#also randomly why am I seeing so many leaks for this update?
Text
Goddamnit, why did all these leaks have to come out while I was asleep? People are already talking about it on here, I missed my chance!
I didn’t want that dream about cars killing us, why did I have to get that instead??
Anyways, this is late but I might as well give my own two cents, because the leaks seem really interesting and I want to talk about them


So these two seem to be Mercury Knight and Silverdrop (or Silver Bell it seems?), who both seem like guys apparently (I thought Silver Bell at least would be a girl)
Not gonna lie, kind of wish Mercury Knight had a simpler design, he looks like a bit too much. Silver Bell’s not too bad though. Also kind of looks like Lilybell
Anyways, on to the topic I really want to get on, these guys





So first off, I’m pretty sure Shadow Milk has to do with the play thing we saw before, their milk ring thing was on there, also they seem to have a jester motif, which actually, the Truth Soul Jam is…kind of fitting
Also another thing I notice is that they have the shapes of all the Soul Jams, but upside down and the wrong color (aside from Shadow Milk and Eternal Sugar)
I really want to know who these guys are, are they like, past wielders of the Soul Jam? Does that mean the Soul Jams change color when they have a proper new wielder that they bond to? That’d be interesting. Or are they new ones that work for Dark Enchantress that she wants to use the Soul Jam once she steals it?
I don’t know but I’m very excited to see who these guys are
Edit: so I got this from @gendy-endy’s post

So it seems like the first theory, these are previous Soul Jam holders, but they seemed to have fallen and turned to darkness? That’s interesting. I still hope we see more about them, as well as the actual Cookies
Also one note about this guy, the Fairy King I think

I don’t know why but his face reminds me of Millennial Tree. Or maybe MT’s costume. Regardless they look kind of similar to me
Anyways I think that’s it
#I’m very excited for that weird five#who are they?#dangit the update’s two weeks away#but at least the first teaser will only be one week#also randomly why am I seeing so many leaks for this update?#it’s crazy#like we have so many new character things#anyways#cookie run#cookie run kingdom#cookie run leaks#crk leaks#new cookie#mercury knight cookie#silver bell cookie#speculation#theory
106 notes
·
View notes
Text
AI competitions don’t produce useful models

By LUKE OAKDEN-RAYNER
A huge new CT brain dataset was released the other day, with the goal of training models to detect intracranial haemorrhage. So far, it looks pretty good, although I haven’t dug into it in detail yet (and the devil is often in the detail).
The dataset has been released for a competition, which obviously lead to the usual friendly rivalry on Twitter:
Of course, this lead to cynicism from the usual suspects as well.
And the conversation continued from there, with thoughts ranging from “but since there is a hold out test set, how can you overfit?” to “the proposed solutions are never intended to be applied directly” (the latter from a previous competition winner).
As the discussion progressed, I realised that while we “all know” that competition results are more than a bit dubious in a clinical sense, I’ve never really seen a compelling explanation for why this is so.
Hopefully that is what this post is, an explanation for why competitions are not really about building useful AI systems.
DISCLAIMER: I originally wrote this post expecting it to be read by my usual readers, who know my general positions on a range of issues. Instead, it was spread widely on Twitter and HackerNews, and it is pretty clear that I didn’t provide enough context for a number of statements made. I am going to write a follow-up to clarify several things, but as a quick response to several common criticisms:
I don’t think AlexNet is a better model than ResNet. That position would be ridiculous, particularly given all of my published work uses resnets and densenets, not AlexNets.
I think this miscommunication came from me not defining my terms: a “useful” model would be one that works for the task it was trained on. It isn’t a model architecture. If architectures are developed in the course of competitions that are broadly useful, then that is a good architecture, but the particular implementation submitted to the competition is not necessarily a useful model.
The stats in this post are wrong, but they are meant to be wrong in the right direction. They are intended for illustration of the concept of crowd-based overfitting, not accuracy. Better approaches would almost all require information that isn’t available in public leaderboards. I may update the stats at some point to make them more accurate, but they will never be perfect.
I was trying something new with this post – it was a response to a Twitter conversation, so I wanted to see if I could write it in one day to keep it contemporaneous. Given my usual process is spending several weeks and many rewrites per post, this was a risk. I think the post still serves its purpose, but I don’t personally think the risk paid off. If I had taken even another day or two, I suspect I would have picked up most of these issues before publication. Mea culpa.
Let’s have a battle

Nothing wrong with a little competition.*
So what is a competition in medical AI? Here are a few options:
getting teams to try to solve a clinical problem
getting teams to explore how problems might be solved and to try novel solutions
getting teams to build a model that performs the best on the competition test set
a waste of time
Now, I’m not so jaded that I jump to the last option (what is valuable to spend time on is a matter of opinion, and clinical utility is only one consideration. More on this at the end of the article).
But what about the first three options? Do these models work for the clinical task, and do they lead to broadly applicable solutions and novelty, or are they only good in the competition and not in the real world?
(Spoiler: I’m going to argue the latter).
Good models and bad models
Should we expect this competition to produce good models? Let’s see what one of the organisers says.
Cool. Totally agree. The lack of large, well-labeled datasets is the biggest major barrier to building useful clinical AI, so this dataset should help.
But saying that the dataset can be useful is not the same thing as saying the competition will produce good models.
So to define our terms, let’s say that a good model is a model that can detect brain haemorrhages on unseen data (cases that the model has no knowledge of).
So conversely, a bad model is one that doesn’t detect brain haemorrhages in unseen data.
These definitions will be non-controversial. Machine Learning 101. I’m sure the contest organisers agree with these definitions, and would prefer their participants to be producing good models rather than bad models. In fact, they have clearly set up the competition in a way designed to promote good models.
It just isn’t enough.
Epi vs ML, FIGHT!

If only academic arguments were this cute
ML101 (now personified) tells us that the way to control overfitting is to use a hold-out test set, which is data that has not been seen during model training. This simulates seeing new patients in a clinical setting.
ML101 also says that hold-out data is only good for one test. If you test multiple models, then even if you don’t cheat and leak test information into your development process, your best result is probably an outlier which was only better than your worst result by chance.
So competition organisers these days produce hold-out test sets, and only let each team run their model on the data once. Problem solved, says ML101. The winner only tested once, so there is no reason to think they are an outlier, they just have the best model.
Not so fast, buddy.
Let me introduce you to Epidemiology 101, who claims to have a magic coin.
Epi101 tells you to flip the coin 10 times. If you get 8 or more heads, that confirms the coin is magic (while the assertion is clearly nonsense, you play along since you know that 8/10 heads equates to a p-value of <0.05 for a fair coin, so it must be legit).
Unbeknownst to you, Epi101 does the same thing with 99 other people, all of whom think they are the only one testing the coin. What do you expect to happen?
If the coin is totally normal and not magic, around 5 people will find that the coin is special. Seems obvious, but think about this in the context of the individuals. Those 5 people all only ran a single test. According to them, they have statistically significant evidence they are holding a “magic” coin.
Now imagine you aren’t flipping coins. Imagine you are all running a model on a competition test set. Instead of wondering if your coin is magic, you instead are hoping that your model is the best one, about to earn you $25,000.
Of course, you can’t submit more than one model. That would be cheating. One of the models could perform well, the equivalent of getting 8 heads with a fair coin, just by chance.
Good thing there is a rule against it submitting multiple models, or any one of the other 99 participants and their 99 models could win, just by being lucky…
Multiple hypothesis testing
The effect we saw with Epi101’s coin applies to our competition, of course. Due to random chance, some percentage of models will outperform other ones, even if they are all just as good as each other. Maths doesn’t care if it was one team that tested 100 models, or 100 teams.
Even if certain models are better than others in a meaningful sense^, unless you truly believe that the winner is uniquely able to ML-wizard, you have to accept that at least some other participants would have achieved similar results, and thus the winner only won because they got lucky. The real “best performance” will be somewhere back in the pack, probably above average but below the winner^^.

