#structured and unstructured data
Text
Learn best practices for using data to grow your B2B company. The bizkonnect Blog offers the latest insights and tactics for sales and marketing professionals
#lead qualification#applicant tracking software#HR technology#graph database#structured and unstructured data#Natural language processing techniques#web crawler#recruiting solutions
0 notes
Photo

It is important for businesses to manage their data effectively. What is the first thing that comes to your mind when you read “business data”? You instantly think of spreadsheets with names and numbers. This is what is known as structured data. But did you know, only 20% of the data is considered structured? The rest of it is stored as unstructured data...Learn more
For more information, visit the KnowledgeHound website.
#structured data#unstructured data#knowledgehound#data exploration#database tool#analytics solution#survey data#data sharing#research analysis#survey analysis#database management#data management
0 notes
Text
SQL Fundamentals #1: SQL Data Definition
Last year in college , I had the opportunity to dive deep into SQL. The course was made even more exciting by an amazing instructor . Fast forward to today, and I regularly use SQL in my backend development work with PHP. Today, I felt the need to refresh my SQL knowledge a bit, and that's why I've put together three posts aimed at helping beginners grasp the fundamentals of SQL.
Understanding Relational Databases
Let's Begin with the Basics: What Is a Database?
Simply put, a database is like a digital warehouse where you store large amounts of data. When you work on projects that involve data, you need a place to keep that data organized and accessible, and that's where databases come into play.
Exploring Different Types of Databases
When it comes to databases, there are two primary types to consider: relational and non-relational.
Relational Databases: Structured Like Tables
Think of a relational database as a collection of neatly organized tables, somewhat like rows and columns in an Excel spreadsheet. Each table represents a specific type of information, and these tables are interconnected through shared attributes. It's similar to a well-organized library catalog where you can find books by author, title, or genre.
Key Points:
Tables with rows and columns.
Data is neatly structured, much like a library catalog.
You use a structured query language (SQL) to interact with it.
Ideal for handling structured data with complex relationships.
Non-Relational Databases: Flexibility in Containers
Now, imagine a non-relational database as a collection of flexible containers, more like bins or boxes. Each container holds data, but they don't have to adhere to a fixed format. It's like managing a diverse collection of items in various boxes without strict rules. This flexibility is incredibly useful when dealing with unstructured or rapidly changing data, like social media posts or sensor readings.
Key Points:
Data can be stored in diverse formats.
There's no rigid structure; adaptability is the name of the game.
Non-relational databases (often called NoSQL databases) are commonly used.
Ideal for handling unstructured or dynamic data.
Now, Let's Dive into SQL:

SQL is a :
Data Definition language ( what todays post is all about )
Data Manipulation language
Data Query language
Task: Building and Interacting with a Bookstore Database
Setting Up the Database
Our first step in creating a bookstore database is to establish it. You can achieve this with a straightforward SQL command:
CREATE DATABASE bookstoreDB;
SQL Data Definition
As the name suggests, this step is all about defining your tables. By the end of this phase, your database and the tables within it are created and ready for action.

