
jourzua
blog.jose.cl
Factura Electrónica
jose.cl
@jourzua
59 posts
Don't wanna be here? Send us removal request.
Last Seen Blogs

sentimental-bits
in my princess era

jh-object
Browsing BDSM

ziviherbals-blog1
Zivi Herbals - Ayurvedic PCD Pharma Company

klancefanfictionvault
Klance Fanfiction Vault

seo-dairies
Untitled
Text
CodificaciÃ3n de Caracteres
Por primera vez participé en la conferencia Starsconf que se desarrolló en Santiago el viernes 3 y sábado 4 de noviembre. Tuve la suerte que mi propuesta de charla fuese seleccionada y expuse sobre “CodificaciÃ3n de Caracteres”. Sí, con ese mismo título “mal” escrito. En esta publicación describiré algunos temas que se mencionaron en la presentación y dejaré también un enlace al archivo usado.
La presentación comenzó revisando de manera muy resumida la historia de las codificaciones de caracteres partiendo por la tabla ASCII. Este conjunto de caracteres, se comenzó a usar desde 1963 usando 7 bits para definir un total de 128 caracteres entre las posiciones 0 y 127:
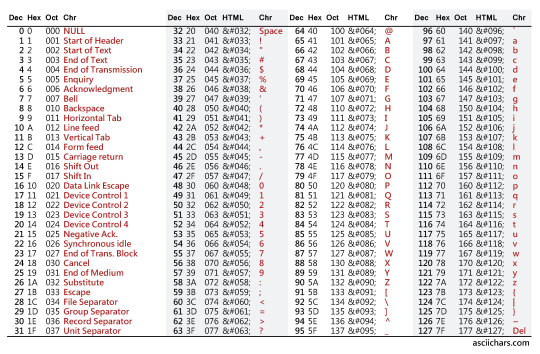
Al usar solo 7 bits, dejó un bit disponible (1 byte tiene 8 bits) que terminó siendo usado para distintas implementaciones, completando las posiciones entre 128 y 255. Al comenzar el uso de Internet y de paso el intercambio de texto entre distintos computadores, comenzaron los problemas de poder interpretar de buena forma en un computador los textos generados en otro computador. Uno de los ejemplos de conjuntos de caracteres definidos desde ASCII es ISO-8859-1 o también llamado Latin1, publicado en 1987. Este conjunto incluye 191 caracteres considerando las vocales con tilde y la letra ñ entre otros, por lo cual fue (y en algunos caso sigue siendo) usado en América, Europa Occidental, Oceanía y parte de África. En Chile no es raro encontrar instituciones que lo siguen usando, sobre todo cuando se busca tener compatibilidad con fuentes de datos de decenas de años.
Considerando la diversidad de conjuntos de caracteres definidos a partir de ASCII y los problemas asociados para interpretar de buena forma los textos, es que aparece Unicode como un conjunto de caracteres que pretende ser el estándar que incluye todos los caracteres de uso común de cualquier lenguaje escrito. Para ello, asigna a cada caracter un identificador llamado code point. En la versión 10 de este estándar publicada en junio de este año, se incluyen 136.690 caracteres considerando 56 emoticonos y hasta el signo de bitcoin. Vale la pena mencionar que por ejemplo, en Unicode se considera dar soporte a lenguajes que actualmente no están en uso pero se espera dar soporte por motivos históricos. Entre algunas propuestas podemos encontrar la solicitud de soporte para incluir rongorongo, lenguaje escrito de Rapa Nui que contiene decenas de símbolos con distintas formas y se encuentra tallado en tablas, como la siguiente imagen:

Teniendo a Unicode como estándar, es momento de considerar algoritmos para convertir de caracter a bytes. Acá es cuando aparece UTF (Unicode Transformation Format) con sus distintas implementaciones: UTF-8, UTF-16, UTF-32. Para la presentación me enfoqué en UTF-8, por ser la más común y recomendable para aplicaciones web. Esta codificación coincide con la tabla ASCII en las posiciones 32 a 127, por lo que un documento hecho con codificación ASCII es totalmente compatible y se puede procesar e interpretar sin problemas en UTF-8.
Algo en lo que hice mucho hincapié es que el “¡Texto plano no existe!”. Lo que sí existe es texto plano con una codificación asociada, esa es la forma completa de informar un documento de texto a una contraparte para que lo pueda procesar de buena manera. Comenté el ejemplo de informar una hora: para que sea totalmente claro no sirve decir “son las 13:07″, se debe acompañar de la zona horaria para que no quede lugar a distintas interpretaciones, de esa forma cualquier contraparte en cualquier zona horaria tiene claridad del valor.
A continuación, enfoqué la presentación en comentar sobre Aplicaciones Web y codificación. Para ello usé el siguiente diagrama:

En el diagrama quise dejar en claro que tenemos un cliente y un servidor que usan el protocolo HTTP, cada uno con componentes que tienen configuraciones relacionadas a codificación de caracteres. En el lado del servidor mencioné que uno debe preocuparse de la configuración de codificación del sistema operativo. Para ello, en sistemas operativos del tipo Unix se puede usar el comando locale para tener información de la codificación configurada:
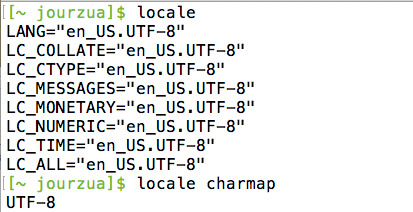
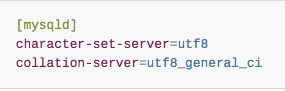
En el caso de la base de datos, es necesario considerar la configuración de codificación en el servicio de datos, en el caso de MySQL, se recomienda revisar en el archivo de configuración “my.cnf” los parámetros:
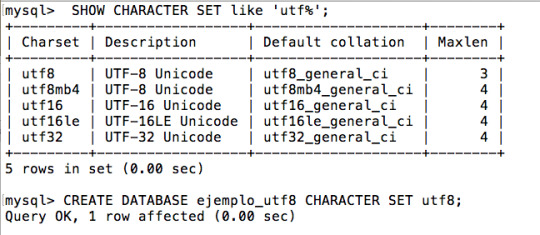
Además, se recomienda conectarse al servidor de base de datos y consultar los conjuntos de caracteres disponibles y de paso indicar el que se debe usar al momento de crear la base de datos, las tablas y las columnas:
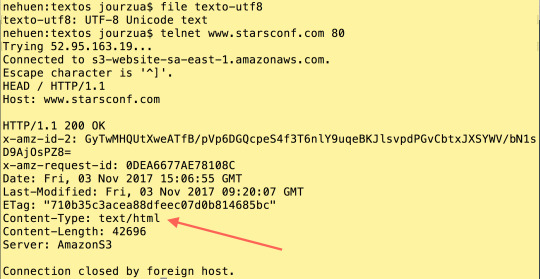
En el caso del servicio que cumple la función de servidor web, se recomienda revisar el contenido de la cabecera HTTP “Content-Type”. Se debe tener en cuenta que en la versión 1.1 del protocolo el valor default para esta cabecera es “ISO-8859-1″. En el caso del servidor web Apache, se recomienda revisar la configuración de la propiedad “AddDefaultCharset”. La configuración de un servidor web se puede probar usando el comando “telnet”, tal como se muestra en el siguiente ejemplo en donde se obtuvo las cabeceras de una petición HTTP al servidor web del sitio de la conferencia y lamentablemente no tenía el atributo “charset” asociado a la cabecera “Content-Type”:
El último tema en el lado del servidor, es lo relacionado al sistema web que se desarrolló y que atiende a los clientes. Se debe tener especial cuidado con el entorno de desarrollo, considerando la codificación de caracteres de los editores de texto que se usan para escribir código y mensajes que se transmiten al usuario. Si desde el lenguaje de programación hay una conexión a la base de datos, se recomienda usar en la URL de conexión los atributos relacionados a codificación de caracteres. Por ejemplo, para el caso de conectar desde el lenguaje Java a MySQL usando jdbc a una base de datos con codificación UTF-8 se debería usar:
jdbc:mysql://localhost:3306/mydb?useUnicode=true&characterEncoding=utf8
Cuando se genera HTML desde la aplicación, no se debe olvidar incluir el elemento <meta> en la cabecera del documento, considerando que quede entre los primeros 1024 bytes del documento. Esto último es porque algunos navegadores solo consideran estos bytes para decidir qué codificación de caracteres usarán para desplegar el documento.
En caso de necesitar convertir contenidos de una codificación a otra, se puede usar el comando iconv el cual puede ayudar, por ejemplo, a convertir texto desde Latin1 a UTF-8. La descripción de este comando es la siguiente:

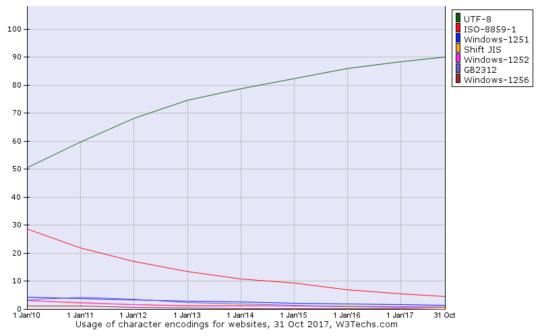
Finalmente, sobre qué codificación de caracteres usar no hay muchas dudas. Tanto la W3C como la tendencia de uso apuntan a que se debe usar UTF-8. El sitio W3Techs.com muestra la siguiente estadística de uso de encoding en sitios web para los últimos 7 años mostrando claramente el uso de UTF-8 sobre el 90% y de Latin1 bajando a cerca del 5%:
En el caso de la W3C, en la sección de preguntas frecuentes responde directamente que se debe usar UTF-8:

Como mencioné al principio de esta publicación, acá está el enlace al archivo PDF de la presentación.
0 notes
Text
Actualizar Certificado Servidor SII en Java
Cada cierto tiempo, el SII actualiza los certificados digitales de los servidores de certificación (maullin.sii.cl) y producción (palena.sii.cl) de Factura Electrónica y las comunicaciones seguras con dichos servidores comienzan a fallar porque Java no conoce y no confía en los nuevos certificados. En esta situación, es necesario obtener el nuevo certificado y se puede usar el comando openssl, por ejemplo para maullin.sii.cl:
openssl s_client -connect maullin.sii.cl:443 > maullin.pem
(para terminar debes presionar Control+C)
Este comando realiza una conexión segura con el servidor maullin.sii.cl,
mostrando al principio información acerca de la conexión e incluye el certificado del servidor. Toda esta información queda escrita en el archivo maullin.pem.
Luego de terminar la conexión (terminar el comando openssl ->
Control+C), se debe editar el archivo "maullin.pem" para extraer el
certificado. Se debe dejar todo lo que está entre las líneas
(incluyendo estas líneas):
-----BEGIN CERTIFICATE-----
-----END CERTIFICATE-----
Esto corresponde al certificado en formato PEM del servidor del SII. A
este archivo lo llamaremos maullin.pem, luego se importa usando el comando keytool de Java. En caso tener Java instalado en la ruta /usr/java/jdk1.6.0_21/, se debería ejecutar:
/usr/java/jdk1.6.0_21/bin/keytool -import -keystore /usr/java/jdk1.6.0_21/jre/lib/security/cacerts -alias SII -file maullin.pem
Ojo que se debe ajustar la ruta del archivo “cacerts” a la instalación de Java que se esté usando. El comando keytool pedirá una clave, si no se ha
asignado una anteriormente, se usa la clave: changeit
1 note
·
View note
Text
Se vienen las hass :-9
Luego de 4 años, parece que tendremos más de 1 palta :-)
0 notes
Text
Damascos!
Nuestra primera cosecha de damascos!
Lo más importante es que pasaron varias veces la prueba de calidad de Damián :-)
0 notes
Text
Iniciando la primavera con 122 árboles! :-O
Hace pocos días actualizamos la hoja de cálculo en la que mantenemos todos los árboles de la parcela, agregando los últimos ornamentales y frutales, y nos sorprendimos al darnos cuenta que ya tenemos 122 árboles! Los frutales suman 90 y los ornamentales 32.
Con tanto árbol, más aves llegan a visitarnos :-) en las dos primeras fotos hay varios jilgueros en un ciprés calvo que compramos a principios de este año:
jilgueros
jilguero
Acá hay un diucón sobre un arbusto:
diucón
Acá tenemos una pareja de tortolas sobre el nogal más grande:
tórtolas
Por estos días, los almendros están entre los primeros en producir los frutos:
Almendras
Otro frutal que es "tempranero" es el damasco, que también ya tiene frutos:
damasco
Finalmente, adjunto una foto de los cerezos, que recién comienzan su trabajo:
flor de cerezo
0 notes
Text
¿Problemas con Ubuntu 12.04 y Synergy 1.4.9?
Problema
Tengo dos equipos con Ubuntu 12.04, uno es mi Desktop y otro es mi notebook. La idea es poder usar el teclado y mouse conectado al Desktop para manejar el Notebook. Para eso existe synergy que me funcionaba muy bien en las versiones anteriores de mi sistema operativo y hardware. Ahora el problema es que logro compartir el teclado y mouse, pero cuando "vuelvo" desde el cliente al servidor, los monitores del servidor (con tarjeta Nvidia Quadro 600) se apagan y vuelven a prender, con el mensaje en syslog:

"Solución"
Después de buscar por varios lados posibles soluciones, un compañero de trabajo @m4rcool me dijo que tenía una solución, muy "chanta" y vergonzosa de recomendar, pero aquí va:
Inicie synergys en el servidor
inicie synergyc en el cliente
Mueva el mouse desde el servidor al cliente y vuelva, las pantallas se apagarán y volverán a enceder
En el servidor, presione Ctrl+Alt+F1 para pasar salir del entorno gráfico y pasar a modo consola, luedo presione Ctrl+Alt+F7 para volver al modo gráfico
Mueva el mouse desde el servidor al cliente
Problema Solucionado!!
Desconozco si el problema se origina en Ubuntu, en Unity, en el driver de nvidia o en synergy, si encuentro una solución más elegante y oficial, espero compartirla por este medio. Si usted tiene algo que pueda servir para este problema, de antemano le agradezco que lo comente acá mismo.
0 notes
Text
Etapas para la generación y envío de DTE al SII
Más de una vez me han preguntado cuales son las etapas que se deben cumplir para realizar un envío de DTE al SII, es algo básico del sistema, pero hay muchas dudas para alguien que recién comienza en esto.
En este post, enumero de manera simple las etapas:
Obtener certificado digital de persona, enrolamiento en el SII y descarga del Set de pruebas
Descarga de CAF (código autorización de folios) en la opción "Solicitud de Timbraje Electrónico" en el sitio de certificación (o de postulantes) del SII
Generar XML de DTE usando el CAF. Si descargaste un CAF que autoriza un tipo DTE 33 (factura electrónica), generas un XML que cumpla con el formato de ese DTE con un folio en el rango correspondiente, luego generas el TED (Timbre electrónico del DTE, firmando digitalmente los datos del TED usando la llave privada del CAF). Finalmente, debes firmar digitalmente todo el DTE usnado el certificado digital de persona
El paso 3) lo puedes repetir tantas veces como tantos DTE quieras generar. Luego, debes armar un XML de EnvioDTE, que corresponde al tipo de XML que el SII espera recibir. Ese EnvioDTE tiene una carátula y un conjunto de DTE que son los que generaste en 3) y se deben agregar al EnvioDTE sin hacer ninguna modificación, ni aplicar indentación ni nada. Luego firmas digitalmente el XML de EnvioDTE con el certificado digital de persona y tendrás un XML listo para enviar al SII.
Enviar al SII. En este paso, puedes hacer el upload usando un browser con la URL: Envío DTE (documentos y libros) si lo quieres automatizar, tendrás que implementar el protocolo de autenticación automática según el manual del SII: Web Service Autenticación Automática con Certificado Digital. En ese caso, debes implementar un cliente de webservice, el cual primero pide una semilla, la recibe, la firma digitalmente y pide al SII un "token" adjuntando la semilla firmada. Con ese token, puede hacer un "upload" a una URL del SII simulando un método POST de HTTP según indica el manual: Envío Automático de Documentos Tributarios Electrónicos Finalmente, debes guardar la respuesta del POST, la cual contiene un elemento llamado "trackid" que corresponde al identificador de tu EnvioDTE en el SII y lo necesitarás para cuando te llegue la respuesta del SII por email y saber a que EnvioDTE corresponde esa respuesta.
El SII recibe tus DTE, los valida y te generará una respuesta por email, al email registrado para recibir las respuesta. También puedes automatizar las consultas de estado del envío y de un DTE en particular, usando los otros webservices disponibles y el trackid que recibiste en 5)
Bueno, espero se haya entendido un poco el proceso
4 notes
·
View notes
Text
Frutas y Frutales!
En esta época ya se comienza a notar todo el trabajo de los frutales, la mayoría ya botó la flor y dan paso a los frutos. Esta primera foto muestra la flor del nogal, bastante diferente al común de las flores:
Flor de Nogal
Y en esta segunda foto aparecen las primeras nueces que se están formando:
Nueces
Las parras también están en plena actividad, el año pasado cosechamos como 3 racimos de uva, para este año al parecer habrá una producción mucho mayor:
Uvas
Los dos perales también están en plena actividad, el año pasado cosechamos una, si, una pera. Ahora se ven muchas más:
Peras
La siguiente es la foto del mancaqui, la flor es totalmente verde y ya se están formando los frutos:
Mancaqui
Los limones nos han dado frutos todo el año, acá las flores y una abeja polinizando:
Flor de limón
Los kiwis también están formando las flores, el año pasado cosechamos 5 unidades, ahora se ve abundancia de flores:
flor de Kiwi
El año pasado compramos un damasco, creció mucho y ahora dio hartas flores, acá los frutos
damascos
Por lo que se ve en la siguiente foto, el manzano se portará muy bien, estas son manzanas verde:
manzanas
Los que más se destacaron con las flores fueron los almendros, y lo mejor, los árboles se ven muy cargados de frutos, dos fotos de los almendros:
almendras
almendras
Los cerezos el año pasado nos dieron aproximadamente 7 kilos de cerezas, ahora se ve que vamos bien:
cerezas
Para el final dejo, a mi gusto, las mejores frutas: los duraznos! se ve que van muy bien todas las variedades:
durazno
durazno
durazno
Esta última foto es de una "cuculí" que hizo un nido sobre un foco halógeno que tenemos en la terraza de la casa, creemos que es un arriesgado lugar, ya que nuestra gata se trepa al parrón y queda muy cerca, pero parece no preocuparle a ella:
cuculí anidando
0 notes
Text
Como buscar nombre para un hijo(a)
Para los que somos padres, en algún momento tuvimos que pasar por la etapa de decidir el nombre que se le pondría al hijo o hija que viene en camino. Convencí a mi señora que lo óptimo era buscar el nombre cuando se tiene plena certeza del sexo de nuestro bebé y eso fue como al cuarto mes de embarazo.
El procedimiento que seguimos fue el siguiente:
Cada uno hace un listado con los nombres que le gustan. En mi caso, decidí recorrer el calendario y anotar los nombres que me gustaban. Mi señora ya tenía sus candidatos.
Con los dos conjuntos de nombres, generamos un único conjunto con los nombres que a los dos nos gustaban.
Con el listado de nombres que nos gustaban, hicimos una planilla de cálculo compartida entre la futura mamá y el futuro papá (usamos google-docs) y agregamos varias columnas con datos que nos parecían relevantes: Número de conocidos, Resultados Google, Origen, Significado, Ranking Registro Civil y Resultados Facebook.
Para el número de conocidos, simplemente totalizamos la cantidad de personas que conocíamos con ese nombre, el nombre menos repetido tendría más probabilidad de ser elegido.
Para la columna de "Resultados Google", simplemente anotamos la cantidad de resultados que nos daba Google al buscar el nombre y apellido paterno entre comillas dobles. Por ejemplo, si nos gustaba el nombre "Belarmino", en Google buscamos: "Belarmino Urzúa" (incluyendo las comillas, puede agregar site:.cl para que la búsqueda sea solo dentro de páginas .cl). Esto nos indica que tantas coincidencias existen para ese nombre con ese apellido.
Las columnas Origen y Significado las llenó mi señora, quien se encargó de buscar en Internet el origen del nombre y el significado asociado.
Para la columna del ranking del registro civil, miramos las estadísticas de nombres más comunes, considerando que un peor ranking es mejor, debido a que el nombre está menos usado. El sitio de las estadísticas es: http://www.registrocivil.cl/Servicios/Estadisticas/Archivos/NombresComunes/Nombres_Annos.htm
Para la columna de "resultados facebook", hicimos una búsqueda del nombre más el primer apellido en facebook y anotamos que tan popular era esa combinación.
Creo que el "procedimiento" podría parecer engorroso, pero al final con mi señora quedamos bien conformes, nos vimos obligados a esforzarnos en buscar un nombre que nos gustaba y que no era tan común en nuestros círculos. Además, considerando que algunas clínicas también publican el listado de nombres de los recién nacidos, se podrían agregar más columnas y mejorar la búsqueda.
Finalmente, comento que el proceso fue bien entretenido y si algún día mi hijo me pregunta porque le pusimos ese nombre, lo podemos referir a este artículo ;-)
1 note
·
View note
Photo

