finishes' it. That's on top of just being general dataset grist.
But that work is, definitionally, not published. There's no avenue to a fair use argument for scraping it, so they have to ask. And because they know it will be an unpopular ask, they make it a quiet op-out.
This was sinister enough when it was Photoshop, but PDF is mainly used for official documents and forms. That's tax documents, medical records, college applications, insurance documents, business records, legal documents. And because this is a server-side scrape, even if you opt-out, you have no guarantee that anyone you're sending those documents to has done so.
So, in case you weren't keeping score, corps like Adobe, Disney, Universal, Nintendo, etc all have the resources to make generative AI systems entirely with work they 'own' or can otherwise claim rights to, and no copyright argument can stop them because they own the copyrights.
They just don't want you to have access to it as a small creator to compete with them, and if they can expand copyright to cover styles and destroy fanworks they will. Here's a pic Adobe trying to do just that:

If you want to know more about fair use and why it applies in this circumstance, I recommend the Electronic Frontier Foundation over the Copyright Alliance.
169 notes
·
View notes
Text
There's a nuance to the Amazon AI checkout story that gets missed.

Because AI-assisted checkouts on its own isn't a bad thing:

This was a big story in 2022, about a bread-checkout system in Japan that turned out to be applicable in checking for cancer cells in sample slides.
But that bonus anti-cancer discovery isn't the subject here, the actual bread-checkout system is. That checkout system worked, because it wasn't designed with the intent of making the checkout cashier obsolete, rather, it was there to solve a real problem: it's hard to tell pastry apart at a glance, and the customers didn't like their bread with a plastic-wrapping and they didn't like the cashiers handling the bread to count loaves.
So they trained the system intentionally, under controlled circumstances, before testing and launching the tech. The robot does what it's good at, and it doesn't need to be omniscient because it's a tool, not a replacement worker.
Amazon, however, wanted to offload its training not just on an underpaid overseas staff, but on the customers themselves. And they wanted it out NOW so they could brag to shareholders about this new tech before the tech even worked. And they wanted it to replace a person, but not just the cashier. There were dreams of a world where you can't shoplift because you'd get billed anyway dancing in the investor's heads.
Only, it's one thing to make a robot that helps cooperative humans count bread, and it's another to try and make one that can thwart the ingenuity of hungry people.
The foreign workers performing the checkouts are actually supposed to be training the models. A lot of reports gloss over this in an effort to present the efforts as an outsourcing Mechanical Turk but that's really a side-effect. These models all work on datasets, and the only place you get a dataset of "this visual/sensor input=this purchase" is if someone is cataloging a dataset correlating the two...
Which Amazon could have done by simply putting the sensor system in place and correlating the purchase data from the cashiers with the sensor tracking of the customer. Just do that for as long as you need to build the dataset and test it by having it predict and compare in the background until you reach your preferred ratio. If it fails, you have a ton of market research data as a consolation prize.
But that could take months or years and you don't get to pump your stock until it works, and you don't get to outsource your cashiers while pretending you've made Westworld work.
This way, even though Amazon takes a little bit of a PR bloody nose, they still have the benefit of any stock increase this already produced, the shareholders got their dividends.
Which I suppose is a lot of words to say:

#amazon AI#ai discourse#amazon just walk out#just walk out#the only thing that grows forever is cancer#capitalism#amazon
129 notes
·
View notes
Text