Epi101 says this effect is called multiple hypothesis testing. In the case of a competition, you have a ton of hypotheses – that each participant was better than all others. For 100 participants, 100 hypotheses.
One of those hypotheses, taken in isolation, might show us there is a winner with statistical significance (p<0.05). But taken together, even if the winner has a calculated “winning” p-value of less than 0.05, that doesn’t mean we only have a 5% chance of making an unjustified decision. In fact, if this was coin flips (which is easier to calculate but not absurdly different), we would have a greater than 99% chance that one or more people would “win” and come up with 8 heads!
That is what an AI competition winner is; an individual who happens to get 8 heads while flipping fair coins.
Interestingly, while ML101 is very clear that running 100 models yourself and picking the best one will result in overfitting, they rarely discuss this “overfitting of the crowds”. Strange, when you consider that almost all ML research is done of heavily over-tested public datasets …
So how do we deal with multiple hypothesis testing? It all comes down to the cause of the problem, which is the data. Epi101 tells us that any test set is a biased version of the target population. In this case, the target population is “all patients with CT head imaging, with and without intracranial haemorrhage”. Let’s look at how this kind of bias might play out, with a toy example of a small hypothetical population:

In this population, we have a pretty reasonable “clinical” mix of cases. 3 intra-cerebral bleeds (likely related to high blood pressure or stroke), and two traumatic bleeds (a subdural on the right, and an extradural second from the left).
Now let’s sample this population to build our test set:
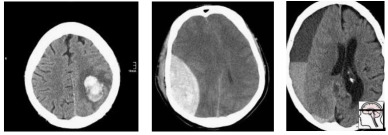
Randomly, we end up with mostly extra-axial (outside of the brain itself) bleeds. A model that performs well on this test will not necessarily work as well on real patients. In fact, you might expect a model that is really good at extra-axial bleeds at the expense of intra-cerebral bleeds to win.
But Epi101 doesn’t only point out problems. Epi101 has a solution.
So powerful
There is only one way to have an unbiased test set – if it includes the entire population! Then whatever model does well in the test will also be the best in practice, because you tested it on all possible future patients (which seems difficult).
This leads to a very simple idea – your test results become more reliable as the test set gets larger. We can actually predict how reliable test sets are using power calculations.

These are power curves. If you have a rough idea of how much better your “winning” model will be than the next best model, you can estimate how many test cases you need to reliably show that it is better.
So to find out if you model is 10% better than a competitor, you would need about 300 test cases. You can also see how exponentially the number of cases needed grows as the difference between models gets narrower.
Let’s put this into practice. If we look at another medical AI competition, the SIIM-ACR pneumothorax segmentation challenge, we see that the difference in Dice scores (ranging between 0 and 1) is negligible at the top of the leaderboard. Keep in mind that this competition had a dataset of 3200 cases (and that is being generous, they don’t all contribute to the Dice score equally).

So the difference between the top two was 0.0014 … let’s chuck that into a sample size calculator.

Ok, so to show a significant difference between these two results, you would need 920,000 cases.
But why stop there? We haven’t even discussed multiple hypothesis testing yet. This absurd number of cases needed is simply if there was ever only one hypothesis, meaning only two participants.
If we look at the leaderboard, there were 351 teams who made submissions. The rules say they could submit two models, so we might as well assume there were at least 500 tests. This has to produce some outliers, just like 500 people flipping a fair coin.
Epi101 to the rescue. Multiple hypothesis testing is really common in medicine, particularly in “big data” fields like genomics. We have spent the last few decades learning how to deal with this. The simplest reliable way to manage this problem is called the Bonferroni correction^^.
The Bonferroni correction is super simple: you divide the p-value by the number of tests to find a “statistical significance threshold” that has been adjusted for all those extra coin flips. So in this case, we do 0.05/500. Our new p-value target is 0.0001, any result worse than this will be considered to support the null hypothesis (that the competitors performed equally well on the test set). So let’s plug that in our power calculator.

Cool! It only increased a bit… to 2.6 million cases needed for a valid result :p
Now, you might say I am being very unfair here, and that there must be some small group of good models at the top of the leaderboard that are not clearly different from each other^^^. Fine, lets be generous. Surely no-one will complain if I compare the 1st place model to the 150th model?

So still more data than we had. In fact, I have to go down to the 192nd placeholder to find a result where the sample size was enough to produce a “statistically significant” difference.
But maybe this is specific to the pneumothorax challenge? What about other competitions?
In MURA, we have a test set of 207 x-rays, with 70 teams submitting “no more than two models per month”, so lets be generous and say 100 models were submitted. Running the numbers, the “first place” model is only significant versus the 56th placeholder and below.
In the RSNA Pneumonia Detection Challenge, there were 3000 test images with 350 teams submitting one model each. The first place was only significant compared to the 30th place and below.
And to really put the cat amongst the pigeons, what about outside of medicine?

As we go left to right in ImageNet results, the improvement year on year slows (the effect size decreases) and the number of people who have tested on the dataset increases. I can’t really estimate the numbers, but knowing what we know about multiple testing does anyone really believe the SOTA rush in the mid 2010s was anything but crowdsourced overfitting?
So what are competitions for?

They obviously aren’t to reliably find the best model. They don’t even really reveal useful techniques to build great models, because we don’t know which of the hundred plus models actually used a good, reliable method, and which method just happened to fit the under-powered test set.
You talk to competition organisers … and they mostly say that competitions are for publicity. And that is enough, I guess.
AI competitions are fun, community building, talent scouting, brand promoting, and attention grabbing.
But AI competitions are not to develop useful models.
* I have a young daughter, don’t judge me for my encyclopaedic knowledge of My Little Pony.**
** not that there is anything wrong with My Little Pony***. Friendship is magic. There is just an unsavoury internet element that matches my demographic who is really into the show. I’m no brony.
*** barring the near complete white-washing of a children’s show about multi-coloured horses.
^ we can actually understand model performance with our coin analogy. Improving the model would be equivalent to bending the coin. If you are good at coin bending, doing this will make it more likely to land on heads, but unless it is 100% likely you still have no guarantee to “win”. If you have a 60%-chance-of-heads coin, and everyone else has a 50% coin, you objectively have the best coin, but your chance of getting 8 heads out of 10 flips is still only 17%. Better than the 5% the rest of the field have, but remember that there are 99 of them. They have a cumulative chance of over 99% that one of them will get 8 or more heads.
^^ people often say the Bonferroni correction is a bit conservative, but remember, we are coming in skeptical that these models are actually different from each other. We should be conservative.
^^^ do please note, the top model here got $30,000 and the second model got nothing. The competition organisers felt that the distinction was reasonable.
Luke Oakden-Rayner is a radiologist (medical specialist) in South Australia, undertaking a Ph.D in Medicine with the School of Public Health at the University of Adelaide. This post originally appeared on his blog here.
AI competitions don’t produce useful models published first on https://wittooth.tumblr.com/
0 notes
Text
AI competitions don’t produce useful models

