#data processing
Text

Victoria Composite High School vocational classes: Data Processing, Edmonton, Alberta, 1966
17 notes
·
View notes
Text
Speechy Research Devlog: Some New Tools & New Discoveries
Hey everyone, so it is about 8:30pm and I am sure that by the time I write this it will be nearly 9 but I wanted to update everyone who is following my Speechy research on here. I programmed 2 new programs today, a Prosodic Pitch Analyzer (PPA), and an RMS Energy Analyzer using my handy-dandy new favorite library librosa.
Prosodic Pitch Analyzer

The PPA calculates the fundamental frequency (F0) or pitch of an audio signal and visualizes it using a line plot. This is a useful tool for analyzing prosodic features of speech such as intonation, stress, and emphasis.
The code takes an audio file as input, processes it using the librosa library to extract the fundamental frequency / pitch, and then plots the pitch contour using matplotlib.
The output plot shows the pitch contour of the audio signal over time, with changes in pitch represented by changes in the vertical position of the line. The plot can be used to identify patterns in the pitch contour, such as rising or falling intonation, and to compare the pitch contour of different audio signals.
The prosodic pitch analyzer can be used to detect changes in pitch, which can be indicative of a neurological speech disorder. For example, a person with ataxic dysarthria, which is caused by damage to the cerebellum, may have difficulty controlling the pitch and loudness of their voice, resulting in variations in pitch that are not typical of normal speech. By analyzing changes in pitch using a tool like the prosodic pitch analyzer, it is possible to identify patterns that are indicative of certain neurological disorders. This information can be used by clinicians to diagnose and treat speech disorders, and to monitor progress in speech therapy.
RMS Energy Analyzer
The program that calculates the energy of a person's speech processes an audio file and calculates the energy of the signal at each time frame. This can be useful for analyzing changes in a person's speech over time, as well as for detecting changes in the intensity or loudness of the speech.
The program uses the librosa library to load and process the audio file, and then calculates the energy of each frame using the root-mean-square (RMS) energy of the signal. The energy values are then plotted over time using the matplotlib library, allowing you to visualize changes in the energy of the speech.
By analyzing changes in energy over time, you can gain insight into how the speech patterns of people with these disorders may differ from those without.
Analysis with PPA
The research that I've been focused on today primarily looked at the speech recording of myself, the mid-stage HD patient with chorea, the late-stage HD patient (EOL), and a young girl with aphasia.

The patient with aphasia had slurred speech and varied rising and falling much like an AD patient. Earlier I saw her ROS and was surprised at the differences between my rate of speech and hers (aphasia v AD)

My rate of speech
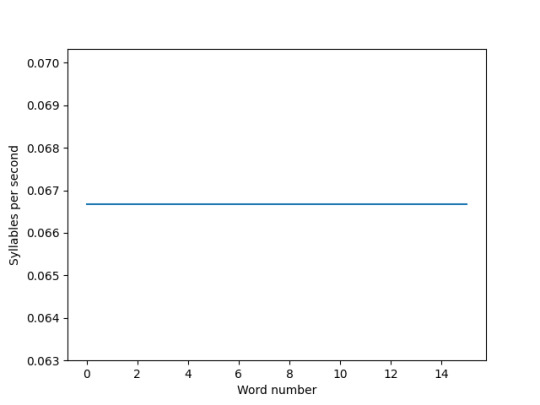
The girl with aphasia's rate of speech
So I decided to compare our speech pitches as well and this is what ours looked like side-by-side.
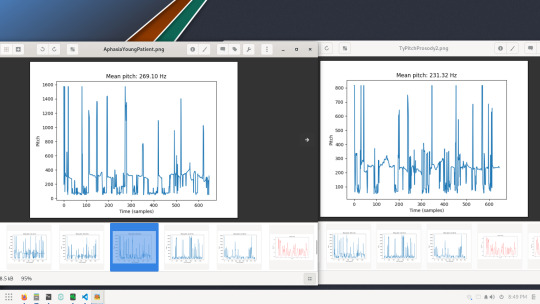
Hers is on the left, mine on the right.