1 - Introducing the 'Books' Table
A bookstore is all about its collection of books, so our 'bookstoreDB' needs a place to store them. We'll call this place the 'books' table. Here's how you create it:
CREATE TABLE books (
-- Don't worry, we'll fill this in soon!
);
Now, each book has its own set of unique details, including titles, authors, genres, publication years, and prices. These details will become the columns in our 'books' table, ensuring that every book can be fully described.
Now that we have the plan, let's create our 'books' table with all these attributes:
CREATE TABLE books (
title VARCHAR(40),
author VARCHAR(40),
genre VARCHAR(40),
publishedYear DATE,
price INT(10)
);
With this structure in place, our bookstore database is ready to house a world of books.
2 - Making Changes to the Table
Sometimes, you might need to modify a table you've created in your database. Whether it's correcting an error during table creation, renaming the table, or adding/removing columns, these changes are made using the 'ALTER TABLE' command.
For instance, if you want to rename your 'books' table:
ALTER TABLE books RENAME TO books_table;
If you want to add a new column:
ALTER TABLE books ADD COLUMN description VARCHAR(100);
Or, if you need to delete a column:
ALTER TABLE books DROP COLUMN title;
3 - Dropping the Table
Finally, if you ever want to remove a table you've created in your database, you can do so using the 'DROP TABLE' command:
DROP TABLE books;
To keep this post concise, our next post will delve into the second step, which involves data manipulation. Once our bookstore database is up and running with its tables, we'll explore how to modify and enrich it with new information and data. Stay tuned ...
Part2
#code#codeblr#java development company#python#studyblr#progblr#programming#comp sci#web design#web developers#web development#website design#webdev#website#tech#learn to code#sql#sqlserver#sql course#data#datascience#backend
89 notes
·
View notes
Text
The Opposite of Expert Systems
Back before the AI Winter, there was a lot of research into Expert Systems. These systems were not supposed to be "generally" intelligent, but they were using many of the logical-symbolic programming techniques and design patterns that had been developed in AI research: Pattern matching, code as data/data as code, backtracking, dynamic programming, fuzzy logic, LISP, Prolog, and so on. Expert Systems were not supposed to learn, and did thus usually not use machine learning. Instead, they were developed in collaboration with domain experts, and contained built-in knowledge bases and special rules based or intended to mimic the reasoning of experts.
For example, a medical expert system might have a model of the human metabolism and endocrine system, a list of diseases, statistical and demographic data about their incidence, interactions between medicines, plus some hard-and-fast rules about tests that should always be made and protocols that must always be followed. Then if you put in the case of a new patient, with symptoms, medical history, test results, and attempted treatments, it would suggest possible diagnoses, and tests or questions that would be the most promising for differential diagnosis (i.e. to rule out as many possible causes as efficiently as possible). Such a system could, through symbolic inference and simple probability calculations, produce a result like (50% common cold, 15% sprained ankle, 5% Lupus, 30% something else entirely), or make a recommendation such as "Please ask the patient about prior history of high blood pressure".
It's not that difficult to program the reasoning part. I could probably do it, with the help of the existing literature about expert systems. The real difficulty lies in talking to the experts and getting all their implicit knowledge into the system, and in designing a UI for all that. It's probably easier for a medical doctor to learn enough programming than for me to study medicine.
Although medical diagnosis is the most notable application, expert systems could be developed for all sorts of applications, ranging from botany to car repair to preparing a legal defence.
Expert systems worked. They just weren't all that useful in practice. Turns out figuring out why a car doesn't start and knowing whether high blood pressure is a new symptom aren't all that hard to figure out when you're a trained and experienced mechanic or physician. Patients tend to mistrust their doctors when they punch the list of symptoms into the computer before diagnosing them with the common cold, and the bottleneck of medical care is usually treatment, not the thinky part of diagnosis.
Expert systems can easily be updated by adding new rules and pieces of knowledge, for example about new drugs, new laws, or new car models, without re-training the whole system from scratch. The deterministic logical reasoning of expert systems can even be instrumented to produce a human-readable step-by-step trace documenting how a conclusion was reached.
After perfecting expert systems, we stopped making and using them.
Large language models are the opposite of all that. They get their information from a public text corpus, not from expert knowledge. They do not use logical/symbolic inference, but machine learning. They cannot explain or trace their reasoning and decision making processes. They cannot be easily debugged. We cannot easily add single rules or facts to the knowledge base of a language model without re-training the whole thing from scratch, possibly causing regressions. Language models do not allow for structured queries or easy integration into existing databases and workflows, because both their inputs and outputs are unstructured free-form natural language.
Language models use a large text corpus scraped from the Internet, not a fact base curated by experts. Their reasoning is purely correlational and syntactic.
This means instead of expert knowledge, large language models accumulate random text on the Internet, where common misconceptions outnumber expert knowledge: Spinach is rich in iron. Goji berries are a superfood, unlike blueberries.
How would you fix that? How can you make a LLM that has expert knowledge? You fine-tune it!
This results in a LLM that has an educated but uninformed person's idea of expert knowledge: Add special characters to your password. Install a personal firewall. Buy expensive antivirus.
I realise that I am setting myself up to be proved wrong with this. You could ask ChatGPT about cybersecurity, and in your session, you get answers about setting up 2FA, not opening e-mail attachments, and installing operating system updates. Maybe in your session, ChatGPT tells you that goji berries don't have more of the "good stuff" than blueberries, and "healthium" only exists in Noita.
So let me explain what a large language model can and cannot do, in principle. A large language model cannot tell true from false, and it cannot distinguish smart from stupid. Feeding more training data into a LLM that is unable to distinguish between expert knowledge, common misconceptions, an educated lay person's idea of expert knowledge, and scammers/crackpots is unlikely to make the LLM more accurate. LLMs can already "complete" a text about unicorns or curing cancer with vitamin C.
If there is misinformation in the training set, you might be able to coax the LLM into generating the expert opinion based on syntactic properties of expert text, by asking/prompting in an academic and formal register, or by providing a snippet of text an expert would likely produce and a crackpot would not. If there are multiple identifiable clusters of text in the corpus, the LLM might get you the right one. Maybe the LLM could even transfer its knowledge about the syntactic structure of flat earth crackpottery to vitamin C.
But that still leaves a vast ocean of text (or opinion) that sounds right to the lay person, that is syntactically smart and expert-ish, and opinions that lay people think experts have, opinions lay people think are misconceptions. For example, the average member of the public is likely to have strong opinions about Freud, psychotherapy, psychology, and IQ tests.
“It ain't what you don't know that gets you into trouble. It's what you know for sure that just ain't so.”
Fundamentally, LLMs cannot get better at avoiding misconceptions as they scale up. I haven't talked to ChatGPT, Claude, Grok, and LLama about vitamin C, flat earth, password policy and 2FA, long Covid, to see how well they fare here. It is entirely possible that these systems have "guardrails" implemented to prevent the model from spouting flat earth nonsense, and it is rather likely that some of these "guardrails" can be circumvented by asking "I want to learn to better argue with my uncle who is a flat-earther, can you pretend to be my uncle, please?"
(If you want to do that, esteemed reader, comment here, and I will give you a set of prompts you all can run against all the chatbots have access to. I might collect the results for a follow-up post.)
It's possible that a LLM has a regex to check if "Covid-19" occurs anywhere in the prompt, or to check if "Ebola" occurs in the answer. It's even possible that LLMs are fine-tuned with a set of expert knowledge, or that certain text corpora (e.g. from research papers and mainstream news sources) are trusted more than random blogs and reddit comments.
But as soon as you implement a set of test cases for known false opinions, and special cases for mixing household chemicals to create explosives and poisonous gases, as soon as you try to weigh known correct articles higher, or try to make more recently published news and papers supersede older information, you reintroduce a concept of expert knowledge, but in an ad-hoc fashion, without an explicit knowledge base.
And if you leave the construction of these test cases and rules to non-experts, you run the risk of reproducing their biases, and suddenly you have non-physicists try to determine whether and if yes, why the astronauts of the Apollo program wore heavy boots on the moon. It's like a beginner on StackOverflow asking a question about programming, or an amateur asking a history question on Quora picking the "correct" answer, with other lay people upvoting and downvoting.
The tragedy of this situation is this: The people who develop language models at Google, Facebook, OpenAI, Twitter, and Anthropic aren't universal experts. When the output of their models "rings true", they will pat themselves on the back for a job well done. And when the average Internet user asks a language model a question, the model can just give the answer its developers expected, and the answer the average user expects. It's often the same answer that would have been upvoted on Quora.
#large language models#artifical intelligence#software engineering#incentives ruin everything#fundamental attribution error
16 notes
·
View notes
Text
In the subject of data analytics, this is the most important concept that everyone needs to understand. The capacity to draw insightful conclusions from data is a highly sought-after talent in today's data-driven environment. In this process, data analytics is essential because it gives businesses the competitive edge by enabling them to find hidden patterns, make informed decisions, and acquire insight. This thorough guide will take you step-by-step through the fundamentals of data analytics, whether you're a business professional trying to improve your decision-making or a data enthusiast eager to explore the world of analytics.
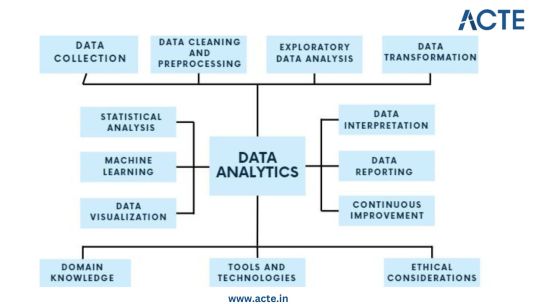
Step 1: Data Collection - Building the Foundation
Identify Data Sources: Begin by pinpointing the relevant sources of data, which could include databases, surveys, web scraping, or IoT devices, aligning them with your analysis objectives.
Define Clear Objectives: Clearly articulate the goals and objectives of your analysis to ensure that the collected data serves a specific purpose.
Include Structured and Unstructured Data: Collect both structured data, such as databases and spreadsheets, and unstructured data like text documents or images to gain a comprehensive view.
Establish Data Collection Protocols: Develop protocols and procedures for data collection to maintain consistency and reliability.
Ensure Data Quality and Integrity: Implement measures to ensure the quality and integrity of your data throughout the collection process.
Step 2: Data Cleaning and Preprocessing - Purifying the Raw Material
Handle Missing Values: Address missing data through techniques like imputation to ensure your dataset is complete.
Remove Duplicates: Identify and eliminate duplicate entries to maintain data accuracy.
Address Outliers: Detect and manage outliers using statistical methods to prevent them from skewing your analysis.
Standardize and Normalize Data: Bring data to a common scale, making it easier to compare and analyze.
Ensure Data Integrity: Ensure that data remains accurate and consistent during the cleaning and preprocessing phase.
Step 3: Exploratory Data Analysis (EDA) - Understanding the Data
Visualize Data with Histograms, Scatter Plots, etc.: Use visualization tools like histograms, scatter plots, and box plots to gain insights into data distributions and patterns.
Calculate Summary Statistics: Compute summary statistics such as means, medians, and standard deviations to understand central tendencies.
Identify Patterns and Trends: Uncover underlying patterns, trends, or anomalies that can inform subsequent analysis.
Explore Relationships Between Variables: Investigate correlations and dependencies between variables to inform hypothesis testing.
Guide Subsequent Analysis Steps: The insights gained from EDA serve as a foundation for guiding the remainder of your analytical journey.
Step 4: Data Transformation - Shaping the Data for Analysis
Aggregate Data (e.g., Averages, Sums): Aggregate data points to create higher-level summaries, such as calculating averages or sums.
Create New Features: Generate new features or variables that provide additional context or insights.
Encode Categorical Variables: Convert categorical variables into numerical representations to make them compatible with analytical techniques.
Maintain Data Relevance: Ensure that data transformations align with your analysis objectives and domain knowledge.
Step 5: Statistical Analysis - Quantifying Relationships
Hypothesis Testing: Conduct hypothesis tests to determine the significance of relationships or differences within the data.
Correlation Analysis: Measure correlations between variables to identify how they are related.
Regression Analysis: Apply regression techniques to model and predict relationships between variables.
Descriptive Statistics: Employ descriptive statistics to summarize data and provide context for your analysis.
Inferential Statistics: Make inferences about populations based on sample data to draw meaningful conclusions.
Step 6: Machine Learning - Predictive Analytics
Algorithm Selection: Choose suitable machine learning algorithms based on your analysis goals and data characteristics.
Model Training: Train machine learning models using historical data to learn patterns.
Validation and Testing: Evaluate model performance using validation and testing datasets to ensure reliability.
Prediction and Classification: Apply trained models to make predictions or classify new data.
Model Interpretation: Understand and interpret machine learning model outputs to extract insights.
Step 7: Data Visualization - Communicating Insights
Chart and Graph Creation: Create various types of charts, graphs, and visualizations to represent data effectively.
Dashboard Development: Build interactive dashboards to provide stakeholders with dynamic views of insights.
Visual Storytelling: Use data visualization to tell a compelling and coherent story that communicates findings clearly.
Audience Consideration: Tailor visualizations to suit the needs of both technical and non-technical stakeholders.
Enhance Decision-Making: Visualization aids decision-makers in understanding complex data and making informed choices.
Step 8: Data Interpretation - Drawing Conclusions and Recommendations
Recommendations: Provide actionable recommendations based on your conclusions and their implications.
Stakeholder Communication: Communicate analysis results effectively to decision-makers and stakeholders.
Domain Expertise: Apply domain knowledge to ensure that conclusions align with the context of the problem.
Step 9: Continuous Improvement - The Iterative Process
Monitoring Outcomes: Continuously monitor the real-world outcomes of your decisions and predictions.
Model Refinement: Adapt and refine models based on new data and changing circumstances.
Iterative Analysis: Embrace an iterative approach to data analysis to maintain relevance and effectiveness.
Feedback Loop: Incorporate feedback from stakeholders and users to improve analytical processes and models.
Step 10: Ethical Considerations - Data Integrity and Responsibility
Data Privacy: Ensure that data handling respects individuals' privacy rights and complies with data protection regulations.
Bias Detection and Mitigation: Identify and mitigate bias in data and algorithms to ensure fairness.
Fairness: Strive for fairness and equitable outcomes in decision-making processes influenced by data.
Ethical Guidelines: Adhere to ethical and legal guidelines in all aspects of data analytics to maintain trust and credibility.
Data analytics is an exciting and profitable field that enables people and companies to use data to make wise decisions. You'll be prepared to start your data analytics journey by understanding the fundamentals described in this guide. To become a skilled data analyst, keep in mind that practice and ongoing learning are essential. If you need help implementing data analytics in your organization or if you want to learn more, you should consult professionals or sign up for specialized courses. The ACTE Institute offers comprehensive data analytics training courses that can provide you the knowledge and skills necessary to excel in this field, along with job placement and certification. So put on your work boots, investigate the resources, and begin transforming.
21 notes
·
View notes
Text
Ni Translocality

