#vframe
Photo

Toronto from a Vrame 🖼️ 📸Nikon D5600, 70-300 mm non-VR DX, natural lighting, handheld, Lightroom classic. My shot and edit. #torontophoto #torontolove #torontoskyline #torontophotography #torontocanada #torontophotographer #toronto #ontario #ontariophotographer #discoverontario #discovertoronto #watersedge #lakeontario #framed #vframe #ducks #canadagoose #canadatourism #canadaphotography #landscapephotography (at Toronto, Ontario) https://www.instagram.com/p/CpQh_H6JcPs/?igshid=NGJjMDIxMWI=
#torontophoto#torontolove#torontoskyline#torontophotography#torontocanada#torontophotographer#toronto#ontario#ontariophotographer#discoverontario#discovertoronto#watersedge#lakeontario#framed#vframe#ducks#canadagoose#canadatourism#canadaphotography#landscapephotography
0 notes
Photo
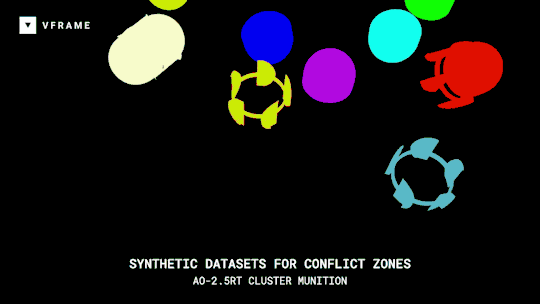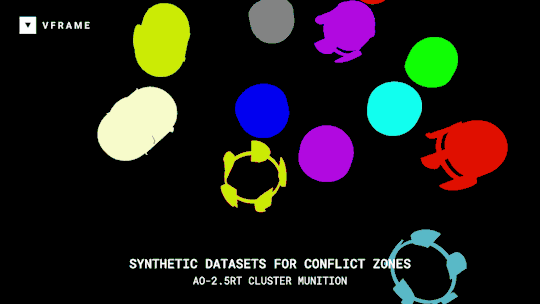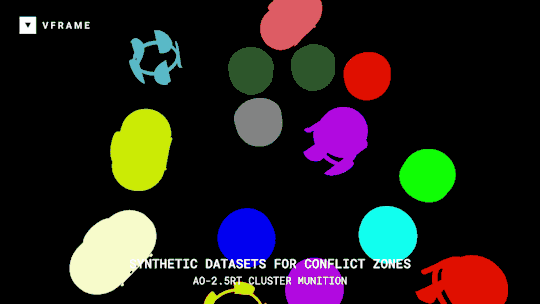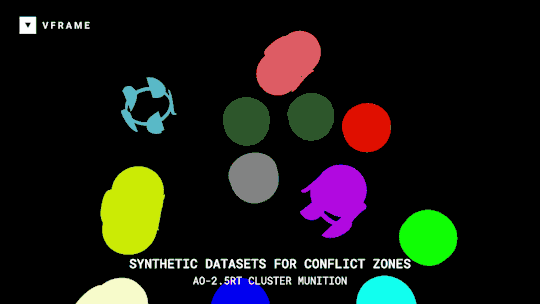
VFRAME
Adam Harvey
A collection of open-source computer vision software tools designed specifically for human rights investigations that rely on large datasets of visual media.
Specifically VFRAME is developing computer vision tools to process million-scale video collections, scene summarization algorithms to reduce processing times, object detection models to detect illegal munitions, synthetic datasets to train object detection models, a visual search engine to locate similar images of interest, and an custom annotation system to create training data. Read more
https://vframe.io/
#computer vision#image analysis#war photography#artists projects#unthinking photography#synthetic imaging#dataset#image datasets
1 note
·
View note
Text
devlog: 01/08/2021
Today I could finish the piranha enemy animation. But let me admit that it does not look at all like a piranha. It's just a fish enemy. I wanted it to look like a piranha but I just couldn't dot it yet.
While importing the animations I thought there was a bug in my spritesheet importer - which automatically sets the right hframes and vframes in the sprite node and create animation tracks in the animation player - and went to debug it. It took some time to notice that it was not a bug in the importer, but the fact that the animation file was using a frame size different from what I wrote in the config file (which the spritesheet importer uses to get information from). When I draw or animate, I usually define my target sprite size (say, 16x16), then I add one extra tile length as a border on all four sides, so for a 16x16 image, we have a 48x48 canvas size (16 as on border + expected sprite length of 16 + 16 on the opposite border). But even though I put the dimensions right in the config file, the canvas size on krita was wrong (it was 46x46), which messed up the import logic. When I fixed the canvas size on krita the spritesheet was imported as intended.
After that, I started making the sound effects and had a lot of trouble with it. I wanted a splash effect but couldn't find a way to make one that pleased me. I need to renew my SFX creation workflow in order to be capable of making a wider range of sound effects, with more variation and more control over the sound. In the end, I would try to use labchirp, which I have already used before, but my time ran out and I had to finish the stream
So, If you're interested, check out the timelapse (the embedded videos bellow won't show on tumbler dashboard, only on the blog view):
https://www.youtube.com/watch?v=_UtYwSRjoKA
youtube
Also, check out the livestream itself.
https://www.youtube.com/watch?v=Gcq9aQ_Kx0o
https://www.twitch.tv/videos/865653958
0 notes
Photo

