#like you CAN call it two diff versions but it’s the same script so no u can’t. what’s the crossover event. it’s the same THING
Text
actually i’m gonna speak on the “versions” of newsies for a min
the only two “versions”. are broadway and 92sies. we do like actually know that right. because those are two different plot lines with different events and entirely different songs.
west end? not a version. it’s a production. it’s new staging and orchestrations which is different for us, and certainly fresh character interpretation, but at the end of the day that’s what it is— interpretation.
so the “livesies and west end are diff versions” (which already doesn’t make sense because then wouldn’t bway and tour be slightly different as well with that argument) is kind of. just. a weird separation in the name of—speaking as a writer here—maybe “keeping the work we already have”. like oh i wrote racer this way but now he’s this way.
guess what! doesn’t matter. it’s a character. there’s no- like no version besides bway script and 92sies script. what you draw character from are the actual words spoken- and yeah, staging will influence you bc if it doesn’t that’s weird, but it’s not a different character. are we. do you get me.
mainly my worry is othering, and personally this fandom cannot afford to do that w/ michael’s jack kelly, because then i’ll become violent and no one wants that :/ a new person playing jack doesn’t make it an other, different jack it just makes it yet another millionth interpretation of jack. yk. like do we get what i’m saying here
#like you CAN call it two diff versions but it’s the same script so no u can’t. what’s the crossover event. it’s the same THING#and no this doesn’t only apply to like canon au thoughts. tbh. bc why would it#at the end of the day it’s still YOUR interpretation of what you watched actually. so Your racer isn’t btc’s Or josh barnett’s.#it’d be an interp of one or both. yk#anyway good morning#fizz freaks#newsies#newsies uk#newsies live#LIKE IF PPL SAW THE JAPAN TOUR. yk? interpretation. we’ve been thru this before it’s just now a production that’s like#more accessible to english speakers. i’m js#newsies 1992#these r just my thoughts as a person actively working in live theater !!
73 notes
·
View notes
Text
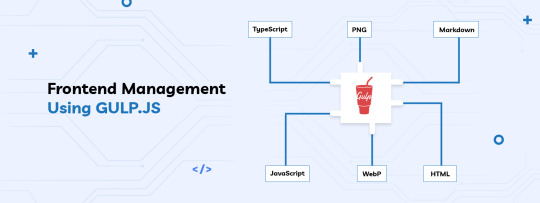
Frontend Management Using GULP.JS
Originally Posted On...
Gulp is dealing with rendered HTML content, compressing and minified assets, compiling Sass to CSS code, deploying files from development to the production side, automating the most frustrating tasks, etc.
Gulp is the task manager that helps with developing applications. It allows specifying tasks that for example process files or run different programs. The commands can be easily chainable which results in better re-usability. There can also be specified dependency between the commands.
What you should know?
It is a command Line toolkit (CLI based tool) so you should be familiar with the terminal. Also you should have knowledge of basics of javascript, installed node.js and also install Node Package Manager (NPM).
Why use Gulp.js?
Gulp is dealing with rendered HTML content, compressing and minified assets, compiling Sass to CSS code, deploying files from development to the production side, automating the most frustrating tasks, etc.
Gulp is the task manager that helps with developing applications. It allows specifying tasks that for example process files or run different programs. The commands can be easily chainable which results in better re-usability. There can also be specified dependency between the commands.
Introduction :
Gulp is a task runner toolkit to automate & enhance your workflow. It is used to automate slow, repetitive workflows and compose them into efficient build pipelines in web development.
Installing Gulp:
To check Node and NPM are installed in the machine or not run the following command:
Node –version
npm –version
Install the gulp command line globally.
$ npm install --global gulp-cli
Create a project folder and navigate to it.
$ mkdir sample_project
$ cd sample_project
$ npm init
$ npm install --save-dev gulp (It will install the gulp package in your dev dependency)
$ gulp –version (verify your gulp version)
Create a “gulpfile.js” (or Capitalized Gulpfile.js).
-Create a file named gulpfile.js in your project folder.
Role: The file called gulpfile.js holds the specification of tasks It will be run automatically when you run the ‘gulp’ command. It is written in JavaScript and therefore it is easy to use different libraries
Note: if you are using Typescript, rename to gulpfile.ts and install ts-node module and same for babel, rename to gulpfile.babel.js and install @babel/register module.
What are Tasks in a gulp:
The task is asynchronous javascript functions to execute it. There are two types of tasks, public tasks which allow you to execute tasks using the gulp command over all projects, and private tasks are made to be used internally, it looks like other tasks but the end user can’t execute them independently.
To register as a public task it should be exported.
Series() & parallel() are the composing methods that allow any number of task functions. They will execute tasks as per their names in series and parallel respectively.
src() and dest() are used to interact with files in your computer to read files from the source and end or put files to a destination within the stream. Here src can be operated in three diff modes: streaming, buffering, and empty.
pipe() is there to chain transform files.
Note: Before to put at destination we can apply operation on files . There are many modules available to make it easy. For example uglifyJS is a javascript parser, composer, beautifier toolkit, ‘rename’ is to change file name on production side.
For example:
const { src, dest } = require('gulp');
const uglify = require('gulp-uglify');
const rename = require('gulp-rename');
exports.default = function() {
return src('src/*.js')
.pipe(src('vendor/*.js'))
.pipe(dest('output/'))
.pipe(uglify())
.pipe(rename({ extname: '.min.js' }))
.pipe(dest('output/'));
}
Here all js files will be minified and renamed by filename.min.js and stored in the/dest folder. GLOB: it is a string literally used to match file paths.
For example:
‘src/*.js’ : will consider all .js files available in the src folder.
'scripts/**/*.js'’ : will consider all .js files in /script folder and in sub folder too.
['scripts/**/*.js' ’: '!scripts/vendor/special**'] : from the script folder it will consider all .js files except the folder /vendor.
Conclude: Gulp toolkit is very useful for web developers to make it easy on the production side of web development. Still, many features are there which will be discussed in part-2
Get In Touch With Us To Know More...
0 notes
Photo

#TwinPeaks’: David Lynch Talks About Reviving the Iconic Series
"Cable television is a new art house, and it’s good that it’s here," says Lynch, who talks Showtime, inspiration and the red room.
He dressed like a G-man.
When he arrived for his interview with Variety, David Lynch wore a black suit, a white shirt, a black tie, and wingtips. His hair was styled the same way as always, but what had once been jet black was now mostly white. The only pop of color on Lynch was incongruous; it emerged when he sat down for the interview. As he gestured while talking, a yellow plastic watch peeked out from the sleeve of his white shirt. It was the only item that didn’t make him look like his “Twin Peaks” character, FBI official Gordon Cole.
Lynch was as affable an interviewee as I’ve ever come across, but his answers were concise: His art may rely on the creation of a mysterious atmosphere, but in talking about his return to the world of “Twin Peaks,” he couldn’t have been more unequivocal and direct. When he disagreed with the premise of a question, which was not an uncommon occurrence, he did so in the friendliest possible way. The single longest answer — and it was an impassioned one, at that — revolved around his thoughts on the state of non-tentpole cinema.
The director is nothing if not attentive; he actually closed his eyes at several points in order to focus as completely as he could on his answers. At times, he would knead his hands together as he spoke, eyes closed, focused inward. That intensity seemed appropriate, given that he spoke about how his work is often inspired by images that float up from the deepest parts of his subconscious. Lynch doesn’t take credit for the existence of the strange moods and disjunctive tableaus that fill his work; he says he just channels what he sees, and puts that out into the world.
One more unequivocal thing: Lynch hates the idea of spoiling the experience of watching one of his creations. So in the conversation below, which was excerpted in this feature story on the drama’s return, there are no details about individual episodes of the “Twin Peaks” return, which arrived May 21 on Showtime.
When you’re on the set, are you a director who wants to have a very exact rendition of what you’ve envisioned?
Yes.
Down to line readings?
Yeah, it has to be very specific, or it has to be something that works just as well. If it doesn’t work in the line of things, then you have to talk and adjust things.
Are you looking for the actors to collaborate with you and bring you an idea that they think might execute your vision?
Not really. You know, it’s mostly — they tune into pretty much to what it is, and if they don’t, it’s pretty quick to explain the thing. Then there’s some that are good and some that are great line readings. You just keep working until it feels correct to you.