Lo que propone Google para "curas católicos"
14 notes
·
View notes
Text
Está llegando la Primavera!
Hace casi 3 años que escribí por última vez en este blog, desde ese tiempo hemos agregado varias cosas a la parcela y sobre todo árboles :-) Para esta temporada, ya comenzaron a aparecer las primeras flores de dos de las variedades de duraznos más tempraneros:
Mientras sacaba fotos a las flores, me encontré con un nido que quedó al descubierto luego que los espinos de la reja botaran sus hojas:
Entre todos los injertos que se hicieron, más de un árbol de durazno quedó con dos variedades. La siguiente foto muestra un "brazo" del árbol totalmente florecido y el resto sólo con botones:
Pero los primeros frutales en florecer son los almendros, el año pasado teníamos 10 y este año agregamos dos más. La siguiente foto muestra como una abeja está haciendo el trabajo de polinización en una flor del almendro:
Para este año tenemos muchas flores en los almendros, creo que debe ser por que los árboles ya cumplieron dos años desde que los tenemos:
A continuación una panorámica de todos los almendros:
Finalmente, una foto de las flores del damasco que tenemos desde el año pasado:
Espero seguir actualizando el blog esta temporada, todavía falta que broten los nogales, parras, kiwis, mancaqui, manzanos, perales, higuera, ciruelo :-)
0 notes

