#Data Labeling
Text
The Power of AI and Human Collaboration in Media Content Analysis

In today’s world binge watching has become a way of life not just for Gen-Z but also for many baby boomers. Viewers are watching more content than ever. In particular, Over-The-Top (OTT) and Video-On-Demand (VOD) platforms provide a rich selection of content choices anytime, anywhere, and on any screen. With proliferating content volumes, media companies are facing challenges in preparing and managing their content. This is crucial to provide a high-quality viewing experience and better monetizing content.
Some of the use cases involved are,
Finding opening of credits, Intro start, Intro end, recap start, recap end and other video segments
Choosing the right spots to insert advertisements to ensure logical pause for users
Creating automated personalized trailers by getting interesting themes from videos
Identify audio and video synchronization issues
While these approaches were traditionally handled by large teams of trained human workforces, many AI based approaches have evolved such as Amazon Rekognition’s video segmentation API. AI models are getting better at addressing above mentioned use cases, but they are typically pre-trained on a different type of content and may not be accurate for your content library. So, what if we use AI enabled human in the loop approach to reduce cost and improve accuracy of video segmentation tasks.
In our approach, the AI based APIs can provide weaker labels to detect video segments and send for review to be trained human reviewers for creating picture perfect segments. The approach tremendously improves your media content understanding and helps generate ground truth to fine-tune AI models. Below is workflow of end-2-end solution,
Raw media content is uploaded to Amazon S3 cloud storage. The content may need to be preprocessed or transcoded to make it suitable for streaming platform (e.g convert to .mp4, upsample or downsample)
AWS Elemental MediaConvert transcodes file-based content into live stream assets quickly and reliably. Convert content libraries of any size for broadcast and streaming. Media files are transcoded to .mp4 format
Amazon Rekognition Video provides an API that identifies useful segments of video, such as black frames and end credits.
Objectways has developed a Video segmentation annotator custom workflow with SageMaker Ground Truth labeling service that can ingest labels from Amazon Rekognition. Optionally, you can skip step#3 if you want to create your own labels for training custom ML model or applying directly to your content.
The content may have privacy and digitial rights management requirements and protection. The Objectway’s Video Segmentaton tool also supports Digital Rights Management provider integration to ensure only authorized analyst can look at the content. Moreover, the content analysts operate out of SOC2 TYPE2 compliant facilities where no downloads or screen capture are allowed.
The media analysts at Objectways’ are experts in content understanding and video segmentation labeling for a variety of use cases. Depending on your accuracy requirements, each video can be reviewed or annotated by two independent analysts and segment time codes difference thresholds are used for weeding out human bias (e.g., out of consensus if time code differs by 5 milliseconds). The out of consensus labels can be adjudicated by senior quality analyst to provide higher quality guarantees.
The Objectways Media analyst team provides throughput and quality gurantees and continues to deliver daily throughtput depending on your business needs. The segmented content labels are then saved to Amazon S3 as JSON manifest format and can be directly ingested into your Media streaming platform.
Conclusion
Artificial intelligence (AI) has become ubiquitous in Media and Entertainment to improve content understanding to increase user engagement and also drive ad revenue. The AI enabled Human in the loop approach outlined is best of breed solution to reduce the human cost and provide highest quality. The approach can be also extended to other use cases such as content moderation, ad placement and personalized trailer generation.
Contact [email protected] for more information.
2 notes
·
View notes
Text
the fact that shakespeare was a playwright is sometimes so funny to me. just the concept of the "greatest writer of the English language" being a random 450-year-old entertainer, a 16th cent pop cultural sensation (thanks in large part to puns & dirty jokes & verbiage & a long-running appeal to commoners). and his work was made to be watched not read, but in the classroom teachers just hand us his scripts and say "that's literature"
just...imagine it's 2450 A.D. and English Lit students are regularly going into 100k debt writing postdoc theses on The Simpsons screenplays. the original animation hasn't even been preserved, it's literally just scripts and the occasional SDH subtitles.txt. they've been republished more times than the Bible
