
Last Seen Blogs

izzyneedsabreak
just trying to get bi

myprincesspassion
Sans titre

jimmerzz0905
I JUST WANTED MY CHEEEEEEEEEEESE

iiboronii
everyone's favorite silly goose

taacky-phoenix
Phoenix
Text
Análisis de texto aplicado a las respuestas de una pregunta abierta de un cuestionario.
Presentamos un ejemplo de cómo analizar una pregunta abierta en un cuestionario, utilizando las técnicas de Minería de Texto.
La pregunta en un cuestionario ficticio, es la siguiente:
¿Qué lo motiva a continuar comprando en Almacenes "Lo Nuestro"?
Almacenes "Lo Nuestro", son una cadena de almacenes de herramientas por membresía. La pregunta tiene 350 respuestas efectivas.
1. DISTRIBUCIÓN DE FRECUENCIAS DE LAS PALABRAS.
Nube de palabras total.

En primer lugar analizamos la nube de palabras con las palabras más frecuentes, en donde claramente resalta Precios, seguido de Productos , Ser Socio, Calidad y Buenos. Por lo que claramente se observan menciones a atributos positivos de los almacenes.
Nube de palabras de segundo plano.
Zoom eliminando las más frecuentes de la nube anterior

Para profundizar en este análisis de palabras, podemos observar la siguiente nube de palabras en la que excluimos las 10 palabras más frecuentes, esto para hacer un "zoom" sobre palabras que en la primer nube pueden pasar desapercibidas.
En este caso se presentan las palabras que tienen una frecuencia de 5 o más.
Distribución de Frecuencias de Palabras.
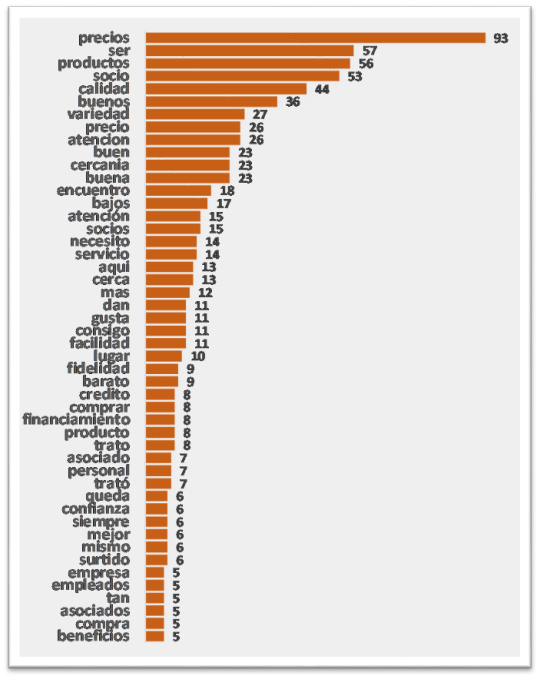
“Verbatims” para las palabras Precios y Productos.

Podemos acompañar las palabras más frecuentes con algunos "verbatims":
• Los precios y la calidad de los productos.
• Tiene buenos precios y variedad de productos.
• precios bajos y variedad de marcas y productos.
• La calidad y los precios de los productos.
• buenos productos y precios.
2. ANÁLISIS EXPLORATORIO DE FRASES.
En el análisis de textos, podemos ir avanzando desde la "descripción" de las palabras utilizadas a la fase de mayor profundidad que nos permita reconocer frases y tendencias en las respuestas.
Dendograma de las palabras más frecuentes.