Kyle MacLachlan has said that you have such a close working relationship that you often don’t even need to speak. Is that something that develops over time?
Yeah, I think so, but I think I’ve known a lot of people as long as Kyle. We’re real close and sort of on the same page. So if I have any kind of doubt, he’ll pick up on that and think about it and he’ll know why. He’ll play back in his head something and say, “Well, off we go again.” We don’t have to say anything.
Because he’s so in tune with what you’re going for?
Yeah, the character is a certain way and Kyle knows what that way is, so he knows if he veered off at any time.
When you were envisioning this return to “Twin Peaks” — actually, I’ll back up a bit. In a more general way, is it images that come to you?
No, an idea holds everything, really, if you analyze it. It comes in a burst. An idea comes in, and if you stop and think about it, it has sound, it has image, it has a mood, and it even has an indication of wardrobe, and knowing a character, or the way they speak, the words they say. A whole bunch of things can come in an instant.
When you began to consider returning to “Twin Peaks,” did you receive flashes of those things, and then it was a matter of finding ways to join them together?
Yeah. I work with Mark Frost, so we talk and we get ideas. We kick around those ideas, and they get more and more specific, and something starts talking to you, and they know the way they want to be, and then there it is.
When you say “they know,” you’re saying the characters know?
No, the ideas. You pick up on the way they want to be. That’s what I always say, it’s like fish. You don’t make the fish, you catch the fish. It’s like, that idea existed before you caught it, so in some strange way, we human beings, we don’t really do anything. We just translate ideas. The ideas come along and you just translate them.
And transmit them to other people.
Yeah. You may build a thing, and then eventually it gets finished, and you show it.
What were lessons learned from the first two seasons of “Twin Peaks” that you wanted to carry forward into this new experience with it?
For me, I wanted to be involved with all the writing and I wanted to direct all of them. Not that other directors didn’t do a fine job. But, it’s passing through different people, it’s just natural that they would end up with [something] different than what I would do. That’s what I learned.
In a perfect world, would you have loved to have directed all of the first two seasons?
Oh yeah.
Showtime first announced this project in October 2014, and now here we are in 2017, so it’s been a very…
Long time. And we were writing before that [he and Frost began collaborating again in 2012].
When you sat down with Mark again and decided to do this, what was it that made you think, “Yeah, we definitely need to do that.” You had an accumulation of ideas?
No.
No pile of fish that you’d caught?
No. It was 25 years later, which was [a time frame mentioned] in the original thing, and that’s one thing. Another is a love for the world and the people in the world. Then, as soon as you start to focus on that, that’s when ideas start coming.
The experience of working with ABC, do you look back fondly on that?
Sure. I mean, I didn’t really know that side of it. I just remember loving the pilot. The pilot to me is the thing. That sets the mood and the characters and the feel of “Twin Peaks.”
I can actually remember the quality of the light in the room the day “Twin Peaks” premiered, because it’s so imprinted on me. Watching it again, that atmosphere in the pilot is still so effective and mysterious. I understand that the ideas come to you and you want to transmit them, but are you also trying to access an emotional state in yourself, or reproduce that in the viewer?
No, it comes with the idea and … emotion is a tricky thing. A bunch of elements that need to come together to conjure that feeling and have it go over into other people. I guess, like Mel Brooks said, “If you don’t laugh while you’re writing the thing, the audience isn’t going to laugh.” If you don’t cry or feel it while you’re doing it, it’s probably not going to translate.
At times, “Twin Peaks” is also a very funny show.
It’s a bunch of things. That’s the thing. It’s like life, actually — you could be crying in the morning and laughing in the afternoon. It’s the way it is.
Were you surprised when it came out how popular it was?
Yeah. You know, TV executives, I guess they worry, so they have some tests they do on shows, especially a pilot. Apparently in those days, it took place in Philadelphia, and there was a room full of regular people. On a scale from one to 100, it did a 52. It didn’t do terribly, but they didn’t have really any idea. Something happened between that test screening and the air date. Something went in the air.
Showtime Gary Levine, who was at ABC then, talked about how it was held for mid-season — people in the media got to see it and some of the buzz started that way. The interest built over time, and people began to hear about before it came out.
People hear about lots of things.
But there were fewer things to hear about 27 years ago. There was a lot less TV being made.
That’s true.
Why was it important to revisit that “25 years later” time frame?
Well, I had a thing happen to me [during the making of the] pilot. A pilot is open-ended. But in case the pilot flops, they ask you to do a closed ending — they call it the European version. Partway through shooting the pilot, people would say, “Remember David, you have to do a closed ending.” I had zero interest in doing that and no time to do it anyway. No ideas. Mark was not having any ideas.
In the editing process, one evening about 6:30 p.m., I think — it was very nice weather. Warm, and it was a nice sun, low in the sky. Me and [editors] Duwayne Dunham and Brian Berdan went out into the parking lot from the editing room, and we were talking about something. I leaned up against the roof of a car, like this [he folds his arms out in front of him, as if resting on a car roof]. The roof was so warm, but not too warm. It was just a really good feeling, and into my head came the red room in Cooper’s dream. That opened up a portal in the world of “Twin Peaks.” A super important opening, and it led to [the idea that it] took place 25 years later — that dream.
Were you worried about what network the new season would end up at and how it would be received?
No. You see the thing is, there are plenty of things to worry about, but it’s so enjoyable. If nothing happens, it’s still okay. This whole trip has been enjoyable.
You and Mark did ended up settling on Showtime. Why was that?
Well, a lot of reasons, but the long and the short of it is now I’m really happy to work with Showtime and [CEO] David Nevins and [president of programming] Gary Levine and [executive] Robin Gurney and all the people there.
So you brought Showtime the entire script in one 400-page binder. What was it like talking about that with them, getting their feedback?
I think, if you asked 100 people to read something, you’d get 100 different things. Like they say, never turn down a good idea, but never take a bad idea. You stay true to the ideas and you can’t veer off from those things.
I talked to David and Gary from Showtime about the problems that occurred in April 2015, when you said you were going to step away from “Twin Peaks.”
What did they say?
David Nevins said that, once it was explained to him what you wanted, he thought you were making a reasonable and rational request to potentially be able to expand what you were doing. But it wasn’t fitting the normal pattern of what business affairs was used to. That’s where he thought the hitch happened.
Basically, that’s it.
And as soon as he could, he and Gary went over to your house and you all drank coffee.
Gary brought treats for me. Some cookies.
So in the main, what’s your relationship been like with Showtime?
Solid gold.
When you went into production and were shooting it, what were some of the most exciting parts of it?
Every day was exciting. Every day. It’s supposed to be that way. It’s like, this is a day you work with this character, and they do this, and it’s this is part of the story, so it should be exciting. It should be a really great feeling when you get it. Each day you try to get it. I always say, in the morning, you have a glass bridge that you’re supposed to cross. It’s so delicate, you wonder if it will break apart. As you go, it turns to steel. When you get [what you want], it’s a steel bridge. Getting it the way you want it to be, that’s a beautiful high, and it’s a high for everybody. It’s difficult to go home and go right to sleep. And it’s murder to get up in the morning.
Did you feel like you had a bit more freedom with Showtime? Although I know you’ve said that ABC didn’t really place too many limits on you in terms of Standards & Practices.
No, we pretty much did what we wanted to do. [We did] what the story wanted. You don’t think, “Oh, I can do this now.” The story tells you what’s going to happen.
Would you do another season?
I don’t know. You never say no. You don’t know what will happen. It depends on a lot of things.
When I think about Agent Cooper, I see him as an optimistic man. He seems like someone who is excited to meet the challenges of life. How much of who he is is reflective of who you are?
Well, I believe in intuition. I believe in optimism, and energy, and a kind of a Boy Scout attitude, and Cooper’s got all those things. I think a real good detective has those things. He’s got more intuition than more detectives, though.
Was he an Eagle Scout, though, like you?
Was Cooper an Eagle Scout? I never thought about it. I don’t know.
Well, that could be season four, then — a prequel. In the main, do you watch much TV?
I watch some news. I watch the Velocity Channel. It’s about cars. That’s my new love, this Velocity Channel and the different shows where they customize cars and restore cars. It’s pretty great. These car guys are real artists, some of them. Some of these cars are so beautiful.