#due to the Great Data Decay academics write viciously argumentative articles on which episodes aired in what order#at conferences professors have known to engage in physically violent altercations whilst debating the air date number of household viewers#90% of the couch gags have been lost and there is a billion dollar trade in counterfeit “lost copies”#serious note: i'll be honest i always assumed it was english imperialism that made shakespeare so inescapable in the 19th/20th cent#like his writing should have become obscure at the same level of his contemporaries#but british imperialists needed an ENGLISH LANGUAGE (and BRITISH) writer to venerate#and shakespeare wrote so many damn things that there was a humongous body of work just sitting there waiting to be culturally exploited...#i know it didn't happen like this but i imagine a English Parliament House Committee Member For The Education Of The Masses or something#cartoonishly stumbling over a dusty cobwebbed crate labelled the Complete Works of Shakespeare#and going 'Eureka! this shall make excellent propoganda for fabricating a national identity in a time of great social unrest.#it will be a cornerstone of our elitist educational institutions for centuries to come! long live our decaying empire!'#'what good fortune that this used to be accessible and entertaining to mainstream illiterate audience members...#..but now we can strip that away and make it a difficult & alienating foundation of a Classical Education! just like the latin language :)'#anyway maybe there's no such thing as the 'greatest writer of x language' in ANY language?#maybe there are just different styles and yes levels of expertise and skill but also a high degree of subjectivity#and variance in the way that we as individuals and members of different cultures/time periods experience any work of media#and that's okay! and should be acknowledged!!! and allow us to give ourselves permission to broaden our horizons#and explore the stories of marginalized/underappreciated creators#instead of worshiping the List of Top 10 Best (aka Most Famous) Whatevers Of All Time/A Certain Time Period#anyways things are famous for a reason and that reason has little to do with innate “value”#and much more to do with how it plays into the interests of powerful institutions motivated to influence our shared cultural narratives#so i'm not saying 'stop teaching shakespeare'. but like...maybe classrooms should stop using it as busy work that (by accident or designs)#happens to alienate a large number of students who could otherwise be engaging critically with works that feel more relevant to their world#(by merit of not being 4 centuries old or lacking necessary historical context or requiring untaught translation skills)#and yeah...MAYBE our educational institutions could spend less time/money on shakespeare critical analysis and more on...#...any of thousands of underfunded areas of literary research i literally (pun!) don't know where to begin#oh and p.s. the modern publishing world is in shambles and it would be neat if schoolwork could include modern works?#beautiful complicated socially relevant works of literature are published every year. it's not just the 'classics' that have value#and actually modern publications are probably an easier way for students to learn the basics. since lesson plans don't have to include the#important historical/cultural context many teens need for 20+ year old media (which is older than their entire lived experience fyi)
23K notes
·
View notes
Link
Status update by Maruful95
Marufu Islam is commended here. informed about data labelling for startups as well as businesses of all sizes. capable of using several tools, such as Supervisely, Super Annotate, Labelbox, CVAT, and others, to label a wide range of picture collections. capable of working in the COCO, XML, JSON, and CSV formats. Ready to incorporate into your projects?
I'm Md. Maruful Islam is a proficient Bangladeshi data annotator trainer. At the moment, I consider it an honour to be employed by Acme AI, the leader in the data annotation industry. Throughout my career, I've gotten better at using a range of annotation tools, including SuperAnnotate, Kili, Cvat, Tasuki, FastLabel, and others. I am a well-respected professional in the field, having produced consistently excellent annotations. My certifications for GDPR, ISO 27001, and ISO 9001 further guarantee that privacy and data security regulations are adhered to. I sincerely hope you will give my application some thought. As a data annotator, I'd like to know more about this project and provide recommendations based on my knowledge.
Fiveer-https://www.fiverr.com/s/vqgwlL
Upwork-https://www.upwork.com/services/product/design-ai-segmentation-labeling-bounding-box-for-precision-1746946743155208192?ref=project_share
0 notes
Text
Mastering Data Collection in Machine Learning: A Comprehensive Guide -
Artificial intelligence, mastering the art of data collection is paramount to unlocking the full potential of machine learning algorithms. By adopting systematic methods, overcoming challenges, and adopting best practices, organizations can harness the power of data to drive innovation, gain competitive advantage, and provide transformative solutions across various domains.
Through careful data collection, Globose Technology Solutions remains at the forefront of AI innovation, enabling clients to harness the power of data-driven insights for sustainable growth and success.
#Data Collection#Machine Learning#Artificial Intelligence#Data Quality#Data Privacy#Web Scraping#Sensor Data Acquisition#Data Labeling#Bias in Data#Data Analysis#Public Datasets#Data-driven Decision Making#Data Mining#Data Visualization#data collection company#dataset
1 note
·
View note
Text
Streamline Computer Vision Workflows with Hugging Face Transformers and FiftyOne
0 notes
Text
How Does Data Annotation Assure Safety in Autonomous Vehicles?
To contrast a human-driven car with one operated by a computer is to contrast viewpoints. Over six million car crashes occur each year, according to the US National Highway Traffic Safety Administration. These crashes claim the lives of about 36,000 Americans, while another 2.5 million are treated in hospital emergency departments. Even more startling are the figures on a worldwide scale.

