#ReadTheDocs
Text
Using Cython to Optimize Python Code
Python is a popular and versatile programming language, but it can be slow compared to other languages like C or C++. This is where Cython comes in. Cython is a tool that allows you to write Python-like code, but compiles it to C, resulting in faster performance.
Cython is particularly useful for scientific and numerical computing, where performance is critical. It can be used to optimize existing Python code, or write new code in Cython for improved performance. In this article, we’ll take a look at how to use Cython and why it’s valuable for Python programmers to learn.
Getting started with Cython is easy. You can install it using pip, the Python package manager, by running the following command in your terminal:

Once you have Cython installed, you can start using it to optimize your Python code. The basic idea is to write your code in Cython, then compile it to C, which can then be imported and used in your Python code.
Here’s a simple example that demonstrates how to use Cython. Let’s say we have a Python function that calculates the sum of squares of numbers in a list:

We can optimize this function by writing it in Cython, then compiling it to C. Here’s the Cython version:

In this example, we’ve added a cdef statement to declare the variables as C data types, which results in faster performance. We can then compile this Cython code to C using the following command in our terminal:
This will generate a .c file that can be imported and used in your Python code.
Cython is a powerful tool that allows you to write Python-like code and optimize it for performance. Whether you’re working on scientific and numerical computing or just looking to improve the performance of your code, Cython is worth learning.
Some great resources for learning Cython include the official documentation, tutorials and example code on the Cython website, and the “Cython: A Guide for Python Programmers” book by Kurt Smith.
Here is the Cython Wiki:
As well as the ReadTheDocs for Cython:
There is also a great tutorial series on using Cython by Pythonist on Youtube
youtube
By using Cython, you can take your Python skills to the next level and achieve faster performance for your code. Give it a try and see the results for yourself!
#Cython#python#Cpython#python programming#python3#python code#python tips#python programmer#tips and tricks#tech tips#tech tutorial#programming tutorial#code optimization#better programmer#tips#programming#programmer#programmers#tech industry#tech#Youtube
7 notes
·
View notes
Text
nhangtramhuongtphcm
Roomstyler: https://roomstyler.com/users/nhangtramhuongtphcm
Twitch.tv: https://www.twitch.tv/nhangtramhuongtphcm
Ebay: https://www.ebay.com/usr/nhangtramhcm
Readthedocs: https://readthedocs.org/projects/nhangtramhuongtphcm/ Zazzle: https://www.zazzle.com/mbr/238919026957795146
0 notes
Text
Which Linux distros have downloadable documentation?
I can’t read readthedocs. It gives me migraines.
0 notes
Text
[Media] securityonion-docs
securityonion-docs
This repo stores the source code for our documentation which is published by ReadTheDocs
We use RST format so that ReadTheDocs can publish in both HTML and PDF formats.
https://github.com/Security-Onion-Solutions/securityonion-docs
0 notes
Text
Anyone else find it just absolutely infuriating when technical projects use Google Groups for their mailing lists or forums or other discussions or questions?
I don't know about you, but I don't enjoy waiting several seconds until some plaintext discussion on golang-nuts loads, for example.
Which it does take several seconds, even on a modern high end laptop or phone.
I haven't timed it, but literally anything else - GitHub issues, godoc, readthedocs, etc - all load significantly faster - or at least something about all of those feels much less like a jarring mental slowdown to me.
1 note
·
View note
Text
The Perfect Documentation Storm
Let’s be clear. Nobody likes writing documentation. Writing good documentation is also hard. Making it look visually pleasing can be even more challenging. I’ve been involved with a project aimed to make user documentation easy to consume but also easy for anyone to contribute to. My north star for good documentation is the Ansible documentation. It’s visually very pleasing, easy to find stuff and it’s all there. Google does a damn good job indexing it so whatever you need is three keywords away. The project at hand is not capable of leveraging some of magic sauces behind the Ansible documentation project but I found a middle ground that completely blew my away. From here on forward this is the toolchain I will recommend for all and any documentation project: MkDocs and GitHub Pages.
Requirements
The bulk of our starting source docs today is all written in markdown and we were not interested in converting to a new “language” or learn a new one. It has to be version controlled, human readable and reviewable markdown. It disqualifies a bunch of different popular tools out there, but hear me out her. So, GitHub is an excellent place to store, version and review markdown files, let's start there.
Next, there needs to be a way to edit and review the markdown rendering locally (or remotely) efficiently before submitting pull requests. It should not be counter-productive with multiple tools, renders and manual refresh/walkthrough navigation to get visual feedback. As we sniffed around other successful documentation projects we learned about MkDocs as we investigated the capabilities of Read The Docs. Little did we know that MkDocs lets you render and edit docs locally very efficiently, it’s widely used, extensible and looks beautiful out-of-the-box. Just add markdown!
Also, MkDocs can deploy directly to GitHub Pages by putting the rendered output in a separate branch and all of a sudden you have everything in one place. That alone makes it very convenient as we don’t have to interact with separate services to host the documentation. One might think we’re done here but it leaves one big gap in the solution, that is the reviewing of pull requests part. In the event of a pull request, the person who merges to master needs to render the pages after the merge. You may quickly resort to readthedocs.org for this reason but what if I told you that there is a GitHub Action available that does this for you already? That changes the game. Full control end-to-end through GitHub. Let's do it!