Do you watch any scripted TV?
I loved “Breaking Bad” and “Mad Men.”
Are you still going to make feature films?
Feature films are suffering a kind of bad time right now, in my opinion, because the feature films that play in theaters are blockbusters. That seems to fill the theaters, but the art-house cinema is gone.
If I made a feature film, it might play in L.A. and New York, a couple of other places, for a week in a little part of a cineplex, and then it would go who knows where. I built [“Twin Peaks”] to be on the big screen. It will be on a smaller screen, but it’s built for the big screen. You want a feature film to play on a big screen with big sound, and utilize all the best technology to make a world.
It’s really tough after all that work to not get it in the theater. So I say that cable television is a new art house, and it’s good that it’s here.
“Twin Peaks” airs on Showtime Sundays at 9 p.m
link (TP)
2 notes
·
View notes
Text
LXC vs Docker: Why Docker is Better
So what, one may ask, is the difference between these VE’s and a traditional VM? Well, the main difference is that in a VE there is no preloaded emulation manager software as in a VM. In a VE, the application (or OS) is spawned in a container and runs with no added overhead, except for a usually minuscule VE initialization process. There is no hardware emulation, which means that aside from the small memory software penalty, LXC will boast bare metal performance characteristics because it only packages the needed applications. Oh, and the OS is also just another application that can be packaged too. Contrast this to a VM, which packages the entire OS and machine setup, including hard drive, virtual processors and network interfaces. The resulting bloated mass usually takes a long time to boot and consumes a lot of CPU and RAM.
Advantage: VE. So why haven’t VM’s already have gone the way of the dinosaur? The problem with VE’s is that, up to now at least, they cannot be neatly packaged into ready-made and quickly deployable machines – think of the flexibility and time saving offered by Amazon’s myriad AWS machine configs. Also, this means they cannot be easily managed via neat GUI management consoles and they don’t offer some other neat features of VM’s such as IaaS setups and live migration.
So the VE crowd is not unlike the overclockers and modders of the CPU and computer hardware universe – they extract more utility from the standard machine in the market. But doing so calls for advanced technical skills, and results in a highly customized machine that’s not necessarily guaranteed to be interoperable with others. Also, if you don’t know what you’re doing, you will royally mess up your machine.
What They Do
Think of LXC as supercharged chroot on Linux. It allows you to not only isolate applications, but even the entire OS. Its helper scripts focus on creating containers as lightweight machines - basically servers that boot faster and need less RAM. There are two user-space implementations of containers, each exploiting the same kernel features:
Libvirt, which allows the use of containers through the LXC driver by connecting to 'lxc:///'. This can be very convenient as it supports the same usage as its other drivers.
Another implementation, called simply 'LXC', is not compatible with libvirt, but is more flexible with more userspace tools. It is possible to switch between the two, though there are peculiarities which can cause confusion.
Docker, on the other hand, can do much more than this. Docker can offer the following capabilities:
Portable deployment across machines: you can use Docker to create a single object containing all your bundled applications. This object can then be transferred and quickly installed onto any other Docker-enabled Linux host.
Versioning: Docker includes git-like capabilities for tracking successive versions of a container, inspecting the diff between versions, committing new versions, rolling back etc.
Component reuse: Docker allows building or stacking of already created packages. For instance, if you need to create several machines that all require Apache and MySQL database, you can create a ‘base image’ containing these two items, then build and create new machines using these already installed.
Shared libraries: There is already a public registry (http://index.docker.io/ ) where thousands have already uploaded the useful containers they have created. Again, think of the AWS common pool of different configs and distros – this is very similar.
For a great list of Docker’s capabilities, see this thread on Stackoverflow: https://stackoverflow.com/questions/17989306/what-does-docker-add-to-just-plain-lxc
Popularity
If popularity were the only criteria for deciding between these two containerization technologies, then Docker would handily beat LXC and its REST tool, LXD. It’s easy to see why, with Docker taking the devops world by storm since its launch back in 2013. Docker’s popularity, however, is not an event in isolation, rather, the application containerization that Docker champions just happens to be a model that tech giants, among them Google, Netflix, Twitter, and other web-scale companies, have gravitated to for its scaling advantages.
LXC, while older, has not been as popular with developers as Docker has proven to be. This is partly due to the difference in use cases that these two technologies focus on, with LXC having a focus on sys admins that’s similar to what solutions like the Solaris operating system, with its Solaris Zones, Linux OpenVZ, and FreeBSD, with its BSD Jails virtualization system. These solutions provide OS containers for a whole system, which is achieved, typically, by providing a different root for the filesystem, and creating environments that are isolated from each other and can’t share state.
Docker went after a different target market, developers, and sought to take containers beyond the OS level to the more granular world of the application itself. While it started out being built on top of LXC, Docker later moved beyond LXC containers to its own execution environment called libcontainer. Unlike LXC, which launches an operating system init for each container, Docker provides one OS environment, supplied by the Docker Engine, and enables developers to easily run applications that reside in their own application environment which is specified by a docker image. Just like with LXC, these images can be shared among developers, with a dockerfile, in the case of Docker, automating the sequence of commands for building an image.
The Docker user base is large and continues to grow, with ZDNet estimating the number of containerized applications at more than 3.5 million and billions of containerized applications downloaded using Docker. Linux powerhouses such as Red Hat and Canonical, the backers of Ubuntu, are firmly on the Docker bandwagon, as are even bigger tech companies like Oracle and Microsoft. With such adoption, it’s likely Docker will continue to outstrip LXC in popularity, though system containers like LXC have their place in virtualization of traditional applications that are difficult to port to the microservice architecture that’s popular these days.
Tooling and CLI
LXC tooling sticks close to what system administrators running bare metal servers are used to, with direct SSH access allowing the use of automation scripts your team might have used on bare metal or VMs running on VirtualBox and other virtualized production environments. This portability makes migrating any application from a Linux server to running on LXC containers rather seamless, but only if you are not using containerization solutions already. The LXC command line provides essential commands that cover routine management tasks, including the creation, launch, and deletion of LXC containers. LXD images can be obtained from the built in image remotes, supplying an LXD remote, or manually importing a Linux image from a tarball. Once you’ve created and launched a container from an image, you can then run Linux commands in the container.
Docker’s tooling is centered around the Docker CLI, with commands for listing, fetching, and managing Docker images. A public image registry, Docker Hub, provides access to a variety of images for commonly used applications. Notably, you can also download OS images, which lets you run, say, a Linux system in a Docker container. This is functionality that you would typically associate with LXC containers, which allow you to run OS systems without needing a VM. However, Docker containers aim to be even lighter weight in order to support the fast, highly scalable, deployment of applications with microservice architecture.
Ecosystem and Cloud Support
With backing from Canonical, LXC and LXD have an ecosystem tightly bound to the rest of the open source Linux community. The entire range of tools that work on VMs and Linux systems tend to work for LXC as well, after all, the containers on a LXC host system have Linux OS instances running within them. This means that your team won’t need to find an additional vendor for LXC specific tooling, since the tools you already use on Linux will work when your applications run on LXC containers. For managing your LXC containers, which may live on a single server or potentially thousands of nodes, the LXD hypervisor provides a clean REST API that you can use. LXD is implemented in Go, to ensure high performance and networking concurrency, with excellent integration with OpenStack and other Linux server systems.
In contrast, Docker requires much more specialized support and has spawned off a sizable ecosystem, since the application container deployment model that it seeks to achieve is such a novel concept in the timeline of software deployments. The application container space is younger than the VM scene, and this results in a lot more fluidity. Docker now runs on Windows, and is supported by major cloud providers such as AWS, IBM, Google, and Microsoft Azure.
Docker’s ecosystem includes the following set of tools:
Docker Swarm - An orchestration tool to manage clusters of Docker containers
Docker Trusted Registry - A private registry for trusted Docker images
Docker Compose - A tool for launching applications with numerous containers that need to exchange data.
Docker Machine - A tool for creating Docker-enabled virtual machines.
There are more tools that help to fill out the entire stack, providing specialized functionality to support your Docker deployments. Docker Hub, Docker’s official open image registry, contains over 100,000 container images from open source contributors, vendors, and the Docker community.