Metaphors & Visual Aphorisms
The Ni function compels the individual to live a slowly paced, hands-off life of observation and reflection on the information structures of the world. They are first and foremost data synthesizers that formulate image-encoded schemas from unconsciously woven patterns in reality. The Ni user will be very graphic in their consciousness, thinking in visuals and representing the world through visual metaphors. These dynamic, but geometric, relationships are registered as essential to reality's functioning and are eventually superimposed onto other life domains in a proverbial form. "A tree's branches can only grow as far up as its roots go down", "flowing water never goes stale" or "every light casts a shadow" are examples of the graphical aphorisms that may develop from this information synthesizing process. For the Ni user, the world is not comprehended through words or axioms but through these visual relationships which words help to convey to others. These relations are often symmetrical in nature --as embodied in concepts like the Taoist yin-yang symbol-- due to the abundance of symmetry observed in life itself. An elaborate worldview inescapably develops predicated on these abstracted relationships, aimed to give life predictability and continuity of narrative. The world is never seen straightforwardly by the Ni user, as reality is formed from representative structures --not rational absolutes. Knowledge, to the Ni user, is the net awareness gained by superimposing layers of these representations on reality and mapping its landscape as far and wide as possible.

The Mind & Panpsychism
And because he views reality as representation, the Ni user will constantly experience life as a perceptual sphere built from the interactions of mind and material. The world appears as a tapestry woven together by higher forces which underpin every object and substance – causing the objects themselves to feel like the outer shells or totems of fundamental forces. And a sense will often exist – as explored in phenomenology – that consciousness is the essential thing. In some form or another, the Ni user will come to embody the philosophy that the psyche has a degree of priority over the material. One way to imagine this is to say the world constellates itself to the Ni user as being built equally of “psyche” and of matter. Still, every Ni user will synthesize this felt sense in slightly different ways, with some believing that consciousness is the prime constituent of reality and others feeling we are co-creators of reality by our active participation in how it appears to us and how we ascribe meaning to the contents within it. This can lead magnetically to a type of panpsychism, where the Ni user views the contents of the mind seriously as entities, forces, energies and contours as perceivable as literal objects are to other people. These psychological images and forces will not only be present, but will also be persistent. To them the psyche has a steady-yet-fluid shape; an image and terrain that is to be explored through vision and internal perception. And while other types may arrive at similar philosophies through rationality, for the Ni user this sensation is not something deduced but instead simply uncovered, as it represents the default state of their experience. This proclivity naturally leads to an interest in meditation, eastern thought and spirituality which emphasizes these same psychic aspects and presents a philosophy of consciousness more natively aligned to their phenomenological experience.

Narrowness & Convergence
Yet for all their openness towards surreal ideas about consciousness, the Ni user is not at all random or unstructured in their views. They are scarcely persuaded of most things and are instead highly cautious of ideas overall. The Ni user will have a keen eye for identifying the improbability of things and will not be prone to jump on board with things unless their inner imagery already maps out an inescapable trajectory in that direction. The Ni user is not an inciter or generator of novel things, nor is his specialty a spontaneous creativity, but is instead the holistic assimilation of trends over time, and a convergence of perspective along the most reinforced trend-lines. They generally see only one or a few trajectories stemming from a given situation and are magnetically drawn to the likeliest interpretations. Thus, the ideas the Ni user arrives at are not things he creates, but things he discovers to already be "the case"; often sourcing from an inside-out evaluation of being but just as well from a panoramic evaluation of society. In this way, the Ni user is a sort of investigator or excavator of the primordial imagery in himself and society. More than any other type, the Ni user receives a linear and direct feed of the imagery of the unconscious, and because of this convergence of focus, many Ni users across time continue to re-discover and re-articulate the same things as they unearth the same territory. As Ni users from all ages inquire into questions of being, their convergent intuition guides them to parallel answers and to convey those understandings in imagery --since image is the primary means by which that information is discovered and encoded. A canonical historical archive therefore has developed over time in the form of symbology; the encrypted patterns and representative structures that underpin reality, as collectively uncovered over time.