Illustration Photo: VFRAME is a computer vision toolkit designed for human rights researchers and investigative journalists. It provides customized state-of-the-art tools for object detection and quantification, scene classification, visual search, image annotation for creating datasets, APIs to integrate with existing workflows, the ability to train new algorithms, and graphic content filtering algorithms to reduce exposure to traumatic Content. (credits: Adam Harvey / Ars Electronica / Flickr Creative Commons Attribution-NonCommercial-NoDerivs 2.0 Generic (CC BY-NC-ND 2.0))
EU Call for Applications: NGI Explorers Program in USA - Data-Efficient Machine Learning
This topic focuses on the investigation and development of data-efficient machine learning methods that are able to leverage knowledge from external/existing data sources, exploit the structure of unsupervised data, and combine the tasks of efficiently obtaining labels and training a supervised model. Areas of interest include, but are not limited to: Active learning, Semi-supervised learning, Learning from "weak" labels/supervision, One/Zero-shot learning, Transfer learning/domain adaptation, Generative (Adversarial) Models, as well as methods that exploit structural or domain knowledge.
Furthermore, while fundamental machine learning work is of interest, so are principled data-efficient applications in, but not limited to: Computer vision (image/video categorization, object detection, visual question answering, etc.), Social and computational networks and time-series analysis, and Recommender systems.
Details
Many recent efforts in machine learning have focused on learning from massive amounts of data resulting in large advancements in machine learning capabilities and applications.
However, many domains lack access to the large, high-quality, supervised data that is required and therefore are unable to fully take advantage of these data-intense learning techniques. This necessitates new data-efficient learning techniques that can learn in complex domains without the need for large quantities of supervised data.
Skills required
A basic understanding of Machine Learning
Application Deadline: 31 July 2019
Check more https://adalidda.com/posts/AdgoKh4FiaAup5dyM/eu-call-for-applications-ngi-explorers-program-in-usa-data
0 notes
Text
Ars Electronica Export – Error: The Art of Imperfection
While visiting Berlin for the transmediale we stumbled on the Ars Electronica Export exhibition at the DRIVE Volkswagen Group Forum. The artworks were were very professionally curated into the space and it was not too disturbing with the show case cars in between. To my joy there was a number of artworks that related to Machine Vision. Some of them I have seen at earlier editions of Ars Electronica, yet some of them were new to me. Below some of my documentation from the exhibition with artwork abstracts copied from the exhibition webpage.


Echo by Georgie Pinn

Echo is a bridge to another person’s memory, identity and intimate experience. The key intention of the work is to generate empathy and connect strangers through an exchange of facial identity and storytelling. Seated inside a graffitied photo booth and guided by an AI character, you slowly see another’s face morph into your own, driving your features with their expression. When you record your own story, layers of yourself are echoed in the other. What story will you share with a stranger?
Creative Producer: Kendyl Rossi (AU/CA)
www.electric-puppet.com.au


youtube
ller by Prokop Bartoníček , Benjamin Maus

Jller is part of a research project on industrial automation and historical geology. The apparatus sorts pebbles from the German river Jller by their geologic age. The river carries pebbles that are the result of erosions in the Alps, and those from deeper rock layers once covered by glaciers. The machine uses computer vision to sort the stones by colors, lines, layers, grain and surface texture, and classifying them into age categories using a manually trained algorithm.
www.prokopbartonicek.com
www.allesblinkt.com
Narciss by Waltz Binaire

