
voidstarzero
(void*) 0
'The inverse of my verse, a null domain.'
13 posts
Don't wanna be here? Send us removal request.
Last Seen Blogs

kittyrulestheworld
Sevenlibraslong

aquataholic
Wild Type

myspajoy
massage, facials, yoga & pilates


dust
Dust
Photo

Psychedelic Zooey
3 notes
·
View notes
Text
I went to a photography equipment garage sale a couple of weekends ago and got a lovely vintage 50mm lens for my Nikon camera. It’s an F-series lens from the 60s/70s, and works perfectly with my F65 (manufactured in the early 2000s; bought for me by my mum from the used section of our local Henry’s in the mid-2000s). I love that this compatibility between two pieces of equipment manufactured 3-4 decades apart is possible because, even as both their camera and lens technologies have evolved, Nikon has stuck to the same lens mount interface since... 1959. Truly incredible product vision and engineering discipline.
I’ve gone through 3 rolls of film since acquiring my new lens and I cannot stop playing with it. I still have about a half dozen more rolls to shoot before I’ll start developing. (Obviously, one roll of black and white set aside entirely for artsy macro cat pics.)

1 note
·
View note
Text
no autograph has been found
In fact, Hopkins seems to have originated his sprung rhythm as a reform of Swinburne's ternary meter by eliminating what he perceived as its quantitative infelicities (Schneider 1968, Kiparsky 1989).
(Hanson and Kiparsky, 1996, p. 300)
Another [presentation piece] is supposed to be the 'Ad Mariam', printed in the 'Stonyhurst Magazine', Feb. '94. This is in five stanzas of eight lines, in direct and competent imitation of Swinburne: no autograph has been found; and, unless Fr. Hopkins's views of poetic form had been provisionally deranged or suspended, the verses can hardly be attributed to him ... nor can I put aside the overruling objection that G. M. H. would not have wished these 'little presentation pieces' to be set among his more serious artistic work. I do not think that they would please any one who is likely to be pleased with this book.
(Bridges, 1918, p. 105)
Wherefore we love thee, wherefore we sing to thee,
Where shall we find her, how shall we sing to her,
We, all we, thro' the length of our days,
Fold our hands round her knees, and cling?
The praise of the lips and the hearts of us bring to thee,
O that man's heart were as fire and could spring to her,
Thee, oh maiden, most worthy of praise;
Fire, or the strength of the streams that spring!
For lips and hearts they belong to thee
For the stars and the winds are unto her
Who to us are as dew unto grass and tree,
As raiment, as songs of the harp-player;
For the fallen rise and the stricken spring to thee,
For the risen stars and the fallen cling to her,
Thee, May-hope of our darkened ways!
And the southwest wind and the west wind sing.
(Hopkins, 1894; Swinburne, 1865)
References
Bridges, R. (Ed.). (1918). Poems of Gerard Manley Hopkins. London: Humphrey Milford
Hanson, K., & Kiparsky, P. (1996). A Parametric Theory of Poetic Meter. Language, 72 (2), 287–335. https://doi.org/10.2307/416652
Hopkins, G. M. (1894). Ad Mariam. Poetry Nook. Retrieved May 19, 2022, from https://www.poetrynook.com/poem/ad-mariam
Swinburne, A. C. (1865). Atalanta in Calydon. Retrieved May 19, 2022, from https://en.wikisource.org/wiki/Atalanta_in_Calydon/Text
3 notes
·
View notes
Note
Just wanted to say I really enjoyed reading your blog entries. Hope your Masters is going well!
Hi, thank you! Sorry if this response is coming very late, I haven't been very active on here for a while (which is to say, the Masters is going well...)
0 notes
Text
DPoP with Spring Boot and Spring Security
Solid is an exciting project that I first heard about back in January. Its goal is to help “re-decentralize” the Web by empowering users to control access to their own data. Users set up “pods” to store their data, which applications can securely interact with using the Solid protocol. Furthermore, Solid documents are stored as linked data, which allows applications to interoperate more easily, hopefully leading to less of the platform lock-in that exists with today’s Web.