Her pitch seemed to start off higher (unstable though) like mine, but mine fell during my recording and wobbled for a while. She had some drastic pitch differences but mine had around 16 peaks, where hers had around 18-19. Her latter peaks weren't as high frequency as mine, as my frequency peaks ended up mostly very high in the 1600hz or around 1000hz. There is quite a bit of instability in both our pitches though.
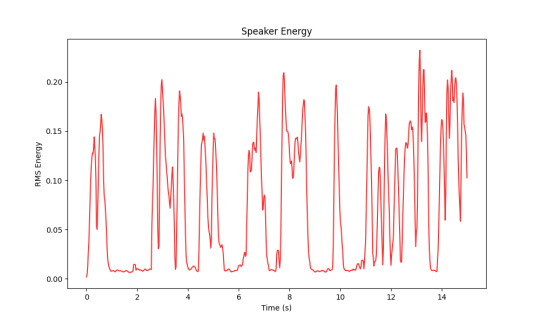
Her energy levels in the 15 seconds of speech started off at high-mid energy, then dropped around 1 second in until almost 3 seconds, shot back up and varied in high, high-mid energy, then had several "dips, and higher moments of energy. At the end around 13 seconds she got a huge boost of "gusto" (well.. energy). She had around 7 breaths (noted by the dips / flatlines)

This was mine. It seems like as the 15 seconds went on I started to run out of steam. I wasn't able to keep my energy higher. Mine had around 11 breaths so I was running out of breath eg having a breathier voice more than she was.
Research Conclusion for Today
Although we have quite a bit in common with our speech energy and pitches, our rate of speaking isn't. She used more syllables at a constant rate which made it pretty obvious she had a lot of slurring / overshooting, mine was a lot less syllables and rate of speech was quite slow and varied more than hers. This illustrates my cognitive difficulties and use of placeholder words along with slight slurring.
As far as pitch, seems that we had similar issues with pitch throughout the 15 second clips, mine spiked in the latter when I was getting "wore out" and hers spiked earlier when she had more energy.
Our energy levels differ because although she had moments of energy, I tuckered out pretty quickly.
I hope this helps shed some insight into both aphasia patients and ataxic dysarthria / HD patients speech / some cognitive differences.
Will update again tomorrow when I am done with another day of programming and research!
#python#python developer#python development#data science#data scientist#data processing#data scraping#web scraping#speech pathology#speech disorder#ataxic dysarthria#ataxia#huntingtons disease#stroke#dementia#aphasia#data analyst#data analysis#medical research#medical technology#medical#biotechnology#artificial intelligence#sound processing#sound engineering#machine learning#ai#cognitive issues
10 notes
·
View notes
Text
Everything You Need to Know About Machine Learning
Ready to step into the world of possibilities with machine learning? Learn all about machine learning and its cutting-edge technology. From what do you need to learn before using it to where it is applicable and their types, join us as we reveal the secrets. Read along for everything you need to know about Machine Learning!

What is Machine Learning?
Machine Learning is a field of study within artificial intelligence (AI) that concentrates on creating algorithms and models which enable computers to learn from data and make predictions or decisions without being explicitly programmed. The process involves training a computer system using copious amounts of data to identify patterns, extract valuable information, and make precise predictions or decisions.
Fundamentally, machine Learning relies on statistical techniques and algorithms to analyze data and discover patterns or connections. These algorithms utilize mathematical models to process and interpret data. Revealing significant insights that can be utilized across various applications by different AI ML services.
What do you need to know for Machine Learning?
You can explore the exciting world of machine learning without being an expert mathematician or computer scientist. However, a basic understanding of statistics, programming, and data manipulation will benefit you. Machine learning involves exploring patterns in data, making predictions, and automating tasks.
It has the potential to revolutionize industries. Moreover, it can improve healthcare and enhance our daily lives. Whether you are a beginner or a seasoned professional embracing machine learning can unlock numerous opportunities and empower you to solve complex problems with intelligent algorithms.
Types of Machine Learning
Let’s learn all about machine learning and know about its types.
Supervised Learning
Supervised learning resembles having a wise mentor guiding you every step of the way. In this approach, a machine learning model is trained using labeled data wherein the desired outcome is already known.