Hello World
Since it wasn’t glaringly obvious to me on how to piece everything together, I thought I share my findings in this blog. Let’s walk through a Hello World example where we start with nothing.
First, create a new empty GitHub repo and clone it (you need to create your own repo as my demo repo won't work).
$ git clone https://github.com/drajen/hello-docs Cloning into 'hello-docs'...
Next, we need to install mkdocs if you haven’t already. Acquiring Python and pip is beyond the scope of this tutorial.
$ sudo pip install mkdocs
Change dir into the hello-docs directory and run:
$ cd hello-docs $ mkdocs new . INFO - Writing config file: ./mkdocs.yml INFO - Writing initial docs: ./docs/index.md
The mkdocs command creates the docs directory, this is where your source markdown lives. A skeleton index.md is populated with some MkDocs metadata. There’s also a starter mkdocs.yml file that allows you to configure your project. I want to use the Read The Docs theme, so, let’s configure that:
$ echo 'theme: readthedocs' >> mkdocs.yml
Next, we want to visually inspect what the documentation looks like:
$ mkdocs serve INFO - Building documentation... INFO - Cleaning site directory [I 200311 16:29:05 server:296] Serving on http://127.0.0.1:8000 [I 200311 16:29:05 handlers:62] Start watching changes [I 200311 16:29:05 handlers:64] Start detecting changes
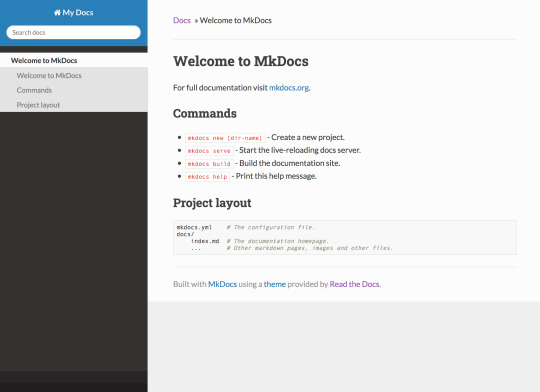
Browsing to http://127.0.0.1:8000/ should now present the following website:
In an attempt to try illustrate how the local editing works, I generated a GIF from a screen capture. Simply edit text in your favorite editor (vi) and hit :w. The content will automatically be rebuilt and reloaded based on your markdown edits.
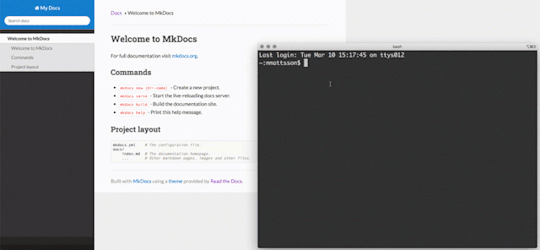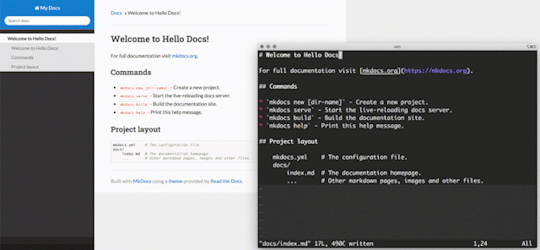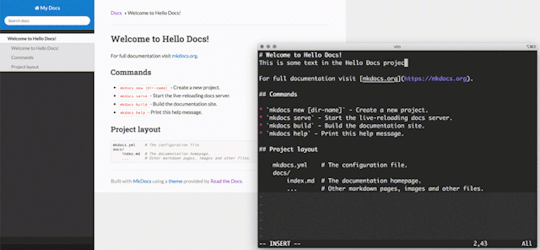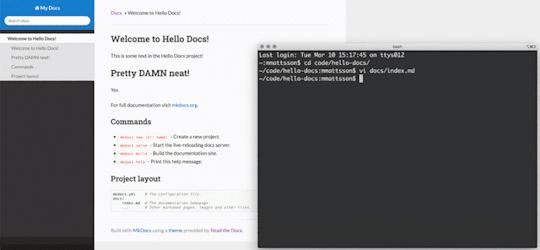
This is awesome!
Publish!
Not quite done yet. To demonstrate the next steps, we need to publish our site. Let’s add site/ (where the local build lives) to .gitignore and push our content.
$ echo 'site/' >>.gitignore $ git add . $ git commit -a -m 'Initial hack...' $ git push origin master
Next, have MkDocs publish to the gh-pages branch.
$ mkdocs gh-deploy INFO - Cleaning site directory INFO - Building documentation to directory: /Users/mmattsson/code/hello-docs/site WARNING - Version check skipped: No version specificed in previous deployment. INFO - Copying '/Users/mmattsson/code/hello-docs/site' to 'gh-pages' branch and pushing to GitHub. INFO - Your documentation should shortly be available at: https://drajen.github.io/hello-docs/
Visiting the URL MkDocs spits out above should be rendered in a few moments. It’s possible to tweak the URL by setting a custom domain for GitHub Pages under the repository settings. You’ll need a DNS CNAME pointing to <user/org>.github.io for that to work properly.
Action!