I’ve been itching to play with this for months, and finally got some free time over the past few weekends to try building a Solid app. Solid's authentication protocol, Solid OIDC, is built on top of regular OIDC with a mechanism called DPoP, or "Demonstration of Proof of Possession". While Spring Security makes it fairly easy to configure OIDC providers and clients, it doesn't yet have out-of-the-box support for DPoP. This post is a rough guide on adding DPoP to a Spring Boot app using Spring Security 5, which gets a lot of the way towards implementing the Solid OIDC flow. The full working example can be found here.
DPoP vs. Bearer Tokens
What's the point of DPoP? I will admit it's taken me a fair amount of reading and re-reading over the past several weeks to feel like I can grasp what DPoP is about. My understanding thus far: If a regular bearer token is stolen, it can potentially be used by a malicious client to impersonate the client that it was intended for. Adding audience information into the token mitigates some of the danger, but also constrains where the token can be used in a way that might be too restrictive. DPoP is instead an example of a "sender-constrained" token pattern, where the access token contains a reference to an ephemeral public key, and every request where it's used must be additionally accompanied by a request-specific token that's signed by the corresponding private key. This proves that the client using the access token also possesses the private key for the token, which at least allows the token to be used with multiple resource servers with less risk of it being misused.
So, the DPoP auth flow differs from Spring's default OAuth2 flow in two ways: the initial token request contains more information than the usual token request; and, each request made by the app needs to create and sign a JWT that will accompany the request in addition to the access token. Let's take a look at how to implement both of these steps.
Overriding the Token Request
In the authorization code grant flow for requesting access tokens, the authorization process is kicked off by the client sending an initial request to the auth server's authorization endpoint. The auth server then responds with a code, which the client includes in a final request to the auth server's token endpoint to obtain its tokens. Solid OIDC recommends using a more secure variation on this exchange called PKCE ("Proof Key for Code Exchange"), which adds a code verifier into the mix; the client generates a code verifier and sends its hash along with the authorization request, and when it makes its token request, it must also include the original code verifier so that the auth server can confirm that it originated the authorization request.
Spring autoconfigures classes that implement both the authorization code grant flow and the PKCE variation, which we can reuse for the first half of our DPoP flow. What we need to customize is the second half -- the token request itself.
To do this we implement the OAuth2AccessTokenResponseClient interface, parameterized with OAuth2AuthorizationCodeGrantRequest since DPoP uses the authorization code grant flow. (For reference, the default implementation provided by Spring can be found in the DefaultAuthorizationCodeTokenResponseClient class.) In the tokenRequest method of our class, we do the following:
retrieve the code verifier generated during the authorization request
retrieve the code received in response to the authorization request
generate an ephemeral key pair, and save it somewhere the app can access it during the lifetime of the session
construct a JWT with request-specific info, and sign it using our generated private key
make a request to the token endpoint using the above data, and return the result as an OAuth2AccessTokenResponse.
Here's the concrete implementation of all of that. We get the various data that we need from the OAuth2AuthorizationCodeGrantRequest object passed to our method. We then call on RequestContextHolder to get the current session ID and use that to save the session keys we generate to a map in the DPoPUtils bean. We create and sign a JWT which goes into the DPoP header, make the token request, and finally convert the response to an OAuth2AccessTokenResponse.
Using the DPoP Access Token
Now, to make authenticated requests to a Solid pod our app will need access to both an Authentication object (provided automatically by Spring) containing the DPoP access token obtained from the above, as well as DPoPUtils for the key pair needed to use the token.