By LUKE OAKDEN-RAYNER
A huge new CT brain dataset was released the other day, with the goal of training models to detect intracranial haemorrhage. So far, it looks pretty good, although I haven’t dug into it in detail yet (and the devil is often in the detail).
The dataset has been released for a competition, which obviously lead to the usual friendly rivalry on Twitter:
Of course, this lead to cynicism from the usual suspects as well.
And the conversation continued from there, with thoughts ranging from “but since there is a hold out test set, how can you overfit?” to “the proposed solutions are never intended to be applied directly” (the latter from a previous competition winner).
As the discussion progressed, I realised that while we “all know” that competition results are more than a bit dubious in a clinical sense, I’ve never really seen a compelling explanation for why this is so.
Hopefully that is what this post is, an explanation for why competitions are not really about building useful AI systems.
DISCLAIMER: I originally wrote this post expecting it to be read by my usual readers, who know my general positions on a range of issues. Instead, it was spread widely on Twitter and HackerNews, and it is pretty clear that I didn’t provide enough context for a number of statements made. I am going to write a follow-up to clarify several things, but as a quick response to several common criticisms:
I don’t think AlexNet is a better model than ResNet. That position would be ridiculous, particularly given all of my published work uses resnets and densenets, not AlexNets.
I think this miscommunication came from me not defining my terms: a “useful” model would be one that works for the task it was trained on. It isn’t a model architecture. If architectures are developed in the course of competitions that are broadly useful, then that is a good architecture, but the particular implementation submitted to the competition is not necessarily a useful model.
The stats in this post are wrong, but they are meant to be wrong in the right direction. They are intended for illustration of the concept of crowd-based overfitting, not accuracy. Better approaches would almost all require information that isn’t available in public leaderboards. I may update the stats at some point to make them more accurate, but they will never be perfect.
I was trying something new with this post – it was a response to a Twitter conversation, so I wanted to see if I could write it in one day to keep it contemporaneous. Given my usual process is spending several weeks and many rewrites per post, this was a risk. I think the post still serves its purpose, but I don’t personally think the risk paid off. If I had taken even another day or two, I suspect I would have picked up most of these issues before publication. Mea culpa.
Let’s have a battle

Nothing wrong with a little competition.*
So what is a competition in medical AI? Here are a few options:
getting teams to try to solve a clinical problem
getting teams to explore how problems might be solved and to try novel solutions
getting teams to build a model that performs the best on the competition test set
a waste of time
Now, I’m not so jaded that I jump to the last option (what is valuable to spend time on is a matter of opinion, and clinical utility is only one consideration. More on this at the end of the article).
But what about the first three options? Do these models work for the clinical task, and do they lead to broadly applicable solutions and novelty, or are they only good in the competition and not in the real world?
(Spoiler: I’m going to argue the latter).
Good models and bad models
Should we expect this competition to produce good models? Let’s see what one of the organisers says.
Cool. Totally agree. The lack of large, well-labeled datasets is the biggest major barrier to building useful clinical AI, so this dataset should help.
But saying that the dataset can be useful is not the same thing as saying the competition will produce good models.
So to define our terms, let’s say that a good model is a model that can detect brain haemorrhages on unseen data (cases that the model has no knowledge of).
So conversely, a bad model is one that doesn’t detect brain haemorrhages in unseen data.
These definitions will be non-controversial. Machine Learning 101. I’m sure the contest organisers agree with these definitions, and would prefer their participants to be producing good models rather than bad models. In fact, they have clearly set up the competition in a way designed to promote good models.
It just isn’t enough.
Epi vs ML, FIGHT!

If only academic arguments were this cute
ML101 (now personified) tells us that the way to control overfitting is to use a hold-out test set, which is data that has not been seen during model training. This simulates seeing new patients in a clinical setting.
ML101 also says that hold-out data is only good for one test. If you test multiple models, then even if you don’t cheat and leak test information into your development process, your best result is probably an outlier which was only better than your worst result by chance.
So competition organisers these days produce hold-out test sets, and only let each team run their model on the data once. Problem solved, says ML101. The winner only tested once, so there is no reason to think they are an outlier, they just have the best model.
Not so fast, buddy.
Let me introduce you to Epidemiology 101, who claims to have a magic coin.
Epi101 tells you to flip the coin 10 times. If you get 8 or more heads, that confirms the coin is magic (while the assertion is clearly nonsense, you play along since you know that 8/10 heads equates to a p-value of <0.05 for a fair coin, so it must be legit).
Unbeknownst to you, Epi101 does the same thing with 99 other people, all of whom think they are the only one testing the coin. What do you expect to happen?
If the coin is totally normal and not magic, around 5 people will find that the coin is special. Seems obvious, but think about this in the context of the individuals. Those 5 people all only ran a single test. According to them, they have statistically significant evidence they are holding a “magic” coin.
Now imagine you aren’t flipping coins. Imagine you are all running a model on a competition test set. Instead of wondering if your coin is magic, you instead are hoping that your model is the best one, about to earn you $25,000.
Of course, you can’t submit more than one model. That would be cheating. One of the models could perform well, the equivalent of getting 8 heads with a fair coin, just by chance.
Good thing there is a rule against it submitting multiple models, or any one of the other 99 participants and their 99 models could win, just by being lucky…
Multiple hypothesis testing
The effect we saw with Epi101’s coin applies to our competition, of course. Due to random chance, some percentage of models will outperform other ones, even if they are all just as good as each other. Maths doesn’t care if it was one team that tested 100 models, or 100 teams.
Even if certain models are better than others in a meaningful sense^, unless you truly believe that the winner is uniquely able to ML-wizard, you have to accept that at least some other participants would have achieved similar results, and thus the winner only won because they got lucky. The real “best performance” will be somewhere back in the pack, probably above average but below the winner^^.
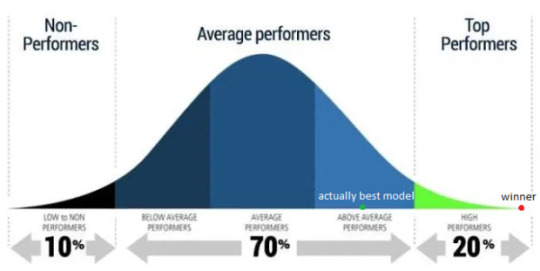
Epi101 says this effect is called multiple hypothesis testing. In the case of a competition, you have a ton of hypotheses – that each participant was better than all others. For 100 participants, 100 hypotheses.
One of those hypotheses, taken in isolation, might show us there is a winner with statistical significance (p<0.05). But taken together, even if the winner has a calculated “winning” p-value of less than 0.05, that doesn’t mean we only have a 5% chance of making an unjustified decision. In fact, if this was coin flips (which is easier to calculate but not absurdly different), we would have a greater than 99% chance that one or more people would “win” and come up with 8 heads!
That is what an AI competition winner is; an individual who happens to get 8 heads while flipping fair coins.
Interestingly, while ML101 is very clear that running 100 models yourself and picking the best one will result in overfitting, they rarely discuss this “overfitting of the crowds”. Strange, when you consider that almost all ML research is done of heavily over-tested public datasets …
So how do we deal with multiple hypothesis testing? It all comes down to the cause of the problem, which is the data. Epi101 tells us that any test set is a biased version of the target population. In this case, the target population is “all patients with CT head imaging, with and without intracranial haemorrhage”. Let’s look at how this kind of bias might play out, with a toy example of a small hypothetical population:

