#Unsupervised Learning
Text
Tim Drake's eating habits as an unsupervised child
Just imagine little Tim Drake all alone in his big mansion making food for himself for the first time. He's like maybe 8 and no 8 year old has a sophisticated palate no matter their tax bracket. So, TIm just has the most horrific food tastes known to man. Like he comes over to Wayne Manor for brunch and he's giving Alfred a heart attack as the butler watches this 14 year old spread jelly and marshmallow fluff onto handmade, wholegrain waffles. The first time he spends the night with Kon at the Kent Farm he's nearly taken straight back to Gotham because he's dipping Ma's famous fried chicken in soy sauce. He gets a whole article in the Gotham Gazette when he gets papped eating a hot dog with chocolate sauce and mustard (#choccymustard trends on Gotham twitter for a week). This kid has the most unhinged palate and the best part is up until Robin he doesn't really understand it because there is no one there to tell him it's weird and rich people eat weird shit all the time. He's just living his life eating waffles with jam and hotdogs with chocolate sauce because that sounded delicious to 8 year old Timothy Drake. Bruce just immediately accepted it like he did with Dick's incilination to climb every chandelier ever or Jason's penchant for making mix tapes (like honest to god cd mix tapes) of audiobooks with wild ass names and leaving them around the manor. Everyone else is horrified though.
#tim drake#bruce wayne#jason todd#dick grayson#richard grayson#food#unsupervised learning#alfred pennyworth#get this child some real food#choccymustard#gotham social media clowns on tim drake#time drake clowns on time drake
244 notes
·
View notes
Text
Hyperparameter tuning in machine learning
The performance of a machine learning model in the dynamic world of artificial intelligence is crucial, we have various algorithms for finding a solution to a business problem. Some algorithms like linear regression , logistic regression have parameters whose values are fixed so we have to use those models without any modifications for training a model but there are some algorithms out there where the values of parameters are not fixed.
Here's a complete guide to Hyperparameter tuning in machine learning in Python!
#datascience #dataanalytics #dataanalysis #statistics #machinelearning #python #deeplearning #supervisedlearning #unsupervisedlearning
#machine learning#data analysis#data science#artificial intelligence#data analytics#deep learning#python#statistics#unsupervised learning#feature selection
3 notes
·
View notes
Text
Decoding the Mind of Artificial Intelligence: Understanding How AI Thinks
#ArtificialIntelligence #MachineLearning #DeepLearning #SupervisedLearning #UnsupervisedLearning #ReinforcementLearning #NeuralNetworks #Data #Algorithm #AIlimitations #AImodel
Artificial Intelligence (AI) has come a long way in recent years. From the early days of rule-based systems to the current state-of-the-art machine learning models, AI has evolved to be able to tackle increasingly complex tasks. But have you ever wondered about how AI thinks?
At the core of AI is the ability to learn from data. Machine learning algorithms are used to train AI models on large…

View On WordPress
#AI#AI limitations#AI model#Algorithm#artificial intelligence#Data#Deep Learning#future of AI#machine learning#neural networks#Reinforcement Learning#Supervised Learning#Unsupervised Learning
2 notes
·
View notes
Text
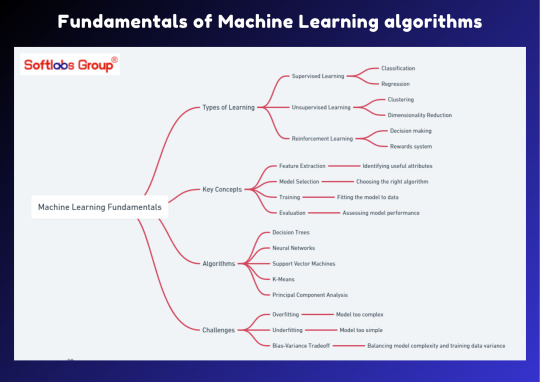
Discover the fundamentals of Machine Learning algorithms through our comprehensive guide. This simplified overview breaks down the essential principles behind ML algorithms, making it easier to grasp their concepts and applications. Perfect for anyone eager to delve into the world of artificial intelligence. Stay informed with Softlabs Group for more insightful content on cutting-edge technologies.
0 notes
Text
Unsupervised learning is a branch of artificial intelligence that involves the training of an algorithm on unstructured data. Unstructured data is defined as data that does not have any predefined categorizations or labels.
#Unsupervised Learning Market#Unsupervised Learning Market size#Unsupervised Learning#Unsupervised machine Learning
0 notes
Text
Unsupervised Learning | PythonGUI
Unsupervised learning is a type of machine learning where the model learns patterns and structures from unlabeled data without any predefined target variable. Its goal is to discover the underlying structure or relationships within the data. If you want to know more about Unsupervised Learning, take a look at this blog.