On each request, the application must generate a fresh JWT and place it in a DPoP header as demonstrated by the authHeaders method below:
private fun authHeaders( authToken: String, sessionId: String, method: String, requestURI: String ): HttpHeaders { val headers = HttpHeaders() headers.add("Authorization", "DPoP $authToken") dpopUtils.sessionKey(sessionId)?.let { key -> headers.add("DPoP", dpopUtils.dpopJWT(method, requestURI, key)) } return headers }
The body of the JWT created by DPoPUtils#dpopJWT contains claims that identify the HTTP method and the target URI of the request:
private fun payload(method: String, targetURI: String) : JWTClaimsSet = JWTClaimsSet.Builder() .jwtID(UUID.randomUUID().toString()) .issueTime(Date.from(Instant.now())) .claim("htm", method) .claim("htu", targetURI) .build()
A GET request, for example, would then look something like this:
val headers = authHeaders( authToken, sessionId, "GET", requestURI ) val httpEntity = HttpEntity(headers) val response = restTemplate.exchange( requestURI, HttpMethod.GET, httpEntity, String::class.java )
A couple of last things to note: First, the session ID passed to the above methods is not retrieved from RequestContextHolder as before, but from the Authentication object provided by Spring:
val sessionId = ((authentication as OAuth2AuthenticationToken) .details as WebAuthenticationDetails).sessionId
And second, we want the ephemeral keys we generate during the token request to be removed from DPoPUtils when the session they were created for is destroyed. To accomplish this, we create an HttpSessionListener and override its sessionDestroyed method:
@Component class KeyRemovalSessionListener( private val dPoPUtils: DPoPUtils ) : HttpSessionListener { override fun sessionDestroyed(se: HttpSessionEvent) { val securityContext = se.session .getAttribute("SPRING_SECURITY_CONTEXT") as SecurityContextImpl val webAuthDetails = securityContext.authentication.details as WebAuthenticationDetails val sessionId = webAuthDetails.sessionId dPoPUtils.removeSessionKey(sessionId) } }
This method will be invoked on user logout as well as on session timeout.
0 notes
Text
The one thing I have found no substitute for during this year of lockdowns is the experience of visiting used bookstores. They are what people with romantic notions about libraries think libraries are, but there is no real curatorial or organizational goal in a used bookstore. You enter one and are confronted by a mass of as many books as could be crammed into the space, and the more disorderedly the arrangement, the better it feels. There may be signs guiding you to general sections, but few rules and no promises as to what you’ll find in each. It’s a thrill to discover whether the poetry shelf will, on this visit, contain out-of-print works by a favourite Canadian poet, a book of Russian photography, or an inexplicably large number of leather-bound volumes of something dull, perhaps inherited and then offloaded by an unappreciative beneficiary. There may be an online catalog, provided through services like AbeBooks or a periodically updated PDF on the store’s website, but there is almost always a tacit agreement that it is incomplete. There is neither any way to order something specific, nor to anticipate future stock. Used bookstores deliberately resist our expectations of “order and method”, and I miss the comfort of hanging out in the middle of that every now and then.
4 notes
·
View notes
Text
Parsing ISBD. part II, Contextualizing MARC Data
When I resumed blogging last year, I had aimed to post at least a couple of times per month. It was an ambitious goal and I did not succeed; hopefully this year will be better?
Anyway, please enjoy the following long overdue conclusion to our ISBD parsing discussion, rescued from my drafts. I wrote this many months ago, and have since been working on deepening my understanding of serials cataloguing, but I'm going to publish this post as is so that we can move on to other MARC topics next time!
Though the parser combinators we talked about in the last post are powerful, we sometimes need more context when making ISBD parsing decisions. Consider the following two examples:
Abstracts of Bulgarian scientific literature. Mathematics, physics, astronomy, geophysics, geodesy / Bulgarian Academy of Sciences, Centre for Scientific Information and Documentation.
MInd, the meetings index. Series SEMT, Science, engineering, medicine, technology.
The first is for one set of volumes (titled Mathematics, physics, astronomy, geophysics, geodesy) of a multipart monograph (Abstracts of Bulgarian scientific literature); the second is for a series titled Science, engineering, medicine, technology, designated by the series name Series SEMT, within the journal MInd, the meetings index.
The data upto the first period in both cases denotes the "common title" of each work, but it's what follows that's interesting. There are two possible ISBD patterns that can be applied here, based on the grammar alone:
Common title. Dependent title designation, Dependent title
Common title. Dependent title
As you can see, the commas in the dependent title of both examples make it ambiguous as to which way they should be parsed. Technically, there's no reason why "Mathematics" in the first title couldn't be parsed as a dependent title designation, even though we can tell from our understanding of English that that isn't correct. Our parser doesn't understand natural language, though; it needs some simpler way to decide which rule to apply.
There are two different ways to parse MARC title data, and as this example shows, neither on its own is the right way. A MARC 245 field can be parsed according to its subfields, or according to its ISBD grammar as we've been doing, but these parses are non-composable (the elements extracted by each parse do not always line up with each other), and kind of orthogonal to each other (each may capture something that the other misses).
As I've said before, context-sensitive parsing allows us to feed extra information to the parser to help "contextualize" its parsing decisions. In this case, we want to allow our ISBD parser to access and work with the subfields-based parse when parsing the whole title statement. (Note that this is very different from breaking a field into its subfields and then trying to analyze the grammar within each subfield; instead we're keeping the data intact and looking at the ISBD structure in parallel to the subfields structure.)