The model gains knowledge from these provided examples and can accurately predict or classify new, unseen data. It serves as a highly effective tool for tasks such as detecting spam, analyzing sentiment, and recognizing images.
Unsupervised Learning
In the realm of unsupervised learning, machines are granted the autonomy to explore and unveil patterns independently. This methodology mainly operates with unlabeled data, where models strive to unearth concealed structures or relationships within the information.
It can be likened to solving a puzzle without prior knowledge of what the final image should depict. Unsupervised learning finds frequent application in diverse areas such as clustering, anomaly detection, and recommendation systems.
Reinforcement Learning
Reinforcement learning draws inspiration from the way humans learn through trial and error. In this approach, a machine learning model interacts with an environment and acquires knowledge to make decisions based on positive or negative feedback, referred to as rewards.
It's akin to teaching a dog new tricks by rewarding good behavior. Reinforcement learning finds extensive applications in areas such as robotics, game playing, and autonomous vehicles.
Machine Learning Process
Now that the different types of machine learning have been explained, we can delve into understanding the encompassing process involved.
To begin with, one must gather and prepare the appropriate data. High-quality data is the foundation of any triumph in a machine learning project.
Afterward, one should proceed by selecting an appropriate algorithm or model that aligns with their specific task and data type. It is worth noting that the market offers a myriad of algorithms, each possessing unique strengths and weaknesses.
Next, the machine goes through the training phase. The model learns from making adjustments to its internal parameters and labeled data. This helps in minimizing errors and improves its accuracy.
Evaluation of the machine’s performance is a significant step. It helps assess machines' ability to generalize new and unforeseen data. Different types of metrics are used for the assessment. It includes measuring accuracy, recall, precision, and other performance indicators.
The last step is to test the machine for real word scenario predictions and decision-making. This is where we get the result of our investment. It helps automate the process, make accurate forecasts, and offer valuable insights. Using the same way. RedBixbite offers solutions like DOCBrains, Orionzi, SmileeBrains, and E-Governance for industries like agriculture, manufacturing, banking and finance, healthcare, public sector and government, travel transportation and logistics, and retail and consumer goods.
Applications of Machine Learning
Do you want to know all about machine learning? Then you should know where it is applicable.
Natural Language Processing (NLP)- One area where machine learning significantly impacts is Natural Language Processing (NLP). It enables various applications like language translation, sentiment analysis, chatbots, and voice assistants. Using the prowess of machine learning, NLP systems can continuously learn and adapt to enhance their understanding of human language over time.
Computer Vision- Computer Vision presents an intriguing application of machine learning. It involves training computers to interpret and comprehend visual information, encompassing images and videos. By utilizing machine learning algorithms, computers gain the capability to identify objects, faces, and gestures, resulting in the development of applications like facial recognition, object detection, and autonomous vehicles.
Recommendation Systems- Recommendation systems have become an essential part of our everyday lives, with machine learning playing a crucial role in their development. These systems carefully analyze user preferences, behaviors, and patterns to offer personalized recommendations spanning various domains like movies, music, e-commerce products, and news articles.
Fraud Detection- Fraud detection poses a critical concern for businesses. In this realm, machine learning has emerged as a game-changer. By meticulously analyzing vast amounts of data and swiftly detecting anomalies, machine learning models can identify fraudulent activities in real-time.
Healthcare- Machine learning has also made great progress in the healthcare sector. It has helped doctors and healthcare professionals make precise and timely decisions by diagnosing diseases and predicting patient outcomes. Through the analysis of patient data, machine learning algorithms can detect patterns and anticipate possible health risks, ultimately resulting in early interventions and enhanced patient care.
In today's fast-paced technological landscape, the field of artificial intelligence (AI) has emerged as a groundbreaking force, revolutionizing various industries. As a specialized AI development company, our expertise lies in machine learning—a subset of AI that entails creating systems capable of learning and making predictions or decisions without explicit programming.
Machine learning's widespread applications across multiple domains have transformed businesses' operations and significantly enhanced overall efficiency.
#ai/ml#ai#artificial intelligence#machine learning#ai development#ai developers#data science#technology#data analytics#data scientist#data processing
3 notes
·
View notes
Text
#data#data cleaning#data science#machine learning algorithms#machine learning#ai#data processing#big data#data mining
9 notes
·
View notes
Link
This guide provides valuable insights into the benefits of having a portfolio and offers a range of significant projects that can be included to help you get started or accelerate your career in data science. Download Now.