Ease Of Use
Docker and LXC both provide ample documentation, with helpful guides for creating and deploying containers. Bindings and libraries exist for languages such as Python and Java, making it even easier for developer teams to use. When comparing the two technologies, however, Docker’s ever-growing ecosystem will take much more to manage. Docker might have become the standard for running containerized applications, with tools like Kubernetes and Docker Swarm providing the orchestration, however, the ecosystem comes with additional complexity.
Part of this has to do with Docker’s key innovation of single-process containers, over and above the standard multiprocess containers that LXC provided. When Docker introduced this innovation, it inevitably led to downstream complexity for teams porting over traditional applications to a non-standard operating system environment. A lot more planning, architecture decisions and scripting to support applications has to be done.
With LXC, a large part of this complexity is avoided since LXC runs a standard OS init for each container, providing a standard Linux operating system for your apps to live in. As a result, migrating from a VM or bare metal server is often easier to do if you are moving to LXC containers, unlike if you want to move to Docker containers. On the other hand, Docker’s approach makes working with containers easier for developer since they don’t have to use raw, low-level LXC themselves. This split between a systems admin and developer focus continues to characterize adoption of these tools.
Related Container Technology
As alluded to above, the world of containers is particularly dynamic, and involves a lot of innovation both around LXC, Docker, as well as alternative containerization technologies. What’s considered standard practice today can become old and substandard fairly fast. This is why you want to be aware of the bigger world of virtualization and containerization. These are some of the container technologies to watch:
Kubernetes - Drawing from Google’s experience of running containers in production over the years, Kubernetes facilitates the deployment of containers in your data center by representing a cluster of servers as a single system.
Docker Swarm - Swarm is Docker’s clustering, scheduling and orchestration tool for managing a cluster of Docker hosts.
rkt - Part of the CoreOS ecosystem of containerization tools, rkt is a security minded container engine that uses KVM for VM-based isolation and packs other enhanced security features.
Apache Mesos - An open source kernel for distributed systems, Apache Mesos can run different kinds of distributed jobs, including containers.
Amazon ECS - Elastic Container Service is Amazon’s service for running and orchestrating containerized applications on AWS, with support for Docker containers.
Conclusion
LXC offers the advantages of a VE on Linux, mainly the ability to isolate your own private workloads from one another. It is a cheaper and faster solution to implement than a VM, but doing so requires a bit of extra learning and expertise.
Docker is a significant improvement of LXC’s capabilities. Its obvious advantages are gaining Docker a growing following of adherents. In fact, it starts getting dangerously close to negating the advantage of VM’s over VE’s because of its ability to quickly and easily transfer and replicate any Docker-created packages. Indeed, it is not a stretch to imagine that VM providers such as Cisco and VMware may already be glancing nervously at Docker – an open source startup that could seriously erode their VM profit margins. If so, we may soon see such providers also develop their own commercial VE offerings, perhaps targeted at large organizations as VM-lite solutions. As they say, if you can’t beat ‘em, commercially join ‘em.[Source]-https://www.upguard.com/articles/docker-vs-lxc
Beginners & Advanced level Docker Training in Mumbai. Asterix Solution's 25 Hour Docker Training gives broad hands-on practicals.
0 notes
Text
An Overview of What's Coming in Vue 3
At the time of this writing, Vue 3.0 is at its 10th alpha version. Expect a faster, smaller, more maintainable, and easier to use version of the Vue you know and love. You can still use Vue via a script tag and your Vue 2.x code will continue to work. But you can start playing with the alpha version of Vue 3.0 here and we’re going to get into some of what v3 is offering.
Among other things, there’s a new API for creating components. It doesn’t introduce new concepts to Vue, but rather exposes Vue’s core capabilities like creating and observing reactive state as standalone functions. This is ultimately useful to Vue developers of all levels.
Options API and Composition API
In Vue 2, components are created with the object-based Options API. Vue 3 adds a set of APIs, referred to as the Composition API, which is function-based. This is primarily to address two issues that Vue 2 ran into for very large projects.
In large components that encapsulate multiple logical tasks, you want to group code by feature, but the nature of the Options API is that such code gets split up (among lifecycle hooks and so on), negatively affecting readability. Secondly, you want to be able to reuse logic in large-scale projects, and in Vue 2, solutions like mixins don’t address either issue very well.
Vue 3 seeks to kill both birds with one stone by exposing a new API. This API will live alongside the Options API, not replace it. This means that you can go on building components in the way that you’re used to without encountering any problems. But, you can also start building with the Composition API, which provides more flexible code organization and logic reuse capabilities as well as other improvements.
Even if the problems it specifically addresses are not pertinent to you, the new API has clearly had a lot of thought go into it to push Vue forward as a framework, for instance, by reducing the extent to which Vue operates “magically” behind the scenes.
— Sorry to interrupt this program! 📺
If you're interested in learning Vue in a comprehensive and structured way, I highly recommend you try The Vue.js Master Class course by Vue School. Learning from a premium resource like that is a serious investment in yourself.
Plus, this is an affiliate link, so if you purchase the course you help Alligator.io continue to exist at the same time! 🙏
- Seb, ✌️+❤️
Composition API
The Composition API is available now as a plugin for Vue 2 so you can try it out. It will be shipped baked-in in Vue 3.
In Vue 2 reactivity was achieved through the getters and setters of Object.defineProperty. This caused some limitations which you’ve already probably experienced (e.g.: updating an Array by index). In Vue 3, reactivity is accomplished through proxies, a feature that was introduced in JavaScript ES6.
You need not have a Vue instance to use the new reactivity API. It offers standalone APIs which allow you to create, observe, and react to state changes.
You would first import { reactive } from 'vue'. Then, you could create an object in the following way:
const state = reactive({ count: 0 })
You’ll have access to APIs that will allow you to dynamically inject component lifecycle hooks into a Vue instance.
The lifecycle registration methods can only be used in the setup() method which is the entry point where all the composition functions are called. For instance:
import { onMounted } from 'vue' export default { setup() { onMounted(() => { console.log('component is mounted.') }) } }
Functions that use these APIs can be imported into a component, allowing the component to do multiple logical tasks with reusable and readable code.
TypeScript
The composition API also offers better TypeScript support. It’s supposed to result in better type inferences with bindings returned from setup() and props declarations used to infer types.
Component code using TypeScript and JavaScript will look largely identical and TypeScript definitions benefit JavaScript users as well, say, if they use an IDE like Visual Studio Code.
View Declaration
Vue 2 supports templates as well as render functions. You don’t need to know an awful lot here except that Vue 3 continues to support both while optimizing rendering speed (such as by speeding up diff algorithms that operate under the hood so that Vue knows what needs to be re-rendered).
Faster
Virtual DOM has been rewritten from the ground-up to make for faster mounting and patching.
Compile-time hints have been added to reduce runtime overhead. This means skipping unnecessary condition branches and avoiding re-renders. Static tree and static prop hoisting means entire trees and nodes can skip being patched. Inline functions (like in a handler for a component in a template) won’t cause unnecessary re-renders.
You’re going to get a proxy-based observation mechanism with full language coverage and better performance. Instance properties will be proxied faster using native Proxy instead of Object.defineProperty like before.
You can expect up to 100% faster component instance initialization with double the speed and half the memory usage. 🏎️🏎️🏎️
Smaller
Vue 3 is also smaller.
It is tree shaking-friendly. Tree shaking refers to shaking off unused code. The core runtime has gone from ~20kb in size, gzipped, to ~10kb, gzipped.
The size of the Vue bundle increases with each new feature but, by providing most global APIs and Vue helpers as ES module exports, Vue 3 makes more code tree shakeable, even template code.
Coherence
Libraries like Vue Router and test-utils will be updated to line up with the new Vue. Vue now has a custom renderer API (similar to React Native for those who want to use it to create renderers for mobile or other host environments.
Conclusion
There is a ton to look forward to with Vue 3 with more like Portals that couldn’t fit in this short post. The new Composition API moves us towards an all around better Vue. An exact release date is not set but it’s coming soon. Get a head start now!
via Alligator.io https://ift.tt/2RdfYbt
0 notes
Text
Overlord: Saving Private Ryan Meets Resident Evil Meets Captain America!