The human ability of self-perception and our urge to question, research, pray and design have long been unique in the world. But is this still true in the digital age? Narciss is the first digital object that reflects upon its own existence by exploring its physical body with a camera. An AI Algorithm translates the observations into lyrical guesses about who it thinks it is. The algorithm simulates human cognition from a behavioural perspective. The resulting rapprochement of man and machine questions our self-image and our raison d‘être.
waltzbinaire.com
Mosaic Virus by Anna Ridler

Mosaic is the name of the tulip virus responsible for the coveted petal stripes that caused the speculative prices during the ”tulip mania” in the 1630s. This work draws a parallel to the current speculations around cryptocurrencies, showing blooming tulips whose stripes reflect the value of the Bitcoin currency. Echoing how historical still lifes were painted from imagined bouquets rather than real ones, here an Artificial Intelligence constructs an image of how it imagines a tulip looks like.
This work has been commissioned by Impakt within the framework of EMAP/EMARE, co-funded by Creative Europe.
Myriad (Tulips) by Anna Ridler

This work is the training data set for the parallel work Mosaic Virus. Ten thousand, or a myriad, tulips were photographed and sorted by hand by the artist according to criteria of color, type and stripe — a work that is the basis of any database for machine learning. The images reveal the human aspect that sits behind machine learning and how the labels are often ambiguous. How objective can artificial intelligence actually be when it is repeating the decisions made by people? And how difficult is it to classify something as complex as gender or identity when it is hard to categorize a white from a light pink tulip?
annaridler.com
The Normalizing Machine by Mushon Zer-Aviv, Dan Stavy, Eran Weissenstern

Early scientific methods to standardize, index and categorize human faces were adopted by the Eugenics movement as well as the Nazis to criminalize certain face types. Alan Turing, considered the founder of computer science, hoped that algorithms would transcend this systemic bias by categorizing objectively, and end the criminalization of deviations like his own homosexuality. But how do algorithms identify a “normal“ face? And how do we?
mushon.com
stavdan.com
eranws.github.io
youtube
VFRAME – Visual Forensics and Advanced Metadata Extraction by Adam Harvey

VFRAME is an open source computer vision toolkit designed for human rights researchers and journalists. VFRAME is currently working with the Syrian Archive, an organization dedicated to documenting war crimes and human rights abuses, to build AI that can automatically detect illegal munitions in videos. Their current research explores the use of 3D modeling and physical fabrication to create new image training datasets.
ahprojects.com


Written by Linda Kronman, originally posted here.
0 notes
Link
0 notes
Link
VFRAME is a collection of open-source computer vision software tools designed specifically for human rights investigations that rely on large datasets of visual media.
0 notes
Text
Monaco Global with v frame systems and coil tie series,she tie bolt

In the construction industry, often accessing structures and high buildings is a tough and continuous safety concern. As they are positioned at such great heights above the ground level, the significance of offering contemporary and new support structures becomes obvious with the lives of many workers at risk. The correct installation of scaffolds is critical and using the correct items such as VFrame Series, Coil Tie Series and She Tie Bolts from Monaco Global.Scaffolding systems are a vital support structure and frame that is imperative for various activities including window cleaning, painting, building inspections, performing repair and maintenance of buildings and civil engineering.Monaco Global’s products comprise of various materials such as wood and metals. Get in touch with the team today to discuss your Building requirements www.monaco-global.com.au
0 notes
Text
Syrienkrieg: So spürt künstliche Intelligenz Kriegsvebrechen auf!
Die Software „VFrame“ kann private Aufnahmen aus dem Syrienkrieg automatisiert auswerten und nach Hinweisen auf Kriegsverbrechen untersuchen. Nutzen möchte diese Möglichkeit unter anderem die Organisation „Syrian Archive“. Diese hat bereits in der Vergangenheit versucht, alle Videos aus öffentlich zugänglichen Quellen zu erfassen und zu dokumentieren. Die Zahl der Aufnahmen ist aber so groß, dass es … http://bit.ly/2JS5VT5
0 notes
Text
Vena [vFrame] Apple iPhone 6s / 6 Case [Aluminum Metal Frame] Ultra Slim Fit Hybrid TPU Bumper Case Cover for Apple...
Vena [vFrame] Apple iPhone 6s / 6 Case [Aluminum Metal Frame] Ultra Slim Fit Hybrid TPU Bumper Case Cover for Apple…
Real Aluminum Vena vFrame is designed using high quality aluminum to provide the exclusive premium look. The beveled volume and power buttons are made of real aluminum and are carefully crafted to maintain the same great tactile feedback from your device’s buttons. Hybrid Dual Layer Build Vena vFrame has a dual layer build wrapping the corners of your Apple iPhone 6 (4.7″) with premium aluminum…
View On WordPress
#6#6S#Aluminum#android smartphone accessories#Apple#apple wireless charger#bose audio#bose earphones#bose headphones#Bumper#case#Cover#Fit#Frame#hybrid#iPhone#iphone accessories#iphone aluminum case#iphone cases#iphone covers#iphone earphones#iphone headphones#iphone screen protectors#iphone silicone case#metal#portable backup battery#portable charger#portable speakers#samsung memory card#samsung wireless charger
0 notes
Text
UBD Gelar Workshop bertema "membangun rumah hanya 7 hari"
UBD Gelar Workshop bertema “membangun rumah hanya 7 hari”
Palembang (JettNews) – Universitas bina darma palembang gelar Workshop bersama Indonesia dan Malaysia forum bisnis dan exhibition VFrame dengan tema “membangun rumah hanya 7 hari”di aula lantai 6 universitas bina darma, Rabu (22/2).
Rektor Universitas Bina Darma Buchori Rahman dalam sambutanya menyambut baik workshop ini juga sekaligus salah satu bentuk upaya mensukseskan program pemerintah…
View On WordPress
0 notes
Text
Transmediale 2019
The transmediale 2019 was a festival with out a topic. The organizers wanted to leave it open this year avoiding to give a specific direction or tone for emerging thoughts and content. The theme of the festival program was built around the question of: What moves you? Emotions and feelings were examined in talks, workshops and performances to open up discussion about the affective dimensions of digital culture today.