El Dendrograma es una herramienta muy útil para determinar la asociación de palabras en frases. Por ejemplo podemos apreciar asociaciones de palabras como Productos + Calidad, también Ser + Socio, Atención + Buena, Encuentro + Consigo + Necesito. Incluso podemos asociar palabras en un segundo nivel como: [ ( Productos + Calidad ) + Precios ], o { [ ( Consigo + Necesito ) + Encuentro ] + Cercanía }.
El dendrograma nos permite asociar palabras y encontrar sentido a estas palabras dentro de un contexto específico.
Otra herramienta indispensable en el análisis del texto es la formación de conglomerados de palabras o "Clusters". Tiene un sentido similar al Dendrograma, pero además nos ayuda a determinar aspectos más profundos al graficar las palabras en un plano bidimensional, lo que nos permite determinar patrones en las respuestas.
Mapa de Cluster en dos dimensiones.
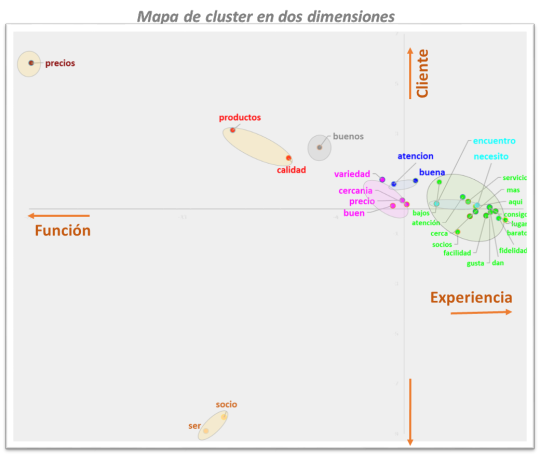
En este "mapa" podemos observar los clusters o agrupaciones de palabras, pero además, tenemos dos ejes de coordenadas que nos permiten contextualizar las palabras. En este caso observamos en el eje vertical la "relación" con los almacenes, en dónde las reacciones de las personas se muestran en la dualidad de ser socio y cliente. Por otro lado, en el eje horizontal, observamos la otra dualidad del consumidor: la funcionalidad y la experiencia.
3. TÓPICOS DE RESPUESTAS.
Con este análisis podemos determinar la pertenencia de las palabras a diversos tópicos, con una medida de asociación al tópico.
Tópicos
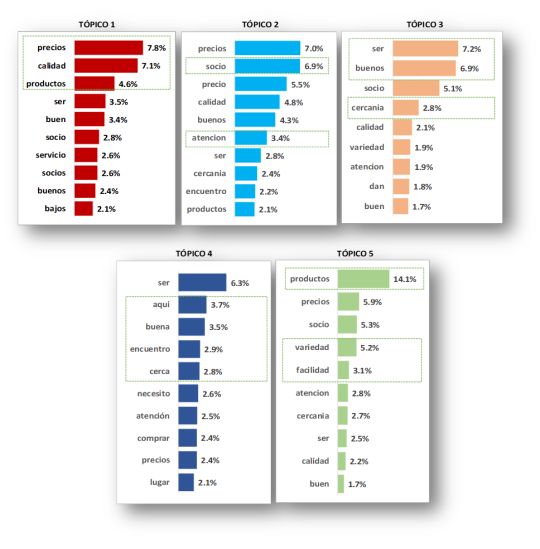
En este caso, tenemos un primer tópico compuesto por las palabras Precios + Calidad + Productos, que se complementa con las palabras Ser Socio + Buen + Producto. Sin embargo, hay un segundo tópico en que la palabra socio tiene una más fuerte medida de pertenencia, en este tópico, también encontramos Atención y Cercanía, pero ésta última tiene una mayor pertenencia al tercer tópico. Finalmente, podemos determinar cinco tópicos principales en este análisis:
1. Precio ( + Calidad + Productos ).
2. Socio ( + Atención ).
3. Buenos ( + Cercanía ).
4. Encuentro ( + Cerca + Aquí + Buena).
5. Variedad ( + Productos + Facilidad ).
4. ANALISIS DE SENTIMIENTOS.
Finalmente, en este análisis, incluimos la relación de cada una de las respuestas con una gama completa de sentimientos:
Sentimientos.
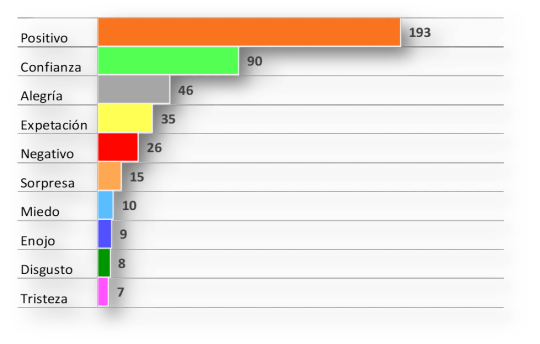
El sentimiento de mayor relevancia en las respuestas es Positivo, seguido por Confianza, Alegría, Expectación, todos éstos sentimientos expresan reacciones positivas. Los negativos quedan en una segunda posición, con mucha menor frecuencia.
Hicimos un recorrido sobre las principales herramientas de análisis de textos, aplicado a las respuestas a una pregunta abierta de un cuestionario.
Para el procesamiento de los datos se utiliza el software libre R.
Enlace al Sitio Web.
#TextMining#Cuestionario#Preguntas abiertas#Análisis de Contenido#Procesamiento de Lenguaje Natural#Lenguaje Natural#datascience#r#cran
0 notes
Text
Función autocompletar de Excel para textos
En el video adjunto, mostramos paso a paso, como a partir de columnas con nombres y apellidos, se pueden columnas adicionales con diferentes combinaciones de forma sencilla y rápida.
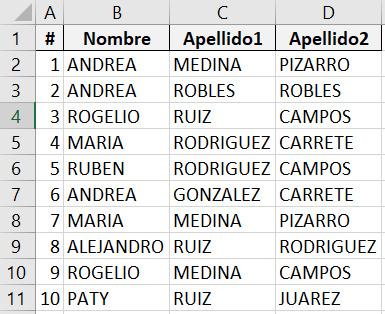
Partimos de las tres columnas, para crear adicionales:
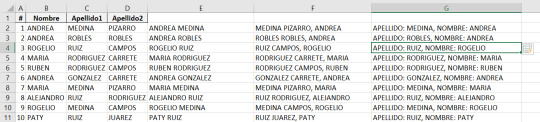
El video que explica como se construyen:
youtube
1 note
·
View note
Text
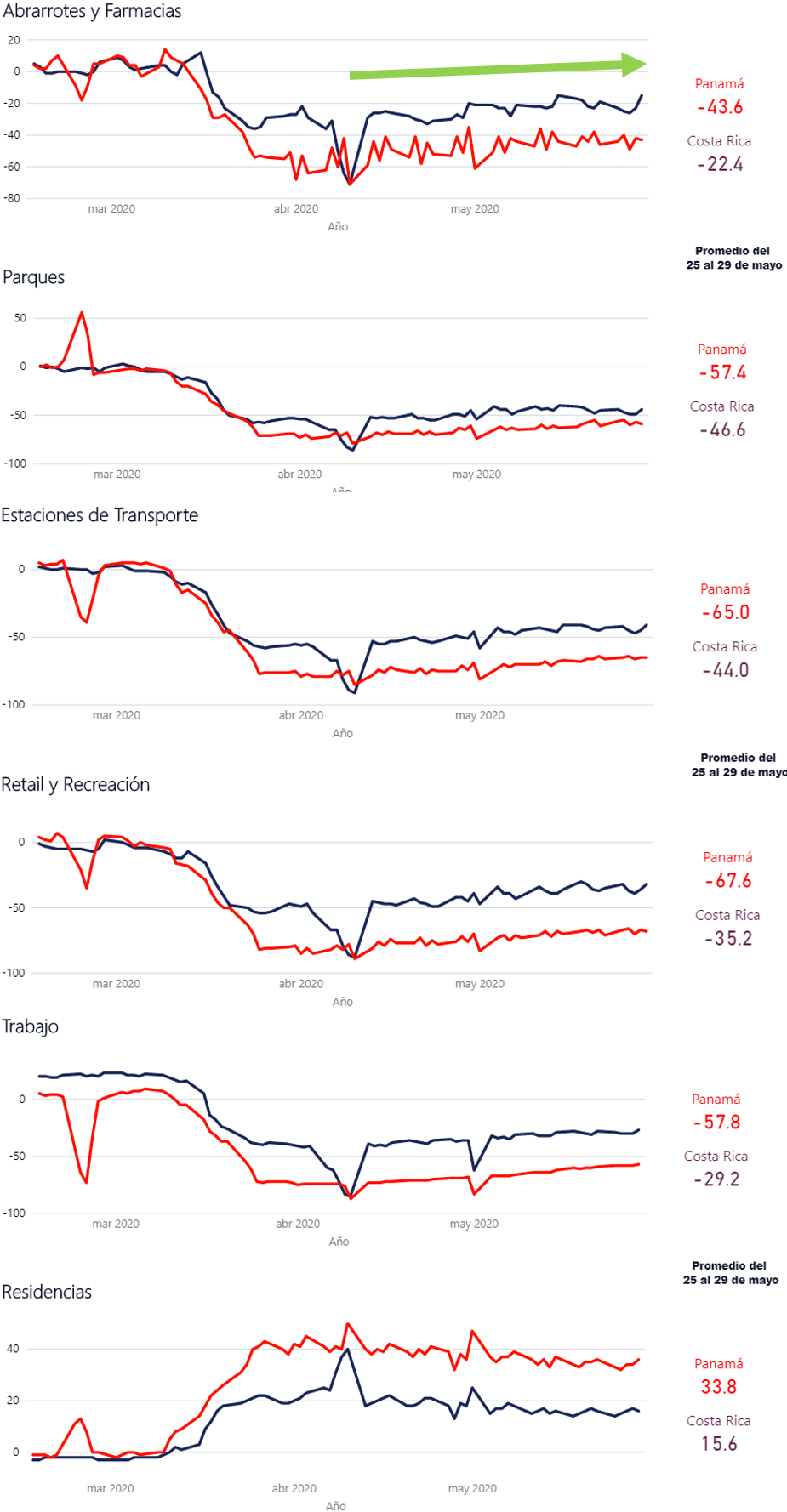
Movilidad en Costa Rica y Panamá al 29 de mayo del 2020
Los datos sobre la movilidad suministrada por Google, como medida de distanciamiento social, nos sirven para comparar a Costa Rica y Panamá, países vecinos con diferencias en las restricciones para diminuir el contacto, y con diferencias en los casos positivos y defunciones acumuladas.
Ambos países vecinos tiene diferencias importantes en las formas para disminuir el contacto social, Panamá tiene una cuarentena obligatoria y permite solamente salir por algunas horas y algunos días a la semana, para comprar en supermercados y farmacias. En Costa Rica las autoridades hacen el llamado a la conciencia ciudadana y han cerrado centros educativos, bares y restaurantes, además se restringe la circulación de vehículos privados algunos días.
Los casos positivos y defunciones presentadas son muy diferentes: Panamá acumula 4.016 casos y Costa Rica 642, en cuanto a defunciones, Panamá alcanza 109 y Costa Rica 4 (al 17 de abril)
Los resultados para lograr el distanciamiento social muestran a Panamá con mejores resultados, sin embargo la diferencia para los últimos días se reduce.
Google suministra la información en porcentajes con respecto a los días antes de los primeros casos de Covid-19 presentados en la Región.
0 notes
Text
Macaya y los “detectives”
En Twitter en Costa Rica se ha presentado polémica por declaraciones del Presidente Ejecutivo de la Caja Costarricense del Seguro Social, indicando que los líderes comunales se convertirían en “detectives” contra el COVID-19.
Dadas las reacciones a favor y en contra, nos dimos a la tarea de recopilar los Tweets que contienen la palabra “Macaya” y construir las redes de comunicación establecidas por la discusión en Twitter.
Este primer post, presenta los grafos de la comunicación de 1806 tweets y re-tweets que se emitieron entre el 6 de junio del 2020 a las 0 horas (GMT) y el 9 de junio del 2020 a la 1:09 (GMT).
Los nodos (puntos) corresponden a cuentas de Twetter y las aristas (líneas) a las relación entre nodos (envío y/o recepción del tweet).
Los colores de los nodos corresponden a los “cluster” o grupos identificados por medio de la modularidad (Modularity class).
El tamaño de los nodos, corresponde al vector de centralidad (eigenvector centrality), que es una medida de la influencia del nodo en la red, por lo que a mayor tamaño, mayor influencia sobre la red tiene ese nodo.
El tamaño del texto corresponde al grado de entrada (número de interacciones recibidas por el nodo).
La forma general del grafo es:

En la siguiente imagen se identifican los nodos con mayor relevancia (grado de entrada superior a 5:
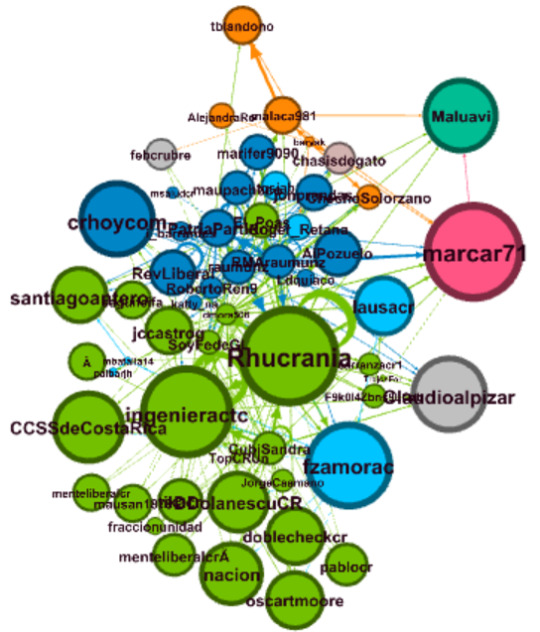
En adelante, veremos un acercamiento por sectores del grafo:
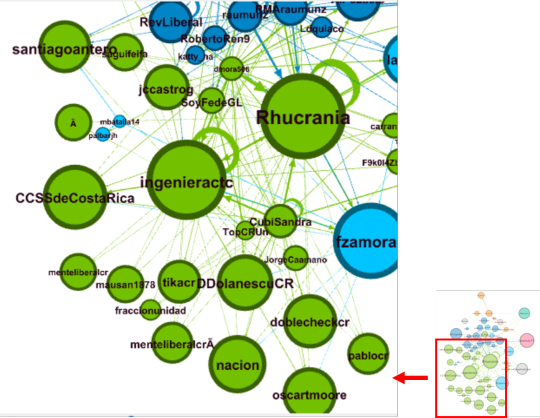
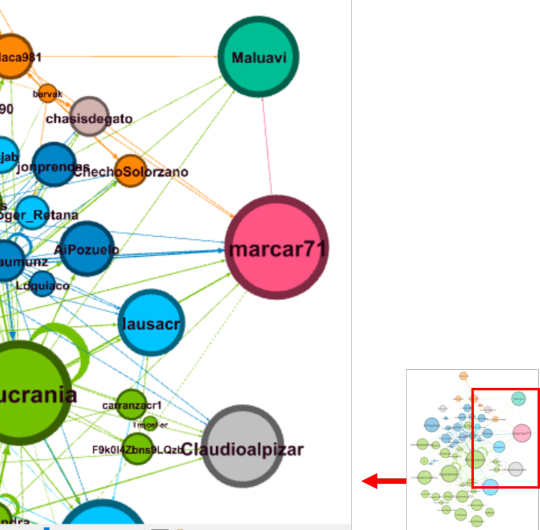
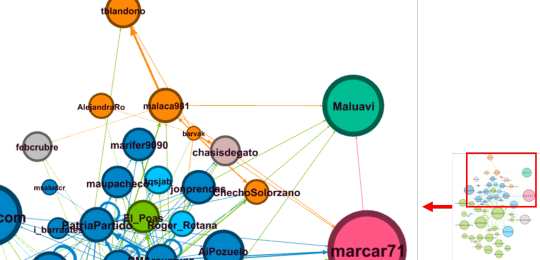
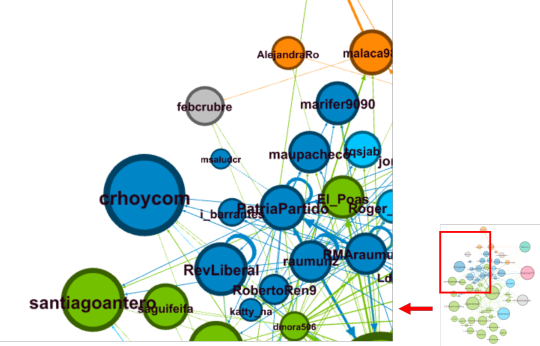
Una vista más reducida, es la que muestra los nodos con un grado de entrada de 10 o más:
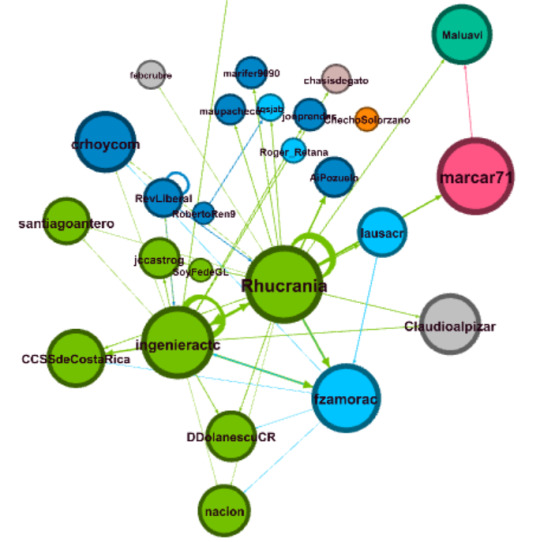
En el siguiente post profundizaremos en el diálogo establecido.
La extracción de datos se realizó con R y para los grafos y sus estadísticas se utilizó Gephi.
0 notes
Link
0 notes
Text
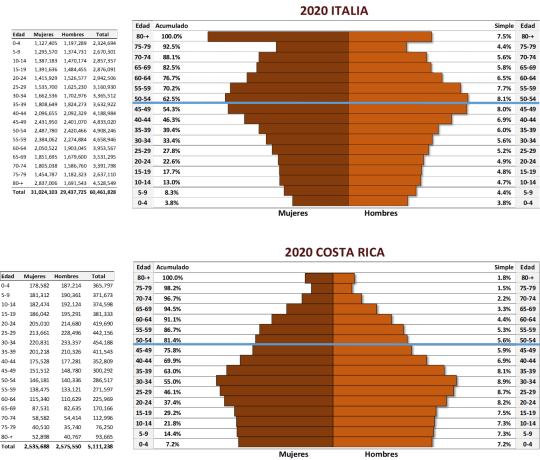
Estructura de la Población por Edad y Sexo: Italia y Costa Rica
Esta es una muy breve comparación de Costa Rica e Italia sobre estructura de la población por grupos de edad y sexo. Como se observa, en Italia el 46% de la población tiene 50 años o más, en Costa Rica es el 24%. Mayores de 80 años en Italia son el 7,5% en Costa Rica 1.8%. En Italia, con 30 años o menos son 33,4%, en Costa Rica 55%. Dado que el COVID-19, en menores de 30 años, produce efectos muy leves y en muchos casos sus síntomas pasan desapercibidos, y que en mayores de 80 años puede ser grave, todas las comparaciones que se hagan entre Italia y Costa Rica, deben corregir el efecto de la edad. Si solo se comparan datos totales, eso invalida la comparación.
0 notes
Photo