Now the skeleton is published. How do we accept pull requests and have the gh-pages branch rebuilt on merge to master? This GitHub Action does that exact job for you.
It only works reliably with personal tokens. A token is generated on your user account and a secret is part of the repository settings.
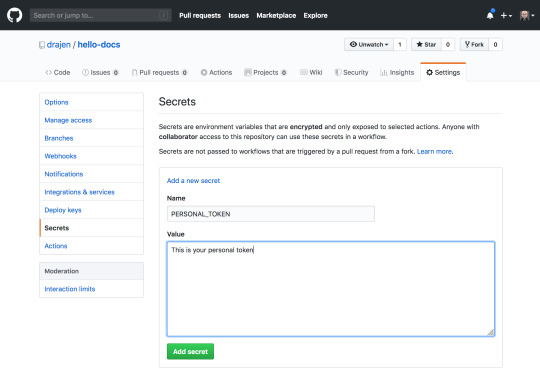
So, in the middle bar you’ll find an “Actions” tab, create a new workflow and paste in the YAML from the Deploy MkDocs GitHub Action. Don’t forget to change the token attribute!
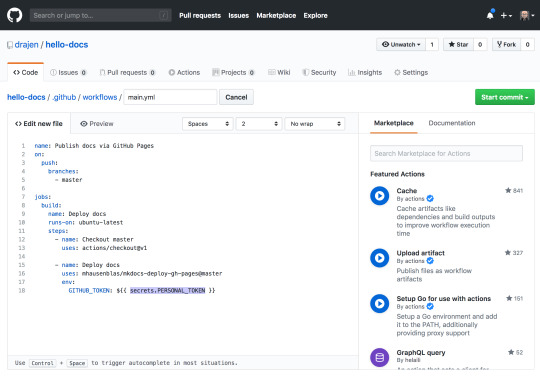
Now, this GitHub Action will run for each merge to master, that makes it easy to accept pull requests for markdown. If big navigational changes is in the PR, it could make sense to clone the pull request and render the branch locally. That will allow visual inspection of the navigation and check for errors in the MkDocs build log.
Happy documenting!
0 notes
Text
January 11, 2018
News and Links
Constantinople is coming. [Also, this is the January 11, 2019 issue but I can't fix the title without breaking links]
Upgrade your clients ASAP! EF FAQ and blog post. From MyCrypto, what users need to know about the Constantinople fork
Layer 1
[eth1] Rinkeby testnet forked successfully. Update your clients ASAP!
[eth2] What’s New in Eth2
[eth2] Latest Eth2 implementer call notes
[eth2] Validator economics of Eth2. Also a thorough Eth staking ROI spreadsheet model
[eth2] Discussion about storage rent “eviction archive” nodes and incentives
web3foundation, Status and Validity Labs update and call for participants on private, decentralized messaging, a la Whisper
Layer 2
Live on Rinkeby testnet: Plasma Ignis - often called “roll up” - 500 transactions per second using SNARKs for compression (not privacy), no delay to exit, less liveness requirements, multi-operator. Check out the live demo.
Georgios Konstantopoulos: A Deep Dive on RSA Accumulators
Canto: proposed new subprotocol to allow sidechain-like subnets
Fae: a subnet by putting Fae’s binary transactions in the data field
A RaidenNetwork deep dive explainer
Can watchtowers and monitoring services scale?
Counterfactual dev update: full end to end implementation of Counterfactual with demos and dev environment will be live on Ropsten in next 2 weeks
Stuff for developers
Embark v4.0.0-beta.0
Ganache v2.0.0-beta.2
ZeppelinOS v2.1
Updated EthereumJS readthedocs
Solidity CTF: mirror madness from authio
Solstice: 15 analyzer Solidity security tool
EVM code fuzzing using input prediction
Compound’s self-liquidation bug
Gas Stations Network, an incentivized meta transaction relay network, live on Ropsten
Understanding Rust lifetimes
How to quickly deploy to Görli cross-client testnet
Maker CDP leverager in one call
Codefund2.0 - sustainability for open source project advertising without 3rd party trackers
RSA accumulator in Vyper
Analyzing 1.2m mainnet contracts in 20 seconds using Eveem and BigQuery
0x Market Maker program. 15k to run a market making bot on a 0x relayer
POANet: Honey Badger BFT and Threshold Cryptography
Ecosystem
Afri’s Eth node configuration modes cheat sheet. A great accompaniment to Afri’s did Ethereum reach 1 tb yet? The answer is obviously no, state plus chaindata is about 150 GB.
MyEtherWallet v5 is in beta and MEWConnect on Android
Ethereum Foundation major grant to Parity: $5m for ewasm, light wallet, and Eth2
Enterprise
What enterprises need to know about AWS’s Blockchain as a Service
2019 is the year of enterprise tokens?
Governance and Standards
Notes from latest core devs call, includes ProgPoW section. On that topic, IfDefElse put out a ProgPoW FAQ including responses from AMD and Nvidia. Also check understanding ProgPoW from a few months ago
Martin Köppelmann on the governance protocol of DXdao
Pando Network: DAOs and the future of content
EIP1682: storage rent
EIP1681: temporal replay protection
ERC1683: URLs with asset and onboarding functionality
ERC1690: Mortability standard
ERC820 Pseudo-introspection Registry Contract is final
ERC1155 multi-token standard to last call
Application layer
Demo testing on Kovan testnet of the Digix governance platform
Brave at 5.5m MAUs, up 5x in 2018. It also got much more stable over the year, and being able to use a private tab with TOR on desktop makes it a must (mobile has been a must for a long time). Here’s my referral code if you haven’t switched yet.