Transmediale at Haus der Kulturen der Welt
Of course it is impossible to attend all of the program, so I console my self with the knowledge that part of the program I missed i can usually catch later on transmediales YouTube channel where they publish most of the talks and panels.
Following some of my transmediale 2019 highlights:
Workshop(s)
I had the chance to get to Berlin a bit earlier to attend Adam Harvey’s (VFRAME) and Jeff Deutch (Syrian Archive) workshop Visual Evidence: Methods and Tools for Human Rights investigation. The workshop centered around the research and development of tools to manage a huge amount of video material from conflict areas, specifically Syria. The Syrian Archive collects material intending to documented and archive evidence for possible future use in trying to hold war criminals accountable for their actions. The challenge for human rights activists working with footage from Syria is that there is a massive amount of material. Manually sorting out the relevant videos for archiving is just requiring too much time. To tackle this challenge the Syrian Archive started a collaboration with artist Adam Harvey to develop computer vision tools aiding the process of finding relevant material among hours of footage. Videos often filmed by non professionals in violent, often life threatening, situations (a very specific video aesthetic which is relevant when training object recognition).

Adam Harvey describing the process of developing object recognition tool.
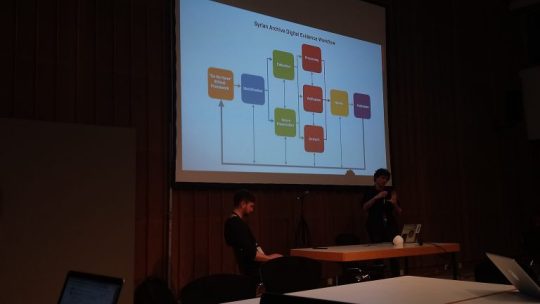
Jeff Deutch describing the workflow of verifying evidence.
After learning about the archiving challenges of human right activists Adam took us trough the process of developing VFRAME (Visual Forensics and Metadata Extraction) which is a collection of open source computer vision tools aiming to aid human rights investigations dealing with unmanageable amounts of video footage. The first tool developed was simply per-processing frames for visual query. A video was rendered to one image showing a scene selection. This helped the activist to see the different scenes of a video in one gaze enabling them to process the information of a several minute long video in just 10 seconds. Now the workflow was much faster, yet it would still take years to process all of the video footage. What the activist were looking for in the videos was evidence of human right abuses, children rights abuses, and also identifying illegal weapons and ammunition. To automatize some of the work load, as a first step, Adam and the Syrian Archive has started an object recognition training of a neural network to identify weapons and ammunition. Adam used the example of A0-2.5RT cluster munition as an example to talk about the challenges they had.
Adam showed us a tool that they have been using for annotating objects, but it has been time consuming and a greater challenge was not having enough images to actually train the network. While working with the filmed footage the activist had learned to see patterns how the object (in this case A0-2.5RT) was appearing ( eg. environments, light conditions, filming angel etc.). Hence one successful solution was to synthesize data, in other words to produced 3D renderings of the ammunition simulating the aesthetics of the documented videos. The 3D renderings with various light conditions, camera lenses, filming angels provides the neural network with additional data for training. Adam also showed experiments with 3D prints of the A0-2.5RT, but according to him it is way more effective to use the photorealistic 3D renderings.