0 notes
Text

Probabilistic model-based clustering is an excellent approach to understanding the trends that may be inferred from data and making future forecasts. The relevance of model based clustering, one of the first subjects taught in data science, cannot be overstated. These models serve as the foundation for machine learning models to comprehend popular trends and their behavior. You can also learn about neural network guides and python for data science if you are interested in further career prospects of data science.
#Clustering#Data Mining#Machine Learning#Probabilistic Models#Model-Based Clustering#Gaussian Mixture Models#Expectation-Maximization Algorithm#Unsupervised Learning#Data Analysis#Pattern Recognition#Data Science#Bayesian Methods#Hidden Markov Models#Statistical Learning#Cluster Analysis.
0 notes
Text
Artificial Intelligence Engineering: Building Intelligent Systems | Coders
Looking to build intelligent systems using Artificial Intelligence? Our AI engineering course provides you with the essential concepts and techniques to build intelligent systems that solve complex problems. From understanding the fundamentals of machine learning and neural networks to natural language processing and computer vision, our course covers everything you need to know. Join Coders today and learn how to build intelligent systems that can revolutionize your industry.
Read More-: artificial intelligence engineering
#machine learning#deep learning#reinforcement learning#unsupervised learning#machine learning algorithms#machine learning engineer#machine learning models#ml engineer#artificial intelligence engineering#ai learning#machine learning experts
0 notes
Text
Transform Your Business with Advanced Automation
Machine Learning is a branch of Artificial Intelligence (AI) that is focused on enabling computers to learn from experience. It is a type of algorithm that enables the computers to automatically learn and improve from experience without being explicitly programmed. Machine Learning algorithms are used to build predictive models and make predictions from data. It can be used to identify patterns…

View On WordPress
#artificial intelligence#classification#clustering#data mining#deep learning#natural language processing#neural networks#pattern recognition#predictive analytics#regression#reinforcement learning#supervised learning#unsupervised learning
1 note
·
View note
Text
Unleashing the Power of Machine Learning in the 21st Century
Machine learning is one of the most talked about and rapidly growing fields in the tech industry. It is a branch of artificial intelligence that allows computers to learn and make predictions or decisions without explicit programming. The rise of big data and the increasing availability of computing power have made it possible for machine learning algorithms to handle vast amounts of data and provide valuable insights and predictions.
In recent years, machine learning has been applied in various industries, ranging from healthcare to finance, retail, and marketing. In healthcare, machine learning algorithms are used to analyze patient data and help doctors make more accurate diagnoses. In finance, machine learning is used to detect fraud, analyze financial markets, and make investment decisions. In retail, machine learning is used to personalize shopping experiences, recommend products, and optimize pricing.
One of the key benefits of machine learning is that it allows for automated decision-making, which can save time and resources. Machine learning algorithms can analyze large amounts of data and provide insights in real-time, enabling organizations to make data-driven decisions more efficiently. Additionally, machine learning algorithms are able to improve over time, becoming more accurate as they are exposed to more data.
Despite its many advantages, machine learning is not without its challenges. One of the main challenges is the lack of transparency in decision-making. It can be difficult to understand how machine learning algorithms arrived at a particular decision, making it difficult to explain the decision to stakeholders. Additionally, machine learning algorithms can be biased if the data used to train them is biased, leading to unfair or inaccurate decisions.
In conclusion, machine learning is a powerful tool that has the potential to transform the way we live and work. As the technology continues to evolve and improve, we can expect to see more and more applications of machine learning in various industries. However, it is important to approach machine learning with caution and ensure that the algorithms are developed and used in a transparent and ethical manner.
#Machine Learning#Artificial Intelligence#Data Science#Predictive Modeling#Deep Learning#Neural Networks#Natural Language Processing#Image Recognition#Predictive Analytics#Big Data#Supervised Learning#Unsupervised Learning#Reinforcement Learning#Predictive Maintenance#Recommender Systems#Fraud Detection#Predictive Marketing#Healthcare AI#Computer Vision#Predictive Sales#Predictive Quality Control#Predictive Logistics
0 notes
Text
Tic Tac Toe Game In Python
This is my first small Python project where I built a tac-tac-toe game in Python, we have played a lot in small classes while sitting at the last bench some of us have played at the first bench too. It is a very famous game that we are building today after the completion of this project we can play with our friends with the project we have made.
Here's a complete guide to the Tic-tac-toe game in Python!
#datascience #dataanalytics #dataanalysis #statistics #machinelearning #python #deeplearning #supervisedlearning #unsupervisedlearning
#machine learning#data analysis#data science#artificial intelligence#data analytics#deep learning#python#statistics#unsupervised learning#feature selection
0 notes
Text
Helm.ai Raises $31 Million in Series C Funding Round for Autonomous Vehicle Softwar
Helm.ai Raises $31 Million in Series C Funding Round for Autonomous Vehicle Softwar
Helm.ai is a startup based in Menlo Park, California that is developing software for advanced driver assistance systems, autonomous driving, and robotics. The company recently raised $31 million in a Series C round, led by Freeman Group, pushing its valuation to $431 million.
The company has developed software that can understand sensor data as well as a human, using an unsupervised learning…