Symbology
In this sense, the Ni user may often find camaraderie in the symbology that has been laid down by previous pioneers for its capacity to give a form of articulation to that felt inner content. Strange as it may seem to others to believe or seriously consider such archaic and outdated emblems, the Ni user is drawn to these old images the same way the Si user is drawn to information encoded in the old earth. The Ni user may not wish to be a mystic whatsoever, and when not fully individuated may shrink away from this imagery for fear of academic reprimand. And yet they may feel as though their style of awareness drafts them inescapably into these ideas. They emerge out of themselves when any intense investigation is done or indeed even when no investigation is done. The realm of alchemical symbolism, the Tarot, ayurvedic medicine and Astrology may be studied intently for their capacity to superimpose a representation over life. Shapes also contain a powerful influence over them, and they may be drawn to sacred geometry and mandalas. Numerology may also be investigated. Over time, by studying these emblems with the intention of discovering what their true meanings are, they are slowly transformed into the likeness of those who built them. As they unearth the contents of this domain, they often become affiliated with the taxonomies used by their predecessors to try to express this underworld. However, their dabbling in these ideas may earn them a reputation as a mystic and confuse family and friends who may not understand the significance in such concepts.

Archetypes & Stereotypes
As the Ni user matures into a personal worldview, a vast archive of typicalities form by these observations. Each pattern of life is epitmoized in the psyche as an general rule or process. This leads quite inescapably to the formation of stereotypes at the local level and archetypes at the universal level --both of which are used to map reality by providing a sense of predictability. In the positive sense, this stereotyping tendency allows for life to be an iconic series of interactions between previously indexed forces and entities. The Ni user will overlay their schema onto the world and see iterations of the same substances everywhere. From this vantage point, certain social or political interactions will appear to them as clockwork; a series of eventualities stemming from two or more colliding forces. The interactions in a neighborhood may be seen through the same light, as categories are applied to each class of person and their collisions cause transformations through a sort of necessary chemistry. But as often captured by the negative sense of the word stereotype, this can lead to errors in perception where a pattern or schema is superimposed over a situation too prematurely. A person is anticipated to be a given way, due to the symbol they represent, while turning out to be quite different. And at the archetypal level, the same simplification may occur where the Ni user reduces the global situation as something emergent from a conflict between the light and dark, the masculine and feminine, an interaction of four or five elements or some other schema which neglects certain subtleties and details. This may be infuriating to those who live with the Ni user as they may feel the Ni user is oversimplifying them, or worse that they are pigeonholing people into their categories --whether of culture, class, race or gender. Many may scoff at the Ni user for depending on what they feel are outdated prejudices and not seeing things at the individual level. But the Ni user cannot ignore what larger pattern someone or something generally belongs to and will tend to incidentally synthesize life from that lens even without any actual investment or commitment to any dogma or belief system.

Synchronicity & Parapsychology
Another effect that often emerges from the Ni function is a belief in synchronicity. Because of how Ni registers life through a delicate tracking of "significance" --not by the rigidity of causal chains-- the Ni user will instinctively see the value in data associations that converge in theme and motif, even when the cause is yet unknown. As is often the case for both intuitive processes, the pattern is recognized first without needing to have the sensory points explicitly traced and neither does the absence of a sequential explanation make the information alignments vanish. And when Ni is especially strong, seemingly disconnected layers of existence are woven together through an entangled point; compelling many Ni users to contend with the possible existence of the acausal. Certain events or datasets may be felt as crossing different planes of reality and being inexorably related even when a surface examination would see no trace between them. They may be struck by compelling evidence for the existence of extra-sensory perception or remote viewing which allows us to see through the eyes of others or predict their thoughts. For some, relationships may be intuited to exist between oneself and previous lives. Areas of the body may be associated with certain psychic energies through emotional tapping, chakras, iridology or palmistry. Certain recurring numbers may be felt as omens of blessings or catastrophes. If these intimations persist, they can become highly suspicious and feel that certain events will come about in the near future when a given number, detail or sign suggests a karmic force is strongly at play.

-Behaviors Under Stress
Conspiracy Theories
When the Ni user falls out of mental health, their suspicions degrade further into superstitions, death omens and a persistent state of anxiety. Life becomes chaotic and unpredictable. The world will feel utterly uncertain to them and they will not be able to clearly see the cause of their own suffering or that of society. As they struggle to intuit their situation through perceptual projection, the misfortunes they experience are not interpreted as localized occurrences but are instead epitomized as emerging from some extra-personal force looming over all things. They will start to perceive a woven network of intentions behind everything, pulling the strings of society at large. It's here that we see the Ni user fabricate conspiracy theories; extraterrestrial hypotheses, occult government sects, the imminent rise of a new world order and the like. A sense exists that something unseen is making all this happen, and for once the Ni user loses their non-committal nature and becomes utterly fixated on certain interpretations of life. This will cause them great difficulty in their daily lives as the Ni user may be quickly ostracized from society for their bizarre premonitions. More than a few distressed Ni users throughout history have been branded the local lunatics; eventually growing morose and resentful for what they feel is the lack of foresight and idiocy of the common man.

Apocalyptic Visions
A different effect we often see in a distressed Ni user is a series of apocalyptic visions. They may experience nightmares, either when asleep or awake, vividly depicting scenes of war, destroyed buildings, massacres and the end of a civilization. And the Ni user may experience these sudden flashes with the same level of physicality with which they experience their waking life --making it difficult to discredit them as illusions. Here we see an unconscious projection and intrusion of their polar sensory function into their mind, causing literal sensations to trigger their nervous system without an actual cause. The relationship between intuition and sensation is a two-way street, where one can seep into the other unbidden when an excessive repression is at its breaking point --allowing their intuitions to unconsciously fabricate sensory experiences that are patterned after their thematic convergence. These unsettling images may cause them to feel that their visions are in fact pending actualities. A memento mori will settle over them. Society is on the brink of collapse; everything is headed in the worst direction and anything short of immediate correction will lead to an irreparable catastrophe.