3D print: part of a A0-2.5RT cluster ammunition.
In a panel discussion later during the conference (#26 Building Archives of Evidence and Collective Resistance ) Adam was asked how he felt about developing tools that could possible be missed used. From Adams perspective he was actually appropriating tools that are already misused. VFRAME provides a different perspective for use of machine vision in a very specific context. During the Q&A the issue of bias data sets was questioned. With the context of this case study Adam made it clear that bias actually needs to be included in the search of something very specific. For him the training images needs to capture the variations of a very specific moment, for him bias included e.g. the camera type that is often used (phone), height of the person filming (angel) the environment where the ammunition is often found (sometimes on the ground, or someone holding it in their hands etc.). When trying to detect a very specific object in a very specific type of (video) material, then bias is actually a good thing. Both during the panel and in the workshop it was made clear that the processing large amounts of relevant video material and talking with the people capturing the material on site was very valuable when creating the synthesize 3D footage to train object recognition.
After Adams presentation of the VFRAME tools the workshop continued with Jeff Deutch taking us through processes of verifying the footage. Whereas machine learning is developed to flag relevant material for the activists, a important part of the labor is still manually done by humans. One of the important tasks is to connect the material together validating the date so it can be used as evidence. Jeff us a couple of examples how counter narratives to state news was confirmed by using various OSINT(Open source intelligence) tools such as revers image search (google, tincan), finding Geo-location (twitter, comparing objects and satellite images from Digital Globe), verifying time (unix time stamp), extracting metadata (e.g. Amnesty’s Youtube DataViewer), and collaboration with aircraft spot organizations.
The workshop and the panel were extremely informative in terms of understanding workflows and how machine vision can be used in contexts outside surveillance capitalism. The workshop had also a hands on part in which we were to test some of the VFRAME tools. Unfortunately the afternoon workshop was way to short for this and some debugging and set up issues delayed us enough to be kicked out from the workshop space before we could get hands on trying the tools.
After the transmediale I had the chance to visit the Ars Electronica Export exhibition at DRIVE – Volkswagen Group Forum. There the VFRAME was exhibited among other artworks. It is definitely one of these projects which mixes artistic practice with research and activism emphasizing the relationship between arts and politics. Another transmediale event that related to the workshop and panel mentioned earlier was a very emotional # 31 book launch of Donatella Della Ratta’s Shooting a Revolution. Visual Media and Warfare in Syria. In the discussion there was several links between her ethnographic study and the work of the Syrian Archive.

VFRAME exhibited at the Ars Electronica Export exhibition
Talks

Opening talk by Kristoffer Gansing, Artistic Director of transmediale.
In the #01 Structures of Feeling- transmediale Opening there was some interesting references to machine vision. New York based artist Hanna Davis was presenting her current work generating emotional landscapes experimenting with generative adversarial networks and variational autoencoders. Basically the landscapes (e.g. mountains or forests) was tagged with emotions (anger, anticipation, trust, disgust, sadness, fear, joy, and surprise or ‘none’) buy Crowdflower platform workers (similar to Amazon Mechanical Turk). Then machine learning algorithms were feed with the data set to generate “angry forests” or “sad mountains” etc. The 20 minute talk was definitely a teaser to look more closely into Hannah’s work. Next up was Anna Tuschling who mentioned a number of interesting examples. With a background in psychology she talked how we have tried to understand and represent emotions coupling e.g. neurologist Duchenne de Boulogne’s work in the 1800s with facial recognition technology and applications such as Affectiva (“AFFECTIVA HUMAN PERCEPTION AI UNDERSTANDS ALL THINGS HUMAN – 7,462,713 Faces Analyzed”) and Alibaba Group’s AliPay’s ‘Smile to Pay’ campaign in China.