In this population, we have a pretty reasonable “clinical” mix of cases. 3 intra-cerebral bleeds (likely related to high blood pressure or stroke), and two traumatic bleeds (a subdural on the right, and an extradural second from the left).
Now let’s sample this population to build our test set:
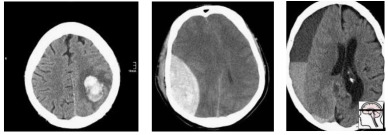
Randomly, we end up with mostly extra-axial (outside of the brain itself) bleeds. A model that performs well on this test will not necessarily work as well on real patients. In fact, you might expect a model that is really good at extra-axial bleeds at the expense of intra-cerebral bleeds to win.
But Epi101 doesn’t only point out problems. Epi101 has a solution.
So powerful
There is only one way to have an unbiased test set – if it includes the entire population! Then whatever model does well in the test will also be the best in practice, because you tested it on all possible future patients (which seems difficult).
This leads to a very simple idea – your test results become more reliable as the test set gets larger. We can actually predict how reliable test sets are using power calculations.

These are power curves. If you have a rough idea of how much better your “winning” model will be than the next best model, you can estimate how many test cases you need to reliably show that it is better.
So to find out if you model is 10% better than a competitor, you would need about 300 test cases. You can also see how exponentially the number of cases needed grows as the difference between models gets narrower.
Let’s put this into practice. If we look at another medical AI competition, the SIIM-ACR pneumothorax segmentation challenge, we see that the difference in Dice scores (ranging between 0 and 1) is negligible at the top of the leaderboard. Keep in mind that this competition had a dataset of 3200 cases (and that is being generous, they don’t all contribute to the Dice score equally).
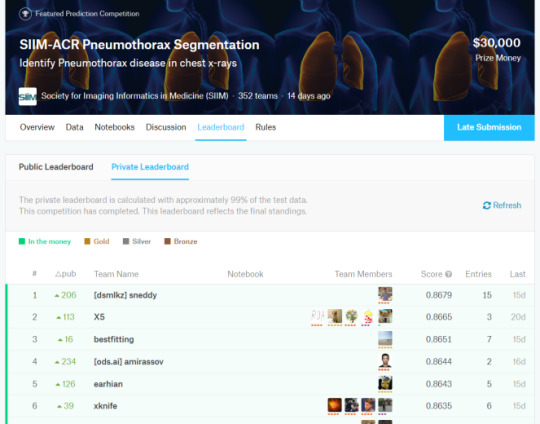
So the difference between the top two was 0.0014 … let’s chuck that into a sample size calculator.
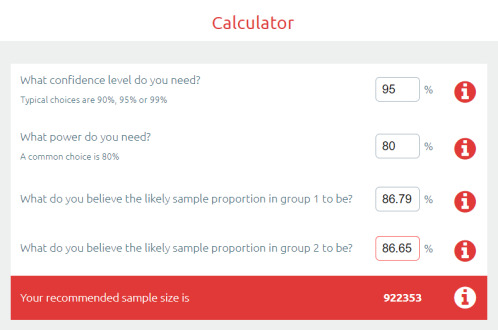
Ok, so to show a significant difference between these two results, you would need 920,000 cases.
But why stop there? We haven’t even discussed multiple hypothesis testing yet. This absurd number of cases needed is simply if there was ever only one hypothesis, meaning only two participants.
If we look at the leaderboard, there were 351 teams who made submissions. The rules say they could submit two models, so we might as well assume there were at least 500 tests. This has to produce some outliers, just like 500 people flipping a fair coin.
Epi101 to the rescue. Multiple hypothesis testing is really common in medicine, particularly in “big data” fields like genomics. We have spent the last few decades learning how to deal with this. The simplest reliable way to manage this problem is called the Bonferroni correction^^.
The Bonferroni correction is super simple: you divide the p-value by the number of tests to find a “statistical significance threshold” that has been adjusted for all those extra coin flips. So in this case, we do 0.05/500. Our new p-value target is 0.0001, any result worse than this will be considered to support the null hypothesis (that the competitors performed equally well on the test set). So let’s plug that in our power calculator.
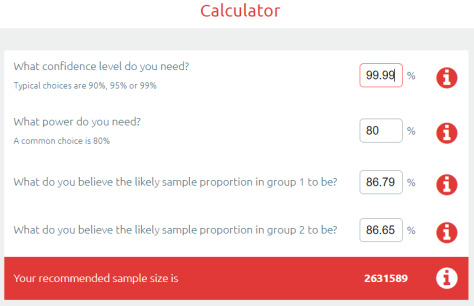
Cool! It only increased a bit… to 2.6 million cases needed for a valid result :p
Now, you might say I am being very unfair here, and that there must be some small group of good models at the top of the leaderboard that are not clearly different from each other^^^. Fine, lets be generous. Surely no-one will complain if I compare the 1st place model to the 150th model?

So still more data than we had. In fact, I have to go down to the 192nd placeholder to find a result where the sample size was enough to produce a “statistically significant” difference.
But maybe this is specific to the pneumothorax challenge? What about other competitions?
In MURA, we have a test set of 207 x-rays, with 70 teams submitting “no more than two models per month”, so lets be generous and say 100 models were submitted. Running the numbers, the “first place” model is only significant versus the 56th placeholder and below.
In the RSNA Pneumonia Detection Challenge, there were 3000 test images with 350 teams submitting one model each. The first place was only significant compared to the 30th place and below.
And to really put the cat amongst the pigeons, what about outside of medicine?

As we go left to right in ImageNet results, the improvement year on year slows (the effect size decreases) and the number of people who have tested on the dataset increases. I can’t really estimate the numbers, but knowing what we know about multiple testing does anyone really believe the SOTA rush in the mid 2010s was anything but crowdsourced overfitting?
So what are competitions for?