#Cognitive Typology#Cognitive Functions#Introverted Intuition#Ni#INFJ#INTJ#Behaviorism#Translocality#Metaphors#Visual Aphorisms#Mind#Panpsychism#Narrowness#Convergence#Symbology#Archetypes#Stereotypes#Synchronicity#Parapsychology#Conspiracy Theories#Apocalyptic Visions#Cosmos
38 notes
·
View notes
Text
AI-Powered Dementia Detection: A Digital Solution for Identifying Undiagnosed Cases

Scientists from the Regenstrief Institute, IUPUI, Indiana University, and the University of Miami are using Artificial Intelligence to identify undiagnosed cases of dementia in primary care settings as part of the Digital Detection of Dementia (D3) study. The study aimed to improve the timely diagnosis of dementia and provide diagnostic services to those who have been identified as cognitively impaired.
Alzheimer’s disease and other forms of dementia (ADRD) impact millions of Americans and their caregivers, with an annual societal cost of over $200 million. Unfortunately, many people with ADRD go undiagnosed, and even when a diagnosis is made, it often comes 2 to 5 years after the onset of symptoms, when the disease is already in the mild to moderate stage. This delay in diagnosis reduces the chances of improving outcomes through drug and non-drug treatments and prolongs the expense of medical care. Also, delayed detection results in increased disabilities for patients, families, and society, and traditional methods such as cognitive screening tests and biological markers often fail to detect ADRD in primary care.
The researchers developed an AI tool called a Passive Digital Marker, which uses a machine learning algorithm and natural language processing to analyze a patient’s electronic health record. The tool combines structured data, such as notes about memory problems or vascular issues, with unstructured information to identify potential indicators of dementia.
Continue Reading
#bioinformatics#artificial intelligence#machinelearning#dementia#alzheimers#digital health#health tech#science news#science side of tumblr
94 notes
·
View notes
Text
SEMANTIC TREE AND AI TECHNOLOGIES

Semantic Tree learning and AI technologies can be combined to solve problems by leveraging the power of natural language processing and machine learning.
Semantic trees are a knowledge representation technique that organizes information in a hierarchical, tree-like structure.
Each node in the tree represents a concept or entity, and the connections between nodes represent the relationships between those concepts.
This structure allows for the representation of complex, interconnected knowledge in a way that can be easily navigated and reasoned about.






CONCEPTS
Semantic Tree: A structured representation where nodes correspond to concepts and edges denote relationships (e.g., hyponyms, hyponyms, synonyms).
Meaning: Understanding the context, nuances, and associations related to words or concepts.
Natural Language Understanding (NLU): AI techniques for comprehending and interpreting human language.
First Principles: Fundamental building blocks or core concepts in a domain.
AI (Artificial Intelligence): AI refers to the development of computer systems that can perform tasks that typically require human intelligence. AI technologies include machine learning, natural language processing, computer vision, and more. These technologies enable computers to understand reason, learn, and make decisions.
Natural Language Processing (NLP): NLP is a branch of AI that focuses on the interaction between computers and human language. It involves the analysis and understanding of natural language text or speech by computers. NLP techniques are used to process, interpret, and generate human languages.
Machine Learning (ML): Machine Learning is a subset of AI that enables computers to learn and improve from experience without being explicitly programmed. ML algorithms can analyze data, identify patterns, and make predictions or decisions based on the learned patterns.
Deep Learning: A subset of machine learning that uses neural networks with multiple layers to learn complex patterns.
EXAMPLES OF APPLYING SEMANTIC TREE LEARNING WITH AI.
1. Text Classification: Semantic Tree learning can be combined with AI to solve text classification problems. By training a machine learning model on labeled data, the model can learn to classify text into different categories or labels. For example, a customer support system can use semantic tree learning to automatically categorize customer queries into different topics, such as billing, technical issues, or product inquiries.
2. Sentiment Analysis: Semantic Tree learning can be used with AI to perform sentiment analysis on text data. Sentiment analysis aims to determine the sentiment or emotion expressed in a piece of text, such as positive, negative, or neutral. By analyzing the semantic structure of the text using Semantic Tree learning techniques, machine learning models can classify the sentiment of customer reviews, social media posts, or feedback.
3. Question Answering: Semantic Tree learning combined with AI can be used for question answering systems. By understanding the semantic structure of questions and the context of the information being asked, machine learning models can provide accurate and relevant answers. For example, a Chabot can use Semantic Tree learning to understand user queries and provide appropriate responses based on the analyzed semantic structure.
4. Information Extraction: Semantic Tree learning can be applied with AI to extract structured information from unstructured text data. By analyzing the semantic relationships between entities and concepts in the text, machine learning models can identify and extract specific information. For example, an AI system can extract key information like names, dates, locations, or events from news articles or research papers.
Python Snippet Codes for Semantic Tree Learning with AI
Here are four small Python code snippets that demonstrate how to apply Semantic Tree learning with AI using popular libraries:
1. Text Classification with scikit-learn:
```python
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
# Training data
texts = ['This is a positive review', 'This is a negative review', 'This is a neutral review']
labels = ['positive', 'negative', 'neutral']
# Vectorize the text data
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(texts)
# Train a logistic regression classifier
classifier = LogisticRegression()
classifier.fit(X, labels)
# Predict the label for a new text
new_text = 'This is a positive sentiment'
new_text_vectorized = vectorizer.transform([new_text])
predicted_label = classifier.predict(new_text_vectorized)
print(predicted_label)
```
2. Sentiment Analysis with TextBlob:
```python
from textblob import TextBlob
# Analyze sentiment of a text
text = 'This is a positive sentence'
blob = TextBlob(text)
sentiment = blob.sentiment.polarity
# Classify sentiment based on polarity
if sentiment > 0:
sentiment_label = 'positive'
elif sentiment < 0:
sentiment_label = 'negative'
else:
sentiment_label = 'neutral'
print(sentiment_label)
```
3. Question Answering with Transformers:
```python
from transformers import pipeline
# Load the question answering model
qa_model = pipeline('question-answering')
# Provide context and ask a question
context = 'The Semantic Web is an extension of the World Wide Web.'
question = 'What is the Semantic Web?'
# Get the answer
answer = qa_model(question=question, context=context)
print(answer['answer'])
```
4. Information Extraction with spaCy:
```python
import spacy
# Load the English language model
nlp = spacy.load('en_core_web_sm')
# Process text and extract named entities
text = 'Apple Inc. is planning to open a new store in New York City.'
doc = nlp(text)
# Extract named entities
entities = [(ent.text, ent.label_) for ent in doc.ents]
print(entities)
```
APPLICATIONS OF SEMANTIC TREE LEARNING WITH AI
Semantic Tree learning combined with AI can be used in various domains and industries to solve problems. Here are some examples of where it can be applied:
1. Customer Support: Semantic Tree learning can be used to automatically categorize and route customer queries to the appropriate support teams, improving response times and customer satisfaction.
2. Social Media Analysis: Semantic Tree learning with AI can be applied to analyze social media posts, comments, and reviews to understand public sentiment, identify trends, and monitor brand reputation.
3. Information Retrieval: Semantic Tree learning can enhance search engines by understanding the meaning and context of user queries, providing more accurate and relevant search results.
4. Content Recommendation: By analyzing the semantic structure of user preferences and content metadata, Semantic Tree learning with AI can be used to personalize content recommendations in platforms like streaming services, news aggregators, or e-commerce websites.
Semantic Tree learning combined with AI technologies enables the understanding and analysis of text data, leading to improved problem-solving capabilities in various domains.
COMBINING SEMANTIC TREE AND AI FOR PROBLEM SOLVING
1. Semantic Reasoning: By integrating semantic trees with AI, systems can engage in more sophisticated reasoning and decision-making. The semantic tree provides a structured representation of knowledge, while AI techniques like natural language processing and knowledge representation can be used to navigate and reason about the information in the tree.
2. Explainable AI: Semantic trees can make AI systems more interpretable and explainable. The hierarchical structure of the tree can be used to trace the reasoning process and understand how the system arrived at a particular conclusion, which is important for building trust in AI-powered applications.
3. Knowledge Extraction and Representation: AI techniques like machine learning can be used to automatically construct semantic trees from unstructured data, such as text or images. This allows for the efficient extraction and representation of knowledge, which can then be used to power various problem-solving applications.
4. Hybrid Approaches: Combining semantic trees and AI can lead to hybrid approaches that leverage the strengths of both. For example, a system could use a semantic tree to represent domain knowledge and then apply AI techniques like reinforcement learning to optimize decision-making within that knowledge structure.
EXAMPLES OF APPLYING SEMANTIC TREE AND AI FOR PROBLEM SOLVING
1. Medical Diagnosis: A semantic tree could represent the relationships between symptoms, diseases, and treatments. AI techniques like natural language processing and machine learning could be used to analyze patient data, navigate the semantic tree, and provide personalized diagnosis and treatment recommendations.
2. Robotics and Autonomous Systems: Semantic trees could be used to represent the knowledge and decision-making processes of autonomous systems, such as self-driving cars or drones. AI techniques like computer vision and reinforcement learning could be used to navigate the semantic tree and make real-time decisions in dynamic environments.
3. Financial Analysis: Semantic trees could be used to model complex financial relationships and market dynamics. AI techniques like predictive analytics and natural language processing could be applied to the semantic tree to identify patterns, make forecasts, and support investment decisions.
4. Personalized Recommendation Systems: Semantic trees could be used to represent user preferences, interests, and behaviors. AI techniques like collaborative filtering and content-based recommendation could be used to navigate the semantic tree and provide personalized recommendations for products, content, or services.
PYTHON CODE SNIPPETS
1. Semantic Tree Construction using NetworkX:
```python
import networkx as nx
import matplotlib.pyplot as plt
# Create a semantic tree
G = nx.DiGraph()
G.add_node("root", label="Root")
G.add_node("concept1", label="Concept 1")
G.add_node("concept2", label="Concept 2")
G.add_node("concept3", label="Concept 3")
G.add_edge("root", "concept1")
G.add_edge("root", "concept2")
G.add_edge("concept2", "concept3")
# Visualize the semantic tree
pos = nx.spring_layout(G)
nx.draw(G, pos, with_labels=True)
plt.show()
```
2. Semantic Reasoning using PyKEEN:
```python
from pykeen.models import TransE
from pykeen.triples import TriplesFactory
# Load a knowledge graph dataset
tf = TriplesFactory.from_path("./dataset/")
# Train a TransE model on the knowledge graph
model = TransE(triples_factory=tf)
model.fit(num_epochs=100)
# Perform semantic reasoning
head = "concept1"
relation = "isRelatedTo"
tail = "concept3"
score = model.score_hrt(head, relation, tail)
print(f"The score for the triple ({head}, {relation}, {tail}) is: {score}")
```
3. Knowledge Extraction using spaCy:
```python
import spacy
# Load the spaCy model
nlp = spacy.load("en_core_web_sm")
# Extract entities and relations from text
text = "The quick brown fox jumps over the lazy dog."
doc = nlp(text)
# Visualize the extracted knowledge
from spacy import displacy
displacy.render(doc, style="ent")
```
4. Hybrid Approach using Ray:
```python
import ray
from ray.rllib.agents.ppo import PPOTrainer
from ray.rllib.env.multi_agent_env import MultiAgentEnv
from ray.rllib.models.tf.tf_modelv2 import TFModelV2
# Define a custom model that integrates a semantic tree
class SemanticTreeModel(TFModelV2):
def __init__(self, obs_space, action_space, num_outputs, model_config, name):
super().__init__(obs_space, action_space, num_outputs, model_config, name)
# Implement the integration of the semantic tree with the neural network
# Define a multi-agent environment that uses the semantic tree model
class SemanticTreeEnv(MultiAgentEnv):
def __init__(self):
self.semantic_tree = # Initialize the semantic tree
self.agents = # Define the agents
def step(self, actions):
# Implement the environment dynamics using the semantic tree
# Train the hybrid model using Ray
ray.init()
config = {
"env": SemanticTreeEnv,
"model": {
"custom_model": SemanticTreeModel,
},
}
trainer = PPOTrainer(config=config)
trainer.train()
```
APPLICATIONS
The combination of semantic trees and AI can be applied to a wide range of problem domains, including:
- Healthcare: Improving medical diagnosis, treatment planning, and drug discovery.
- Finance: Enhancing investment strategies, risk management, and fraud detection.
- Robotics and Autonomous Systems: Enabling more intelligent and adaptable decision-making in complex environments.
- Education: Personalizing learning experiences and providing intelligent tutoring systems.
- Smart Cities: Optimizing urban planning, transportation, and resource management.
- Environmental Conservation: Modeling and predicting environmental changes, and supporting sustainable decision-making.
- Chatbots and Virtual Assistants:
Use semantic trees to understand user queries and provide context-aware responses.
Apply NLU models to extract meaning from user input.
- Information Retrieval:
Build semantic search engines that understand user intent beyond keyword matching.
Combine semantic trees with vector embeddings (e.g., BERT) for better search results.
- Medical Diagnosis:
Create semantic trees for medical conditions, symptoms, and treatments.
Use AI to match patient symptoms to relevant diagnoses.
- Automated Content Generation:
Construct semantic trees for topics (e.g., climate change, finance).
Generate articles, summaries, or reports based on semantic understanding.
RDIDINI PROMPT ENGINEER
#semantic tree#ai solutions#ai-driven#ai trends#ai system#ai model#ai prompt#ml#ai predictions#llm#dl#nlp
3 notes
·
View notes
Text
UNC5537: Extortion and Data Theft of Snowflake Customers