I saw some warnings about tokenized US equity DX.exchange that was in the last newsletter. I have no idea if they are legit or if the warnings are in bad faith but the reason that Szabo’s “trusted third parties are security holes” gets repeated frequently is because it is true. If you choose any cryptoasset that depends on custody of a third party, caveat emptor.
Origin now has editable listings and multiple item support
Nevada counties are storing birth and marriage certificates on Ethereum
Scout unveils its customizable token/protocol explorers for apps, live on Aragon and Livepeer
Veil prediction markets platform built on 0x and Augur launches Jan 15 on mainnet. Fantastic to see the app layer stack coming together. Not open to the USA because…federal government.
Gnosis on the problem of front running in dexes
Status releases desktop alpha, v0.9
Interviews, Podcasts, Videos, Talks
Joseph Lubin on Epicenter. Some good early Eth history here.
Curation Markets community call
Ryan Sean Adams on the case for Ether as money on POV Crypto
Nice Decrypt Media profile of Lane Rettig
Q&A with Mariano Conti, head of Maker Oracles
Andrew Keys on the American Banker podcast
Austin Griffith 2018 lessons learned talk at Ethereum Boulder
Starkware’s Eli Ben-Sasson and Alessandro Chiesa on Zero Knowledge
Nick Johnson talks ENS and ProgPoW on Into the Ether
Tokens / Business / Regulation
Paul Kohlhaas: bonding curve design parameters
Ryan Zurrer: Network keepers, v2
Zastrin to sell a tradeable NFT as a license to use its blockchain dev courses.
Sharespost says it did its first compliant security token trade of BCAP (Blockchain Capital). Link opens PDF
Actus Financial Protocol announces standard for tokenizing all financial instruments.
Missing DeFi piece: longer-term interest generating assets
Gemini’s rules for the revolution on working with regulators.
Blockchain Association proposes the Hinman Standard for cryptoassets
Blockchains LLC releases its 300 page Blockchain Through a Legal Lens
China released restrictive blockchain rules including censorship and KYC
Why Ether is Valuable
General
ETC got 51% attacked. Coinbase was first to announce it, though it appears the target was the gate.io exchange. Amusingly, the price hardly suffered. The amazing thing is that a widely known and relatively easily exploited attack vector like this didn’t happen during bull market when this attack could have been an order of magnitude more profitable.
Michael del Castillo tracks the supply chain of an entire dinner using blockchain products like Viant
Julien Thevenard argues Ethereum is on par or safer than Bitcoin in terms of proof of work.
Coindesk video interview of the creator of HODL. He isn’t at all convinced by Bitcoin’s new “store of value” meme. Very entertaining use of 8 minutes.
That very odd Bitcoin nonce pattern. Phil Daian says it is caused by AntMiners
Researchers brute force attack private keys of poorly implemented ECDSA nonce generation.
Dates of Note
Upcoming dates of note (new in bold):
Jan 14 - Mobi Grand Challenge hackathon ends
Jan 10-Feb7 - 0x and Coinlist virtual hackathon
Jan ~16 - Constantinople hard fork at block 7080000
Jan 24 - List of things for Aragon vote, including on funding original AragonOne team
Jan 25 - Graph Day (San Francisco)
Jan 29-30 - AraCon (Berlin)
Jan 31 - GörliCon (Berlin)
Feb 7-8 - Melonport’s M1 conf (Zug)
Feb 15-17 - ETHDenver hackathon (ETHGlobal)
Mar 4 - Ethereum Magicians (Paris)
Mar 5-7 - EthCC (Paris)
Mar 8-10 - ETHParis (ETHGlobal)
Mar 27 - Infura end of legacy key support (Jan 23 begins Project ID prioritization)
April 8-14 - Edcon hackathon and conference (Sydney)
Apr 19-21 - ETHCapetown (ETHGlobal)
May 10-11 - Ethereal (NYC)
If you appreciate this newsletter, thank ConsenSys
This newsletter is made possible by ConsenSys.

I own Week In Ethereum. Editorial control has always been 100% me.
If you're unhappy with editorial decisions or anything that I have written in this issue, feel free to tweet at me.
Housekeeping
Archive on the web if you’re linking to it: http://www.weekinethereum.com/post/181942366088/january-11-2018
Cent link for the night view: https://beta.cent.co/+81o82u
https link: Substack
Follow me on Twitter, because most of what is linked gets tweeted first: @evan_van_ness
If you’re wondering “why didn’t my post make it into Week in Ethereum?”
Did you get forwarded this newsletter? Sign up to receive the weekly email
1 note
·
View note
Text
Mini Project Retro: Building a Technical Documentation page with HTML & CSS
Following up on a previous post, I still have remaining freeCodeCamp HTML & CSS track projects. I decided to focus on the technical documentation page challenge. Like before, there were some user stories to guide it, an already-built example, and simple instructions to avoid using fancy libraries and frameworks.
