
Last Seen Blogs

existing-caregiver
2002

asdgshwryhey5y-blog
드라마호스트 무료야동 비키니은꼴사진

heilsatancats
Lâl🧸

mishifoltyn
MakeShift

somsetzpuncse1982-blog
Untitled
Text
Gestión y visualización de datos
Semana 1: Cómo poner en marchas su proyecto de investigación
Conjunto de datos (NESARC)
El conjunto de datos recopila información importante para su ámbito, ahora bien, he presentado principal interés por analizar la tendencia al consumo de la nicotina a través de los cigarrillos. El conjunto de datos y libro de códigos de NESARC, crea un sondeo bastante amplio en los Estados Unidos de América, aunque mi enfoque será considerando la población mexicana que migró a su país vecino.
En cuanto a variables existe una amplia gama que se pueden considerar importantes, sin embargo, por cuestiones de factibilidad y evolución dinámica, he decidido solo las que muestran al final del documento en donde se toma en cuenta las siguientes variables:
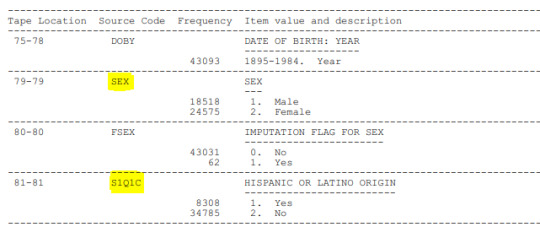
Sexo
Origen (hispano o latino)
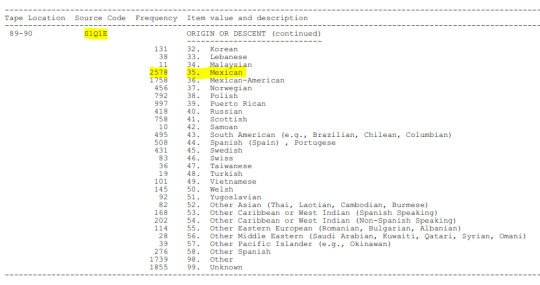
Descencencia de origen
Empleo más reciente
Frecuencia con la que se fuma (cigarrillo de tabaco)
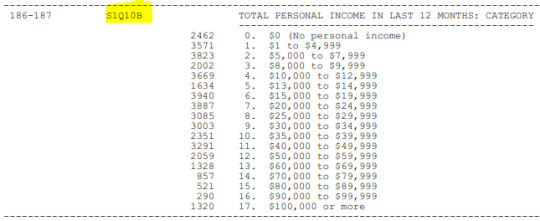
Ingreso personal (anual en dólares americanos) y
Frecuencia con la que se consume alcohol (cerveza)
Con estas variables, pretendo explorar principalmente la asociación del consumo de tabaco con el del ingreso económico y alcohol (cerveza), sugiriendo como hipotesis que las personas con dificultades económicas suelen ser propensos al consumo de tabaco y/o alcohol (cerveza).
Como segunda cuestión, considero importante relacionar el sexo, empleo e ingreso del público mexicano con descendencia hispanoamericana que vive en los Estados Unidos de América, con el propósito de averiguar las coincidencias entre los rangos de salarios y empleos, con el hábito del consumo de tabaco.
Principal cuestionamiento son:
Principalmente: ¿Las personas fumadoras generalmente cuentan con ingresos económicos elevados?
En segundo plano:
¿Influye el tipo de empleo, ingresos y/o sexo al consumo del tabaco?
¿La mayoría de los fumadores son también consumidores de alcohol? (cerveza)?
Con el fin de enriquecer la investigación, es imprescindible hacer referencias respecto al consumo de tabaco y alcohol.
“El consumo de tabaco constituye, en los países desarrollados, la primera causa de mortalidad y morbilidad en adultos que se podría prevenir. En los países desarrollados, el tabaco es responsable del 24% de todas las muertes entre hombres y del 7% entre las mujeres, aunque esta última cifra está aumentando como consecuencia de la incorporación de la mujer a esta adicción. La pérdida de esperanza de vida entre los fumadores es de 14 años de media, dato al que habría que añadir la calidad de vida perdida para resaltar fielmente la importancia de esta enfermedad adictiva”.[1]
“El tabaquismo es uno de los principales problemas de salud pública; constituye la principal causa de muerte prevenible, además de ser la primera causa de años de vida potencialmente perdidos atribuibles a mayor morbilidad y mortalidad de la población general. Con la edad aumenta la prevalencia del consumo que se inicia en edades tempranas. Asimismo, cerca del 90% de los fumadores inician antes de los 18 años.
En América Latina y el Caribe los bajos ingresos económicos se asocian con una mayor prevalencia (del 45%) en el consumo de tabaco. En especial, en Sudamérica, el riesgo de que las personas de ingresos bajos lo consuman es del 63%. Estos hallazgos concuerdan con los obtenidos por otros autores en Europa, quienes confirman la relación entre el consumo de tabaco y un estado socioeconómico bajo. Además, en cuanto a lo ocupacional, algunos autores han señalado que el desempleo es un factor de riesgo para el consumo de sustancias como el tabaco y el alcohol”.[2]
Referencias bibliográficas
[1] Villena Ferrer, A., Morena Rayo, S., Párraga Martínez, I., González Céspedes, M. D., Soriano Fernández, H., & López-Torres Hidalgo, J. (2009). Factores asociados al consumo de tabaco en adolescentes. Revista Clínica de Medicina de Familia, 2(7), 320-325.
[2] Chica-Giraldo, C. D., Álvarez-Heredia, J. F., Naranjo, Y., Martínez-Arias, M. A., Martínez, J. W., Barbosa-Gantiva, O., ... & Cardona-Miranda, L. (2021). Consumo de tabaco y condición de empleo en una región del eje cafetero colombiano. Revista de Salud Pública, 23(1), 1.
LIBRO DE CODIGOS
A continuación, se añaden screenshoot del Codebook, donde se aprecian las variables que fueron seleccionadas para el tema de investigación.