#database#data mining#data warehousing#data#data science#data scientist#data analysis#data analyst#Big Data Analysis#data processing#data projects
5 notes
·
View notes
Text
python matching with ngrams
# https://pythonprogrammingsnippets.com def get_ngrams(text, n): # split text into n-grams. ngrams = [] for i in range(len(text)-n+1): ngrams.append(text[i:i+n]) return ngrams def compare_strings_ngram_pct(string1, string2, n): # compare two strings based on the percentage of matching n-grams # Split strings into n-grams string1_ngrams = get_ngrams(string1, n) string2_ngrams = get_ngrams(string2, n) # Find the number of matching n-grams matching_ngrams = set(string1_ngrams) & set(string2_ngrams) # Calculate the percentage match percentage_match = (len(matching_ngrams) / len(string1_ngrams)) * 100 return percentage_match def compare_strings_ngram_max_size(string1, string2): # compare two strings based on the maximum matching n-gram size # Split strings into n-grams of varying lengths n = min(len(string1), len(string2)) for i in range(n, 0, -1): string1_ngrams = set(get_ngrams(string1, i)) string2_ngrams = set(get_ngrams(string2, i)) # Find the number of matching n-grams matching_ngrams = string1_ngrams & string2_ngrams if len(matching_ngrams) > 0: # Return the maximum matching n-gram size and break out of the loop return i # If no matching n-grams are found, return 0 return 0 string1 = "hello world" string2 = "hello there" n = 2 # n-gram size # find how much of string 2 matches string 1 based on n-grams percentage_match = compare_strings_ngram_pct(string1, string2, n) print(f"The percentage match is: {percentage_match}%") # find maximum ngram size of matching ngrams max_match_size = compare_strings_ngram_max_size(string1, string2) print(f"The maximum matching n-gram size is: {max_match_size}")
#python#ngrams#ngram#string comparison#strings#string#comparison#basic python#python programming#tutorial#snippets#nlp#natural language processing#ai processing#data#datascience#data processing#language#matching strings#string matching#matching#ai#text processing#text#processing#dev#developer#programmer#programming#source code
4 notes
·
View notes
Link
#Financial Services#Data Processing#California#Los Angeles#United States#govt Assist LLC#Web Hosting Services
5 notes
·
View notes
Text
What is Data Protection Act in India?
Introduction
Data Protection Act in India is a law that provides for the protection of personal data. It was first introduced in 2007, and it has been revised multiple times since then. In this article, we will discuss what the proposed Data Protection Act in India includes and how it compares with GDPR.
Data Protection Act in India
The Data Protection Act, 2018 is the primary legislation governing data protection in India. It sets out the principles that organizations should follow to ensure that their personal information is handled with care and security.
The bill was passed by Parliament on March 27, 2018 and came into force on April 1, 2018.[1] It replaced the previous Personal Data Protection Bill, 2012 which had been in effect since July 1, 2012.[2] This second draft was made public by Home Minister Rajnath Singh after intense lobbying by civil society groups who felt it did not go far enough in protecting people's privacy rights.[3][4][5][6]
First Point of Focus is the Personal Data
Data protection act in India
A. What is personal data?
Data is any information that can be used to identify or contact an individual, such as name, address and email id. Personal information includes names, addresses and contact details of individuals; biometric data such as fingerprints and iris scans; financial information (such as credit card numbers); health records; genetic characteristics/proteins in blood samples etc., etc., which can be used for identification purposes by an individual or group of individuals. Sensitive personal data are those which relate to racial or ethnic origin, political opinions or religious beliefs of an individual; criminal history including mental illness or disability; sexual orientation/identity (e.g., gay/lesbian).
The second point of focus is the ‘Personal Information’
The second point of focus is the ‘Personal Information’. This means any information that specifically identifies an individual, such as his/her name, date of birth and address. It also includes anything else which can be used to identify an individual (e.g., fingerprints or facial features).