They obviously aren’t to reliably find the best model. They don’t even really reveal useful techniques to build great models, because we don’t know which of the hundred plus models actually used a good, reliable method, and which method just happened to fit the under-powered test set.
You talk to competition organisers … and they mostly say that competitions are for publicity. And that is enough, I guess.
AI competitions are fun, community building, talent scouting, brand promoting, and attention grabbing.
But AI competitions are not to develop useful models.
* I have a young daughter, don’t judge me for my encyclopaedic knowledge of My Little Pony.**
** not that there is anything wrong with My Little Pony***. Friendship is magic. There is just an unsavoury internet element that matches my demographic who is really into the show. I’m no brony.
*** barring the near complete white-washing of a children’s show about multi-coloured horses.
^ we can actually understand model performance with our coin analogy. Improving the model would be equivalent to bending the coin. If you are good at coin bending, doing this will make it more likely to land on heads, but unless it is 100% likely you still have no guarantee to “win”. If you have a 60%-chance-of-heads coin, and everyone else has a 50% coin, you objectively have the best coin, but your chance of getting 8 heads out of 10 flips is still only 17%. Better than the 5% the rest of the field have, but remember that there are 99 of them. They have a cumulative chance of over 99% that one of them will get 8 or more heads.
^^ people often say the Bonferroni correction is a bit conservative, but remember, we are coming in skeptical that these models are actually different from each other. We should be conservative.
^^^ do please note, the top model here got $30,000 and the second model got nothing. The competition organisers felt that the distinction was reasonable.
Luke Oakden-Rayner is a radiologist (medical specialist) in South Australia, undertaking a Ph.D in Medicine with the School of Public Health at the University of Adelaide. This post originally appeared on his blog here.
AI competitions don’t produce useful models published first on https://venabeahan.tumblr.com
0 notes
Text
Chapter 194: Jiang Yuan’s SUDDEN REPENTANCE
NO SPOILERS PLEASE!!! in the comments or anywhere on this account. We have not finished reading the novel. No copy/paste and all that other shenanigans either. Votes/likes/comments are highly appreciated.
Note: Thank you and WELCOME EMPRESS NANCY for joining us!!
It’s late, GOOD MORNING AND GOODNIGHT~ ٩꒰ ˘ ³˘꒱۶ⒽⓤⒼ♥♡̷♡̷- Sae
As a continued notice, please be advised that the “Addicted: The Novel” blog will always update the chapters earlier than here on Tumblr. Please visit https://addictedthenovel.wordpress.com for up to date postings on the translations. <per Alec>
While reading, if available, please read the footnotes at the end of the chapter for clarification.
---
《你丫上瘾了》
Chapter 194: Jiang Yuan’s SUDDEN REPENTANCE
Translator: Nancy Editor: Sae [Alec, where are you?]
That afternoon, Gu Wei Ting’s car was parked in front of the police station.
Within just second of his arrival, the Chief of Police rushed out to greet him. “General Gu, why didn’t you tell us in advance that you were coming here? I could have sent a car over to pick you up!”
Giving the eager man a quick glance of acknowledgement, Gu Wei Ting promptly headed inside the station with a wooden expression. Following closely behind him, the Chief of Police instructed his subordinate to serve a Gu Wei Ting a cup of tea.
Seeming somewhat perturbed, Gu Wei Ting waved his hand in refusal and said almost incoherently ‘there’s no need.’ Then looking squarely at the man in front of him, he resorted to not beating around the bush and bluntly asked, “What I’ve mentioned to you last time, how is it coming along?”
“We’ve been keeping surveillance on it at all time. Please wait a moment, I will retrieve the data.”
In just a short moment, the Chief of Police meticulously collated all the statistical data before handing it over to Gu Wei Ting.
These were all the recent call records collected through Bai Han Qi’s phone number. The main reason why he did not harass Bai Han Qi for information was so that he could quietly play out this plan in his own way. If he were to march to Bai Han Qi’s home, he was afraid that the disturbance would inadvertently alert him.
“We’ve organized the data in accordance with the frequency of each call from long to short distance. Generally speaking, the phone numbers that had a high frequency of calls were usually within Beijing. In all, not many were from outside of the province. In additions, the majority of calls were only made once and each time it lasted less than 10 seconds. We’ve concluded that those might have been made to the wrong numbers.”
Gu Wei Ting carefully examined the numbers from top to bottom, until he sharply focused his eyes on the fifth phone number.
“What area did this number come from?” Gu Wei Ting asked, keeping his mind open to any loophole.
The Chief of Police took a gander at it, “Oh, this is from Qingdao, Shandong. It’s considered to be one of the cities that has very frequent calls within the province.”
Gu Wei Ting narrowed his eyes in contemplation as brilliant rays of light silently flashed across his eyes, carrying with it a sense of fear that would wring anyone asunder.
-----
Once again, Gu Yang was summoned by Gu Wei Ting to the military base.
“Have you been busy lately?” Gu Wei Ting asked with a considerably soft tone.
Hearing that, Gu Yang faintly replied, “It’s been good. I have some people help out with specific projects so I only need to gather and report the collected materials.”
“There’s a small matter that I want to trouble you with, but I’m not sure whether it’s convenient for you or not.”
“Hehe. Uncle, there’s no need to be so polite with me.”
Gu Wei Ting smiled and said, “You’re an adult now. It’s only normal that I should also be courteous when speaking to you. Besides, you already have your own career. I can’t just conveniently take advantage of you just because we’re related. Nor can I randomly waste your time!”
“It’s fine, I’m not busy. Just be direct with what you have to say,” Gu Yang replied.
Noting Gu Yang’s carefree attitude, Gu Wei Ting’s complexion slightly changed as a strange look of complication took root in his gaze.
“Have you had any contact with Gu Hai?”
“No”, Gu Yang replied sternly.
Gu Wei Ting nodded his head, “Okay then. Since you’re not busy, help me search for Gu Hai and bring him back. I don’t want to use my personal power to search all over the country for him. This would be a disadvantage to my reputation if it were to leak out and worse, this kind of situation is completely unacceptable in the army.”
“Where am I supposed to find him? He had already cut off all contacts with us. At this point, looking for them is like trying to find a needle in a haystack.”
“I’ll give you a clue. They are in Qingdao, Shandong.”
After hearing those words, Gu Yang was still able to perfectly disguise the surprise that beckoned to shoot out from within his eyes. “How do you know that they’re in Qingdao?” Gu Yang asked while feigning ignorant.
“Through investigation.” Gu Wei Ting replied matter-of-factly.
Silence overtook Gu Yang.
“If I continue with the investigation, I'll definitely be able to find their exact location but I don’t want to personally handle this matter. Don’t ask me for the reason. I’m feeling really uneasy at the moment. In short, I have confidence in you and I want to entrust you with the task of dealing with this strenuous ordeal.”
A sense of guilt squirmed its way into Gu Yang’s conscience as he watched the uneasiness riddling Gu Wei Ting’s face.
“Since he has done something like this, you’re still acknowledging him as your son?”
“If I acknowledge it, he is. If I don't, then he isn't.” [1]
While Gu Yang continued to ponder on that phrase, Gu Wei Ting had already walked out of the room.
“General!”
The person standing in front of Gu Wei Ting was a man name Hua Yun Hui, a subordinate that he had personally enlisted to receive special force training. Normally, Gu Wei Ting does not call on him for assistance. The only exception to this would be when Sun Jingwei had his hands full, Gu Wei Ting would then hand over some missions for Hua Yun Hui to handle.
“I have a mission for you.”
Standing perfectly straight, Hua Yun Hui focused all his attention on his commanding general before he spoke in a seemingly monotone voice. “Yes General. I am at your service.”
“You can relax a bit.” Gu Wei Ting’s large hand pressed on Hua Yun Hui’s shoulder, “This mission involves my family matters, so there’s no need to be so serious.”
“Family matters?” Hua Yun Hui asked with curiosity, “Isn’t Sun Jingwei always in charge of your personal matter?”
“He has his hands full lately.”
The truth was, Gu Wei Ting does not fully trust Sun Jingwei anymore.
“There’s someone I want you to keep an eye on. It doesn’t matter what method you use, you must keep surveillance on his whereabouts 24/7. Don’t let him out of your sight.”
Hua Yun Hui’s nerves immediately tensed, “Who?”
“My nephew, Gu Yang.”
---
When Sun Jingwei saw Gu Wei Ting returned, he rushed to him and asked, “General, where did you go just now?”
Gu Wei Ting’s stern gaze immediately swept towards him, “What happened?”
“Just now, your wife came to look for you.”
“Jiang Yuan?” Gu Wei Ting’s brows wrinkled into a small frown, “When did she came here?”
“She just left a moment ago. I let her wait in the room but, once she saw that you weren’t here, she immediately left. General, you should show more concern towards her. When something of this nature happens, it’s only normal that everyone will find it hard to take. After all is said and done, she is a nonetheless a woman. Psychologically, she won’t be able to handle certain things as well as you do. When I saw her a moment ago, I can tell that her mental state doesn’t look too well at all.”
Glancing away, Gu Wei Ting did not say anything else. He continued to busy his time away with work late into the night before he eventually instructed the chauffeur to take him home.
Even as the darkness rolled into the night sky, Jiang Yuan has yet to be taken in by slumber. She sat alone in the dining room lost in thought.
When she heard the door opening, she slowly raised her head for a look.
As Gu Wei Ting walked in, he casually turned his head for a glance and saw Jiang Yuan sitting not too far way. The dim lighting casted against her form revealed the paleness that masked her delicate face. Jiang Yuan stood up and slowly walked towards Gu Wei Ting, her appearance was sickly and drained, unlike her usually lively self.
“Have you eaten? If not, I’ll go cook something.” She asked as she does every day.
Just as Jiang Yuan was about to turn away, Gu Wei Ting grabbed hold of her hand, “Don’t worry, I’ve eaten.”
The only word that came out of Jiang Yuan’s mouth then was “oh”.
In the past, Jiang Yuan had always longed for Gu Wei Ting to return home as soon as possible, just like an imperial concubine longing for the Emperor to personally come to her. Every night, she would lay on the bed and hope for a day where if she were to wake up in the middle of the night, the pillow beside her would unexpectedly be occupied by another person. However, even though Gu Wei Ting was calmly beside her now, she still felt nothing but emptiness.
“It’s quite late already. Why aren’t you sleeping yet?” Gu Wei Ting asked while taking in the details of her face.
Letting out a faint smile, Jiang Yuan said almost incoherently, “I can’t sleep.”
The Jiang Yuan in Gu Wei Ting’s mind was always full of life and energy. Simply put, she was straightforward, outspoken and quick to word her thoughts when needed. When she is feeling uneasy about something, gritting her teeth and fuming with anger was one of her many actions but when she consumed with happiness, she would dance around. In all, she can sometimes be vicious and lovely at other times…..so it was quite rare to see her rather quiet like this.
Gu Wei Ting held Jiang Yuan’s hand and asked with a soothing tone, “Why can’t you sleep?”
“I miss my son.” Jiang Yuan answered honestly.
Gu Wei Ting slowly closed his eyes and willed his heart rate to slow down at the anger that seemed to rose within him. For the past few days, his words were too harsh when he had randomly bellowed in anger. Thinking about his own previous actions now, he suddenly began to hate those kinds of interactions.
“You didn’t go see Ban Han Qi?”
Jiang Yuan shook her head.
Gu Wei Ting was somewhat flabbergasted. Based on Jiang Yuan’s personality, it would have not been a surprise if she had gone to the Bai’s home and cause a complete mess.
“Why didn’t you go?”
Glancing over at him with delicate eyes, Jiang Yuan softly replied, “For the past few days, I’ve been thinking about the words that Lao Bai said. He said the reason Luo Yin has feelings towards another man was because he has a mother that’s neglects him, which in turn caused him to start rejecting women.”
“That’s utter nonsense!” Gu Wei Ting said angrily. “What type of objective reasoning is that? The truth is there, is only one reason. The two of them are bastards!”
Jiang Yuan maintained her silence.
Calming himself down, Gu Wei Ting lit a cigarette and slowly smoked it.
Without any warning, Jiang Yuan started to sob spasmodically.
Gu Wei Ting turned his head for a glance, while his brows slightly pinched together.
“Look at yourself, what are you crying for? You’re already an adult...come here. Don’t cry anymore….” said Gu Wei Ting as he pulled out a tissue and wiped Jiang Yuan’s tears away.
Even then, Jiang Yuan continued to sob sporadically while saying, “I suddenly feel that my son is pitiful. Before, when he was sensible, I’ve never once thought that he was pitiful. But now that he has done something like this, I suddenly feel especially sorry and regretful. Every night, I would dream of him. And in it, he’s out in the world, alone and famish. He’s only 18 years old...other kids his age are still in their parents’ embrace, asking for something to eat and drink. Yet, my 18 years old son is wandering alone. Even though he has a home, he cannot return to it.”
Gu Wei Ting’s heart softened, however his tone is still as stern as ever.
“They brought it upon themselves. It is really worth it for you to be sorry and regretful?”
With her tears stained face, Jiang Yuan turned to face Gu Wei Ting, “Lao Gu, have you ever thought why our sons’ relationship became like this? Doesn’t it have a direct relation with our marriage?”
“What are you trying to say?” Gu Wei Ting’s vision gradually sank. “We're married. Does it make any sense for you to say these things now?”
“I don’t regretting marrying you. I’ve just been thinking why Xiao Hai grew to like Luo Yin and why Luo Yin had also grown to like Xiao Hai. As I kept thinking about it, I only found one possibility. That is, these two boys both lacked maternal love. For Xiao Hai, his mother passed away and Luo Yin was not with me since he was little. So, when they’re together, they must have felt a bit of sympathy for each other.”
“There are many people out there that lack maternal love. How many of them would actually do something like that?”
With emptiness coloring her eyes, Jiang Yuan picked up a pillow and held it against her chest.
“Lao Gu, did you know why Gu Hai suddenly changed his attitude towards you?”
Gu Wei Ting has always held some suspicions regarding this matter. At first, he wanted to ask about it, but as time went by, he thought that it was superfluous, so rather than mentioning it again, he merely took it as his son had finally gotten over it.
“It’s because Luo Yin found out the truth about Gu Hai’s mother’s death.”
Gu Wei Ting’s body shook in shock as he stared at her in incredulity. Suddenly, his pupils seemed to have split open, paving way for a luminous light to shoot out towards Jiang Yuan’s face.
“What did you say?”
Jiang Yuan choked in between sobs as she spoke, “Sun Jingwei didn’t want me to tell you. He was afraid that you’ll be upset and suffer again. And... I didn’t want to tell you either because I was afraid you’ll keep thinking of her. But now, I’m even more afraid that my son will suffer. He is the only person in this world that has my blood.”
---
Translator’s Note:
[1]认则有,不认则无 - To acknowledge it means that it exists. To not acknowledge it means it doesn't.
This translation is closer to the phrase that Gu Wei Ting said, but due to the awkwardness and cryptic meaning that it gives to the overall translation, I decided to change it. Do take note, this translation might change. - Sae
---
Are you Addicted?
Original Novel by Chai Ji Dan
We, the translators and editors, DO NOT own any of this novel’s content.
#are you addicted?#addicted the web series#addicted the novel#bailuoyin#guhai#xu weizhou#huang jingyu#chinese novel#Chinese Translations#chinese webseries#chinesebl#chai jidan
170 notes
·
View notes
Text
AI competitions don’t produce useful models