Going back to the dependent title designation (DTD) problem, we could use this idea to define a subparser as follows:
Look for a candidate DTD in the form of a string followed by a comma.
Consult the subfields parse to see if there are any subfield n values from our current parse position that match the candidate DTD.
If there are, update the parse position in both the ISBD and the subfields parse, and return a successful match. If there are no values in the MARC data that match our candidate, then return a failure to match, which will allow the parser to backtrack and try a different pattern.
With this logic, when the parser attempts to match "Mathematics" as a DTD, it will fail to find |nMathematics in the MARC data (because that string is part of subfield p), and will instead correctly use the second pattern above.
0 notes
Text
Parsing ISBD. Interlude : Parser Combinators
I was going to pick up from the end of my previous post on ISBD, but I thought I should take a minute to talk about parser combinators first. There's lots on the internet already about what these are, so I’ll keep this specific to how they are used in the ISBD parsing library I mentioned last time.
Simply put, this approach to writing a parser consists of first writing smaller parsers focused on specific parts of the input, then combining them using higher-order “combinators” which encapsulate parsing logic like repetition, choosing between alternatives, etc. For example, isbd-parser defines several simple parsers that match exact sequences in the grammar, like " = ", " ; ", etc. Given the equalSign parser which matches " = " and a parser called data that matches any string not containing special grammar symbols, we could define a parser that matches parallel data as follows:
val parallelData: rule = seq(equalSign, data)
Here, seq is a combinator that produces a parser which runs the parsers given as input in sequence. (The rule type is a wrapper class around parsers in Autumn.) So, parallelData matches any input that begins with " = " followed by a string of data.
In a similar way, we can build up a parser for parsing a full parallel title statement given smaller parsers for each of the components of the statement; simplfiying a little, these would be the title proper, other title information, and statement of responsibility:
val otherInfo: rule = seq(colon, data) val sor: rule = seq(slash, data) val parallelTitleFull: rule = seq( parallelData, otherInfo.maybe(), sor.maybe() )
Notice the .maybe() on the otherInfo and sor parsers; this is another combinator which produces a parser that matches zero or one occurrences of the input matched by the original parser, similar to ? in regular expressions. So parallelTitleFull matches an equal sign followed by a title proper, and optionally other title info and/or a SOR.
I mentioned last time the ambiguity with " = " in ISBD statements; one possible context in which you might find an equal sign is after a statement of responsibility, where it can either be just a parallel SOR1:
Bibliotheca Celtica : a register of publications relating to Wales and the Celtic peoples and languages / Llyfrgell Genedlaethol Cymru = The National Library of Wales
...or the start of a parallel version of the entire title statement:
Xiao xiao xiao xiao de huo / [Mei] Wu Qishi zhu = Little fires everywhere / Celeste Ng.
This is a case where the type of the data after the " = " depends on both what has already been parsed and what remains to be parsed. How do we handle this? Well, we've already got a parser for the full parallel title statement and here's a simple one for the parallel SOR:
val parallelSOR: rule = seq(equalSign, data)
In a statement of responsibility context, we want to apply exactly one of these parsers, depending on which one best matches the remaining input after the " = ". To do that, we can use the longest combinator:
val parallelSOROrTitle: rule = longest(parallelSOR, parallelTitleFull)
longest tries each parser in turn, and chooses the one that consumes the most input. Thus, if there is only a SOR, the parallel data will be parsed as a statement of responsibility; otherwise, it will be parsed as a parallel title statement. (Note that the SOR is technically a little more complicated, in an uninteresting way; the grammar has been simplified here for the sake of illustration.)
Since a title statement doesn't need to contain anything but a title proper, how do we know the string "The National Library of Wales" is actually a SOR and not a title? Mercifully, ISBD specifies that if there is only parallel title proper information, it must be recorded after the title proper itself, not after the entire title statement, so we can safely rule out that possibility here. ↩︎
1 note
·
View note
Text
Parsing ISBD. part I
I’ve had a long-running draft about parsing ISBD that I keep editing and re-editing, unsure of how to start with this complicated subject. ISBD is an outmoded system of punctuation used to structure bibliographic data. An ISBD statement can often contain more information than MARC fields alone capture, such as parallel titles or granular contribution information for collected works. Parsing it accurately can improve the quality of data that is possible to extract from legacy MARC records. This is quite a challenge, though; the ISBD grammar is not technically regular, and therefore impossible to parse reasonably using common tools based on regular expressions.