Overlord is Saving Private Ryan meets a Resident Evil video game meets Captain America: The First Avenger. And I mean that in very specific and detailed ways.
The WWII movie is about a unit of the 101st Airborne being parachuted into Normandy the night of the D-Day invasion (the invasion being Operation Overlord, hence the title of the movie). Their mission is to take down one radio tower, built on the ruins of a church, that being destroyed will allow air cover for the beach landings, scheduled to start in just a few hours. The platoon suffers during the landing, and only five of them survive to carry out the mission.
This part of the movie is, of course, Saving Private Ryan. The captain’s landing craft got shot up on Omaha Beach, many men dying; the airplane gets shot up over Normandy, many men dying. The men hastily exit the landing craft and make their way up the beach, the men hastily exit the aircraft and fall into Normandy. Many men die once they’re on the beach, men die once they’ve parachuted, and their bodies hang from trees, like the condemned at a gallows. (In a moment calling back to Barry Pepper’s sniper in Ryan, the sniper of the 101st Airborne platoon even says that if you got him to Berlin, he could shoot Hitler in the head and the war would be over. It’s nearly the same quote, though Saving Private Ryan’s dialogue was written much better.)
[SPOILERS follow. If Saving Private Ryan meets Resident Evil meets Captain America: The First Avenger sounds like your kind of thing, go see it and come back here for the discussion.]
The entire point of this part of the movie is to photocopy a scene from Private Ryan, and then to give it some kind of horror twist (both Zombie Movie horror and Horror of War horror). In Private Ryan, the squad walks along the countryside, weapons held at the ready, the men getting to know each other, and Oppum talks about his book. In Overlord the squad walks along a road—At night! Totally different!—with their weapons held at the ready, getting to know each other, and one of the guys is writing a book. He talks about the book, and is blown up by a mine.
Later on, one of the soldiers gets shot up, and he falls on his back. The men tear open his shirt, and he’s gone all pale. He’s squirming, blood is flowing out of the holes in his chest and torso, and the men are desperately trying to save him, but he eventually dies. In Private Ryan, it’s their medic, and they inject him with morphine. In this movie, in an identical scene (the CAMERA ANGLES are even the same), after he dies the main character injects him with zombie juice and he comes back to life and begins mutating…
… just like a person infected by the T-Virus in a Resident Evil game. Which moves us to the Resident Evil portion of the movie.
The church isn’t just a church, it’s built atop an ancient well and in that well is evil that can cause a nasty plague, but also bring people back from the dead as monsters. The Nazis discover this, build a secret base underneath the church, and begin experimenting with creating super-strong, aggressive, deathless super-soldiers from this goop. As the SS captain says, “A thousand-year Reich needs thousand-year soldiers.”
They trap villagers in bags and keep them marinated in goop, to produce more of the stuff, they have a decapitated head that’s kept alive, moaning to be released from its hellish existence, and monster soldiers are kept in cells, where unspeakable experiments are carried out. (Also, they infect villagers with the plague, then haul them out into the woods to KILL THEM WITH FIRE. The flamethrowers are cool, at least.) All of this in an ancient stone structure, filled with Weird Science Nazi gizmos, a nightmarish lab / morgue, helpless innocents killed by the monsters and the Nazis, and control systems for the radio tower.
It’s Resident Evil. Or, at least, it wouldn’t be out of place in any of the Resident Evil games I’ve played. No giant monsters, but that’s about it.
So the French resistance hottie (because there’s ALWAYS a hot French chick in a black leather coat with an SMG) is allowing herself to be used by the SS captain, in order to keep her brother safe, but the American soldiers are having none of that and in the ensuing firefight SS guy is shot in the face and races back to his Secret Base of Evils and Also Gory Horror. The soldiers chase him, set up an ambush, and begin killing Nazis.
In the basement of the base, the Nazi captain injects himself with the zombie-making goop and becomes a super-strong super-soldier who looks a lot like the Red Skull, at least along the left side of his face. A gooey, bloody drippy, massive-scar-and-portions-of-his-cheek-hanging-loose Red Skull, but the Red Skull nonetheless.
So the soldiers come for the tower, and run into its horrors. Down to just two survivors inside the base, one of them—the blonde dude (okay, sandy blonde. Same diff.)—is all shot up and dying so he injects himself with the goop, and becomes a super-strong super-soldier who takes on the Red Skull in a superhero battle.
No, really. It’s right there in the movie.
Things blow up, the tower is down, planes fly over the beaches, and Hitler’s 1000 Year Reich is on its way to being destroyed. YAY!
Something happens when artists copy other artists who are copying other artists who made something great because they did the research, and everybody else after them didn’t. Your stuff feels bland, regurgitated, recycled, rote. It feels like a copy of a copy of a copy. There’s none of the unexpected but authentic details that a work needs to stay fresh.
The WWII scenes of Overlord are copies of copies of copies. Not just photocopying exact scenes from Saving Private Ryan (to a shameless degree), but also scenes from Kelly’s Heroes (the minefield), The Longest Day (the clickers and challenge calls), and probably other WWII films I failed to remember or recognize. The WWII stuff is entirely as expected, no surprises, nothing different, nothing but barely-disguised versions of things we’ve seen before, dozens of times. It’s all safe. The same. No bold choices or risks taken at all, anywhere.
The Zombie Horror part of the movie is at least a fresh take on that. There are creatures, but only a couple of them get out, and there’s no Zombie Apocalypse scenes where zombies flood into the lab and eat the Nazis, who themselves rise as zombies. Shooting them in the head does nothing, instead KILL IT WITH FIRE is the trick, and there’s flamethrowers handy. It’s a different take on zombie lore, different enough to be fresh.
The movie obviously had a lot of money behind it, and suffers from that—things look too neat and controlled and professionally done. This kind of horror often benefits from the rawness and flawed cinematography a low budget brings. It adds character, whereas a carefully controlled, fully storyboarded and scripted movie is utterly without character, like a beautiful but bland model. She’s hot, but there’s nothing distinctive about her, nothing that sets her beauty apart from hundreds or thousands more just like her. Horror movies need character more than prettiness, and this film is too pretty.
All these issues aside, the movie isn’t bad as a zombie movie. It’s got chills and gore, evil bad guys and noble good guys. There’s bad things afoot, the soldiers stop it, and monsters get killed. It’s fast paced and delivers the goods. At heart, it’s a low budget zombie horror movie, made on a big budget.
Strange that a movie about the living dead should feel so lifeless.
Jasyn Jones, better known as Daddy Warpig, is a host on the Geek Gab podcast, a regular on the Superversive SF livestreams, and blogs at Daddy Warpig’s House of Geekery. Check him out on Twitter.
Overlord: Saving Private Ryan Meets Resident Evil Meets Captain America! published first on https://medium.com/@ReloadedPCGames
0 notes
Text
Working with the Hadoop Distributed File System (HDFS)
The Hadoop Distributed File System (HDFS) allows you to both federate storage across many computers as well as distribute files in a redundant manor across a cluster. HDFS is a key component to many storage clusters that possess more than a petabyte of capacity.
Each computer acting as a storage node in a cluster can contain one or more storage devices. This can allow several mechanical storage drives to both store data more reliably than SSDs, keep the cost per gigabyte down as well as go some way to exhausting the SATA bus capacity of a given system.
Hadoop ships with a feature-rich and robust JVM-based HDFS client. For many that interact with HDFS directly it is the go-to tool for any given task. That said, there is a growing population of alternative HDFS clients. Some optimise for responsiveness while others make it easier to utilise HDFS in Python applications. In this post I'll walk through a few of these offerings.
If you'd like to setup an HDFS environment locally please see my Hadoop 3 Single-Node Install Guide (skip the steps for Presto and Spark). I also have posts that cover working with HDFS on AWS EMR and Google Dataproc.
The Apache Hadoop HDFS Client
The Apache Hadoop HDFS client is the most well-rounded HDFS CLI implementation. Virtually any API endpoint that has been built into HDFS can be interacted with using this tool.
For the release of Hadoop 3, considerable effort was put into reorganising the arguments of this tool. This is what they look like as of this writing.
