#Data Hoarding
Text
Really awesome command-line programs I've discovered on GitHub
I'm a data hoarder, so all of these have to do with downloading and saving media. I also use a Mac, so all of these are MacOS-compliant via Homebrew. If you also use a Mac (or Linux), do yourself a favor and install Homebrew via Terminal right now- all you need to do is copy-paste a line of code into Terminal and it will open you up to tons of awesome programs that normally only run on Windows.
Anyway, onto the list!
Yt-dlp (Youtube/Video downloader): On top of letting you rip Youtube videos directly from the site, this program supports a huge array of other video/media websites. The program is highly customizable as well; I would highly recommend at least installing FFmpeg, which allows you to download videos in quality higher than the default 720p. Here's a guide on how to do that for Windows and I wrote a guide here for Mac (I forgot to write in the guide that you should install FFmpeg via Homebrew).
Mangadex-dl (Mangadex downloader): Allows you to download manga directly from Mangadex, the hub of scanlation. Like yt-dlp it is customizable and you can pick which chapters you want to download (useful if you only want to download current chapters you haven't gotten before).
Gallery-dl (Bulk image downloading): A godsend for an art-hoarder like me, this program allows you to bulk download things like Pixiv pages, Twitter galleries, Deviantart galleries, Instagram pages, etc. Like yt-dlp it is highly customizable. Some websites (like Pixiv) may require user authentication; the GitHub page outlines the steps each authentication process requires.
List of other command line programs you might find interesting on GitHub
I'm sure I'll add to this list as I find more cool stuff on GitHub!
638 notes
·
View notes
Text
An interoperability rule for your money

This is the final weekend to back the Kickstarter campaign for the audiobook of my next novel, The Lost Cause. These kickstarters are how I pay my bills, which lets me publish my free essays nearly every day. If you enjoy my work, please consider backing!

"If you don't like it, why don't you take your business elsewhere?" It's the motto of the corporate apologist, someone so Hayek-pilled that they see every purchase as a ballot cast in the only election that matters – the one where you vote with your wallet.
Voting with your wallet is a pretty undignified way to go through life. For one thing, the people with the thickest wallets get the most votes, and for another, no matter who you vote for in that election, the Monopoly Party always wins, because that's the part of the thick-wallet set.
Contrary to the just-so fantasies of Milton-Friedman-poisoned bootlickers, there are plenty of reasons that one might stick with a business that one dislikes – even one that actively harms you.
The biggest reason for staying with a bad company is if they've figured out a way to punish you for leaving. Businesses are keenly attuned to ways to impose switching costs on disloyal customers. "Switching costs" are all the things you have to give up when you take your business elsewhere.
Businesses love high switching costs – think of your gym forcing you to pay to cancel your subscription or Apple turning off your groupchat checkmark when you switch to Android. The more it costs you to move to a rival vendor, the worse your existing vendor can treat you without worrying about losing your business.
Capitalists genuinely hate capitalism. As the FBI informant Peter Thiel says, "competition is for losers." The ideal 21st century "market" is something like Amazon, a platform that gets 45-51 cents out of every dollar earned by its sellers. Sure, those sellers all compete with one another, but no matter who wins, Amazon gets a cut:
https://pluralistic.net/2023/09/28/cloudalists/#cloud-capital
Think of how Facebook keeps users glued to its platform by making the price of leaving cutting of contact with your friends, family, communities and customers. Facebook tells its customers – advertisers – that people who hate the platform stick around because Facebook is so good at manipulating its users (this is a good sales pitch for a company that sells ads!). But there's a far simpler explanation for peoples' continued willingness to let Mark Zuckerberg spy on them: they hate Zuck, but they love their friends, so they stay:
https://www.eff.org/deeplinks/2021/08/facebooks-secret-war-switching-costs
One of the most important ways that regulators can help the public is by reducing switching costs. The easier it is for you to leave a company, the more likely it is they'll treat you well, and if they don't, you can walk away from them. That's just what the Consumer Finance Protection Bureau wants to do with its new Personal Financial Data Rights rule:
https://www.consumerfinance.gov/about-us/newsroom/cfpb-proposes-rule-to-jumpstart-competition-and-accelerate-shift-to-open-banking/
The new rule is aimed at banks, some of the rottenest businesses around. Remember when Wells Fargo ripped off millions of its customers by ordering its tellers to open fake accounts in their name, firing and blacklisting tellers who refused to break the law?
https://www.npr.org/sections/money/2016/10/07/497084491/episode-728-the-wells-fargo-hustle
While there are alternatives to banks – local credit unions are great – a lot of us end up with a bank by default and then struggle to switch, even though the banks give us progressively worse service, collectively rip us off for billions in junk fees, and even defraud us. But because the banks keep our data locked up, it can be hard to shop for better alternatives. And if we do go elsewhere, we're stuck with hours of tedious clerical work to replicate all our account data, payees, digital wallets, etc.