en Parque Andrés Bello https://www.instagram.com/p/B5oO3HTnFEDVwzk5uTVs9O1PILsILZH4MH5CDA0/?igshid=1mh4vpa5286yh
0 notes

Text
Interpolación espacial con R
Este caso, muestra como realizar la interpolación espacial utilizando R.
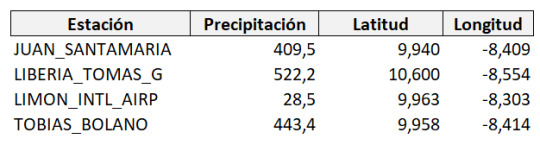
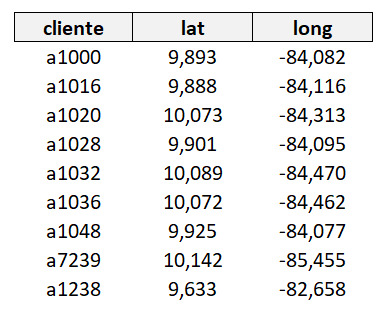
En primer lugar se tienen los datos de precipitación registrados el mismo día en un mes de octubre, en cuatro estaciones meteorológicas oficiales de Costa Rica. Además se tienen los datos de 9 puntos para los que se desea estimar la precipitación de ese día.
Para mostrar los resultados sobre un mapa, se utiliza el mapa con la división político-administrativa de Costa Rica, en su división por cantones (municipios), el mapa se tiene en formato shapefile.
Las estaciones con su ubicación y medición de precipitaciones son:
Los puntos para obtener las precipitaciones son:
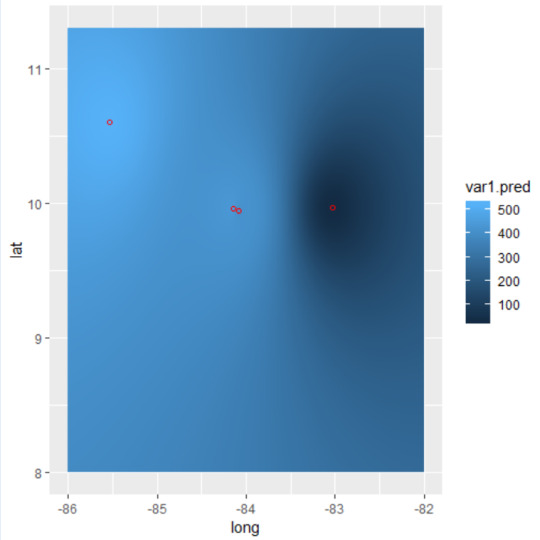
Este es el gráfico de los cuatro puntos en coordenas x-y (longitud-latitud):