The term ‘sensitive personal data’ has been defined in Section 2(1)(b) as follows:
"Sensitive personal data" means any information relating to an identified or identifiable natural person who can be directly or indirectly traced back to him/her by means of such information."
The third point of focus is on the “Sensitive Personal Data”
The third point of focus is on the “Sensitive Personal Data”. This is information about race, religion, caste, tribe, ethnic origin or political opinions. It also includes philosophical beliefs and union membership.
In India there are two types of sensitive personal data - namely genetic data (including DNA), biometric information such as fingerprints or iris scans etc., national identification numbers issued by a central authority such as Aadhaar card issued under Section 7(1) of Aadhaar Act 2016 which has been put in place by Government through its Rule making power under Article 239B(1) in order to establish an identity management system across various government departments and agencies including UIDAI (Unique Identification Authority of India). Therefore every authority must ensure that they comply with this law while collecting any kind of sensitive personal information from individuals who are involved in the process
The fourth point of focus is on the “Proprietary Data”
The fourth point of focus is on the “Proprietary Data”. This refers to any data that is not publicly available, but which can be used by an individual or organization.
Proprietary data may be personally identifiable information (e.g., name and address), financial information (e.g., credit card number), business process details (e.g., sales data), customer lists or similar types of information that can only be accessed by one party at a time for specific purposes such as marketing campaigns or product development etc
How does the proposed Data Protection Act in India compare with GDPR?
The proposed Data Protection Act in India is similar to GDPR in that it has a broad definition of personal data and sets out a number of principles for protecting the same. However, there are some key differences between these two pieces of legislation:
The proposed Data Protection Act excludes “sensitive data” from its scope (which would include ethnic origin and religious belief). While this may seem like an advantageous feature at first glance, it could actually prove problematic if you need access to sensitive information about your clients or employees. For example, if someone were being treated for cancer and needed their diagnosis recorded on their file as part of their treatment plan—and that information was deemed too important not just for them but also anyone who might come across it later on—your organization would likely be required by law to keep such details private so only those involved with treating them could access them safely.
Information about data protection in India provides some details about its GDPR elements.
Data Protection Act in India
The Information Technology (IT) Act, 2000 defines the term ‘personal information’ as follows:
any information that can be used to identify a person, and which is recorded in any form or medium; or
any information which relates to an individual and is specified by law to be required to be maintained by an agency or body.
Conclusion
It is recommended that you must keep the data protection in mind while using the various internet resources. You need to be careful about what you are sharing on the internet, especially with public social media websites like facebook, twitter and instagram etc . The proposed Data Protection Act should provide a more secure ecosystem for users to use these services without fear of being affected by hackers or criminals.
2 notes
·
View notes
Text
In-process libs for a processing pipeline as a DAG of actions
From Clojurians Slack, key contributions by Adrian Smith, respatilized, Ben Sless.
Ben Sless' more.async/dataflow for composing simple core.async processes, inspired by Onyx.
Bob CI (uses XTDB for persistence)
Onyx - written with distributed computation in mind but as far as I know nothing prevents running it entirely in memory on a single node. Designed exactly for the type of dynamic workflow definition you describe. The docs are extremely thoughtfully written, describing exactly why an information model is superior to an API
Dativity - a 'stateless process engine' that allows DAG-like computation by dispatching functions on the basis of what the data looks like at a given point in time. Not sure how dynamic it can be at runtime, though.
Daguerreo- explicitly patterned after Apache Airflow but designed to run in-process.
Matrix ("Fine-grained, transparent data flow between generative objects.") - it's kind of at the boundary between reactive programming and DAG computation.
Overseer - (see above description, basically - but stores job state in Datomic)
Titanoboa (though not in-process)
Note: Dynamic manipulation of the DAG and full state inspection are generally missing in these.
An article by respatialized on the topic: Organizing Computation With Finite Schema Machines, where he outlines his thinking about how to solve a similar problem using malli schemas without pulling in a library like one of those.
Some more libs:
https://github.com/plumatic/plumbing
https://github.com/vvvvalvalval/mapdag
https://github.com/hesenp/dag-runner
https://github.com/clj-commons/dirigiste
https://github.com/kyleburton/impresario
https://github.com/andrewmcveigh/workflows
2 notes
·
View notes
Link

In the current business climate, organizations produce and consume data at remarkable speed. That's why there is a growing need for efficient data...