art is work. If you didn't put in hard work it's not art. If you didn't bleed then you're taking shortcuts. you have to put in "effort" or your art is worthless. if you don't have a work ethic then you're worthy of derision. if you are unwilling or unable to suffer then you are unworthy of making art
this is so, so obviously a conservative, reactionary sentiment. This is what my fucking dad says about Picasso. "They just want to push the button" is word-for-word what people used to say about electronic music - not "real" instruments, no talent involved, no skill, worthless. how does this not disturb more people? this should disturb you! is everyone just seeing posts criticizing AI and slamming reblog without reading too close, or do people actually agree with this?
usual disclaimer: this is not a "pro-ai" stance. this is a "think about what values you actually have" stance. there are many more coherent ways to criticize it
1K notes
·
View notes
Text
"how do I keep my art from being scraped for AI from now on?"
if you post images online, there's no 100% guaranteed way to prevent this, and you can probably assume that there's no need to remove/edit existing content. you might contest this as a matter of data privacy and workers' rights, but you might also be looking for smaller, more immediate actions to take.
...so I made this list! I can't vouch for the effectiveness of all of these, but I wanted to compile as many options as possible so you can decide what's best for you.
Discouraging data scraping and "opting out"
robots.txt - This is a file placed in a website's home directory to "ask" web crawlers not to access certain parts of a site. If you have your own website, you can edit this yourself, or you can check which crawlers a site disallows by adding /robots.txt at the end of the URL. This article has instructions for blocking some bots that scrape data for AI.
HTML metadata - DeviantArt (i know) has proposed the "noai" and "noimageai" meta tags for opting images out of machine learning datasets, while Mojeek proposed "noml". To use all three, you'd put the following in your webpages' headers:
<meta name="robots" content="noai, noimageai, noml">
Have I Been Trained? - A tool by Spawning to search for images in the LAION-5B and LAION-400M datasets and opt your images and web domain out of future model training. Spawning claims that Stability AI and Hugging Face have agreed to respect these opt-outs. Try searching for usernames!
Kudurru - A tool by Spawning (currently a Wordpress plugin) in closed beta that purportedly blocks/redirects AI scrapers from your website. I don't know much about how this one works.
ai.txt - Similar to robots.txt. A new type of permissions file for AI training proposed by Spawning.
ArtShield Watermarker - Web-based tool to add Stable Diffusion's "invisible watermark" to images, which may cause an image to be recognized as AI-generated and excluded from data scraping and/or model training. Source available on GitHub. Doesn't seem to have updated/posted on social media since last year.
Image processing... things
these are popular now, but there seems to be some confusion regarding the goal of these tools; these aren't meant to "kill" AI art, and they won't affect existing models. they won't magically guarantee full protection, so you probably shouldn't loudly announce that you're using them to try to bait AI users into responding
Glaze - UChicago's tool to add "adversarial noise" to art to disrupt style mimicry. Devs recommend glazing pictures last. Runs on Windows and Mac (Nvidia GPU required)
WebGlaze - Free browser-based Glaze service for those who can't run Glaze locally. Request an invite by following their instructions.
Mist - Another adversarial noise tool, by Psyker Group. Runs on Windows and Linux (Nvidia GPU required) or on web with a Google Colab Notebook.
Nightshade - UChicago's tool to distort AI's recognition of features and "poison" datasets, with the goal of making it inconvenient to use images scraped without consent. The guide recommends that you do not disclose whether your art is nightshaded. Nightshade chooses a tag that's relevant to your image. You should use this word in the image's caption/alt text when you post the image online. This means the alt text will accurately describe what's in the image-- there is no reason to ever write false/mismatched alt text!!! Runs on Windows and Mac (Nvidia GPU required)
Sanative AI - Web-based "anti-AI watermark"-- maybe comparable to Glaze and Mist. I can't find much about this one except that they won a "Responsible AI Challenge" hosted by Mozilla last year.
Just Add A Regular Watermark - It doesn't take a lot of processing power to add a watermark, so why not? Try adding complexities like warping, changes in color/opacity, and blurring to make it more annoying for an AI (or human) to remove. You could even try testing your watermark against an AI watermark remover. (the privacy policy claims that they don't keep or otherwise use your images, but use your own judgment)
given that energy consumption was the focus of some AI art criticism, I'm not sure if the benefits of these GPU-intensive tools outweigh the cost, and I'd like to know more about that. in any case, I thought that people writing alt text/image descriptions more often would've been a neat side effect of Nightshade being used, so I hope to see more of that in the future, at least!
224 notes
·
View notes
Text
re: why nightshade/glaze is useless, aka "the chicken is already in the nugget", from the perspective of an Actual Machine Learning Researcher
a bunch of people have privately asked me to answer this aspect of the five points i raised, and i tire of repeating myself, so

the fundamental oversight here is a lack of recognition that these AI models are not dynamic entities constantly absorbing new data; they are more akin to snapshots of the internet at the time they were trained, which, for the most part, was several years ago.
to put it simply, Nightshade's efforts to alter images and introduce them to the AI in hopes of affecting the model's output are based on an outdated concept of how these models function. the belief that the AI is actively scraping the internet and updating its dataset with new images is incorrect. the LAION datasets, which are the foundation of most if not all modern image synthesis models, were compiled and solidified into the AI's 'knowledge base' long ago. The process is not ongoing; it's historical.

i think it's important for people to understand that Nightshade is fighting is against an already concluded war. the datasets have been created, the models have been trained, and the 'internet scraping' phase is not an ongoing process for these AI. the notion that AI is an ever-updating Skynet seeking to cannibalize all your art (or that the companies using it are constantly seeking out new art to add to the pile) is a science fiction myth, not a reality.
(for the many other reasons why it won't work see my other post. really i just wanted an excuse to make and post these two sloppy meme edits).
cheers
1K notes
·
View notes
Last Seen Blogs