I carried a printout of one of the most difficult parts of the grammar -- the title statement punctuation -- in my notebook for the better part of last year, something to idly stare at when my brain needed a break from whatever less important problems I was working on at the time. A few months ago, I finally sat down and wrote out the core of a context-sensitive ISBD parser. The context-sensitivity is crucial: unlike regexps, or even context-free parsers, context-sensitive techniques allow you to share extra information with the parser to aid its parsing decisions, which turns out to be the key to handling ISBD’s ridiculous complexity.
What kinds of “extra information”? One case is for precisely understanding equal signs in the input. An equal sign is followed by parallel (i.e., translated) information of a type that depends on what data the parser has already seen. So, an equal sign before a colon (which indicates supplemental title info, like a subtitle) would mean that the data following the equal sign is a parallel title proper; while an equal sign after a colon (but before a slash!) could mean the data is a parallel subtitle, but could also mean the data is a parallel title that will be followed by a parallel subtitle; and so on. The context-sensitive approach would store information describing the history of the parse ("Was the last thing I saw a title, subtitle, statement of responsibility, etc?”) and refer to this information when encountering an equal sign. The very nice thing about doing this in a framework like Autumn is that this stateful information is automatically kept accurate in light of things like backtracking. So you end up with quite a tidy solution for a complicated piece of parsing logic.
Another interesting case, which I think I’ll talk about next time, is when there isn’t enough information in the input itself to determine how it should be parsed, so the MARC data needs to be combined with the input to more accurately extract information.
0 notes
Text
Delegates in Kotlin
When I started using Kotlin for work last year, I went pretty quickly from uncertainty about whether it deserved the hype to devoted enthusiasm. The syntax does make it much more fun to write than Java, but Kotlin’s real strength is that it lets us out of the mindjail of OOP, in principled and easy-to-use ways.
One of my favourite Kotlin features is delegated properties. These are properties (and/or local variables) that are managed by a delegate class which allows for encapsulating and sharing logic among classes without resorting to inheritance. I generally quite dislike inheritance-based patterns, so being able to conveniently use delegates instead of inheriting from a bunch of interfaces is really nice.
In my work, I’ve found them helpful for implementing properties that apply to only small subsets of the hundreds of children of a particular data class -- subsets whose members otherwise have nothing to do with each other. (No need to create pointlessly deep class hierarchies just to share code.) I recently ran into a situation where I needed to use different parameters to compute the value of a delegated property in different situations. Depending on the details, there are at least a couple of ways to do this in Kotlin, using either the type of the object passed to the delegate, or by using annotations on the property itself.
Targeted delegates
A delegate class must implement getValue (and, for vars, setValue) methods, whose first argument is the object on which the delegate is defined. This can be used to tailor a delegate's behaviour for specific classes. Consider this setup:
open class Example class ExampleChild1 : Example() { val dprop by Delegate() } class ExampleChild2 : Example() { val dprop by Delegate() }
If the Delegate class is defined as follows, then ExampleChild1.dprop will be computed using value 1, while ExampleChild2.dprop, using the default of 0:
import kotlin.reflect.KProperty class Delegate { operator fun getValue(thisRef: Example, property: KProperty<*>): Int { return calculateValue(0) } operator fun getValue(thisRef: ExampleChild1, property: KProperty<*>): Int { return calculateValue(1) } private fun calculateValue(i: Int): Int { TODO() } }
It's a simple example, but the getValue implementations could also extract the value to pass to calculateValue from other data in thisRef instead of using a constant. Note also that if dprop had been defined on Example, this wouldn't work as written. (There are ways to make it work, though...)
Annotating delegated properties
Another approach is to "pass" the values in to the delegate using annotations. This allows the user of the delegate to have more control over the delegate's behaviour and, unlike the previous example, also works in the case where different delegated properties within the same class may need to be computed differently.