View On WordPress
#ACVC Partners#advanced driver assistance systems#Amplo#autonomous driving#autonomous vehicles#commercial partnerships#Freeman Group#funding#Goodyear Ventures#Helm.ai#Honda Motor Co.#neural networks#OEMs#R&D#Series C#software#Sungwoo Hitech#Tier 1 suppliers#unsupervised learning#valuation
1 note
·
View note
Text
0 notes
Text
Applications of Machine Learning's Clustering Techniques in Everyday Life
Data mining, web cluster engines, academia, bioinformatics, image processing & transformation, and many more fields or areas of real-life examples can all apply clustering techniques, which have proven to be a successful solution in the sectors mentioned above. Applications of machine learning can also be seen in daily life. The following list includes some typical application platforms where clustering as a tool can be used.
Recommendation engines
Collaborative filtering is one of the well-known recommendation systems and approaches, whereas the recommendation system is a frequently used way of automating individualised suggestions concerning goods, services, and information. The clustering process in this method indicated consumers who shared similar interests. The performance of collaborative filtering techniques is enhanced by utilising the computation/estimation as data supplied by multiple users. And this can be used in a variety of applications to generate recommendations. The recommendation engine, for instance, is frequently used on Amazon, Flipkart, and Youtube to propose products and songs of the same genre. In collaborative filtering algorithms, dealing with large amounts of data clustering is the first step in reducing the pool of underlying relevant neighbours. However, doing so also improves the efficiency of sophisticated recommendation engines. In essence, based on the preferences of customers who are members of the cluster, each cluster will be given to particular preferences. Customers would subsequently receive recommendations approximated at the cluster level inside each cluster.