#datamanagementservices#data entry service companies#data processing#data conversion services#data entry outsourcing company#data management
2 notes
·
View notes
Text
Pocket-Sized Powerhouse: Unveiling Microsoft’s Phi-3, the Language Model That Fits in Your Phone
New Post has been published on https://thedigitalinsider.com/pocket-sized-powerhouse-unveiling-microsofts-phi-3-the-language-model-that-fits-in-your-phone/
Pocket-Sized Powerhouse: Unveiling Microsoft’s Phi-3, the Language Model That Fits in Your Phone
In the rapidly evolving field of artificial intelligence, while the trend has often leaned towards larger and more complex models, Microsoft is adopting a different approach with its Phi-3 Mini. This small language model (SLM), now in its third generation, packs the robust capabilities of larger models into a framework that fits within the stringent resource constraints of smartphones. With 3.8 billion parameters, the Phi-3 Mini matches the performance of large language models (LLMs) across various tasks including language processing, reasoning, coding, and math, and is tailored for efficient operation on mobile devices through quantization.
Challenges of Large Language Models
The development of Microsoft’s Phi SLMs is in response to the significant challenges posed by LLMs, which require more computational power than typically available on consumer devices. This high demand complicates their use on standard computers and mobile devices, raises environmental concerns due to their energy consumption during training and operation, and risks perpetuating biases with their large and complex training datasets. These factors can also impair the models’ responsiveness in real-time applications and make updates more challenging.
Phi-3 Mini: Streamlining AI on Personal Devices for Enhanced Privacy and Efficiency
The Phi-3 Mini is strategically designed to offer a cost-effective and efficient alternative for integrating advanced AI directly onto personal devices such as phones and laptops. This design facilitates faster, more immediate responses, enhancing user interaction with technology in everyday scenarios.
Phi-3 Mini enables sophisticated AI functionalities to be directly processed on mobile devices, which reduces reliance on cloud services and enhances real-time data handling. This capability is pivotal for applications that require immediate data processing, such as mobile healthcare, real-time language translation, and personalized education, facilitating advancements in these fields. The model’s cost-efficiency not only reduces operational costs but also expands the potential for AI integration across various industries, including emerging markets like wearable technology and home automation. Phi-3 Mini enables data processing directly on local devices which boosts user privacy. This could be vital for managing sensitive information in fields such as personal health and financial services. Moreover, the low energy requirements of the model contribute to environmentally sustainable AI operations, aligning with global sustainability efforts.
Design Philosophy and Evolution of Phi
Phi’s design philosophy is based on the concept of curriculum learning, which draws inspiration from the educational approach where children learn through progressively more challenging examples. The main idea is to start the training of AI with easier examples and gradually increase the complexity of the training data as the learning process progresses. Microsoft has implemented this educational strategy by building a dataset from textbooks, as detailed in their study “Textbooks Are All You Need.” The Phi series was launched in June 2023, beginning with Phi-1, a compact model boasting 1.3 billion parameters. This model quickly demonstrated its efficacy, particularly in Python coding tasks, where it outperformed larger, more complex models. Building on this success, Microsoft latterly developed Phi-1.5, which maintained the same number of parameters but broadened its capabilities in areas like common sense reasoning and language understanding. The series outshined with the release of Phi-2 in December 2023. With 2.7 billion parameters, Phi-2 showcased impressive skills in reasoning and language comprehension, positioning it as a strong competitor against significantly larger models.
Phi-3 vs. Other Small Language Models
Expanding upon its predecessors, Phi-3 Mini extends the advancements of Phi-2 by surpassing other SLMs, such as Google’s Gemma, Mistral’s Mistral, Meta’s Llama3-Instruct, and GPT 3.5, in a variety of industrial applications. These applications include language understanding and inference, general knowledge, common sense reasoning, grade school math word problems, and medical question answering, showcasing superior performance compared to these models. The Phi-3 Mini has also undergone offline testing on an iPhone 14 for various tasks, including content creation and providing activity suggestions tailored to specific locations. For this purpose, Phi-3 Mini has been condensed to 1.8GB using a process called quantization, which optimizes the model for limited-resource devices by converting the model’s numerical data from 32-bit floating-point numbers to more compact formats like 4-bit integers. This not only reduces the model’s memory footprint but also improves processing speed and power efficiency, which is vital for mobile devices. Developers typically utilize frameworks such as TensorFlow Lite or PyTorch Mobile, incorporating built-in quantization tools to automate and refine this process.