By LUKE OAKDEN-RAYNER
A huge new CT brain dataset was released the other day, with the goal of training models to detect intracranial haemorrhage. So far, it looks pretty good, although I haven’t dug into it in detail yet (and the devil is often in the detail).
The dataset has been released for a competition, which obviously lead to the usual friendly rivalry on Twitter:
Of course, this lead to cynicism from the usual suspects as well.
And the conversation continued from there, with thoughts ranging from “but since there is a hold out test set, how can you overfit?” to “the proposed solutions are never intended to be applied directly” (the latter from a previous competition winner).
As the discussion progressed, I realised that while we “all know” that competition results are more than a bit dubious in a clinical sense, I’ve never really seen a compelling explanation for why this is so.
Hopefully that is what this post is, an explanation for why competitions are not really about building useful AI systems.
DISCLAIMER: I originally wrote this post expecting it to be read by my usual readers, who know my general positions on a range of issues. Instead, it was spread widely on Twitter and HackerNews, and it is pretty clear that I didn’t provide enough context for a number of statements made. I am going to write a follow-up to clarify several things, but as a quick response to several common criticisms:
I don’t think AlexNet is a better model than ResNet. That position would be ridiculous, particularly given all of my published work uses resnets and densenets, not AlexNets.
I think this miscommunication came from me not defining my terms: a “useful” model would be one that works for the task it was trained on. It isn’t a model architecture. If architectures are developed in the course of competitions that are broadly useful, then that is a good architecture, but the particular implementation submitted to the competition is not necessarily a useful model.
The stats in this post are wrong, but they are meant to be wrong in the right direction. They are intended for illustration of the concept of crowd-based overfitting, not accuracy. Better approaches would almost all require information that isn’t available in public leaderboards. I may update the stats at some point to make them more accurate, but they will never be perfect.
I was trying something new with this post – it was a response to a Twitter conversation, so I wanted to see if I could write it in one day to keep it contemporaneous. Given my usual process is spending several weeks and many rewrites per post, this was a risk. I think the post still serves its purpose, but I don’t personally think the risk paid off. If I had taken even another day or two, I suspect I would have picked up most of these issues before publication. Mea culpa.
Let’s have a battle