0 notes
Text
Chi-square independence test
The goal is to run a Chi-square test of independence.
The data set contains variables such as television viewing and age group. The relationship that watching television has with people of each age group will be examined.
Python code
import pandas as pd
import numpy
import scipy.stats
import matplotlib.pyplot as plt
import seaborn as sns
def faixa_etaria(row):
if row["PA2"]>=65:
return "Idoso"
elif row["PA2"]>=41:
return "Adulto"
elif row["PA2"]>=18:
return "Adulto Jovem"
elif row["PA2"]>=11:
return "Adolescencia"
else:
return "Infância"
data = pd.read_csv('addhealth_pds.csv', low_memory=False)
data['PA2'] = pd.to_numeric(data['PA2'], errors='coerce')
data['H1DA3'] = pd.to_numeric(data['H1DA3'], errors='coerce')
sub1=data[(data['PA2']>=1) & (data['PA2']<=99) & (data['H1DA3']<7)]
sub1["faixa_etaria"]=sub1.apply(faixa_etaria, axis=1)
sub1 = sub1.dropna()
sub2 = sub1.copy()
recode1 = {1: 10, 2: 20, 3: 30, 0: 1}
sub2['USFREQMO']= sub1['H1DA3'].map(recode1)
ct1=pd.crosstab(sub2['USFREQMO'], sub2['faixa_etaria'])
print (ct1)
colsum=ct1.sum(axis=0)
colpct=ct1/colsum
print(colpct)
print ('chi-square value, p value, expected counts')
cs1= scipy.stats.chi2_contingency(ct1)
print (cs1)
sub2["USFREQMO"] = sub2["USFREQMO"].astype('category')
sub2['USFREQMO'] = pd.to_numeric(sub2['USFREQMO'], errors='coerce')
sns.barplot(data=sub2, x="USFREQMO", y="faixa_etaria",errorbar=None)
plt.xlabel('Days per month')
plt.ylabel('Age Group')
Python Output