Market and Customer segmentation
Market segmentation is the process of dividing the target market into more narrowly defined subgroups. This divides clients/audiences into groups with comparable traits; target and personalisation fall under it. For instance, it's important to target clients correctly if a business wants to receive the best return on investment. If wrongdoing is committed, there is a significant risk of losing all sales and losing the faith of customers. The best action is to focus on people who exhibit particular traits and engage them in campaigns that will assist those who show them. Algorithms for clustering can group people with similar features and potential customers. For instance, you can send marketing content to each group as a test campaign after the groups are established. Depending on how well it performs, you can send them further targeted communications in the future. Various groups of clients are created based on their unique qualities under the customer segmentation application. A business can pinpoint prospective buyers of its goods or services based on user-based analysis. In this sector, the clustering method creates groups of identical customers, and while there is a little difference, it is pretty similar to collaborative filtering. Instead of rating or reviews for grouping, distinguishing qualities of the items are used in this case. Using clustering techniques, we may divide clients into various clusters based on which businesses can consider implementing novel customer-focused tactics. For instance, K-means clustering aids marketers in expanding their consumer base, focusing on specific regions, and segmenting customers according to past purchases, interests, or activities. Another illustration is a telecom business that gathers prepaid customers to study patterns and behaviour related to internet usage, SMS transmission, and recharge amounts. This aids a company in creating user segments and organising promotions.
Social Network Analysis (SNA)
It is the process of using networks and graph theory to examine both qualitative and quantitative social systems. Here, the structure of social networks is mapped out in terms of nodes and the edges, or ties, that bind them together. The link and conflicts between individuals, groups, organisations, businesses, computer networks, and other similarly connected information/knowledge entities must be mapped and measured using clustering methodologies. Clustering analysis can summarise social networks and offer a quantitative study and display of such linkages. For instance, analysing the positioning and clustering of network actors is required to comprehend a network and its participants. Individuals, professional groups, departments, companies, or any sizable system-level entity can serve as actors. Now that SNA has developed a clustering approach, it can visualise participant interaction and get insights into various network roles and groupings, including who acts as a connector, bridge, or expert, an isolated actor, and other comparable data. It also identifies the locations of clusters, the individuals involved, and the network's core nodes and periphery.
Search Result Clustering
You must have experienced similar results received while seeking something particular at Google. There are a variety of similar matches to your original query in these results. The outcome of clustering is this. It creates clusters of related objects in groups. It presents them to you in the form of the most closely connected things grouped inside the data to be searched. The likelihood of reaching the desired outputs of the leading desk increases with the quality of the clustering method used. As a result, the idea of related objects is fundamental to obtaining search results. Even though most of the factors are considered while defining the portrait of associated objects. The data is assigned to a single cluster based on the closest similar items or features, providing users with a wide range of related results. In plain English, the search engine makes an effort to place like objects in one cluster and dissimilar objects in another.
Biological Data Analysis, Medical Imaging Analysis and Identification of Cancer Cells
Analyzing biological data to thoroughly comprehend the linkages found to be connected with experimental observations is one way to relate analytical tools with biological information. Furthermore, because biological data is organized in networks or sequences, clustering techniques are essential for spotting striking similarities. On the other hand, in recent years, the application of human genome research and the growing ability to compile a variety of gene expression data have dramatically advanced biological data analysis. The primary goals of clustering are to provide prediction and description of data structure from large datasets collected in biology and other life sciences, such as medicine or neuroscience. Clustering methods can be used to find cancerous datasets. Depending on the algorithms producing the final clusters, a mixture of cancerous and non-cancerous data can be evaluated using clustering algorithms to understand the various qualities contained in the dataset. By feeding tumour datasets into unsupervised clustering algorithms, we produce accurate results.
Learn Clustering on Python
Check out the course Cluster Analysis: Unsupervised Machine Learning in Python to learn how to build clustering in Python. You will learn the fundamentals of cluster analysis before examining a selection of common clustering approaches, algorithms, and applications. Additionally, techniques for clustering validation and clustering quality assessment will be taught to you.
0 notes
Text
hc that most of tyler's job as a red involves keeping certain teammates alive outside the suits
ivan, to koda, holding a knife to a socket: perhaps this blade shall be a sufficient size!
tyler, vaulting over a table: NO NO NO NO NO
#power rangers#power rangers dino charge#dino charge#tyler navarro#ivan of zandar#koda power rangers#mighty morphin power rangers#headcanon#power rangers incorrect quotes#incorrect power rangers quotes#incorrect quotes#theyre some of the most capable people tylers ever met but god forbid he leave them unsupervised#they’re still learning it’s okay
59 notes
·
View notes
Last Seen Blogs

bloggerinme
Abhishek Chaudhary

natalyakrasavinanatalee
Natalya Krasavina vs Natalee

dementiadesignforum-blog
The Care Home Designer

vesensude
VesenSude

jupiterhospitalmumbai
Jupiter Hospital Mumbai