Nothing wrong with a little competition.*
So what is a competition in medical AI? Here are a few options:
getting teams to try to solve a clinical problem
getting teams to explore how problems might be solved and to try novel solutions
getting teams to build a model that performs the best on the competition test set
a waste of time
Now, I’m not so jaded that I jump to the last option (what is valuable to spend time on is a matter of opinion, and clinical utility is only one consideration. More on this at the end of the article).
But what about the first three options? Do these models work for the clinical task, and do they lead to broadly applicable solutions and novelty, or are they only good in the competition and not in the real world?
(Spoiler: I’m going to argue the latter).
Good models and bad models
Should we expect this competition to produce good models? Let’s see what one of the organisers says.
Cool. Totally agree. The lack of large, well-labeled datasets is the biggest major barrier to building useful clinical AI, so this dataset should help.
But saying that the dataset can be useful is not the same thing as saying the competition will produce good models.
So to define our terms, let’s say that a good model is a model that can detect brain haemorrhages on unseen data (cases that the model has no knowledge of).
So conversely, a bad model is one that doesn’t detect brain haemorrhages in unseen data.
These definitions will be non-controversial. Machine Learning 101. I’m sure the contest organisers agree with these definitions, and would prefer their participants to be producing good models rather than bad models. In fact, they have clearly set up the competition in a way designed to promote good models.
It just isn’t enough.
Epi vs ML, FIGHT!

If only academic arguments were this cute
ML101 (now personified) tells us that the way to control overfitting is to use a hold-out test set, which is data that has not been seen during model training. This simulates seeing new patients in a clinical setting.
ML101 also says that hold-out data is only good for one test. If you test multiple models, then even if you don’t cheat and leak test information into your development process, your best result is probably an outlier which was only better than your worst result by chance.
So competition organisers these days produce hold-out test sets, and only let each team run their model on the data once. Problem solved, says ML101. The winner only tested once, so there is no reason to think they are an outlier, they just have the best model.
Not so fast, buddy.
Let me introduce you to Epidemiology 101, who claims to have a magic coin.
Epi101 tells you to flip the coin 10 times. If you get 8 or more heads, that confirms the coin is magic (while the assertion is clearly nonsense, you play along since you know that 8/10 heads equates to a p-value of <0.05 for a fair coin, so it must be legit).
Unbeknownst to you, Epi101 does the same thing with 99 other people, all of whom think they are the only one testing the coin. What do you expect to happen?
If the coin is totally normal and not magic, around 5 people will find that the coin is special. Seems obvious, but think about this in the context of the individuals. Those 5 people all only ran a single test. According to them, they have statistically significant evidence they are holding a “magic” coin.
Now imagine you aren’t flipping coins. Imagine you are all running a model on a competition test set. Instead of wondering if your coin is magic, you instead are hoping that your model is the best one, about to earn you $25,000.
Of course, you can’t submit more than one model. That would be cheating. One of the models could perform well, the equivalent of getting 8 heads with a fair coin, just by chance.
Good thing there is a rule against it submitting multiple models, or any one of the other 99 participants and their 99 models could win, just by being lucky…
Multiple hypothesis testing
The effect we saw with Epi101’s coin applies to our competition, of course. Due to random chance, some percentage of models will outperform other ones, even if they are all just as good as each other. Maths doesn’t care if it was one team that tested 100 models, or 100 teams.
Even if certain models are better than others in a meaningful sense^, unless you truly believe that the winner is uniquely able to ML-wizard, you have to accept that at least some other participants would have achieved similar results, and thus the winner only won because they got lucky. The real “best performance” will be somewhere back in the pack, probably above average but below the winner^^.
Epi101 says this effect is called multiple hypothesis testing. In the case of a competition, you have a ton of hypotheses – that each participant was better than all others. For 100 participants, 100 hypotheses.
One of those hypotheses, taken in isolation, might show us there is a winner with statistical significance (p<0.05). But taken together, even if the winner has a calculated “winning” p-value of less than 0.05, that doesn’t mean we only have a 5% chance of making an unjustified decision. In fact, if this was coin flips (which is easier to calculate but not absurdly different), we would have a greater than 99% chance that one or more people would “win” and come up with 8 heads!
That is what an AI competition winner is; an individual who happens to get 8 heads while flipping fair coins.
Interestingly, while ML101 is very clear that running 100 models yourself and picking the best one will result in overfitting, they rarely discuss this “overfitting of the crowds”. Strange, when you consider that almost all ML research is done of heavily over-tested public datasets …
So how do we deal with multiple hypothesis testing? It all comes down to the cause of the problem, which is the data. Epi101 tells us that any test set is a biased version of the target population. In this case, the target population is “all patients with CT head imaging, with and without intracranial haemorrhage”. Let’s look at how this kind of bias might play out, with a toy example of a small hypothetical population:

In this population, we have a pretty reasonable “clinical” mix of cases. 3 intra-cerebral bleeds (likely related to high blood pressure or stroke), and two traumatic bleeds (a subdural on the right, and an extradural second from the left).
Now let’s sample this population to build our test set:

Randomly, we end up with mostly extra-axial (outside of the brain itself) bleeds. A model that performs well on this test will not necessarily work as well on real patients. In fact, you might expect a model that is really good at extra-axial bleeds at the expense of intra-cerebral bleeds to win.
But Epi101 doesn’t only point out problems. Epi101 has a solution.
So powerful
There is only one way to have an unbiased test set – if it includes the entire population! Then whatever model does well in the test will also be the best in practice, because you tested it on all possible future patients (which seems difficult).
This leads to a very simple idea – your test results become more reliable as the test set gets larger. We can actually predict how reliable test sets are using power calculations.