The end result is here.
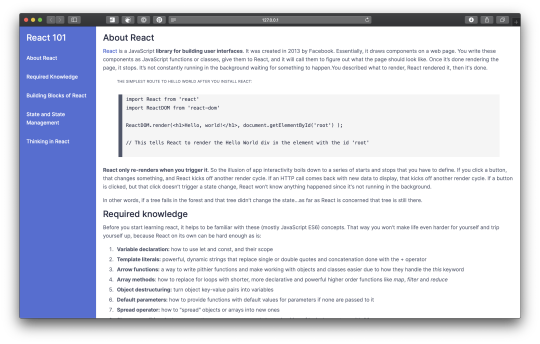
What I did
I created a ‘React 101′ documentation page, trying to add some useful text but keeping it short. I’d learned from previous experience that content generation is the most time-consuming part with these exercises. Sure, I could paste something from MDN like in their example, but I wanted something of my own.
I time boxed it to a 2 calendar days, which really meant around 8 hours of continuous work.
I researched in the form of asking my Twitter community what documentation sites they like, or if they know of good documentation generation tools.
I personally liked the Svelte and Stripe documentation for their layout, ease of reading and color schemes (I’m going through a purple or muted purple phase). I also enjoy documentation pages that come with a version history, which has more to do with their CMS and user experience than with the visual side of things, but it’s a nice touch.
The community really liked documentation sites from Stripe, Netlify, Shopify (Polaris) and Prisma. Prisma was new to me and a highlight for the ease with which you could transition between the same documentation page, but for a different database systems (e.g. PostgreSQL, MongoDB, MySQL) or programming language applicable to your situation. For documentation generation tools or CMS, Kirby, Antora, Docusaurus and ReadTheDocs stood out. A few other mentions were mkdocs (a static site generator that's geared towards building project documentation). What was more intriguing was that ReadTheDocs had no pictures on their site, which seems like a missed opportunity. Kirby is also quite versatile.
Lessons
Styling <pre> and <code> is a challenge, and there are few solutions out there (e.g. Prism)
Though the bulk of the challenge was designed to get you to wrestle with relative and absolute positioning, the other biggie I bumped into was styling code blocks without external help. It’s a non-trivial amount of effort to get code blocks to look presentable on a site, let alone nice. Not even Tumblr has a built-in way to display code.
First, many CSS aspects went into this alone: how to display the code block, appropriate monospace font families, making the code block editable, wrapping and breaking words, dealing with overflow, number of tab spaces, etc. Whew! I tried many permutations until I landed on something I was happy with.
Second, I learned that by using <pre> you get a line break before the text starts, and there’s no great CSS way to get rid of it. However, there’s a workaround to start the text on the same line as the <pre> tag.
Third, encoding symbols (<, >, &, etc) into HTML entities without special help means using a lot of < and > and such. I saw a workaround using a snippet of PHP but decided not to for this project.
Not to mention all the other user preferences, like having line numbers (using JavaScript) and more. A good best practice article dates back to 2013 but is still relevant today. Unsurprisingly, there are several external solutions but the most popular one is Prism, a lightweight and configurable syntax highlighter (not the same Prisma mentioned before). It’d seem that Stripe uses it, and everyone loves Stripe documentation.
Use <figure> and <figcaption> for ease of reading and accessibility
freeCodeCamp teaches this too; the <figure> element is primarily for diagrams and pictures but also works with <code>. It can optionally have a caption with <figcaption>.
Not only that, the accessibility can be improved by adding some ARIA attributes on <pre>: aria-labelledby to point to the <figcaption> (if there is one), and aria-describedby to point to the preceding text (if it describes the example).
Making code blocks editable gives users more control over the snippet
I learned from the best practice article mentioned before that editable code blocks gain extra navigation and selection controls, like being able to click inside the code and use Ctrl+A to select it all or use Shift+Arrow to make partial text-selections with the keyboard to name a couple.
Begin with the end in mind: mobile first, large devices later
This is a classic lesson that I carried over from other projects, though I omitted a clickable hamburger menu from this. I entertained a top-sticky, horizontally scrolling menu. But the more I looked into it, the more time this would have added and required more than HTML&CSS, which were the point of the exercise.
What I’d do differently
Add a hamburger menu toggle for mobile. I kept it simple and chose not to display the navbar on mobile since my page isn’t so long.
Add line numbers to the code blocks. This was brought up in a best practice article, but felt it was outside the scope of this project to add that much JavaScript. Or...
Use a tool like Prism to style code blocks. It seems like a no-brainer, but I wanted to see how far I could get without it.
Change the colors. I liked this combo but I’ll be the first to admit I’m not 100% sure how to mix things up in a more aesthetically pleasing way.
0 notes
Text
Developers Italia, Software Open source per la Pubblica Amministrazione
Vi siete mai chiesti se i software che vengono usati da enti pubblici e dalla pubblica amministrazione sono open source?