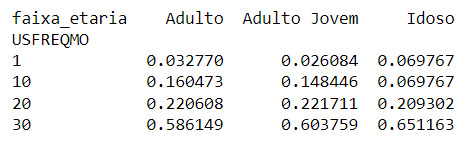

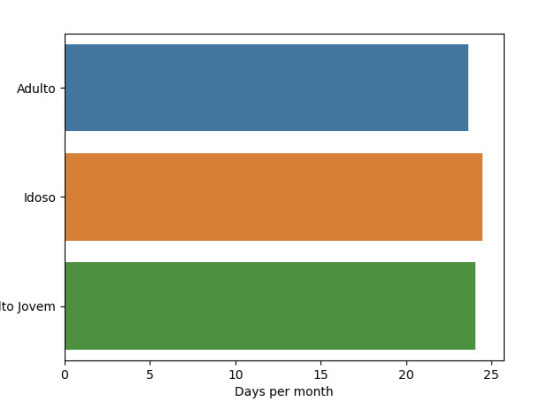
Conclusion
As p-value (0.19) is greater than 0.05, there exists no relationship between the time wacthing television and age group people.
The bar diagram also shows that have no signaficative differences in the graph which further suggests no relationship between the two variables.
This way, the Post-hoc test is not necessary for examining the relationship as there is no significant relationship.
0 notes
Text
Data Analysis Tools
The final task deals with testing a potential moderator. By testing a potential moderator, which makes us wonder if there is an association between two constructs for different subgroups within the sample.
The data set contains variables about purchases in some regions, to determine whether any age group purchases more in-store or out-of-store.
Qualitative variables: In.Store, region
Quantitative variables: Age, Amount, items
Python code
import pandas as pd
import statsmodels.formula.api as smf
import seaborn
import matplotlib.pyplot as plt
def ageGroup(row):
if row["age"]>60:
return "Senior "
elif row["age"]>30:
return "Adult"
elif row["age"]>=18:
return "Young"
elif row["age"]>9:
return "Teenage"
else:
return "Child"
data = pd.read_csv('Demographic_Data_Orig.csv', low_memory=False)
data['age'] = data['age'].apply(pd.to_numeric, errors='coerce')
data['items'] = data['items'].apply(pd.to_numeric, errors='coerce')
data['amount'] = data['amount'].apply(pd.to_numeric, errors='coerce')
data["AgeGroup"]=data.apply(ageGroup, axis=1)
data = data[["region","items","in.store","amount", "AgeGroup"]].dropna()
model1 = smf.ols(formula='amount ~ C(region)', data=data).fit()
print (model1.summary())
recode1 = {1: 'In', 0: 'Out'}
data['in.store']= data['in.store'].map(recode1)
sub1 = data[['amount', 'in.store']].dropna()
print ("means for Amount by Region")
m1= sub1.groupby('in.store').mean()
print (m1)
print ("standard deviation for mean Amount by In vs Out Store")
st1= sub1.groupby('in.store').std()
print (st1)
seaborn.barplot(x="in.store", y="amount", data=data, ci=None)
plt.xlabel('In Store')
plt.ylabel('Amount')
sub2=data[(data['AgeGroup']=='Young')]
sub3=data[(data['AgeGroup']=='Adult')]
print ('association between in-store and out-of-store purchases - Young')
model2 = smf.ols(formula='amount ~ C(region)', data=sub2).fit()
print (model2.summary())
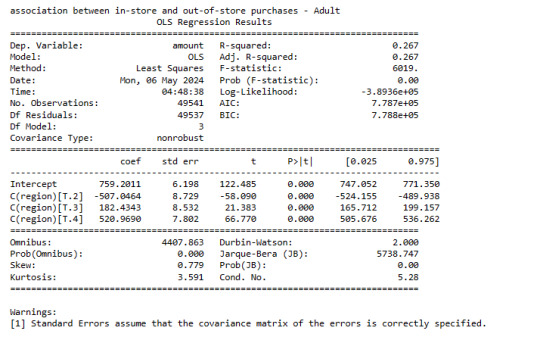
print ('association between in-store and out-of-store purchases - Adult')
model3 = smf.ols(formula='amount ~ C(region)', data=sub3).fit()
print (model3.summary())
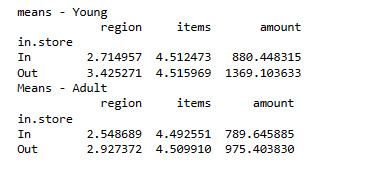
print ("means - Young")
m3= sub2.groupby('in.store').mean()
print (m3)
print ("Means - Adult")
m4 = sub3.groupby('in.store').mean()
print (m4)
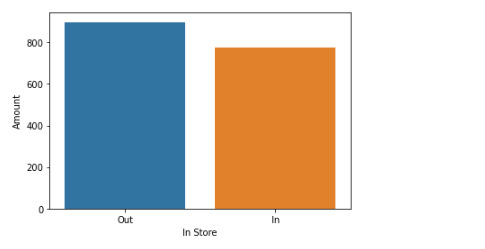
General Result
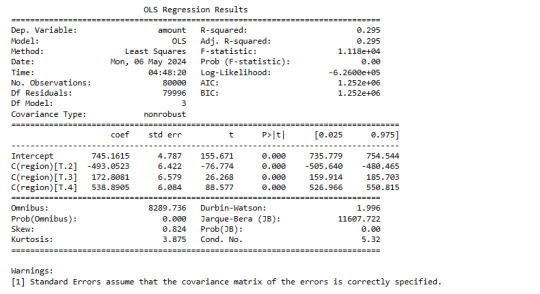
Young Group
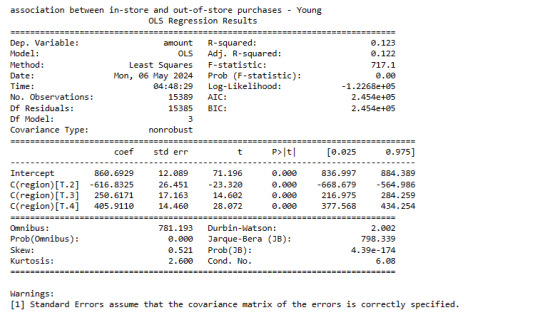
Adult Group
Mean
0 notes
Text
Data Analysis Tools - Correlation
The objective is to generate a Correlation Coefficient, this type of coefficient is used when there are two quantitative variables. For this task, the correlation between life expectancy, CO2 emissions and breast cancer will be used. The dataset used is gap Minder (https://www.gapminder.org/).
Python code
import pandas as pd
import numpy
import seaborn
import scipy
import matplotlib.pyplot as plt
df = pd.read_csv('gapminder.csv', low_memory=False)
df['co2emissions'] = df['co2emissions'].apply(pd.to_numeric, errors='coerce')
df['breastcancerper100th'] = df['breastcancerper100th'].apply(pd.to_numeric, errors='coerce')
df['lifeexpectancy'] = df['lifeexpectancy'].apply(pd.to_numeric, errors='coerce')
df=df[(df['lifeexpectancy']>=1) & (df['lifeexpectancy']<=100) & (df['co2emissions']<1000000000) ]
print(max(df['co2emissions']))
print(min(df['co2emissions']))
df['lifeexpectancy']=df['lifeexpectancy'].replace(' ', numpy.nan)
df['co2emissions']=df['co2emissions'].replace(' ', numpy.nan)
df['breastcancerper100th']=df['breastcancerper100th'].replace(' ', numpy.nan)
df.breastcancerper100th *=10000
df.co2emissions /=1000
df1=df.dropna()
df2=df1
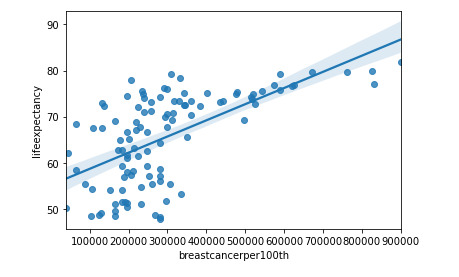
graf1= seaborn.regplot(x="breastcancerper100th", y="lifeexpectancy", fit_reg=True, data=df1)
plt.xlabel('Breast cancer')
plt.ylabel('Life Expectancy')
plt.title('Scatterplot for the Association Between Life Expectancy and Breast cancer')
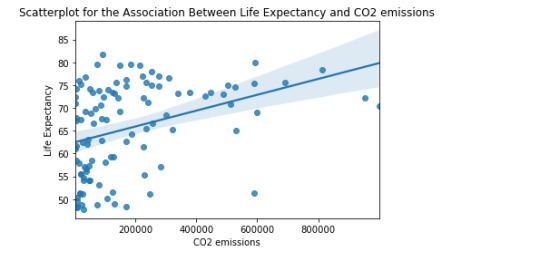
graf2 = seaborn.regplot(x="co2emissions", y="lifeexpectancy", fit_reg=True, data=df1)
plt.xlabel('CO2 emissions')
plt.ylabel('Life Expectancy')
plt.title('Scatterplot for the Association Between Life Expectancy and CO2 emissions')
data_clean=df.dropna()
print ('association between Life Expectancy and co2emissions')
print (scipy.stats.pearsonr(data_clean['co2emissions'], data_clean['lifeexpectancy']))
print ('association between Life Expectancy and Breast cancer')
print (scipy.stats.pearsonr(data_clean['breastcancerper100th'], data_clean['lifeexpectancy']))