These are power curves. If you have a rough idea of how much better your “winning” model will be than the next best model, you can estimate how many test cases you need to reliably show that it is better.
So to find out if you model is 10% better than a competitor, you would need about 300 test cases. You can also see how exponentially the number of cases needed grows as the difference between models gets narrower.
Let’s put this into practice. If we look at another medical AI competition, the SIIM-ACR pneumothorax segmentation challenge, we see that the difference in Dice scores (ranging between 0 and 1) is negligible at the top of the leaderboard. Keep in mind that this competition had a dataset of 3200 cases (and that is being generous, they don’t all contribute to the Dice score equally).
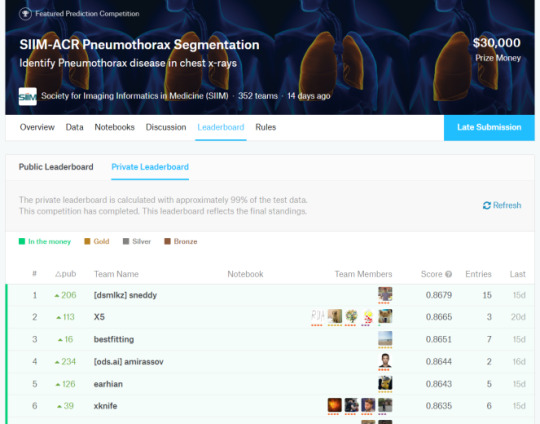
So the difference between the top two was 0.0014 … let’s chuck that into a sample size calculator.
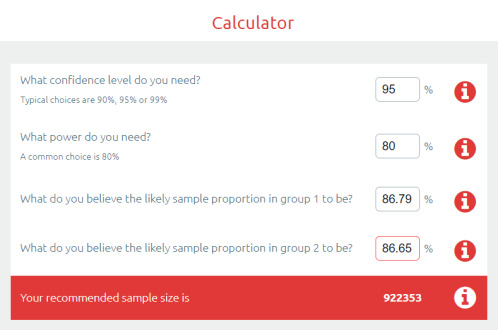
Ok, so to show a significant difference between these two results, you would need 920,000 cases.
But why stop there? We haven’t even discussed multiple hypothesis testing yet. This absurd number of cases needed is simply if there was ever only one hypothesis, meaning only two participants.
If we look at the leaderboard, there were 351 teams who made submissions. The rules say they could submit two models, so we might as well assume there were at least 500 tests. This has to produce some outliers, just like 500 people flipping a fair coin.
Epi101 to the rescue. Multiple hypothesis testing is really common in medicine, particularly in “big data” fields like genomics. We have spent the last few decades learning how to deal with this. The simplest reliable way to manage this problem is called the Bonferroni correction^^.
The Bonferroni correction is super simple: you divide the p-value by the number of tests to find a “statistical significance threshold” that has been adjusted for all those extra coin flips. So in this case, we do 0.05/500. Our new p-value target is 0.0001, any result worse than this will be considered to support the null hypothesis (that the competitors performed equally well on the test set). So let’s plug that in our power calculator.
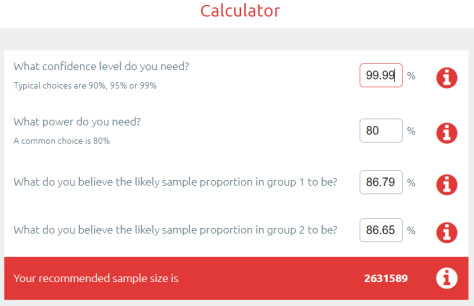
Cool! It only increased a bit… to 2.6 million cases needed for a valid result :p
Now, you might say I am being very unfair here, and that there must be some small group of good models at the top of the leaderboard that are not clearly different from each other^^^. Fine, lets be generous. Surely no-one will complain if I compare the 1st place model to the 150th model?

So still more data than we had. In fact, I have to go down to the 192nd placeholder to find a result where the sample size was enough to produce a “statistically significant” difference.
But maybe this is specific to the pneumothorax challenge? What about other competitions?
In MURA, we have a test set of 207 x-rays, with 70 teams submitting “no more than two models per month”, so lets be generous and say 100 models were submitted. Running the numbers, the “first place” model is only significant versus the 56th placeholder and below.
In the RSNA Pneumonia Detection Challenge, there were 3000 test images with 350 teams submitting one model each. The first place was only significant compared to the 30th place and below.
And to really put the cat amongst the pigeons, what about outside of medicine?

As we go left to right in ImageNet results, the improvement year on year slows (the effect size decreases) and the number of people who have tested on the dataset increases. I can’t really estimate the numbers, but knowing what we know about multiple testing does anyone really believe the SOTA rush in the mid 2010s was anything but crowdsourced overfitting?
So what are competitions for?

They obviously aren’t to reliably find the best model. They don’t even really reveal useful techniques to build great models, because we don’t know which of the hundred plus models actually used a good, reliable method, and which method just happened to fit the under-powered test set.
You talk to competition organisers … and they mostly say that competitions are for publicity. And that is enough, I guess.
AI competitions are fun, community building, talent scouting, brand promoting, and attention grabbing.
But AI competitions are not to develop useful models.
* I have a young daughter, don’t judge me for my encyclopaedic knowledge of My Little Pony.**
** not that there is anything wrong with My Little Pony***. Friendship is magic. There is just an unsavoury internet element that matches my demographic who is really into the show. I’m no brony.
*** barring the near complete white-washing of a children’s show about multi-coloured horses.
^ we can actually understand model performance with our coin analogy. Improving the model would be equivalent to bending the coin. If you are good at coin bending, doing this will make it more likely to land on heads, but unless it is 100% likely you still have no guarantee to “win”. If you have a 60%-chance-of-heads coin, and everyone else has a 50% coin, you objectively have the best coin, but your chance of getting 8 heads out of 10 flips is still only 17%. Better than the 5% the rest of the field have, but remember that there are 99 of them. They have a cumulative chance of over 99% that one of them will get 8 or more heads.
^^ people often say the Bonferroni correction is a bit conservative, but remember, we are coming in skeptical that these models are actually different from each other. We should be conservative.
^^^ do please note, the top model here got $30,000 and the second model got nothing. The competition organisers felt that the distinction was reasonable.
Luke Oakden-Rayner is a radiologist (medical specialist) in South Australia, undertaking a Ph.D in Medicine with the School of Public Health at the University of Adelaide. This post originally appeared on his blog here.
AI competitions don’t produce useful models published first on https://wittooth.tumblr.com/
0 notes
Last Seen Blogs

k1llang3lz
devyy

metallic1975
Metallic

liuxingh
无标题

yourplayersaidwhat
Shit My Players Say

kyojurotrans
★luka