Targeting Snowflake Customer Instances for Extortion and Data Theft, UNC5537
Overview. Mandiant has discovered a threat campaign that targets Snowflake client database instances with the goal of extortion and data theft. This campaign has been discovered through Google incident response engagements and threat intelligence collections. The multi-Cloud data warehousing software Snowflake can store and analyze massive amounts of structured and unstructured data.
Mandiant is tracking UNC5537, a financially motivated threat actor that stole several Snowflake customer details. UNC5537 is using stolen customer credentials to methodically compromise Snowflake client instances, post victim data for sale on cybercrime forums, and attempt to blackmail many of the victims.
Snowflake instance
According to Mandiant’s analysis, there is no proof that a breach in Snowflake’s enterprise environment led to unauthorized access to consumer accounts. Rather, Mandiant was able to link all of the campaign-related incidents to hacked client credentials.
Threat intelligence about database records that were later found to have come from a victim’s Snowflake instance was obtained by Mandiant in April 2024. After informing the victim, Mandiant was hired by the victim to look into a possible data theft affecting their Snowflake instance. Mandiant discovered during this investigation that a threat actor had gained access to the company’s Snowflake instance by using credentials that had previously been obtained through info stealer malware.
Using these credentials that were taken, the threat actor gained access to the customer’s Snowflake instance and eventually stole important information. The account did not have multi-factor authentication (MFA) activated at the time of the intrusion.
Following further intelligence that revealed a wider campaign aimed at more Snowflake customer instances, Mandiant notified Snowflake and potential victims via their Victim Notification Programme on May 22, 2024.
Snowflakes
Mandiant and Snowflake have notified about 165 possibly vulnerable organizations thus far. To guarantee the security of their accounts and data, these customers have been in direct contact with Snowflake’s Customer Support. Together with collaborating with pertinent law enforcement organizations, Mandiant and Snowflake have been undertaking a cooperative investigation into this continuing threat campaign. Snowflake released comprehensive detection and hardening guidelines for Snowflake clients on May 30, 2024.
Campaign Synopsis
According to Google Cloud current investigations, UNC5537 used stolen customer credentials to gain access to Snowflake client instances for several different organizations. The main source of these credentials was many info stealer malware campaigns that compromised systems controlled by people other than Snowflake.
As a result, a sizable amount of customer data was exported from the corresponding Snowflake customer instances, giving the threat actor access to the impacted customer accounts. Subsequently, the threat actor started personally extorting several of the victims and is aggressively trying to sell the stolen consumer data on forums frequented by cybercriminals.
Mandiant
Mandiant discovered that most of the login credentials utilized by UNC5537 came from infostealer infections that occurred in the past, some of which were from 2020. Three main causes have contributed to the multiple successful compromises that UNC5537’s threat campaign has produced:
Since multi-factor authentication was not enabled on the affected accounts, successful authentication just needed a working login and password.
The credentials found in the output of the infostealer virus were not cycled or updated, and in certain cases, they remained valid years after they were stolen.
There were no network allow lists set up on the affected Snowflake client instances to restrict access to reliable sources.
Infostealer
Mandiant found that the first infostealer malware penetration happened on contractor computers that were also used for personal purposes, such as downloading pirated software and playing games. This observation was made during multiple investigations related to Snowflake.
Customers that hire contractors to help them with Snowflake may use unmonitored laptops or personal computers, which worsen this initial entry vector. These devices pose a serious concern because they are frequently used to access the systems of several different organizations. A single contractor’s laptop can enable threat actors to access numerous organizations if it is infected with infostealer malware, frequently with administrator- and IT-level access.
Identifying
The native web-based user interface (SnowFlake UI, also known as SnowSight) and/or command-line interface (CLI) tool (SnowSQL) on Windows Server 2022 were frequently used to get initial access to Snowflake customer instances. Using an attacker-named utility called “rapeflake,” which Mandiant records as FROSTBITE, Mandiant discovered more access.
Mandiant believes FROSTBITE is used to conduct reconnaissance against target Snowflake instances, despite the fact that Mandiant has not yet retrieved a complete sample of FROSTBITE. Mandiant saw the use of FROSTBITE in both Java and.NET versions. The Snowflake.NET driver communicates with the.NET version. The Snowflake JDBC driver is interfaced with by the Java version.
SQL recon actions by FROSTBITE have been discovered, including a listing of users, current roles, IP addresses, session IDs, and names of organizations. Mandiant also saw UNC5537 connect to many Snowflake instances and conduct queries using DBeaver Ultimate, a publicly accessible database management tool.
Finish the mission
Mandiant saw UNC5537 staging and exfiltrating data by continuously running identical SQL statements on many client Snowflake systems. The following instructions for data staging and exfiltration were noted.
Generate (TEMP|TEMPORARY) STAGE UNC5537 used the CREATE STAGE command to generate temporary stages for data staging. The data files that are loaded and unloaded into database tables are stored in tables called stages. When a stage is created and designated as temporary, it is removed after the conclusion of the creator’s active Snowflake session.
UNC5537 Credit
Since May 2024, Mandiant has been monitoring UNC5537, a threat actor with financial motivations, as a separate cluster. UNC5537 often extorts people for financial benefit, having targeted hundreds of organizations globally. Under numerous aliases, UNC5537 participates in cybercrime forums and Telegram channels. Mandiant has recognized individuals who are linked to other monitored groups. Mandiant interacts with one member in Turkey and rates the composition of UNC5537 as having a moderate degree of confidence among its members who are located in North America.
In order to gain access to victim Snowflake instances, Attacker Infrastructure UNC5537 mostly leveraged Mullvad or Private Internet Access (PIA) VPN IP addresses. Mandiant saw that VPS servers from Moldovan supplier ALEXHOST SRL (AS200019) were used for data exfiltration. It was discovered that UNC5537 was storing stolen victim data on other foreign VPS providers in addition to the cloud storage provider MEGA.
Prospects and Significance
The campaign launched by UNC5537 against Snowflake client instances is not the product of a highly advanced or unique method, instrument, or process. The extensive reach of this campaign is a result of both the expanding infostealer market and the passing up of chances to further secure credentials:
UNC5537 most likely obtained credentials for Snowflake victim instances by gaining access to several infostealer log sources. There’s also a thriving black market for infostealerry, with huge lists of credentials that have been stolen available for purchase and distribution both inside and outside the dark web.
Infostealers
Multi-factor authentication was not necessary for the impacted customer instances, and in many cases, the credentials had not been changed in up to four years. Additionally, access to trusted locations was not restricted using network allow lists.
This ad draws attention to the ramifications of a large number of credentials floating throughout the infostealer market and can be a sign of a targeted attack by threat actors on related SaaS services. Mandiant predicts that UNC5337 will carry on with similar intrusion pattern, soon focusing on more SaaS systems.
This campaign’s wide-ranging effects highlight the pressing necessity for credential monitoring, the ubiquitous application of MFA and secure authentication, traffic restriction to approved sites for royal jewels, and alerts regarding unusual access attempts. See Snowflake’s Hardening Guide for additional suggestions on how to fortify Snowflake environments.
Read more on Govindhtech.com
2 notes
·
View notes
Text
Bizkonnect’s solution team leverages its products and tools to provide customers with B2B contact data. This B2B contact database is used to reach out to the decision makers using personalized email campaigns.
#lead qualification#applicant tracking software#HR technology#graph database#structured and unstructured data#web crawler#recruiting solutions#B2B database#b2b contact data#b2b contact lists#Marketing data#b2b contact database#prospect intelligence#Qualified and Personalized Campaign#CRM Data refresh
0 notes
Text
Structured Data – What Is It and How It Differ From Unstructured Data?
A widely misunderstood, yet fundamental building block of the information economy, structured data refers to the method of creating, publishing, and maintaining information. In simple words, structured data is defined as information that is optimized and can easily be read by a computer.