Tastiera con tasto blu e scritto OPEN DATA rispettivamente in bianco e giallo. Fonte: Wikimedia Commons, foto di Agenzia per I’talia Digitale - Presidenza del Consiglio dei Ministri [CC BY 3.0]
Da qualche anno è nato in collaborazione tra AgID (Agenzia per l'Italia Digitale) e il Team per la Trasformazione Digitale del Governo il progetto Developers Italia, una community per gli sviluppatori online con l'obbiettivo di contribuire al miglioramento dei servizi pubblici digitali italiani sviluppando software open source
Fonte: https://developers.italia.it/it/note-legali/
Il sito https://developers.italia.it nasce per mettere a disposizione di tutti il codice sorgente dei software che vengono giornalmente usati dalla Pubblica Amministrazione. Avendo il codice open source, sviluppare i progetti digitali della pubblica amministrazione ha molti piu vantaggi.
Riutilizzare i componenti comuni e i software open source rilasciati da altri enti della Pubblica Amministrazione ha 3 principali vantaggi:
Si risparmia tempo e risorse economiche;
Si evita la necessità di duplicare il lavoro;
Si mettono insieme gli sforzi per costruire un software maturo e soprattutto sicuro.
Come Funziona L’organizzazione?
Un primo importante mattone per attivare questo processo è il Piano Triennale, ovvero un documento strategico che intende guidare e supportare tutta la Pubblica Amministrazione in un processo organico e coerente di trasformazione digitale. Il Piano contiene un cronoprogramma con decine di attività che le Amministrazioni dovranno completare nel prossimo triennio.

Screenshot del sito ufficiale rappresentante cos’è il Piano Trienale.
I progetti principali della piattaforma sono:
SPID: (progetto che già esisteva e che il team ha accelerato, esso è il sistema di riconoscimento online dei cittadini, già utilizzato da oltre 1.5 milioni di persone, e permette di accedere a tutti i siti della Pubblica Amministrazione;
ANPR: l’Anagrafe Nazionale Popolazione Residente;
dati.gov.it: i dati aperti della pubblica amministrazione.
Fonte: https://www.agendadigitale.eu/infrastrutture/team-digitale-cosi-stiamo-creando-il-sistema-operativo-del-paese/
Chi contribuisce a migliorare i codici? Dove vengono pubblicati i codici?
La community è composta da tecnici della Pubblica Amministrazione o dei fornitori, ma anche da cittadini e studenti, che collaborano sugli specifici progetti e comunicano attraverso gli strumenti messi a disposizione:
uno spazio su GitHub per ospitare i codici sorgente e librerie open-source pronte all’uso e all’integrazione;
un’area basata su ReadTheDocs per riscrivere documentazioni strutturate e indicizzabili, pensata e scritta per la fruizione da tecnico a tecnico.

Logo GitHub Social Coding [Public domain], attraverso Wikimedia Commons.
Come gia scritto anche i cittadini possono collaborare, infatti la possibilità di accedere al codice sorgente su GitHub offre maggiore trasparenza e permette a tutti di collaborare per la correzione di problemi e per il miglioramento del software open source.
Fonte: https://teamdigitale.governo.it/it/projects/developers.htm
Perciò Developers Italia costituisce un ulteriore passo in avanti all’interno del percorso di digitalizzazione ed innovazione del Paese.
Post by Michele Cerra
#rivoluzdigitale#rivoluzione#digitale#rivoluzionedigitale#developers#italia#GitHub#spid#anpr#pa#pubblica#amministrazione#comuni#open#source#AgID#software
0 notes
Photo

"[P] pyts: A Python package for time series transformation and classification"- Detail: Hello everyone,Today I would like to share with you a project that I started almost 2 years ago. It will be a long post, so here is a TDLR.TDLR: * pyts (GitHub, PyPI, ReadTheDocs): a Python package for time series transformation and classification. * It aims to make time series classification easily accessible by providing preprocessing and utility tools, and implementations of state-of-the-art algorithms. * pyts-repro: Comparaison with the results published in the literature.MotivationsAlmost two years ago, I was an intern at a company and a colleague was working on a time series classification task. It was my end-of-studies internship and I had been studying machine learning for one year only (my background studies were more focused on statistics). I realized that I had no knowledge about machine learning for time series besides SARIMA and all the models with fewer letters. I also had limited knowledge about computer science. I did some literature search about time series classification and discovered a lot of things that I had never heard of before. Thus, I decided to start a project with the following motivations: * Create a Python package through a GitHub repository (because I had no idea how both worked); * Look at the source code of Python packages that I used regurlaly (numpy, scikit-learn) to gain knowledge; * Implement algorithms about time series classification.Development and what I learntBefore implementing anything, I had to : * Learn how to package a Python project, * Do a more advanced literature search about time series classification, * Think about the structure of the package.When I had an overall first idea of what I wanted to do, I could start coding. During this process, I discovered a lot of tools that were already available and that I had re-implemented myself less efficiently (numpy.digitize, sklearn.utils.check_array, numpy.put, and numpy.lib.stride_tricks.as_strided come to my mind). The following process could pretty much sum up the history of this project: 1. Try to implement a new algorithm; 2. In doing so, find tools that do what I wanted more efficiently, not necessarly related to the new algorithm; 3. Implement the algorithm and edit the relevant code with the newly discovered tools.Two major discoveries had a huge impact on the development of this project: scikit-learn-contrib/project-template and Numba. The former made me discover a lot of concepts that I did not know about (tests, code coverage, continuous integration, documentation) and provides ready-to-use scripts. The latter made optimizing code much easier as I was very confused about Cython and building wheels, and deciced not to use Cython. I also discovered the notion of proper code (pep8, pep257, etc.), and semantic versioning recently. This might be obvious for most people, but I did not know any of these concepts at the time.What this package providesThe current version of pyts consists of the following modules:approximation: This module provides implementations of algorithms that approximate time series. Implemented algorithms are Piecewise Aggregate Approximation, Symbolic Aggregate approXimation, Discrete Fourier Transform, Multiple Coefficient Binning and Symbolic Fourier Approximation.bag_of_words: This module consists of a class BagOfWords that transforms time series into bags of words. This approach is quite common in time series classification.classification: This module provides implementations of algorithms that can classify time series. Implemented algorithms are KNeighborsClassifier, SAXVSM and BOSSVS.decomposition: This module provides implementations of algorithms that decompose a time series into several time series. The only implemented algorithm is Singular Spectrum Analysis.image: This module provides implementations of algorithms that transform time series into images. Implemented algorithms are