One could wonder if these numbers would drop significantly if AVs were to become the norm. Thus, data annotation is contributing significantly to the increased safety and convenience of Autonomous Vehicles. To enable the car to make safe judgments and navigate, its machine-learning algorithms need to be trained on accurate and well-annotated data.
Here are some important features of data annotation for autonomous vehicles to ensure safety:
Semantic Segmentation: Annotating lanes, pedestrians, cars, and traffic signs, as well as their borders, in photos or sensor data, is known as semantic segmentation. The car needs accurate segmentation to comprehend its environment.
Object Detection: It is the process of locating and classifying items, such as vehicles, bicycles, pedestrians, and obstructions, in pictures or sensor data.
Lane Marking Annotation: Road boundaries and lane lines can be annotated to assist a vehicle in staying in its lane and navigating safely.
Depth Estimation: Giving the vehicle depth data to assist it in gauging how far away objects are in its path. This is essential for preventing collisions.
Path Planning: Annotating potential routes or trajectories for the car to follow while accounting for safety concerns and traffic laws is known as path planning.
Traffic Sign Recognition: Marking signs, signals, and their interpretations to make sure the car abides by the law.
Behaviour Prediction: By providing annotations for the expected actions of other drivers (e.g., determining if a pedestrian will cross the street), the car can make more educated decisions.
Map and Localization Data: By adding annotations to high-definition maps and localization data, the car will be able to navigate and position itself more precisely.
Weather and Lighting Conditions: Data collected in a variety of weather and lighting circumstances (such as rain, snow, fog, and darkness) should be annotated to aid the vehicle’s learning process.
Anomaly Detection: Noting unusual circumstances or possible dangers, like roadblocks, collisions, or sudden pedestrian movements.
Diverse Scenarios: To train the autonomous car for various contexts, make sure the dataset includes a wide range of driving scenarios, such as suburban, urban, and highway driving.
Sensor Fusion: Adding annotations to data from several sensors, such as cameras, radar, LiDAR, and ultrasonics, to assist the car in combining information from several sources and arriving at precise conclusions.
Continual Data Updating: Adding annotations to the data regularly to reflect shifting traffic patterns, construction zones, and road conditions.
Quality Assurance: Applying quality control techniques, such as human annotation verification and the use of quality metrics, to guarantee precise and consistent annotations.
Machine Learning Feedback Loop: Creating a feedback loop based on real-world data and user interactions to continuously enhance the vehicle’s performance.
Ethical Considerations: Make sure that privacy laws and ethical issues, like anonymizing sensitive material, are taken into account during the data annotation process.
Conclusion:
An important but frequently disregarded component in the development of autonomous vehicles is data annotation. Self-driving cars would remain an unattainable dream if it weren’t for the diligent efforts of data annotators. Data Labeler provides extensive support with annotating data for several kinds of AI models. For any further queries, you can visit our website. Alternatively, we are reachable at [email protected].
0 notes
Text
Top 7 Data Labeling Challenges and Their Solution
Addressing data labeling challenges is crucial for Machine Learning success. This content explores the top seven issues faced in data labeling and provides effective solutions. From ambiguous labels to scalability concerns, discover insights to enhance the accuracy and efficiency of your labeled datasets, fostering better AI model training.
Read the article:…