That's where the new CFPB order comes in: the Bureau will force banks to "share data at the person’s direction with other companies offering better products." So if you tell your bank to give your data to a competitor – or a comparison shopping site – it will have to do so…or else.
Banks often claim that they block account migration and comparison shopping sites because they want to protect their customers from ripoff artists. There are certainly plenty of ripoff artists (notwithstanding that some of them run banks). But banks have an irreconcilable conflict of interest here: they might want to stop (other) con-artists from robbing you, but they also want to make leaving as painful as possible.
Instead of letting shareholder-accountable bank execs in back rooms decide what the people you share your financial data are allowed to do with it, the CFPB is shouldering that responsibility, shifting those deliberations to the public activities of a democratically accountable agency. Under the new rule, the businesses you connect to your account data will be "prohibited from misusing or wrongfully monetizing the sensitive personal financial data."
This is an approach that my EFF colleague Bennett Cyphers and I first laid our in our 2021 paper, "Privacy Without Monopoly," where we describe how and why we should shift determinations about who is and isn't allowed to get your data from giant, monopolistic tech companies to democratic institutions, based on privacy law, not corporate whim:
https://www.eff.org/wp/interoperability-and-privacy
The new CFPB rule is aimed squarely at reducing switching costs. As CFPB Director Rohit Chopra says, "Today, we are proposing a rule to give consumers the power to walk away from bad service and choose the financial institutions that offer the best products and prices."
The rule bans banks from charging their customers junk fees to access their data, and bans businesses you give that data to from "collecting, using, or retaining data to advance their own commercial interests through actions like targeted or behavioral advertising." It also guarantees you the unrestricted right to revoke access to your data.
The rule is intended to replace the current state-of-the-art for data sharing, which is giving your banking password to third parties who go and scrape that data on your behalf. This is a tactic that comparison sites and financial dashboards have used since 2006, when Mint pioneered it:
https://www.eff.org/deeplinks/2019/12/mint-late-stage-adversarial-interoperability-demonstrates-what-we-had-and-what-we
A lot's happened since 2006. It's past time for American bank customers to have the right to access and share their data, so they can leave rotten banks and go to better ones.
The new rule is made possible by Section 1033 of the Consumer Financial Protection Act, which was passed in 2010. Chopra is one of the many Biden administrative appointees who have acquainted themselves with all the powers they already have, and then used those powers to help the American people:
https://pluralistic.net/2022/10/18/administrative-competence/#i-know-stuff
It's pretty wild that the first digital interoperability mandate is going to come from the CFPB, but it's also really cool. As Tim Wu demonstrated in 2021 when he wrote Biden's Executive Order on Promoting Competition in the American Economy, the administrative agencies have sweeping, grossly underutilized powers that can make a huge difference to everyday Americans' lives:
https://www.eff.org/de/deeplinks/2021/08/party-its-1979-og-antitrust-back-baby
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/10/21/let-my-dollars-go/#personal-financial-data-rights

My next novel is The Lost Cause, a hopeful novel of the climate emergency. Amazon won't sell the audiobook, so I made my own and I'm pre-selling it on Kickstarter!
Image:
Steve Morgan (modified)
https://commons.wikimedia.org/wiki/File:U.S._National_Bank_Building_-_Portland,_Oregon.jpg
Stefan Kühn (modified)
https://commons.wikimedia.org/wiki/File:Abrissbirne.jpg
CC BY-SA 3.0
https://creativecommons.org/licenses/by-sa/3.0/deed.en
-
Rhys A. (modified)
https://www.flickr.com/photos/rhysasplundh/5201859761/in/photostream/
CC BY 2.0
https://creativecommons.org/licenses/by/2.0/
#pluralistic#cfpb#interoperability mandates#mint#scraping#apis#privacy#privacy without monopoly#consumer finance protection bureau#Personal Financial Data Rights#interop#data hoarding#junk fees#switching costs#section 1033#interoperability
159 notes
·
View notes
Text

Me when I stumble on another digital postcard hoarder with loads of stuff that's new to me. ;)
62 notes
·
View notes
Text
Data hoarding is only one part of the equation. Data sharing is the other half. And i don't mean on a large scale but also I mean on a large scale honestly.