Photo

Lo que de verdad sucedió en Stonehenge
5 notes
·
View notes

Text
Imagen de PDF417 en Factura Electrónica
Una de las etapas que se deben enfrentar al implementar un sistema de factura electrónica, es la generación de la representación impresa del XML del DTE. En esta representación impresa, típicamente un PDF, se debe agregar un código de barras bi-dimensional llamado PDF417 que representa al Timbre Electrónico del Documento (TED).
Para generar este timbre, en Java he trabajado con la biblioteca iText que permite generar PDF y en particular PDF417. Si se decide a utilizar esta biblioteca, le recomiendo seguir los siguientes consejos:
Genere el objeto PDF417 con las indicaciones que dice el SII para columnas, filas y errores:
BarcodePDF417 pdf417 = new BarcodePDF417(); pdf417.setCodeRows(5); pdf417.setCodeColumns(18); pdf417.setErrorLevel(5); pdf417.setLenCodewords(999);
Asegúrese que el timbre se genere de forma binaria y que el texto del TED está en el encoding solicitado por el SII (ISO-8859-1). Asuma que "stringTed" contiene el contenido del TED del DTE.
pdf417.setOptions(BarcodePDF417.PDF417_FORCE_BINARY); pdf417.setText(stringTed.getBytes("ISO-8859-1"));
Genere la imagen y agréguela al documento iText. Asuma que se debe ubicar en las coordenadas (x,y) en el documento Document de iText, con un tamaño de 184 pixeles por 72 pixeles.
com.lowagie.text.Image image = pdf417.getImage(); image.setAbsolutePosition(x, y); image.scaleAbsolute(184, 72); documento.add(image);
Con esto, podrían generar sin problemas de encoding ni de lectura los timbres.
24 notes
·
View notes