View On WordPress
#data annotation#data annotation companies#data annotation company#data annotation for AI/ML#Data Annotation in Machine Learning#data labeling
0 notes
Text
Get Quality Data Labeling and Annotation Services to Accelerate Your AI/ML Model Implementation
Accurate data annotation and labeling play a crucial role in numerous applications spanning various industries. Whether it's in healthcare, retail, transcribing spoken words from video conferences, enhancing transportation systems, and countless other scenarios, the process of annotating and labeling data is essential for bringing AI and ML algorithms to fruition.
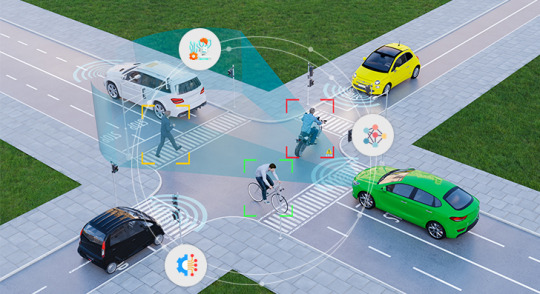
0 notes
Text

Looking to enhance your data for unparalleled insights? Look no further! Suntec AI offers top-notch data labeling services, including sentiment analysis and named entity recognition. Unleash the potential of your data today!
Visit https://buff.ly/3ZxzilS for more info!
#DataLabelingServices#DataLabeling#DataInsights
0 notes
Text
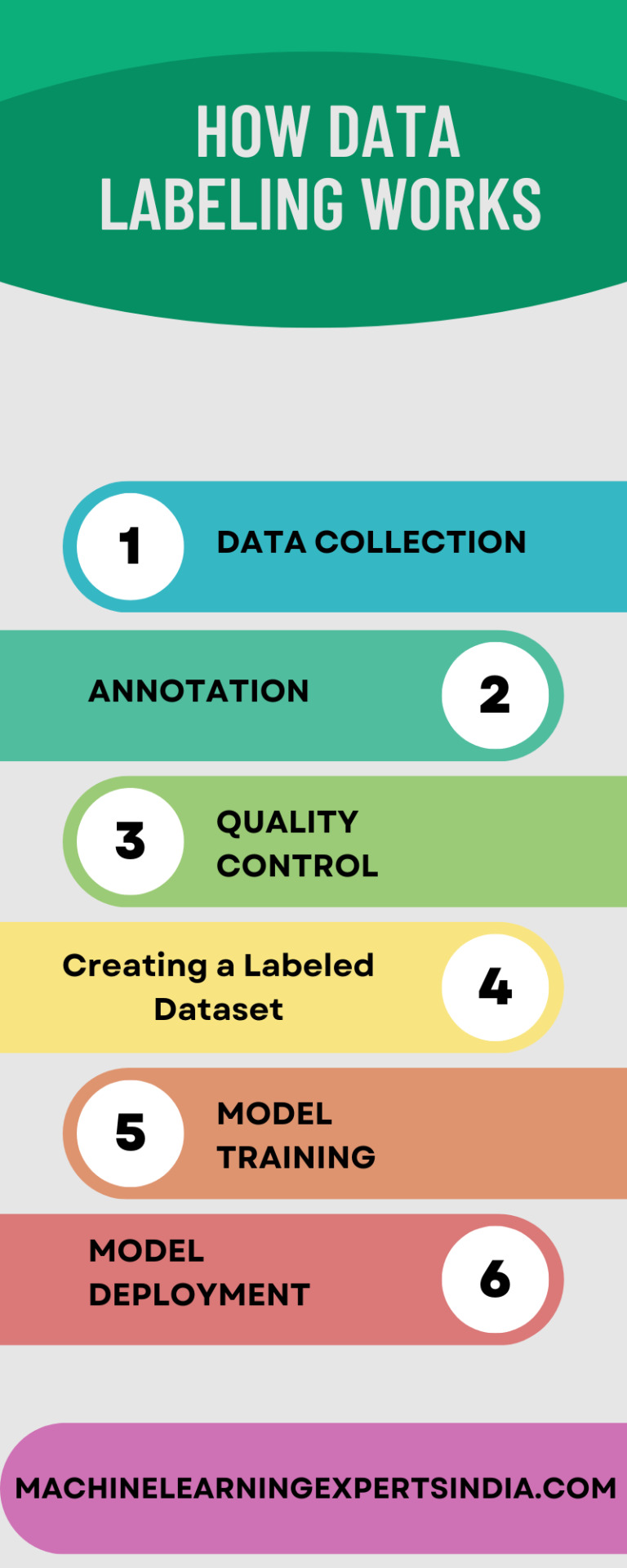
Data labeling involves a series of steps to convert unannotated raw data into annotated data that may be used for model training.
0 notes
Text
Guideline Adherence for Accurate Medical Data Labeling