Admin Commands: cacheadmin configure the HDFS cache crypto configure HDFS encryption zones debug run a Debug Admin to execute HDFS debug commands dfsadmin run a DFS admin client dfsrouteradmin manage Router-based federation ec run a HDFS ErasureCoding CLI fsck run a DFS filesystem checking utility haadmin run a DFS HA admin client jmxget get JMX exported values from NameNode or DataNode. oev apply the offline edits viewer to an edits file oiv apply the offline fsimage viewer to an fsimage oiv_legacy apply the offline fsimage viewer to a legacy fsimage storagepolicies list/get/set block storage policies Client Commands: classpath prints the class path needed to get the hadoop jar and the required libraries dfs run a filesystem command on the file system envvars display computed Hadoop environment variables fetchdt fetch a delegation token from the NameNode getconf get config values from configuration groups get the groups which users belong to lsSnapshottableDir list all snapshottable dirs owned by the current user snapshotDiff diff two snapshots of a directory or diff the current directory contents with a snapshot version print the version Daemon Commands: balancer run a cluster balancing utility datanode run a DFS datanode dfsrouter run the DFS router diskbalancer Distributes data evenly among disks on a given node httpfs run HttpFS server, the HDFS HTTP Gateway journalnode run the DFS journalnode mover run a utility to move block replicas across storage types namenode run the DFS namenode nfs3 run an NFS version 3 gateway portmap run a portmap service secondarynamenode run the DFS secondary namenode zkfc run the ZK Failover Controller daemon
The bulk of the disk access verbs most people familiar with Linux will recognise are kept under the dfs argument.
Usage: hadoop fs [generic options] [-appendToFile <localsrc> ... <dst>] [-cat [-ignoreCrc] <src> ...] [-checksum <src> ...] [-chgrp [-R] GROUP PATH...] [-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] [-chown [-R] [OWNER][:[GROUP]] PATH...] [-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>] [-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...] [-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>] [-createSnapshot <snapshotDir> [<snapshotName>]] [-deleteSnapshot <snapshotDir> <snapshotName>] [-df [-h] [<path> ...]] [-du [-s] [-h] [-v] [-x] <path> ...] [-expunge] [-find <path> ... <expression> ...] [-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-getfacl [-R] <path>] [-getfattr [-R] {-n name | -d} [-e en] <path>] [-getmerge [-nl] [-skip-empty-file] <src> <localdst>] [-head <file>] [-help [cmd ...]] [-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]] [-mkdir [-p] <path> ...] [-moveFromLocal <localsrc> ... <dst>] [-moveToLocal <src> <localdst>] [-mv <src> ... <dst>] [-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>] [-renameSnapshot <snapshotDir> <oldName> <newName>] [-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...] [-rmdir [--ignore-fail-on-non-empty] <dir> ...] [-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]] [-setfattr {-n name [-v value] | -x name} <path>] [-setrep [-R] [-w] <rep> <path> ...] [-stat [format] <path> ...] [-tail [-f] <file>] [-test -[defsz] <path>] [-text [-ignoreCrc] <src> ...] [-touchz <path> ...] [-truncate [-w] <length> <path> ...] [-usage [cmd ...]]
Notice how the top usage line doesn't mention hdfs dfs but instead hadoop fs. You'll find that either prefix will provide the same functionality if you're working with HDFS as an endpoint.
A Golang-based HDFS Client
In 2014, Colin Marc started work on a Golang-based HDFS client. This tool has two major features that stand out to me. The first is that there is no JVM overhead so execution begins much quicker than the JVM-based client. Second is the arguments align more closely with the GNU Core Utilities commands like ls and cat. This isn't a drop-in replacement for the JVM-based client but it should be a lot more intuitive for those already familiar with GNU Core Utilities file system commands.
The following will install the client on a fresh Ubuntu 16.04.2 LTS system.
$ wget -c -O gohdfs.tar.gz \ https://github.com/colinmarc/hdfs/releases/download/v2.0.0/gohdfs-v2.0.0-linux-amd64.tar.gz $ tar xvf gohdfs.tar.gz $ gohdfs-v2.0.0-linux-amd64/hdfs
The release also includes a bash completion script. This is handy for being able to hit tab and get a list of commands or to complete a partially typed-out list of arguments.
I'll include the extracted folder name below to help differentiate this tool from the Apache HDFS CLI.
$ gohdfs-v2.0.0-linux-amd64/hdfs
Valid commands: ls [-lah] [FILE]... rm [-rf] FILE... mv [-nT] SOURCE... DEST mkdir [-p] FILE... touch [-amc] FILE... chmod [-R] OCTAL-MODE FILE... chown [-R] OWNER[:GROUP] FILE... cat SOURCE... head [-n LINES | -c BYTES] SOURCE... tail [-n LINES | -c BYTES] SOURCE... du [-sh] FILE... checksum FILE... get SOURCE [DEST] getmerge SOURCE DEST put SOURCE DEST df [-h]
As you can see, prefixing many GNU Core Utilities file system commands with the HDFS client will produce the expected functionality on HDFS.
$ gohdfs-v2.0.0-linux-amd64/hdfs df -h
Filesystem Size Used Available Use% 11.7G 24.0K 7.3G 0%
The GitHub homepage for this project shows how listing files can be two orders of magnitude quicker using this tool versus the JVM-based CLI.
This start up speed improvement can be handy if HDFS commands are being invoked a lot. The ideal file size of an ORC or Parquet file for most purposes is somewhere between 256 MB and 2 GB and it's not uncommon to see these being micro-batched into HDFS as they're being generated.
Below I'll generate a file containing a gigabyte of random data.
$ cat /dev/urandom \ | head -c 1073741824 \ > one_gig
Uploading this file via the JVM-based CLI took 18.6 seconds on my test rig.
$ hadoop fs -put one_gig /one_gig
Uploading via the Golang-based CLI took 13.2 seconds.
$ gohdfs-v2.0.0-linux-amd64/hdfs put one_gig /one_gig_2
Spotify's Python-based HDFS Client
In 2014 work began at Spotify on a Python-based HDFS CLI and library called Snakebite. The bulk of commits on this project we put together by Wouter de Bie and Rafal Wojdyla. If you don't require Kerberos support then the only requirements for this client are the Protocol Buffers Python library from Google and Python 2.7. As of this writing Python 3 isn't supported.
The following will install the client on a fresh Ubuntu 16.04.2 LTS system using a Python virtual environment.
$ sudo apt install \ python \ python-pip \ virtualenv $ virtualenv .snakebite $ source .snakebite/bin/activate $ pip install snakebite
This client is not a drop-in replacement for the JVM-based CLI but shouldn't have a steep learning curve if you're already familiar with GNU Core Utilities file system commands.
snakebite [general options] cmd [arguments] general options: -D --debug Show debug information -V --version Hadoop protocol version (default:9) -h --help show help -j --json JSON output -n --namenode namenode host -p --port namenode RPC port (default: 8020) -v --ver Display snakebite version commands: cat [paths] copy source paths to stdout chgrp <grp> [paths] change group chmod <mode> [paths] change file mode (octal) chown <owner:grp> [paths] change owner copyToLocal [paths] dst copy paths to local file system destination count [paths] display stats for paths df display fs stats du [paths] display disk usage statistics get file dst copy files to local file system destination getmerge dir dst concatenates files in source dir into destination local file ls [paths] list a path mkdir [paths] create directories mkdirp [paths] create directories and their parents mv [paths] dst move paths to destination rm [paths] remove paths rmdir [dirs] delete a directory serverdefaults show server information setrep <rep> [paths] set replication factor stat [paths] stat information tail path display last kilobyte of the file to stdout test path test a path text path [paths] output file in text format touchz [paths] creates a file of zero length usage <cmd> show cmd usage
The client is missing certain verbs that can be found in the JVM-based client as well as the Golang-based client described above. One of which is the ability to copy files and streams to HDFS.
That being said I do appreciate how easy it is to pull statistics for a given file.
$ snakebite stat /one_gig
access_time 1539530885694 block_replication 1 blocksize 134217728 file_type f group supergroup length 1073741824 modification_time 1539530962824 owner mark path /one_gig permission 0644
To collect the same information with the JVM client would involve several commands. Their output would also be harder to parse than the key-value pairs above.