El resultado de la interpolación, utilizando el modelo IDW y una grilla definida con espaciamiento de 0.01 es:
El gráfico, ahora sobre el mapa de Costa Rica es:
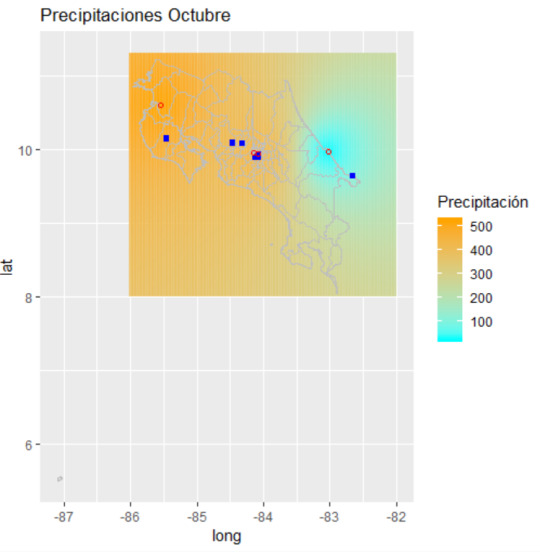
En este mapa, se muestran los puntos de las estaciones meteorológicas (circulos rojos), los puntos de interés (cuadros azules) y la grilla definida para la interpolación (cubre todo el país). El mapa se extiende mucho más al sur, debido a la Isla del Coco, que se encuentra bastante lejana al sur de Costa Rica.
Mediante la función extract, es posible obtener el valor de precipitación en cualquier punto de la grilla definida.
El modelo finalmente se puede almacenar en un archivo con formato raster y se puede utilizar como una capa más en cualquier modelo geoespacial.
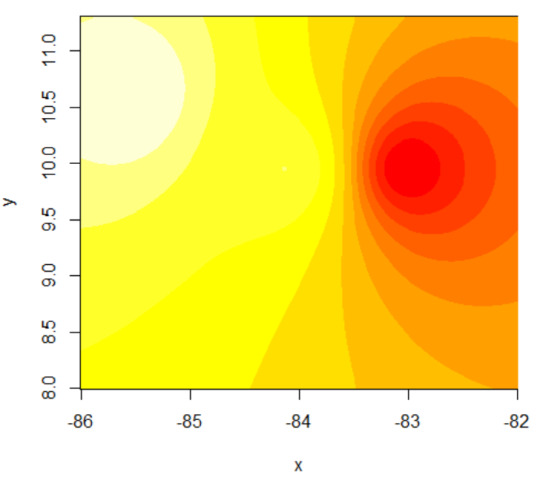
El shapefile con los cantones de Costa Rica se puede obtener en este vínculo:
https://www.dropbox.com/sh/phol9gybuka9ude/AACX6zDKUNfTP7uK82yYibExa?dl=0
El código utilizado en R es:
library(ggplot2)
library(gstat)
library(sp)
library(maptools)
library(ggmap)
library(mapproj)
library(rgdal)
library(raster)
### Estaciones meteorológicas con datos de precipitación y latitud-longitud
dat <- read.table(text = "
lugar precip lat long
JUAN_SANTAMARIA 409.460 9.93991 -84.08670275
LIBERIA_TOMAS_G 522.240 10.60000 -85.54000
LIMON_INTL_AIRP 28.460 9.9631 -83.02569
TOBIAS_BOLANO 443.440 9.95782 -84.13913
", header = TRUE)
## Lista de puntos de venta con código y latitud-longitud
clientes <- read.table(text = "
cliente lat long
a1000 9.89274 -84.0818
a1016 9.8877 -84.1156
a1020 10.0734 -84.31323
a1028 9.90068 -84.0945
a1032 10.0887 -84.46963
a1036 10.0719 -84.46165
a1048 9.92472 -84.0768
a7239 10.141909 -85.454643
a1238 9.63282 -82.65808
", header = TRUE)
dat2 <- dat
dat2$x<-dat$long
dat2$y<-dat$lat
coordinates(dat2) = ~x+y
## muestra puntos en coordenadas x.y
plot(dat2)
## Define el cuadrante geográfico para mostrar los datos en coordenadas x-y longitud-latitud
x.range <- as.numeric(c(-86,-82)) # min/max longitude of the interpolation area
y.range <- as.numeric(c(8, 11.3)) # min/max latitude of the interpolation area
## Construye la grilla de puntos en el cuadrante definido en saltos de 0.01
## La grilla es necesaria para construir el modelo de interpolación de las precipitaciones
grd <- expand.grid(x = seq(from = x.range[1], to = x.range[2], by = 0.01), y = seq(from = y.range[1], to = y.range[2], by = 0.01)) # expand points to grid
coordinates(grd) <- ~x + y
gridded(grd) <- TRUE
## muestra la grilla con los puntos de las estaciones meteorológicas
plot(grd, cex = 1.5, col = "grey")
points(dat2, pch = 1, col = "red", cex = 1)
## se construye el modelo espacial con la interpolación de las precipitaciones utilizando la grilla definida.
idw <- idw(formula = dat$precip ~ 1, locations = dat2, newdata = grd)
idw.output = as.data.frame(idw) # output is defined as a data table
names(idw.output)[1:3] <- c("long", "lat", "var1.pred") # give names to the modelled variables
## Utiliza el mapa en formato shapefile de la división política administrativa de Costa Rica (detalle cantones=municipios)
cantones <- readOGR("C:/ruta/crican1.shp")
## Grafica el modelo de interpolación
ggplot() +
geom_tile(data = idw.output, aes(x = long, y = lat, fill = var1.pred)) +
geom_point(data = dat, aes(x = long, y = lat), shape = 21, colour = "red")
## Gráfica el modelo sobre el mapa de costa rica.
ggplot() +
geom_tile(data = idw.output, alpha = 0.8, aes(x = long, y = lat, fill = round(var1.pred, 0))) +
scale_fill_gradient(low = "cyan", high = "orange") +
geom_path(data = cantones, aes(long, lat, group = group), colour = "grey") +
geom_point(data = clientes, aes(x = long, y = lat), shape = 15, colour = "blue") +
geom_point(data = dat, aes(x = long, y = lat), shape = 21, colour = "red") +
labs(fill = "Precipitación", title = "Precipitaciones Octubre")
### Para extraer los valores de precipitación de acuerdo al modelo idw, se utiliza extract:
## extrae un valor particular
## Punto cercano a Limon (este-centro), menores lluvias
pointa <- SpatialPoints(cbind(-83.02,9.96))
a<-extract(map_raster,pointa)
## extrae un valor particular
## Punto cercano a Liberia (norte-oeste del país), mayores lluvias
pointb <- SpatialPoints(cbind(-85.54,10.6))
b<-extract(map_raster,pointb)
## Punto intemedio
## extrae un valor particular
## Punto cercano a San José (centro)
pointc <- SpatialPoints(cbind(-84,10))
c<-extract(map_raster,pointc)
## Para crear el objeto raster con la interpolación
model_idw<-cbind(idw)
map_raster <- rasterFromXYZ(model_idw)
image(map_raster)
## Almacena archivo raster creado en la interpolación
writeRaster(map_raster, "C:/ruta/inter_precip.grd",overwrite=TRUE )
0 notes
Text
http://tinyurl.com/y2sclxrf
Comparto una publicación sobre procesamiento y análisis electrónico de lenguaje natural, aplicado al discurso de @NitoCortizo en su proclamación como presidente electo de Panamá. #Panama #NitoCortizo #Elecciones2019
0 notes
Text
Análisis de redes en Twitter: tweets con mención a tres candidatos presidenciales en Panamá. 23 de Abril del 2019.
Utilizando el paquete SocialMediaLab de R, se realizó la extracción de los tweets con mención a alguno de los tres candidatos analizados: @NitoCortizo, @RicardoLombanaG y @romuloroux. Los tweets utilizados, corresponden a los últimos 250 para cada candidato, antes de las 9 am del 23 de abril del 2019.
Por medio de SocialMediaLab se crearon las redes dirigidas para cada uno de los candidatos y por medio del Software Gephi se construyeron los grafos (gráficos de redes con nodos y aristas dirigidas). También con Gephi se calcularon algunas estadísticas de los grafos. Además se utilizó Excel para presentar algunas tablas.
El análisis de redes nos permite visualizar las interacciones de diferentes cuentas de Twitter, así como calcular algunas estadísticas de esas redes y también construir agrupaciones de cuentas (cluster de nodos). Esto permite determinar personas o cuentas influyentes en las redes asociadas a algunos candidatos. Las agrupaciones de cuentas además permite analizar los textos de los tweets enfocados en cada uno de los grupos y determinar “influenciadores” positivos o negativos. Esta última parte la abordaremos en un post posterior. En este analizaremos la topología de las redes y algunos estadísticas.
Para aclarar algunos términos del análisis de redes:

Los resultados son:

Se observa que la mayor cantidad de nodos la obtiene @RicardoLombanaG, seguido por @romuloroux y luego @NitoCortizo; en aristas, la mayor cantidad es para @romuloroux, seguido por @RicardoLombanaG y finalmente @NitoCortizo.
Luego revisaremos las mediciones de Modularidad y Longitud Media del Camino.
@NitoCortizo
El gráfico para @NitoCortizo, muestra una amplia influencia de su nodo y varios sub-comunidades con nodos con menor influencia:
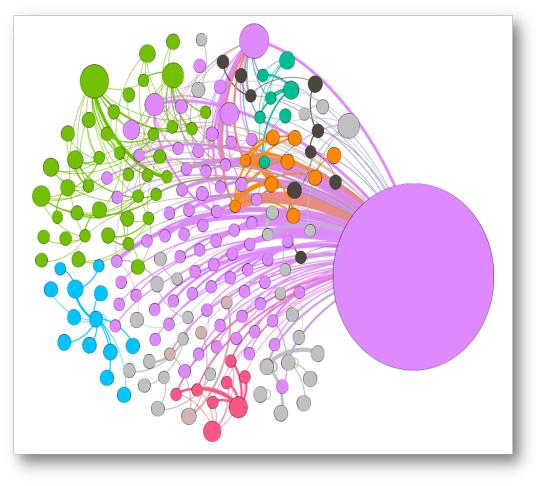
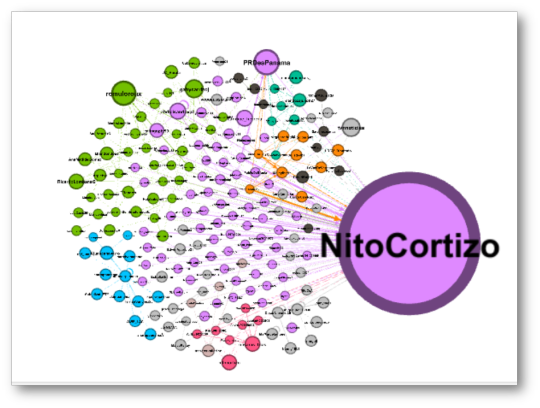
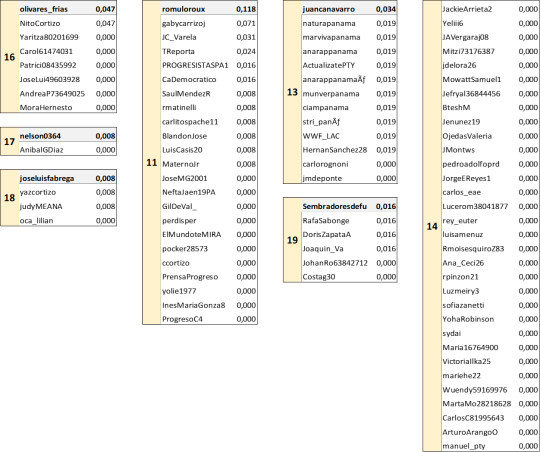
La red se compone de 19 nodos, algunos muy pequeños pero resaltan comunidades “lideradas” por NitoCortizo, RicardoLombanaG, tvnnoticias, DavidSaied, LRCV_Diputado, mendozajulioh27, olivaresfrias, romuloroux, juancanavarro, sembradoresdefu.