The healthcare industry has witnessed the remarkable growth of artificial intelligence (AI), which has found diverse applications. As technology advances, AI’s potential in healthcare continues to expand. Nevertheless, certain limitations currently hinder the seamless integration of AI into existing healthcare systems.
AI is used in healthcare datasets to analyze data, provide clinical decision support, detect diseases, personalize treatment, monitor health, and aid in drug discovery. It enhances patient care, improves outcomes, and drives advancements in the healthcare industry. Many AI services such as Amazon Comprehend Medical, Google Cloud Healthcare API, John Snow Labs provide pre-built models. Due to the variety of medical data and requirements for accuracy human in the loop techniques are important to safeguard accuracy. However, the success of AI and ML models largely depends on the quality of the data they are trained on, necessitating reliable and accurate data labelling services.
Challenges in applying AI in Healthcare
Extensive testing of AI is necessary to prevent diagnostic errors, which account for a significant portion of medical errors and result in numerous deaths each year. While AI shows promise for accurate diagnostics, concerns remain regarding potential mistakes. Ensuring representative training data and effective model generalization are crucial for successful AI integration in healthcare.
In the healthcare sector, ensuring the privacy and security of patient data is paramount, as it not only fosters trust between healthcare providers and patients, but also complies with stringent regulatory standards such as HIPAA, promoting ethical, responsible data handling practices.
Lack of High-Quality Labeled datasets
Achieving a high quality labeled medical dataset poses several challenges, including:
Medical Labeling Skills: -Properly labeling medical data requires specialized domain knowledge and expertise. Medical professionals or trained annotators with a deep understanding of medical terminology and concepts are necessary to ensure accurate and meaningful annotations.
Managing Labeling Quality: -Maintaining high-quality labeling is crucial for reliable and trustworthy datasets. Ensuring consistency, accuracy, and minimizing annotation errors is challenging, as medical data can be complex and subject to interpretation. Robust quality control measures, including double-checking annotations and inter-annotator agreement, are necessary to mitigate labeling inconsistencies.
Managing the Cost of Labeling: -Labeling medical datasets can be a resource-intensive process, both in terms of time and cost. Acquiring sufficient labeled data may require significant financial investment, especially when specialized expertise is involved. Efficient labeling workflows, leveraging automation when feasible, can help manage throughput and reduce costs without compromising data quality.
Data Privacy and Security: -Safeguarding patient privacy and ensuring secure handling of sensitive medical data is crucial when collecting and labeling datasets.
Data Diversity and Representativeness: -Ensuring that the dataset captures the diversity of medical conditions, demographics, and healthcare settings is essential for building robust and unbiased AI models.
Best practices to manage medical labeling projects
Addressing these challenges requires a combination of domain expertise, quality control measures, and optimizing labeling processes to strike a balance between accuracy, cost-effectiveness, and dataset scale.
At Objectways we follow the Best Practices in medical labeling which include
Adherence to Guidelines: -Familiarize labeling teams with clear and comprehensive guidelines specific to the medical domain. Thoroughly understanding the guidelines ensures consistent and accurate labeling.
Conducting KPT (Knowledge, Process, Test): -Provide comprehensive training to labeling teams on medical concepts, terminology, and labeling procedures. Regular knowledge assessments and testing help evaluate proficiency of labeling teams and ensure continuous improvement.
Robust Team Structure: -We have established a structured team comprising labeling personnel, spot Quality Assurance (QA) reviewers, and dedicated QA professionals. This structure promotes accountability, efficient workflow, and consistent quality.
Quality Metrics: -We have implemented appropriate quality metrics such as precision, recall, and F1 score to assess labeling accuracy. We regularly monitor and track these metrics to identify areas for improvement and maintain high-quality standards.
Continuous Feedback Loop: -We have established a feedback mechanism where labeling teams receive regular feedback on their performance. This helps address any inconsistencies, clarify guidelines, and improve overall labeling accuracy.
Quality Control and Spot QA: - By implementing robust quality control measures, including periodic spot QA reviews by experienced reviewers, helps identify and rectify any labeling errors, ensures adherence to guidelines, and maintains high labeling quality.
Data Security and Privacy: - To validate our commitment to security and privacy controls, we have obtained the following formal certifications SOC2 Type2, ISO 27001, HIPAA, and GDPR. These certifications affirm our dedication to safeguarding customer data. Our privacy and security programs continue to expand, adhering to Privacy by Design principles and incorporating industry standards and customer requirements from various sectors.
Summary
At Objectways we have a team of certified annotators, including medical professionals such as nurses, doctors, and medical coders. Our experience includes working with top Cloud Medical AI providers, Healthcare providers and Insurance companies, utilizing advanced NLP techniques to create top-notch training sets and conduct human reviews of pre-labels across a wide variety of document formats and ontologies, such as call transcripts, patient notes, and ICD documents. Our DICOM data labeling services for computer vision cover precise annotation of medical images, including CT scans, MRIs, and X-rays and expert domain knowledge in radiology to ensure the accuracy and quality of labeled data.
In summary, the effectiveness of AI and ML models hinges significantly on the calibre of the data used for training, underscoring the need for dependable and precise data labeling services. Please contact [email protected] to enhance your AI Model Performance
#Objectways#Artificial Intelligence#Machine Learning#Data Science#Data Labeling#Data Annotation#Ai in Healthcare#Artificial Intelligence in Healthcare#Healthcare#Medical Labeling
0 notes
Text