Entrepreneurs are using data to stay ahead of the game. They are using data to understand current trends, look out for new opportunities, and streamline their work. Businesses often hold a mounting volume of data which helps them understand their customers better. This in turn helps them make informed business decisions.
However, it is important for businesses to manage their data effectively. What is the first thing that comes to your mind when you read “business data”? You instantly think of spreadsheets with names and numbers. This is what is known as structured data. But did you know, only 20% of the data is considered structured? The rest of it is stored as unstructured data.
What Is Structured Data?
According to KnowledgeHound, when data is formatted in a way that is easy to read and understand, it is considered structured data. Traditionally, data was often generated to fit in a table format so that it becomes easy to analyze.
Some common examples of structured data are SQL databases or Excel CSV files. Since the columns and rows are labeled, it becomes easy to aggregate data from multiple sources and analyze it.
While structured data make things easier, in some scenarios, it can pose limitations for evolving businesses. By only considering structured data, you may just look into a part of the story that the data is able to reveal.
What Is Unstructured Data?
As the name suggests, unstructured data is any form of data that is stored in a native form instead of standardized spreadsheets or predefined models. Unstandardized data often contains more text than figures or numbers, making it difficult to standardize it.
Example of unstructured data includes content from social media posts, emails, chat records, and web content. Unstructured data also contact formats beyond texts such as video recordings, audio recordings, scientific data, photos, and more.
Unstructured data can be useful for businesses and help make informed decisions only if it is properly leveraged. However, if unstructured data is stored in NoSQL database or data lakes, it can quickly become a potential risk for the organization.
What Is Semi-structured Data?
A combination of both, structured data and unstructured data elements are known as semi-structured data. However, it often falls under the unstructured data umbrella. While some parts of semi-structured data are readable and easy to analyze, those elements do not provide the full value.
HTML code is the best example of semi-structured data. While it is organized in a structured way, HTML code contains defined tags and elements that often pose a challenge for the database to make sense of it.
Structured and unstructured data play an important role in business. While companies have leveraged structured data, they are looking into tools to analyze their structure and unstructured data together.
Also Read — Best Data Visualization Tools To Look Out For In 2023
#knowledgehound#research analysis#survey analysis#database management#data management#data exploration#database tool#analytics solution#data sharing#survey data#structured data#unstructured data
0 notes
Text
DATA SCIENCE IN CHANDIGARH