@RicardoLombanaG
La red de RicardoLombanaG, muestra una gran cohesión hacia su persona, con subcomunidades menos dominantes:
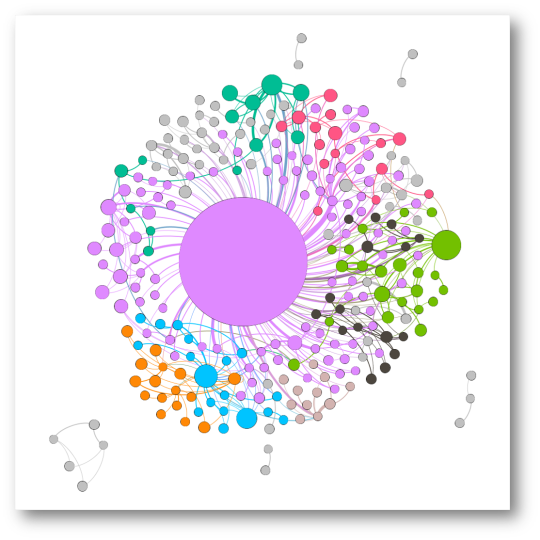

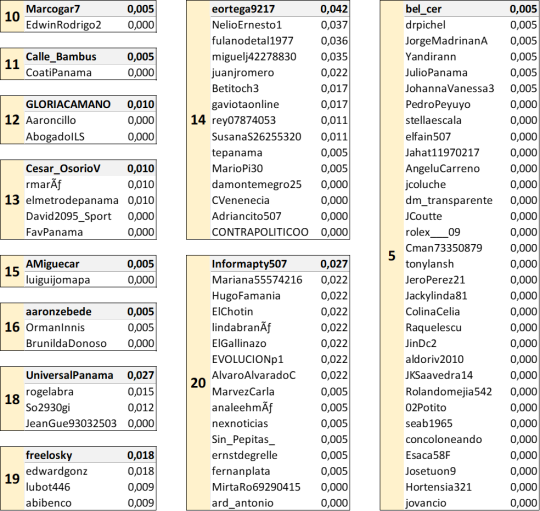
La red de RicardoLombanaG al contener mayor cantidad de nodos, genera más subcomunidades, las más relevantes: TReporta, tvnnoticias, cristal_lawson, eortega9217, bel_cer, informapty507, BlandonJose, asdrubal_ulloa.


@romuloroux
Esta red presenta diferencias con respecto a las dos anteriores: tiene un alto grado de centralidad en romuloroux, pero a la vez presenta dos nodos de gran influencia en la red: su candidato a la vicepresidencia LuisCasis20 y la cuenta de la emisora de radio Oeste985. También de destaca una fuerte presencia del nodo de NitoCortizo.

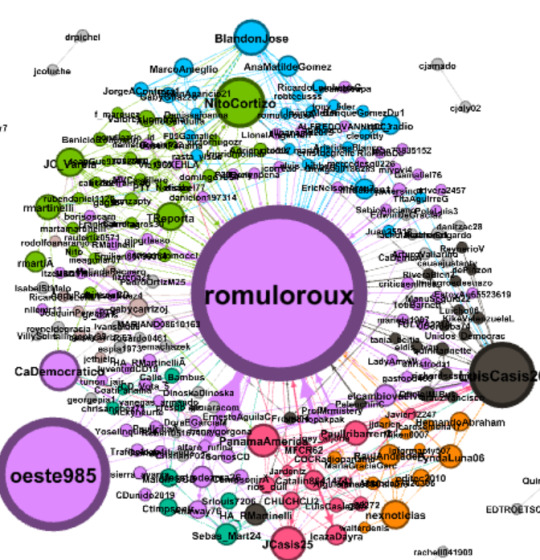
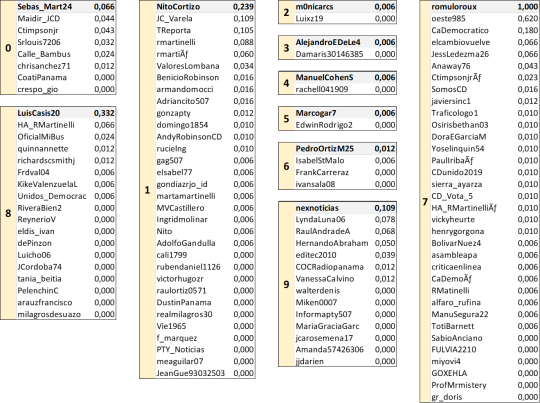
A diferencia de las redes de los otros dos candidatos, la red de romuloroux presenta dos nodos de gran relevancia: LuisCasis20, Oeste985, NitoCortizo, CaDemocratico y BlandonJose. Seguidos de otros nodos de fuerte influencia: nexnoticias, gabycarrizoj y JCasis25.