Data labeling in machine learning involves the process of assigning relevant tags or annotations to a dataset, which helps the algorithm to learn and make accurate predictions.
Learn more
0 notes
Text

Expert Data Annotator Machine Learning
I'm Md. Maruful Islam is a proficient Bangladeshi data annotator trainer. At the moment, I consider it an honour to be employed by Acme AI, the leader in the data annotation industry. Throughout my career, I've gotten better at using a range of annotation tools, including SuperAnnotate, Kili, Cvat, Tasuki, FastLabel, and others.
I am a well-respected professional in the field, having produced consistently excellent annotations. My certifications for GDPR, ISO 27001, and ISO 9001 further guarantee that privacy and data security regulations are adhered to.
I sincerely hope you will give my application some thought. As a data annotator, I'd like to know more about this project and provide recommendations based on my knowledge.
Fiveer-https://www.fiverr.com/s/vqgwlL
Upwork-https://www.upwork.com/services/product/design-ai-segmentation-labeling-bounding-box-for-precision-1746946743155208192?ref=project_share
#data annotation#image annotation services#ai data annotator#artificial intelligence#annotation#ai#annotations#ai image#video annotation#machinelearning#data labeling
0 notes
Link
#artificial systems#Generative AI#Data Preprocessing#Data Labeling#Model Training#Model Evaluation#Model Refinement#Model Deployment#AI model#Data collection#Successful AI Model
0 notes
Photo

Read article visit Link : https://www.datalabeler.com/benefits-of-using-artificial-intelligence-and-machine-learning/
0 notes
Last Seen Blogs


officialjeremyfragrance
notes of stupidity

sereniprise
i'm in space

todfanfic
Tales Of Demons fanfictions

raquellaux-blog
Raquel Lau Fotografia