Recurrence Plot, Gramian Angular Field and Markov Transition Field.metrics: This module provides implementations of metrics that are specific to time series. Implemented metrics are Dynamic Time Warping with several variants and the BOSS metric.preprocessing: This module provides most of the scikit-learn preprocessing tools but applied sample-wise (i.e. to each time series independently) instead of feature-wise, as well as an imputer of missing values using interpolation. More information is available at the pyts.preprocessing API documentation.transformation: This module provides implementations of algorithms that transform a data set of time series with shape (n_samples, n_timestamps) into a data set with shape (n_samples, n_features). Implemented algorithms are BOSS and WEASEL.utils: a simple module with utility functions.I also wanted to have an idea about how my implementations perform compared to the performance reported in the papers and on the Time Series Classification Repository. The point is to see if my implementations are reliable or not. To do so, I created a GitHub repository where I make these comparisons on the smallest datasets. I think that my implementation of WEASEL might be under-performing, but for the other implementations reported the performance is comparable. There are sometimes intentional differences between my implementation and the description of the algorithm in the paper, which might explain the differences in performance.Future workThe main reason of this post is to get feedback. I have been pretty much working on my own on this project, doing what I felt like doing. However, as a PhD student, I know how important it is to get feedback on your work. So, if you have any feedback on how I could improve the package, it would be really appreciated. Nonetheless, I still have ideas of future work: * Add a dataset module: I think that it is an important missing tool of the package. Right now I create a dumb toy dataset in all the examples in the documentation. Adding a couple of datasets in the package directly (I would obviously need to contact authors to get permission to do so) like the iris dataset in scikit-learn would make the examples more relevant in my opinion. Adding a function to download datasets from the Time Series Classification Repository (similarly to sklearn.datasets.fetch_openml or sklearn.datasets.fetch_mldata) would be quite useful too. Being able to generate a toy dataset like sklearn.datasets.make_classification would be a nice addition. If you have any idea about generating a classification dataset for time series, with any number of classes and any number of timestamps, feel free to comment, I would be really interested. Right now I only know the Cylinder-Bell-Funnel dataset, but it is quite limiting (128 timestamps and 3 classes). * Add a multivariate module. Currently the package provides no tools to deal with multivariate time series. Like binary classifiers that need extending for multiclass classification, adding a voting classifier (with a classifier for each feature of the multivariate time series) would be useful, as well as specific algorithms for multivariate time series. * Make the package available on Anacloud Cloud through the conda-forge channel. conda seems to be quite popular thanks to the utilities it provides and making the package installable with conda could be a plus. * Update the required versions of the dependencies: Currently the required versions of the dependencies are the versions that I use on my computer. I'm quite confident that older versions for some packages could work, but I have no idea how to determine them (I exclude doing a backward gridsearch until continuous integreation fails). Are there any tools that can try to guess the minimum versions of the packages, by looking at what functions are used from each package for instance? * Implement more algorithms: Time Series Bag-of-Features, shapelet-based algorithms, etc. A lot of algorithms are not available in the package currently. Adding more metrics specific to time series would also be great.AcknowledgementsLooking back at the history of this project, I realize how much I learnt thanks to the scientific Python community: there are so many open source well-documented tools that are made available, it is pretty amazing.I would also like to thank the authors of papers that I contacted in order to get more information about the algorithms that they presented. I always received quick, kind answers. Special thanks to Patrick Schäfer, who received a lot of emails from me and always replied.I would like to thank all the people involved in the Time Series Classification Repository. It is an awesome tool with datasets freely available and reported results for each algorithm.Finally, I would like to thank every contributor to the project, as well as people helping making this package better through opening issues or sending me emails.ConclusionWorking on this project has been a blast. Sometimes learning takes a lot of time, and I experienced it quite often, but I think that it is worth it. I work on this project on my spare time, so I cannot spend as much time as much as I would like, but I think that it gets slowly but steadily better. There are still a lot of things that are a bit confusing to me (all the configuration files for CI and documentation, managing a git repository with several branches and several contributors), and seeing room for improvement is also an exciting part of this experience.There was a post about machine learning on time series on this subreddit several months ago. If you were interested in what was discussed in this post (and more specially in the top comment), you might be interested in pyts.Thank you very much for reaching the end of this long post. If you have some time to give me any feedback, it would mean a lot to me. Have a very nice day!. Caption by jfaouzi. Posted By: www.eurekaking.com
0 notes
Text
How to Export Jupyter Notebooks Into Other Formats
#ICYDK: When working with Jupyter Notebook, you will find yourself needing to distribute your Notebook as something other than a Notebook file. The most likely reason is that you want to share the content of your Notebook to non-technical users that don't want to install Python or the other dependencies necessary to use your Notebook. The most popular solution for exporting your Notebook into other formats is the built-in tool. You can use nbconvert to export to the following formats: * HTML (-to html) * LaTeX (-to latex) * PDF (-to pdf) * Reveal JS (-to slides) * Markdown (md) (-to markdown) * ReStructured Text (rst) (-to rst) * executable script (-to script) The nbconvert tool uses Jinja templates to convert your Notebook files (.ipynb) to these other static formats. Jinja is a template engine for Python. The nbconvert tool depends on Pandoc and TeX for some of the conversions that it does. You may need to install these separately on your machine. This is documented on ReadTheDocs. https://goo.gl/2WrPk3
0 notes
Text
Zcash [ZEC] releases details on its weekly progress
On July 20th, Zcash released its weekly update report on its official forum. Currently, the team is on a 3-week sprint that began last week. In its blog, Zcash gave updates on its various teams and their roles in the system, such as the Zcashd team, Ecosystem team, Documentation team and more.