But what I am getting at is if someone is looking for some data that you have then you should provide that data freely because free4free is the best way to keep media from completely disappearing. Bartering/trading will not provide those same protections.
Falling for Capitalism's idea of value and requiring any kind of prerequisite to obtain that data (money or a trade or labor) means there will be those who cannot "afford" that data because of a whole host of factors(anything from unemployment, low income, disability, etc). And that would greatly reduce the amount of redundant data in the ecosystem.
Redundant data is very important. And just because a piece of data is very popular doesn't mean it is safe from disappearing. So back up your favorite show, regardless of its popularity.
#piracy#file sharing#data hoarding#some shit some broad said while high as giraffe pussy#skinslipstuff
48 notes
·
View notes
Text
so, i once saw a self-professed data/media hoarder on tumblr whose media storage server was publicly accessible. (it had movies and tv shows and such; unfortunately i can’t find any trace of it.) i think a setup like that would be best for preserving documentation of the palestinian genocide — those news stories/images/videos need to be saved before they're scrubbed, but they won't do much good sitting on individuals' hard drives.
so we need a centralized repository that can stay up for as long as possible. ideally, anyone would be able to view it, and any vetted person would be able to add to it (vetting to limit the risk of sabotage).
long shot, but are there any data-hoarders/internet archivists/etc. on here who would be interested in helping out with that effort, or taking it on themselves?
edited to add a little context: i could easily automate the scraping of posts from instagram, tiktok, and maybe twitter and tumblr*. it’s the hosting that i’d need help with.
*i don’t think anybody is sharing firsthand documentation on tumblr, but we’ve got a lot of copies of things that may have been deleted elsewhere.
#i would call this archival‚ not 'hoarding'‚ but i'm using that tag bc it seems to be the most widely-used.#data hoarding#file sharing#internet archival#digital archiving#digital archives#if i wanted to start my own setup i'd at *least* need to get an extra laptop‚ and probably some other equipment.#and i'm not sure i could keep it up indefinitely; i'm very bad at keeping things going.#so i'm a little wary of starting this on my own#txt#palestine
18 notes
·
View notes
Text
ooooooh downloady linky clicky uwu (austin powers voice) get in mah hard drive xD 1gbps connection to Gawd himself rawr xD xD
*five minutes later*
oh god oh fuck i need more hard drives seagate red blue enterprise ironwolf pro NAS 16tb 18tb 20tb jesus fuck
9 notes
·
View notes
Text
Only in the pony fandom will someone joke about "your 3TB homework folder" and receive the reply "it's 4 actually", with evidence
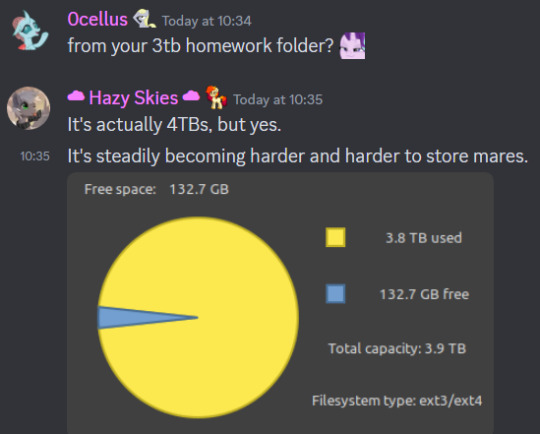
4 notes
·
View notes
Text
Anime folder is reaching the level of critical mass where going by the same folder names gogoanime/anitaku/vidstreaming assigns them is just not feasible. Also i gotta transcode this shit so it's watchable anywhere besides my own house...
We need something similar to how Linux manages block devices - /dev/disk/by-id for intrinsic hardware IDs, /dev/disk/by-label for user created names, /dev/sdXn for simple on-the-fly assignments.
I'm thinking
Move existing /shared/anime/gogo-name/S01EXX.mp4 structure into /shared/anime/by-gogo/
Add /shared/anime/by-anilist
Somehow link all one hundred and ninety-eight folders to their anilist ID numbers
Is there an existing script that does this? Like beets.io but for anime. If not oh well I'll fucking write my own. Good excuse to learn common lisp...