As well as being a CLI tool, Snakebite is also a Python library.
from snakebite.client import Client client = Client("localhost", 9000, use_trash=False) [x for x in client.ls(['/'])][:2]
[{'access_time': 1539530885694L, 'block_replication': 1, 'blocksize': 134217728L, 'file_type': 'f', 'group': u'supergroup', 'length': 1073741824L, 'modification_time': 1539530962824L, 'owner': u'mark', 'path': '/one_gig', 'permission': 420}, {'access_time': 1539531288719L, 'block_replication': 1, 'blocksize': 134217728L, 'file_type': 'f', 'group': u'supergroup', 'length': 1073741824L, 'modification_time': 1539531307264L, 'owner': u'mark', 'path': '/one_gig_2', 'permission': 420}]
Note I've asked to connect to localhost on TCP port 9000. Out of the box Hadoop uses TCP port 8020 for the NameNode RPC endpoint. I've often changed this to TCP port 9000 in many of my Hadoop guides.
You can find the hostname and port number configured for this end point on the master HDFS node. Also note that for various reasons HDFS, and Hadoop in general, need to use hostnames rather than IP addresses.
$ sudo vi /opt/hadoop/etc/hadoop/core-site.xml
... <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> ...
Python-based HdfsCLI
In 2014, Matthieu Monsch also began work on a Python-based HDFS client called HdfsCLI. Two features this client has over the Spotify Python client is that it supports uploading to HDFS and Python 3 (in addition to 2.7).
Matthieu has previously worked at LinkedIn and now works for Google. The coding style of this project will feel very familiar to anyone that's looked at a Python project that has originated from Google.
This library includes support for a progress tracker, a fast AVRO library, Kerberos and Pandas DataFrames.
The following will install the client on a fresh Ubuntu 16.04.2 LTS system using a Python virtual environment.
$ sudo apt install \ python \ python-pip \ virtualenv $ virtualenv .hdfscli $ source .hdfscli/bin/activate $ pip install 'hdfs[dataframe,avro]'
In order for this library to communicate with HDFS, WebHDFS needs to be enabled on the master HDFS node.
$ sudo vi /opt/hadoop/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.datanode.data.dir</name> <value>/opt/hdfs/datanode</value> <final>true</final> </property> <property> <name>dfs.namenode.name.dir</name> <value>/opt/hdfs/namenode</value> <final>true</final> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.namenode.http-address</name> <value>localhost:50070</value> </property> </configuration>
With the configuration in place the DFS service needs to be restarted.
$ sudo su $ /opt/hadoop/sbin/stop-dfs.sh $ /opt/hadoop/sbin/start-dfs.sh $ exit
A configuration file is needed to store connection settings for this client.
[global] default.alias = dev [dev.alias] url = http://localhost:50070 user = mark
A big downside of the client is that only a very limited subset of HDFS functionality is supported. That being said the client verb arguments are pretty self explanatory.
HdfsCLI: a command line interface for HDFS. Usage: hdfscli [interactive] [-a ALIAS] [-v...] hdfscli download [-fsa ALIAS] [-v...] [-t THREADS] HDFS_PATH LOCAL_PATH hdfscli upload [-sa ALIAS] [-v...] [-A | -f] [-t THREADS] LOCAL_PATH HDFS_PATH hdfscli -L | -V | -h Commands: download Download a file or folder from HDFS. If a single file is downloaded, - can be specified as LOCAL_PATH to stream it to standard out. interactive Start the client and expose it via the python interpreter (using iPython if available). upload Upload a file or folder to HDFS. - can be specified as LOCAL_PATH to read from standard in. Arguments: HDFS_PATH Remote HDFS path. LOCAL_PATH Path to local file or directory. Options: -A --append Append data to an existing file. Only supported if uploading a single file or from standard in. -L --log Show path to current log file and exit. -V --version Show version and exit. -a ALIAS --alias=ALIAS Alias of namenode to connect to. -f --force Allow overwriting any existing files. -s --silent Don't display progress status. -t THREADS --threads=THREADS Number of threads to use for parallelization. 0 allocates a thread per file. [default: 0] -v --verbose Enable log output. Can be specified up to three times (increasing verbosity each time). Examples: hdfscli -a prod /user/foo hdfscli download features.avro dat/ hdfscli download logs/1987-03-23 - >>logs hdfscli upload -f - data/weights.tsv <weights.tsv HdfsCLI exits with return status 1 if an error occurred and 0 otherwise.
The following finished in 68 seconds. This is an order of magnitude slower than some other clients I'll explore in this post.
$ hdfscli upload \ -t 4 \ -f - \ one_gig_3 < one_gig
That said, the client is very easy to work with in Python.
from hashlib import sha256 from hdfs import Config client = Config().get_client('dev') [client.status(uri) for uri in client.list('')][:2]
[{u'accessTime': 1539532953515, u'blockSize': 134217728, u'childrenNum': 0, u'fileId': 16392, u'group': u'supergroup', u'length': 1073741824, u'modificationTime': 1539533029897, u'owner': u'mark', u'pathSuffix': u'', u'permission': u'644', u'replication': 1, u'storagePolicy': 0, u'type': u'FILE'}, {u'accessTime': 1539533046246, u'blockSize': 134217728, u'childrenNum': 0, u'fileId': 16393, u'group': u'supergroup', u'length': 1073741824, u'modificationTime': 1539533114772, u'owner': u'mark', u'pathSuffix': u'', u'permission': u'644', u'replication': 1, u'storagePolicy': 0, u'type': u'FILE'}]
Below I'll generate a SHA-256 hash of a file located on HDFS.
with client.read('/user/mark/one_gig') as reader: print sha256(reader.read()).hexdigest()[:6]
Apache Arrow's HDFS Client
Apache Arrow is a cross-language platform for in-memory data headed by Wes McKinney. It's Python bindings "PyArrow" allows Python applications to interface with a C++-based HDFS client.
Wes stands out in the data world. He has worked for Cloudera in the past, created the Pandas Python package and has been a contributor to the Apache Parquet project.
The following will install PyArrow on a fresh Ubuntu 16.04.2 LTS system using a Python virtual environment.
$ sudo apt install \ python \ python-pip \ virtualenv $ virtualenv .pyarrow $ source .pyarrow/bin/activate $ pip install pyarrow
The Python API behaves in a clean and intuitive manor.
from hashlib import sha256 import pyarrow as pa hdfs = pa.hdfs.connect(host='localhost', port=9000) with hdfs.open('/user/mark/one_gig', 'rb') as f: print sha256(f.read()).hexdigest()[:6]
The interface is very performant as well. The following completed in 6 seconds. This is the fastest any client transfer this file on my test rig.
with hdfs.open('/user/mark/one_gig_4', 'wb') as f: f.write(open('/home/mark/one_gig').read())
HDFS Fuse and GNU Core Utilities
One of the most intuitive ways to interact with HDFS for a newcomer could most likely be with the GNU Core Utilities file system functions. These can be run on an HDFS mount exposed via a file system fuse.
The following will install an HDFS fuse client on a fresh Ubuntu 16.04.2 LTS system using a Debian package from Cloudera's repository.
$ wget https://archive.cloudera.com/cdh5/ubuntu/xenial/amd64/cdh/archive.key -O - \ | sudo apt-key add - $ wget https://archive.cloudera.com/cdh5/ubuntu/xenial/amd64/cdh/cloudera.list -O - \ | sudo tee /etc/apt/sources.list.d/cloudera.list $ sudo apt update $ sudo apt install hadoop-hdfs-fuse
$ sudo mkdir -p hdfs_mount $ sudo hadoop-fuse-dfs \ dfs://127.0.0.1:9000 \ hdfs_mount
The following completed in 8.2 seconds.
$ cp one_gig hdfs_mount/one_gig_5
Regular file system commands run as expected. The following gives how much space has been used and is available.
Filesystem Size Used Avail Use% Mounted on fuse_dfs 12G 4.9G 6.8G 42% /home/mark/hdfs_mount
The following shows how much disk space has been used per parent folder.
This will give a file listing by file size.
$ ls -lhS hdfs_mount/user/mark/
-rw-r--r-- 1 mark 99 1.0G Oct 14 09:03 one_gig -rw-r--r-- 1 mark 99 1.0G Oct 14 09:05 one_gig_2 -rw-r--r-- 1 mark 99 1.0G Oct 14 09:10 one_gig_3 ...