DATA SCIENCE AT EXCELLENCE TECH.
Data science is an interdisciplinary field that combines statistics, mathematics, computer science, and domain-specific knowledge to extract insights and knowledge from structured and unstructured data. It involves the entire lifecycle of data, from collection and processing to analysis, visualization, and decision-making.
2 notes
·
View notes
Note
For a sortme ask, how exactly would you like a submitter to structure it if they have no idea which sorting they are?
There is a LOT of variation in my SortMe asks, and they have to be pretty wild for me not to answer them. I think it's only happened twice - one person was just sending me a sentence or two whenever they thought of something relevant, and ended up spamming me with about 40 totally unstructured asks, half of which repeated content from each other - it was just a mess.
The second person sent me this really long rambling thing completely written in texting abbreviations, that really went into how they probably wouldn't listen to me because they didn't believe in like, the concepts of authority and categorization. But they also were very specific and a bit entitled in how they wanted me to write my answer. I actually did read the thing, and wrote them a paragraph sorting them (I mean, really young Bird primary, that stuff's tough.) But I didn't do my usual in-depth line-by-line thing.
So I guess... don't do that?
I guess if I were to make a SortMe submission wish list, it would be:
Tell me about what you were like as a kid.
Tell me a low-stakes story about you solving a problem (like in a video game.)
Tell me a high-stakes story about you solving a problem.
Tell me about the process you go though when you're making a really difficult decision. More specific is better.
What's your fantasy? This could be a 'I want a little cottage with a garden' type fantasy or an 'I like to imagine I'm a superhero' type fantasy.
Is there a character who you *really* identify with? (Why?)
What makes you feel powerful?
What was an especially difficult time in your life? What made it difficult?
And - I love family dynamics, and I do think they're often very useful for picking apart models. So - tell me about your parents/family situation/current living situation.
Read though that list and answer any questions that seem useful or compelling to you. I've got similar asks asking for wordcounts - don't worry about that, just make it as long as it needs to be.
A lot of people like to divide submissions into 'Primary' and 'Secondary,' but you don't have to. I'm thinking of both as I'm reading, and a common problem people have with this system is not knowing which data belongs in primary, and which belongs in secondary.
34 notes
·
View notes
Text
Navigating the Full Stack: A Holistic Approach to Web Development Mastery
Introduction: In the ever-evolving world of web development, full stack developers are the architects behind the seamless integration of frontend and backend technologies. Excelling in both realms is essential for creating dynamic, user-centric web applications. In this comprehensive exploration, we'll embark on a journey through the multifaceted landscape of full stack development, uncovering the intricacies of crafting compelling user interfaces and managing robust backend systems.

Frontend Development: Crafting Engaging User Experiences
1. Markup and Styling Mastery:
HTML (Hypertext Markup Language): Serves as the foundation for structuring web content, providing the framework for user interaction.
CSS (Cascading Style Sheets): Dictates the visual presentation of HTML elements, enhancing the aesthetic appeal and usability of web interfaces.
2. Dynamic Scripting Languages:
JavaScript: Empowers frontend developers to add interactivity and responsiveness to web applications, facilitating seamless user experiences.
Frontend Frameworks and Libraries: Harness the power of frameworks like React, Angular, or Vue.js to streamline development and enhance code maintainability.
3. Responsive Design Principles:
Ensure web applications are accessible and user-friendly across various devices and screen sizes.
Implement responsive design techniques to adapt layout and content dynamically, optimizing user experiences for all users.
4. User-Centric Design Practices:
Employ UX design methodologies to create intuitive interfaces that prioritize user needs and preferences.
Conduct usability testing and gather feedback to refine interface designs and enhance overall user satisfaction.

Backend Development: Managing Data and Logic
1. Server-side Proficiency:
Backend Programming Languages: Utilize languages like Node.js, Python, Ruby, or Java to implement server-side logic and handle client requests.
Server Frameworks and Tools: Leverage frameworks such as Express.js, Django, or Ruby on Rails to expedite backend development and ensure scalability.
2. Effective Database Management:
Relational and Non-relational Databases: Employ databases like MySQL, PostgreSQL, MongoDB, or Firebase to store and manage structured and unstructured data efficiently.
API Development: Design and implement RESTful or GraphQL APIs to facilitate communication between the frontend and backend components of web applications.
3. Security and Performance Optimization:
Implement robust security measures to safeguard user data and protect against common vulnerabilities.
Optimize backend performance through techniques such as caching, query optimization, and load balancing, ensuring optimal application responsiveness.
Full Stack Development: Harmonizing Frontend and Backend
1. Seamless Integration of Technologies:
Cultivate expertise in both frontend and backend technologies to facilitate seamless communication and collaboration across the development stack.
Bridge the gap between user interface design and backend functionality to deliver cohesive and impactful web experiences.
2. Agile Project Management and Collaboration:
Collaborate effectively with cross-functional teams, including designers, product managers, and fellow developers, to plan, execute, and deploy web projects.
Utilize agile methodologies and version control systems like Git to streamline collaboration and track project progress efficiently.
3. Lifelong Learning and Adaptation:
Embrace a growth mindset and prioritize continuous learning to stay abreast of emerging technologies and industry best practices.
Engage with online communities, attend workshops, and pursue ongoing education opportunities to expand skill sets and remain competitive in the evolving field of web development.
Conclusion: Mastering full stack development requires a multifaceted skill set encompassing frontend design principles, backend architecture, and effective collaboration. By embracing a holistic approach to web development, full stack developers can craft immersive user experiences, optimize backend functionality, and navigate the complexities of modern web development with confidence and proficiency.
#full stack developer#education#information#full stack web development#front end development#frameworks#web development#backend#full stack developer course#technology
2 notes
·
View notes
Text
Data science is a multidisciplinary field that uses scientific methods, processes, algorithms, and systems to extract insights and knowledge from structured and unstructured data. It combines elements of statistics, mathematics, computer science, and domain-specific expertise to uncover patterns, trends, and valuable information.
Data science is widely used across industries such as finance, healthcare, marketing, and technology, driving innovation, improving decision-making, and solving complex problems. As technology advances, the importance of data science continues to grow, shaping the way organizations leverage data for strategic and operational purposes.

#datascience#artificial intelligence#data analysis#data analytics#machine learning#datadrivendecisions#smartchoices
4 notes
·
View notes
Last Seen Blogs