Feature Comparison: Phi-3 Mini vs. Phi-2 Mini
Below, we compare some of the features of Phi-3 with its predecessor Phi-2.
Model Architecture: Phi-2 operates on a transformer-based architecture designed to predict the next word. Phi-3 Mini also employs a transformer decoder architecture but aligns more closely with the Llama-2 model structure, using the same tokenizer with a vocabulary size of 320,641. This compatibility ensures that tools developed for Llama-2 can be easily adapted for use with Phi-3 Mini.
Context Length: Phi-3 Mini supports a context length of 8,000 tokens, which is considerably larger than Phi-2’s 2,048 tokens. This increase allows Phi-3 Mini to manage more detailed interactions and process longer stretches of text.
Running Locally on Mobile Devices: Phi-3 Mini can be compressed to 4-bits, occupying about 1.8GB of memory, similar to Phi-2. It was tested running offline on an iPhone 14 with an A16 Bionic chip, where it achieved a processing speed of more than 12 tokens per second, matching the performance of Phi-2 under similar conditions.
Model Size: With 3.8 billion parameters, Phi-3 Mini has a larger scale than Phi-2, which has 2.7 billion parameters. This reflects its increased capabilities.
Training Data: Unlike Phi-2, which was trained on 1.4 trillion tokens, Phi-3 Mini has been trained on a much larger set of 3.3 trillion tokens, allowing it to achieve a better grasp of complex language patterns.
Addressing Phi-3 Mini’s Limitations
While the Phi-3 Mini demonstrates significant advancements in the realm of small language models, it is not without its limitations. A primary constraint of the Phi-3 Mini, given its smaller size compared to massive language models, is its limited capacity to store extensive factual knowledge. This can impact its ability to independently handle queries that require a depth of specific factual data or detailed expert knowledge. This however can be mitigated by integrating Phi-3 Mini with a search engine. This way the model can access a broader range of information in real-time, effectively compensating for its inherent knowledge limitations. This integration enables the Phi-3 Mini to function like a highly capable conversationalist who, despite a comprehensive grasp of language and context, may occasionally need to “look up” information to provide accurate and up-to-date responses.
Availability
Phi-3 is now available on several platforms, including Microsoft Azure AI Studio, Hugging Face, and Ollama. On Azure AI, the model incorporates a deploy-evaluate-finetune workflow, and on Ollama, it can be run locally on laptops. The model has been tailored for ONNX Runtime and supports Windows DirectML, ensuring it works well across various hardware types such as GPUs, CPUs, and mobile devices. Additionally, Phi-3 is offered as a microservice via NVIDIA NIM, equipped with a standard API for easy deployment across different environments and optimized specifically for NVIDIA GPUs. Microsoft plans to further expand the Phi-3 series in the near future by adding the Phi-3-small (7B) and Phi-3-medium (14B) models, providing users with additional choices to balance quality and cost.
The Bottom Line
Microsoft’s Phi-3 Mini is making significant strides in the field of artificial intelligence by adapting the power of large language models for mobile use. This model improves user interaction with devices through faster, real-time processing and enhanced privacy features. It minimizes the need for cloud-based services, reducing operational costs and widening the scope for AI applications in areas such as healthcare and home automation. With a focus on reducing bias through curriculum learning and maintaining competitive performance, the Phi-3 Mini is evolving into a key tool for efficient and sustainable mobile AI, subtly transforming how we interact with technology daily.