Zcashd teams’ focus points on the Zcashd Client:
Support for the Shielded Hierarchical Deterministic Wallets [HD Wallets] aka ZIP32 [ZIP PR 157].
API for Sapling proof generation: Sapling is an upcoming network upgrade for Zcash, which will release in October 2018. It will add more efficiency to Zcash’s shield transactions.
Remote Procedure Call [RPC] support for Sapling Keys: RPC is a protocol used by a program to request another program on a different computer of the network to perform a service without the necessary understanding of the network.
Support for Sapling note.
A new version to Sapling’s specifications: It carries complete proofs required to back ‘Pedersen hash optimizations’.
Updates on Development Infrastructure Team, Zcash
This team provides for all the requirements of developers, in terms of tools and infrastructure for efficient collaboration, design, implementation, reviewing, testing and shipping quality projects.
Its other roles include:
Resolving continued breakage by using MacOS
Creating a CI worker for Windows
Examine the current infrastructure of CI and offer potential upgrades
Fixing the CentOS 7 Builder
Zcash’s ‘meta’ update on the team
The two teams for protocol and Zcashd, have been combined. Apart from the unknown fixes yet to be fetched from the audit result, a large part of the engineering around consensus level is completed. This leaves wallet-level support for Sapling as the top priority.
A new team has also been added to attend to the reference mobile wallet project. This has also been included in the proposal 7 of the recent roadmap.
Another enterprise team has been added to the system. This team will be looking into projects such as Quorum collaboration from last year. Zcash has also conveyed in its official blog that this section will not possess many future updates as the collaborations are carried out under Non-Disclosure Agreement [NDA] until the announcement of a project.
Ecosystem Team
This is a team that will be looking after anything outside the association with Zcashd or the protocol. It will also provide support for tools and services for third-parties. Most importantly, this team is responsible for handling the ecosystem projects built by Zcash Co. Therefore, tracking in this section is restricted to safeguard confidential information on third-parties.
Some of its sub-roles are:
Establishing a connection with third-parties and provide for any support that might be required.
Working on the outreach and education factor of the Sapling project for third-parties
Lastly, Zcash included updates on its Documentation Team.
This team is also directly associated with Zcash and Zcashd and helps enhance the overall accessibility of the systems.
Its sub-roles include:
Investigating the ‘ReadTheDocs’ translation process to formalize it.
Testing GitLab for repository hosting
Contributing to the feature-based wallet selection guide
Migrating the documents from the website to RTD
The post Zcash [ZEC] releases details on its weekly progress appeared first on AMBCrypto.
Zcash [ZEC] releases details on its weekly progress published first on https://medium.com/@smartoptions
0 notes
Link
via Google Alert - celery readthedocs/common https://ift.tt/3lOQuit
0 notes
Text
Cloudsplaining - AWS IAM Security Tool That Identifies Violations
Cloudsplaining - AWS IAM Security Tool That Identifies Violations #assessment #aws #AWSIAM #Cloudsplaining
[sc name=”ad_1″]
Cloudsplaining is an AWS IAM Security Assessment tool that identifies violations of least privilege and generates a risk-prioritized HTML report.
Example report
Documentation
For full documentation, please visit the project on ReadTheDocs.
Installation
Cheat sheet
Example report
Overview
Cloudsplaining identifies violations of least privilege in AWS IAM policies and generates a…
View On WordPress
#assessment#aws#AWS IAM#Cloudsplaining#command line#Exfiltration#Generates#HTML Report#IAM#Identifies#Privilege#Privilege Escalation#python#Remote Code Execution#report#RiskPrioritized#scan#security#security assessment#Security Assessment Tool#tool#Violations
0 notes
Last Seen Blogs

juandavidms
Little Monkey

carrieleeblg
Отдушина графоманки

odnaht
🌹

healthfitnesszen
Untitled

slutforstyles
Jay loves H