Transcode everything into subfolders - unmaniac looks attractive for this but haven't tried it yet
5 notes
·
View notes
Text
youtube
"You can pick this memory up right where you left it off and continue the story as if nothing had ever happened"
3 notes
·
View notes
Text
ISO:
Here are our most sought-after materials;
Seeking Shangri-La/Missing Link script (especially if containing cut materials)
Here Be Monsters! script
Any ParaNorman materials using the name Jackson
Armature photos and/or blueprints
~~~~~~~~~~~~~
Other Early Production scripts
Missing Link storyboards
Material from Canceled LAIKA productions
Laika Digital Design Group (DDG) content
Baubles / Official LAIKA image
“Making Of - The Boxtrolls Interactive Experience (video)"


The video this image is from. (Rampage took this screenshot in early 2021 and hasn’t been able to find it since)
For any information, findings, or leads, please message us or email us at [email protected]
#laika studios#the boxtrolls#laika concept art#paranorman#concept art#coraline#kubo and the two strings#missing link#behind the scenes#mod riot#seeking shangri la#here be monsters#lost media#iso#data hoarding#laika digital archive
6 notes
·
View notes
Text
Bulk downloading tools for images
I've been obsessively bulk downloading Twitter artists because of how uncertain the future of the platform is. I've also gotten into bulk downloading images as a faster alternative to my usual saving methods. I figured I might as well share the tools I use! I'm a Mac user, so all of these tools are both Mac and Windows accessible.
WFDownloader
An absolutely excellent bulk downloading tool. This app handles many more websites than gallery-dl, and it's particularly good for downloading entire Twitter pages. What's more, you can still download images from sites that aren't technically supported via the crawler feature. WFDownloader also gets major points for having highly detailed tutorials and a very responsive, helpful dev you can email for assistance.
Gallery-dl
This is a command line program, so it requires a bit of tech savvy. Most of the steps are outlined on the Github page. This program allows you to bulk download things like Pixiv pages, Tumblr blogs, Deviantart galleries, Instagram pages, etc. Some websites (like Pixiv) may require user authentication; the GitHub page outlines the steps each authentication process requires.
ESUIT
A Chrome extension that lets you bulk download Facebook galleries (something the two aforementioned tools don't do). The only drawback is that the free, basic version only lets you download the first 300 pictures in an album; you'll have to upgrade to a paid membership if you want to bulk download more than 300 photos. However, it's still a very helpful tool, especially if you're only planning on downloading smaller albums.
These are the 3 bulk downloaders I can personally vouch for, although many more exist. Feel free to recommend your own.
#data hoarding#bulk downloader#recommendation#software recommendation#software#archiving#archival#data preservation#computer programs
61 notes
·
View notes
Text

BAHAHAHAHA THEY CAN HIDE THIS IMAGE BEHIND A PAYWALL BUT NOTHING CAN STOP ME
(right click -> "select all" -> right click -> "copy" -> paste into Google Document)
#uhhh long story short I'm a data hoarder#wtf do i tag this as#data hoarding#tech literacy#idfk#the boxtrolls#crowfish crap#one of those days I'm aimlessly scrolling through nothing trying to find something I saw 2 years ago in hopes of discovering a lead and-#its complicated heheheheheh#ignore this post
2 notes
·
View notes
Text
because i’ve overcome some hardware issues i’m going to be taking down a lot of stuff from my google drive (which like... a bunch of those albums were uploaded as MP3′s and just not in a very storage friendly format). kenshi yonezu albums are staying up! and i’m gunna work on shaping up my discogs account so that if anybody really wanted, i could share albums when asked for specific stuff.
#though i sincerely doubt anyone will ask. but whatever heres the option#file sharing#piracy#data hoarding#music collection
10 notes
·
View notes
Text
not me spending 2k on a custom NAS
its gonna be a bit overkill for a NAS but I could also use it as a general server for vpn, mc, etc
#im so excited#actually starting my home lab#why all of my interests are so expensive#:3#196#egg irl#traaa#rule#ruleposting#r/196#home lab#networking#network attached storage#data hoarding#linuxserver#linuxposting#linuxuser#linux#truenas
6 notes
·
View notes
Text
Since my PC's DVD drive caught fire. I decided to replace it with something a little more useful in the modern day. If you're the kind of nerd who ends up doing data recovery for other people, want a cheap and interchangeable form of storage if you handle a lot of big files, or just miss the days of storing data on big old cartridges, a SATA hot swap bay might be for you.
3 notes
·
View notes
Text
Pinterest and tumblr really are archivist's and data hoarder's worst (possibly enjoyable) nightmare. We can't save all the images!
4 notes
·
View notes
Last Seen Blogs

sprklgender
valenrice

inquilabindia
Untitled

jckieboy
Jackie Boy

slow2life
The Life of One

jamtland
MIN DANSKE VERDEN