#000#2023#ai#AI integration#ai studio#API#applications#approach#architecture#artificial#Artificial Intelligence#automation#azure#Bias#billion#Building#Children#Cloud#cloud services#coding#comparison#complexity#comprehension#comprehensive#computers#content#content creation#data#data processing#datasets
0 notes
Text
Demystifying Data Engineering: The Backbone of Modern Analytics
Hey friends! Check out this in-depth blog on #DataEngineering that explores its role in building robust data pipelines, ensuring data quality, and optimizing performance. Discover emerging trends like #cloudcomputing, #realtimeprocessing, and #DataOps
In the era of big data, data engineering has emerged as a critical discipline that underpins the success of data-driven organizations. Data engineering encompasses the design, construction, and maintenance of the infrastructure and systems required to extract, transform, and load (ETL) data, making it accessible and usable for analytics and decision-making. This blog aims to provide an in-depth…

View On WordPress
#artificial intelligence#big data#Cloud Computing#data analytics#data architecture#data catalog#data democratization#data engineering#data engineering best practices#data governance#data infrastructure#data ingestion#data integration#data lifecycle#data migration#data modeling#data pipelines#data privacy#data processing#data quality#data science#data security#data storage#data streaming#data transformation#data warehouse#DataOps#Distributed Computing#ETL#machine learning
2 notes
·
View notes
Text
Efficient Data Management Solutions: Streamline Your Operations
#Data management#Data organization#Data storage#Data optimization#Data accessibility#Data solutions#Information management#Data processing#Database management#Data governance
0 notes
Text
#adaptability#AI challenges#AI Development#AI in the workplace#AI limitations#AI trends#AI vs human intelligence#algorithms#Artificial Intelligence#artificial intelligence models#bias in AI#cognitive psychology#collaboration#computational techniques#creativity#creativity in AI#data processing#Data Security#deep learning#emotional intelligence#ethical considerations#future of AI#future of human intelligence#human cognition#human intelligence#human vs AI#IQ tests#Job search#learning process#machine intelligence
1 note
·
View note
Text
How An Advanced Survey Analysis Software Can Predict The Growth Trajectory Of Your Business
The severe competition that prevails in every industry demands that you accurately predict your growth trajectory so that you can make strategic decisions. While traditional forecasting methods offer some insights, they often overlook a valuable source of information namely, customer and employee feedback. This is where advanced survey analysis software steps in, offering a powerful tool to not only understand your current state but also predict your future course. Let us explore how these sophisticated software solutions can empower you to map a path to sustainable business growth.

Sophisticated survey analysis software extends beyond elementary data gathering and visualisation. It employs advanced statistical methods to unveil concealed patterns and connections within your survey data. Consider the ability to pinpoint particular customer segments at risk of churn or to identify employee engagement factors directly linked to heightened productivity. These insights surpass mere descriptive statistics, uncovering deeper trends in customer behaviour and workforce sentiments crucial for foreseeing future outcomes. By harnessing these predictive capacities, you can pre-emptively tackle potential hurdles and seize emerging opportunities before they become evident.
Top rated survey software goes even further by offering scenario modelling. This allows you to directly test the potential effects of various business decisions on critical metrics like customer satisfaction, brand loyalty, and employee retention. Imagine simulating the launch of a new product to see its impact on specific customer segments, or analysing how a revised employee benefits package might influence overall engagement. This empowers you to make data-driven decisions with greater confidence. By testing different scenarios beforehand, you can mitigate risks and maximise the potential for positive outcomes. In simpler terms, you can predict the success of a marketing campaign before allocating significant resources, or gauge employee receptiveness to a new company policy before implementation.
In addition to its essential features, advanced survey analysis software frequently integrates with other business intelligence tools. This seamless merging enables you to blend survey data with other pertinent datasets, such as sales data, website analytics, and social media engagement metrics. By constructing a comprehensive view of your business landscape, you acquire a deeper comprehension of the elements shaping your growth path. For example, you can uncover connections between customer satisfaction levels and particular marketing initiatives, or evaluate how employee morale influences overall customer service quality. This thorough data analysis empowers you to identify pivotal growth drivers and make informed decisions that enhance all facets of your business operations.
1 note
·
View note
Link
#Data Processing#Web Hosting#California#United States#Govt Assist LLC#Data Structure#Financial Services
2 notes
·
View notes
Last Seen Blogs

fafidanab
Untitled

jassuruartblog
Applause Applesauce

glaretoms
if you dare, you'll see the glare

that-freak-named-ben
Benjamin Fucking Somerset

vedolosowa
Untitled