Defining a very basic annotation to carry the value is straightforward:
annotation class ExampleAnnotation(val i: Int)
It can then be applied to the delegated properties, and the implementation of Delegate modified accordingly. (For this solution you will need to include kotlin-reflect as a dependency.)
class ExampleChild1 : Example() { @ExampleAnnotation(1) val dprop by Delegate() } class ExampleChild2 : Example() { val dprop by Delegate() }
import kotlin.reflect.KProperty class Delegate { operator fun getValue(thisRef: Example, property: KProperty<*>): Int { return property.annotations .filterIsInstance<ExampleAnnotation>() .firstOrNull() ?.let { ann -> calculateValue(ann.i) } ?: calculateValue(0) } private fun calculateValue(i: Int): Int { TODO() } }
I have a preference for this second method, but like I said, the appropriateness of either approach will likely highly depend on the particular case.
0 notes
Text
Bibliographic Polymorphism
Last time I talked a little about the difficulties MARC presents for modern applications. It’s too sophisticated to be considered just structured (or even marked-up) data, yet not semantically contained enough to be a language. But sometimes I wonder: if the MARC effort were undertaken by computer scientists today, would it turn out an actual programming language?
There’s neat computational stuff in MARC that prompts these daydreams. One example is the 880 Alternate Graphic Representation field, which you can see in action in records like this one from the Library of Congress:
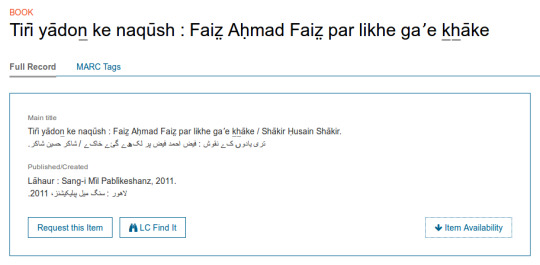
The title and publication information are presented in the original Urdu script as well as the anglicized transliterations. In the MARC record, the original script data is recorded separately from the title and pub fields, via 880 fields:

In the above:
The 3-digit tags at the start of each line identify the field whose data that line contains. The Title Statement field has tag 245, and 260 is for publication-related information.
The two characters following the tag are called indicators (and are not important for today's post).
The string that makes up most of the field is the tag data. It is broken up into subfields by a separator character (in this case, |) followed by a single character identifying the subfield, called a subtag. For example, the 245 field above contains 4 subtags, |6, |a, |b, and |c.
The meaning of a subfield is field-dependent; the |a in the 245 means something very different from the |a in the 260. So, how do the 880s work? In the example above, both contain |a but in the first instance, it's interpreted as the main title, while in the second, it's the place of publication.
The 880 spec has only one subfield defined, |6, whose contents determine the meaning of the field. In the first 880 above, the |6 contains "245", meaning that this 880 takes on the shape of a 245, and hence the |a it contains is interpreted as 245's |a.
Why not just record this data in a 245, then?
The 880 tag itself provides an important context -- namely, that the data it contains is in some other language/script. Treating it as a separate type thus confers the ability to work with this representation -- whether customizing display logic, including or excluding it from search indexes, etc. -- independently from the regular bibliographic data.
It's useful then to think of 880 not as a datafield itself but as a generic container, parameterized over datafields. That is, an 880 field in the MARC record corresponds to a value of type 880<A>, which provides an A datafield along with some information about the alternative representation contained within that datafield (such as the script used). It's both conceptually and practically much cleaner than defining an 880 counterpart for each datafield in the MARC spec.
(For completeness: There are other aspects to the 880, such as the fact that it not only corresponds to another datafield type, but is (usually) linked to a specific instance of that datafield within the MARC record, but these are irrelevant for this discussion.)
1 note
·
View note
Text
RacketDB, and Method Chaining
If you’re wondering where the posts about my Racket RethinkDB driver went, I’ve archived them until I can find the time to reorganize them a little. The good news is that the initial code is now available on Github. It’s missing a few things yet, but there’s enough to play around with.
One of the more interesting aspects to this project was trying to design an API that closely mirrored the nice chaining style offered by the official drivers. To see an example of what I mean, here is how one might write a filter query using the Ruby driver:
r.db("library") .table("books") .filter({:author => "Doris Lessing"}) .run(conn)
What this query serializes to (i.e. what’s transmitted to the server by run) is the following:
[39,[[15,[[14, ["library"]],"books"]],{"author":"Doris Lessing"}]]
where 39 is the code for a filter command; 15, for table; and 14, for db. (See the section on “ReQL Commands” under Serializing Queries in the driver guide for more info.)