Thank you for taking the time to read this post. I offer consulting, architecture and hands-on development services to clients in North America & Europe. If you'd like to discuss how my offerings can help your business please contact me via
LinkedIn
.
DataTau published first on DataTau
0 notes
Link
ApexSQL Log is an amazing tool for reading the transaction log and reading the transaction log can form the basis of a lot of great features, functionality. In this case, we’ll look at how you can use ApexSQL Log for transactional replication to keep a reporting database up to date with your production system.
Reporting server/database
Many times there will be a business requirement for a means to offload work against the production server from reporting requests. Not only can this reduce the load on the production server and potentially improve performance, creating a separate environment, optimized for reporting, can also speed the retrieval of reports and queries, in some cases significantly.
In essence, creating a reporting database mean taking a copy of the production database and moving it to a different server. This will reduce the load on production, as mentioned. But there can be additional benefits including
Moving the reporting server “closer” to reporting clients to reduce network traffic
Adding indexes to optimize select queries to improve performance, without having to worry about degrading the performance of transactional operations
Faster reporting because there are no other transactions or operations taking place, besides reporting, on the new server
Ok, this sounds great, but how do we automatically and reliably sync our reporting and production systems so that we keep our reports timely and accurate to within a certain window of time e.g. 15 minutes?
Transactional replication
This is a great use case for transactional replication, where transactions from the production database can be replicated to the reporting server. As such, this would seem to be a good fit for SQL Server transactional replication. There are a few reasons why you might not want to go that route though …
You don’t have the Enterprise edition of SQL Server or SQL Server 2016, where transactional replication is included in other editions. See Editions and supported features of SQL Server 2016
You don’t have the time or patience to learn how to implement transactional replication and would like an out-of-the-box solution
The servers can’t see or talk to each other directly, so you need to move the transaction store, upload it etc and then download, consume it in a different environment
You already own ApexSQL Log and use it for other purposes e.g. Continuous auditing, disaster recovery, forensic auditing, simulating production loads etc
Why not use Change tracking or CDC?
Both of these solutions offer potential alternatives to transactional replication but come with the same edition restrictions but also can require a lot of custom coding, which can quickly increase the time required and cost of your replication solution. Although these are native solutions, they certainly aren’t hands-free or out-of-the-box, so let’s keep looking
Transactional replication with ApexSQL Log
That brings us back to ApexSQL Log. ApexSQL Log is uniquely suited for just this task.
It can read the SQL Server transaction log quickly and easily and produce accurate results
It has a console application with a full command line interface that allows for extensive, customizable automation
And it can easily set break points to determine where the last job ended so there is never duplicate data or gaps in data
Most of the configuration can be done with an easy to use GUI and saved as a project
The entire implementation, including the reference to the aforementioned project configuration file can be converted to a batch file, with no coding required!
First, the high level view
The concept here is pretty simple. We will set up ApexSQL Log to poll a “Publisher” database. This will be the production database, in our case, that we want to replication transactions from. ApexSQL Log will wake up every 15 minutes, read the transaction log, and write all of the transactions to file as a T-SQL “Redo” script. This script will replay all of the transactions, later, on the “Subscriber” database.
We’ll transport, upload etc the script file as needed, then schedule a simple process to open the file and execute it on the Subscriber database. This can be as simple as a PowerShell script or a batch file.
Variations
With ApexSQL Log we can easily set up sophisticated filters to replicate only the data we need and leave everything else out. For example we can easily filter by operation, table name, user or even add some advanced filters including transaction state and duration, specific table field values and more
We can poll at larger e.g. 1 hour or shorter e.g. 1 minute intervals
If ApexSQL Log can see both servers simultaneously, it can read from the Publisher transaction log and write to the Subscriber directly skipping the step of creating a file, then opening and executing it. For simplicity, this is what we’ll illustrate with our example.
Getting our hands dirty
Ok, let’s build this
First we’ll open ApexSQL Log and connect to the Publisher database, WorldWideExporters.
We’ll configure ApexSQL Log to use the Online log as we’ll make sure the database is in Full recovery mode, ensuring all of the transactions in our 15-minute window will be found there
Next, we will choose to create an Undo/Redo script
Next, let’s set up a filter to determine just what transactions we are going to include and/or exclude. For instance, we can opt to exclude several tables from our job by unchecking them in the ‘Tables’ filter. We can do the same with users or any other filters to achieve high auditing precision
Also, we will only include DML operations and exclude all DDL operations
Now let’s set the options for continuous auditing, automatically including breakpoints so we don’t have any gaps or overlaps that might cause missing or duplicate transactions respectively. ApexSQL Log will always remember the LSN value of the last audited operation and when the time for the next job is due, mentioned LSN value will be used as a starting point ensuring that no duplicate transactions are included in this continuous auditing task as well as no transactions are overlooked or missed.
Once we are done, let’s save our project file as “Replication.axlp” so we can come back to this again if we have any edits, allowing us to quickly update our reporting profile. In fact, we can edit this file and save over the last version to update our configuration settings without even having to update our automation script.
Now that we have everything configured like we want it, let’s use the ‘Batch file’ feature to save a batch (.BAT) file. This file has Windows Shell script that will run ApexSQL Log and then execute it with this saved project without running the GUI or requiring any user actions.
Note: We’ll run this on a Windows client that uses integrated security to connect to both our Publisher and Subscriber databases, so we won’t need to worry about user names or passwords.
Now all we have to do is schedule the batch file with Windows scheduler, SQL Job or some other way. Once scheduled, this job will “wake up” ApexSQL log at a particular interval e.g. 15 minutes and execute it with the instructions included in the batch file and the ApexSQL Log project file and create continuous Redo scripts.
Note that the job to execute the scripts on the “Subscriber” database should also be scheduled via similar/same means in order to finalize our replication job.
See it run
Once I have created my Project file and batch file, for automation, then scheduled it to run every 15 minutes, I’ll make some changes in production.
I’ll run a script to insert 10 rows into [dbo.Employees] table.
Now let’s run a quick query to compare our Publisher and Subscriber databases. Sure enough, you can see that the 10 extra rows exist in the Publisher but not the Subscriber.
Let’s now click our BAT file, because we don’t want to wait 15 minutes, and let it run. Once it closes, let’s re-compare the two databases. We can see that they are now equal as the 10 rows have been replicated to the Subscriber. We can see that both tables now have the same row count of [ 20 ].
Here is what the Redo script looks like in ApexSQL Log built-in editor
Once the script is executed on the “Subscriber” database, data in the “Employees” table will be perfectly replicated
Some enhancements
If we want to dial up the data quality of our reporting database to make sure it is closer to real time, we can change our scheduling interval from 15 minutes to 1 minute.
If we wanted to include DDL operations too, that would make sure we automatically update our Subscriber with any schema changes from the Publisher. So let’s open ApexSQL Log, open our project file, and then add “DDL operations” then hit save.
Additional enhancements
Although our example system is pretty simple and basic – it works, and it should work consistently and reliably. That doesn’t mean we can’t augment it with some cool features including auditing and alerting, to make sure that our reporting database is being replicated properly
Here are some suggestions
Saving T-SQL replay script to file with a date stamp so we have an audit of transactions
Saving date stamped verbose console output to file as additional auditing mechanism
Running the T-SQL script in a separate process, trapping a return code and emailing an alert if there were any errors with the T-SQL script
Trapping an error code from our batch file and sending an email alert if it fails
Adding a call to ApexSQL Diff to automatically compare schemas between Production and Subscriber, immediately after a replication push, and email an alert if any differences were found
To prevent any problems with #e, we can add a step *before* a replication push and compare and synchronize the schema of our Subscriber database with the Publisher immediately before the replication push to be 100% certain the schemas are exact before pushing the last batch of data changes. If we do this, then we can uncheck “DDL operations” from ApexSQL Log and not include them in our replication. This might provide a bit more robust means of keeping our database schemas in sync vs just adding “DDL operations” to our replication push (although in theory, they should accomplish the same thing)
0 notes
Last Seen Blogs

temporal-sandwich
What's Consistentcy?

smaeralit-blog
Smaeralit

eltemplodelashisha
El Templo de la Shisha

dreaminparadice
Stop Bitchin.

myworldisfuckingperfect
A true Love never End..