0 notes
Text
ANOVA Analysis
Course "Data Analysis Tools" on the Coursera platform corresponding to week 01. The objective is to execute an Analysis of Variance using the ANOVA statistical test, this analysis evaluates the measurements of two or more groups that are statistically different from each other. It is mainly used when you want to compare the measurements (quantitative variables) of groups (categorical variables).
The hypotheses are the following:
H0="There is no difference in the mean of the quantitative variable between groups (categorical variable)"
H1= While the alternatives there is a difference.
The Code in Phython
import numpy as ns
import pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
import statsmodels.stats.multicomp as multi
import matplotlib.pyplot as plt
import seaborn as sns
import researchpy as rp
import pycountry_convert as pc
df = pd.read_csv('gapminder.csv')
df = df[['lifeexpectancy', 'incomeperperson']]
df['lifeexpectancy'] = df['lifeexpectancy'].apply(pd.to_numeric, errors='coerce')
def income_categories(row):
if row["incomeperperson"]>15000:
return "A"
elif row["incomeperperson"]>8000:
return "B"
elif row["incomeperperson"]>4000:
return "C"
elif row["incomeperperson"]>1000:
return "D"
else:
return "E"
df=df[(df['lifeexpectancy']>=1) & (df['lifeexpectancy']<=120) & (df['incomeperperson'] > 0) ]
df["Income_category"]=df.apply(income_categories, axis=1)
df = df[["Income_category","incomeperperson","lifeexpectancy"]].dropna()
df["Income_category"]=df.apply(income_categories, axis=1)
print (rp.summary_cont(df['lifeexpectancy']))