The main point here is that the query is nested “inside-out” from the order of the methods. In the most straightforward Racket, we would write something like:
(filter (table "books" (db "library")) (hash "author" "Doris Lessing"))
where each command takes the queries it depends on as arguments. But I find this aesthetically less appealing than the ReQL chaining style, and why make the Racket driver not as great as any other? So then, if we’re going to make calls in inverse order, how do we get each command to “pass itself forward” to the command that needs it?
Inverting the nesting of expressions is exactly what happens with continuation-passing style, so it seems likely that continuations are somehow the answer. In fact, each ReQL command could produce a lambda that takes a “continuation” and applies that to whatever the command itself should produce (in this case, a data structure representation of the command). This continuation knows how the rest of the query needs to be built (hence it’s called “builder”), and how to slot the current command into it. (Where it comes from, we’ll get to in a second.) So, for example, the definition of db might look something like this:
(define (db arg) (λ (builder) (builder (reql-term 'db (list arg) '#hash()))))
db is “anchored” in that it can only occur at the start of a chain, but commands that can be chained in the middle, like table, need to first produce a continuation (for their predecessor), which will in turn produce a lambda that expects a continuation. So, first the chained command receives any query terms it depends on from its predecessor, then it “passes itself forward” via the builder lambda.
(define (table arg) (λ (pred-term) (λ (builder) (builder (reql-term 'table (list pred-term arg) '#hash())))))
Finally, this is all tied together with a function that traverses this list of lambdas and applies them in succession:
(define (build-query . commands) (cond [(empty? commands) (λ (x) x)] [(empty? (rest commands)) ((first commands) (λ (x) x))] [else (let ([chain ((first commands) (second commands))]) (apply build-query (cons chain (rest (rest commands)))))]))
There may be other ways of achieving the same thing, but it’s the best solution I’ve come up with so far for emulating the method chaining style in Racket.
0 notes
Text
Getting started with Protocol Buffers in Racket
Google’s Protocol Buffers provide an easy way to serialize data, and with the PLT protobuf package, you can use them in Racket too. First, install the Racket package and the Protobuf compiler:
$ sudo raco pkg install planet-murphy-protobuf1 $ sudo apt-get install protobuf-compiler
The PLT package installs a binary called protoc-gen-racket which is a plugin for protoc, the Protobuf compiler. This plugin will generate Racket definitions from our .proto files.
To tell protoc to compile to Racket, use the --racket_out parameter, as follows:
$ protoc -I=$SRC_DIR --racket_out=$DST_DIR $SRC_DIR/sample.proto
where SRC_DIR is the location of the .proto file and DST_DIR is the directory where the compiled files should go.
Creating messages
Using the example from the Protobuf docs, suppose we have the following in sample.proto:
message Person { required string name = 1; required int32 id = 2; optional string email = 3; }
If we run the above protoc command, we’ll get a sample.rkt file that looks something like this:
#lang racket/base ;; Generated using protoc-gen-racket v1.1 (require (planet murphy/protobuf:1/syntax)) (define-message-type person ((required primitive:string name 1) (required primitive:int32 id 2) (optional primitive:string email 3))) (provide (all-defined-out))
This syntax defines the struct for our Person message. It also generates a variadic constructor named person* that takes upto three keyword arguments, one for each field, where the keyword is the field name. For example:
(define p (person* #:name "A. Philip" #:id 42))
Serializing and deserializing
To see how serializing and deserializing work, create two Racket files, serialize.rkt and deserialize.rkt, containing the following code:
;; serialize.rkt #lang racket (require (planet murphy/protobuf)) (require "proto/sample.rkt") ;; Create a new Person message. (define p (person* #:name "A. Philip" #:id 42)) ;; Serialize message and send to the default output port. (serialize p)
;; deserialize.rkt #lang racket (require (planet murphy/protobuf)) (require "proto/sample.rkt") ;; Attempt to deserialize input as a Person message, ;; and retrieve the "name" field. (person-name (deserialize (person*)))
Now, we can do the following:
$ racket serialize.rkt | racket deserialize.rkt "A. Philip"
Further reading
Racket Protocol Buffers package documentation
Racket structs
keyword arguments in Racket lambdas
0 notes