Anna Tuschling taking about neurologist Duchenne de Boulogne’s work

Structures of Feeling – transmediale 2019 opening panel with Hanna Davis, Anna Tuschling and Stefan Wellgraf, moderated by Kristoffer Gansing.
From the #12 Living Networks Talk, Asia Bazdyrieva’s & Solveig Susse’s Geocinema awoke my interest. They considers machine vision technology such as surveillance cameras, satellite images an cell phones together with geosensors an cinematic apparatus sensing fragments of the earth. The # 15 Reworking the Brain Panel with Hyphen-Labs and Tony D Sampson was not quite what I had expected, yet Sampson’s presentation connected with the readings we done on the non-conscious (N. Katherine Hayles, Unthought). He reflected on how brain research has started to effect experience capitalism (UX Industry) asking “What can be done to a brain?” and “What can a brain do?”. In the Q&A Sampson revealed a current interest in the non-conscious states of the brain while sleep walking which I found intriguing.

NeuroSpeculative AfroFeminism (NSAF) by Hyphen Labs

Nonconscious debate Hayles/Sampson.
In my opinion one of the best panels was #25 Algorithmic Intimacies with !Mediengruppe Bitnik and Joanna Moll, moderated by Taina Bucher. The panel discussed the deepening relationship between humans and machines and how it is mediated by algorithms, apps and platforms. The cohabitation with devices we are dependent on was discussed through examples of the artists works. !Mediengruppe Bitnik presented three of their works Random Darknet Shopper, Ashley Madison Angels and Alexiety. All of the works asked important questions about intimacy, privacy, trust and responsibility. The Ashley Madison Angels work bridged well with Joanna Molls work the Dating Brokers illustrating how our most intimate data (including profile pictures and other images) are shared among dating platforms or sold forward capitalizing on our loneliness. Ashley Madison is a big dating platform that is specially marketed to people who feel lonely in their current relationship (marriage), so it encourages adultery. In 2015 the Impact Team hacked their site, while the company did not care too much about the privacy of their customers, the hackers dumped the breach making it available for everyone. The dump was large containing a huge amount of profiles, and also source code and algorithms. It became an unique chance for journalist and researchers to understand how such services are constructed. Among others !Mediengruppe Bitnik was curios to understand how our love life is orchestrated by algorithms. What was discovered from the breach was an imbalance between male and female profiles. The service lacked female profiles and due to this they had installed 17.000 chat bots. !Mediengruppe Bitnik thought that there would be amazing AI developments in creating these bots. They were to have conversations with clients from different cultures, in various languages about a number of topics. But it turned out to be very basic chat bots, with 4-5 A4 pages of erotic toned hook up lines. A well choreographed flirting was enough to keep up the conversation and the client paying for chat time. In the Ashley Madison Angels video installation the pick up lines are read by avatars wearing black “Eyes Wide Shut” type of venetian masks. After the talk I asked Carmen ( !Mediengruppe Bitnik ) about the masks. She told me that they were a feature provided by the service, as a playful joke to add on your profile image. Actually all the bots profile images were masked with the feature so that the profile images could not be run through e.g. googles revers image search to confirm abuse of profile images. In the end the chat bots were using 17000 stolen, maybe slightly altered id’s of existing people. Carmen also noted that the masks would not work anymore whereas google can now recognize a images as a duplicate using just parts of the image/face. In connection to the Ashley Madison bots also the army of human CHAPTA solvers was mentioned in the talk. There is a effective business model exploiting cheap labor to solve CHAPTAS for bots almost in real time.

!Mediegruppe Bitnik talking about their work Ashley Madison Angels.
Joanna Moll continued talking about the “dating business”. Together with the Tactical Tech Collective she has researched in how dating profile data is shared and sold by data brokers. For her work Dating Brokers she bought one million profiles for 136€. These profiles (partly anonymised) can be browsed through using the interface she created. Additionally a extensive report on the research part of the project can be read in The Dating Brokers: An autopsy of online love. The report describes common practices of so called White Label Dating. While no one wants to be the first person registering onto a dating platform there is a common practice to either share data among groups of companies. When agreeing to the user terms ones profile can be shared among “partners” that can reach up to 700 companies having legal access to the data. Additionally the profiles are sold in bundles like the one million profiles Joanna bought from the dating service Plenty of Fish. The data set included about 5 million images, and I would not wonder if these images end up fed into neural networks hungry for faces to recognize.

Joanna Moll reporting on her research for The Dating Brokers: An autopsy of online love.

Dating profiles can be shared among partners, this means your data can legally be breached up to 700 companies.
There was several interesting talks about the commons, machine learning, affect and other topics, yet the talks described here more or less relate to my research.
Written by Linda Kronman - Full text here
0 notes
Last Seen Blogs

azemrei
azem

eukoz
𝘌𝘶𝘬𝘰𝘻


maple-and-pie
Always time to be spooky

kissingthebluedark-blog
my drug is my baby