fig1, ax1 = plt.subplots()
df_new = [df[df['Income_category']=='A']['lifeexpectancy'], df[df['Income_category']=='B']['lifeexpectancy'], df[df['Income_category']=='C']['lifeexpectancy'], df[df['Income_category']=='D']['lifeexpectancy'], df[df['Income_category']=='E']['lifeexpectancy']]
ax1.set_title('life expectancy')
ax1.boxplot(df_new)
plt.show()
results = smf.ols('lifeexpectancy ~ C(Income_category)', data=df).fit()
print (results.summary())
print ("Tukey")
mc1 = multi.MultiComparison(df['lifeexpectancy'], df['Income_category'])
print (mc1)
res1 = mc1.tukeyhsd()
print (res1.summary())
print ('means for for life expectancy by Income')
m1= df.groupby('Income_category').mean()
print (m1)
print ('Results')
print ('standard deviations for life expectancy by Income')
sd1 = df.groupby('Income_category').std()
print (sd1)
Conclusions – ANOVA Analysis
An ANOVA test is carried out, integrated by 176 rows, 171 will be used for the test. A filter is applied to eliminate some incorrect values, such as non-numeric, negative, etc., reducing the rows of the original data set.
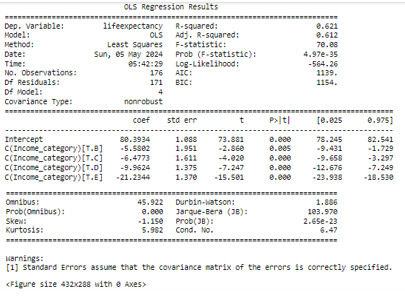
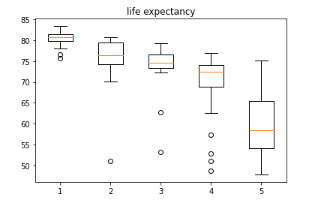
The ANOVA analysis shows a graph for each category (at the top) and, as can be seen, the life expectancy of class A, has a life expectancy of 80.39 years while the E class has a life expectancy of 59, 15 years


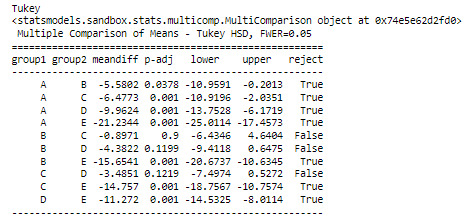
1 note
·
View note