Aunque la disposición aplica para estudios por muestreo (encuestas), dado que la Ley de Panamá exige que cualquier publicación relacionada con las próximas elecciones, aclaramos que este NO es un estudio de carácter científico.
0 notes
Text
Panamá: el primer debate presidencial en Twitter, 20 de febrero del 2019 (Parte 1).
Presentamos un breve análisis de las reacciones en Twitter al primer debate presidencial realizado en Panamá, este 20 de febrero de 2019.
La ley local, exige aclarar que este análisis NO utiliza la metodología de muestreo probabilístico, por lo que este análisis NO es de carácter científico.
Sin embargo, los datos corresponden a la totalidad de tweets (censo), que se emitieron entre las 7 pm y 11 pm, del día 20 de febrero del 2019, en la red social Twitter. Los tweets analizados contienen alguna de las siguientes palabras: NitoCortizo, MarcoAmeglio, AnaMatildeGomez, RicardoLombanaG ,Romuloroux, BlandonJose, SaulMendezR, correspondientes a los nombres de las cuentas de cada uno de los 7 candidatos presidenciales. Además, las metodologías utilizadas para analizar y representar los análisis, son aceptadas científicamente.
Aclaramos que este análisis es descriptivo y muestra los datos relevantes, pero no toma posturas políticas, ni hace juicios de valor.
La nomenclatura utilizada es la siguiente:
LCortizo (@NitoCortizo)
AMGomez (@AnaMatildeGomez)
JBlandon (@BlandonJose)
MAmeglio (@MarcoAmeglio)
RLombana (@RicardoLombanaG)
RRoux (@Romuloroux)
SMendez (@SaulMendezR)
En esta primera parte, mostraremos las reacciones de forma cuantitativa, en la segunda parte, incluiremos las reacciones expresadas en los textos de los tweets.
El total de tweets en el periodo de análisis para los siete candidatos es de 17,001. A continuación mostramos, la totalidad de tweets con las menciones a alguno de los candidatos presidenciales, hora a hora, de 7 pm a 11 pm (20 de febrero del 2019), distribuidos por candidato:
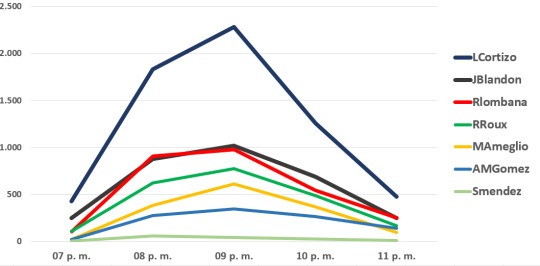
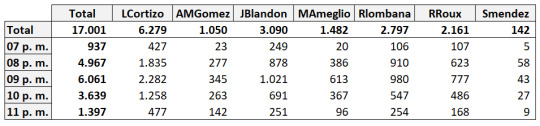
La siguiente, es la distribución por minuto para la totalidad de tweets del periodo, incluyendo los 7 candidatos:
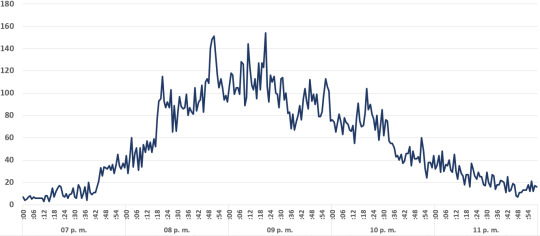
A continuación, las gráficas, minuto a minuto para cada uno de los siete candidatos:
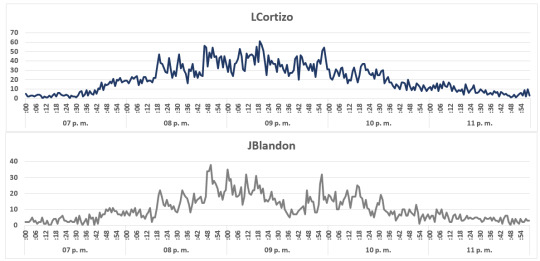

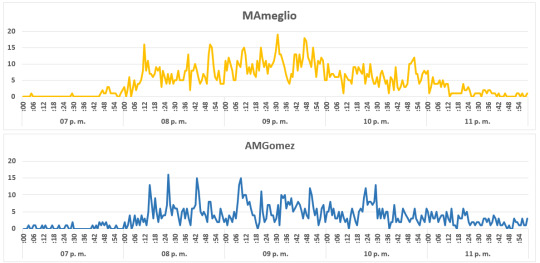
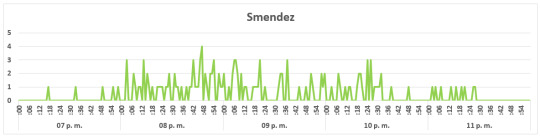
En la segunda parte, presentaremos, un análisis de las reacciones en twitter, utilizando técnicas de análisis de textos, para la totalidad de tweets por candidato, y las reacciones durante los momentos en que los candidatos obtienen la mayor cantidad de reacciones durante el debate.
Nota: para la extracción de datos de twitter se utilizó el software R, las librerías SocialMediaLab y tm. Para la construcción de nubes de palabras y dendogramas de palabras la librería wordcloud. Además se utiliza Excel para procesamiento y presentación de los datos.
#datamining#data mining#bigdata#big data#cran#r#panama#eleccionespanama2019#panamá#socialmedialab#tm#wordcloud#twitter
0 notes
Link
0 notes
Text
#MartinelliExtraditado en Twitter
Se analizan los tweets con el hashtag #MartinelliExtraditado entre el 9 de junio y el 13 de junio a las 8:00 am (hora de Panamá).
En total se procesaron 2.704 tweets.
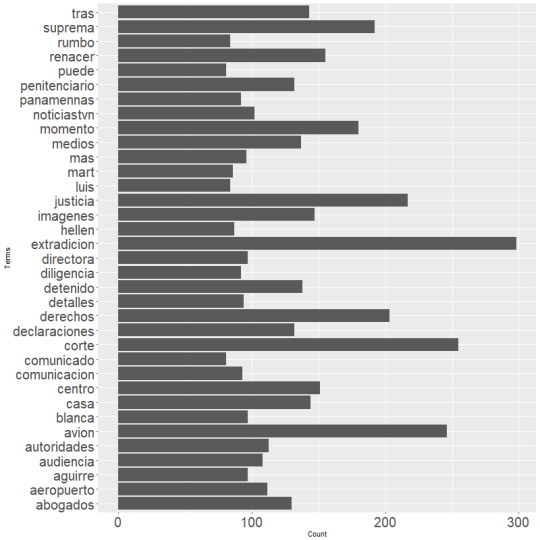
Las palabras más frecuentes (más de 80 menciones) son:
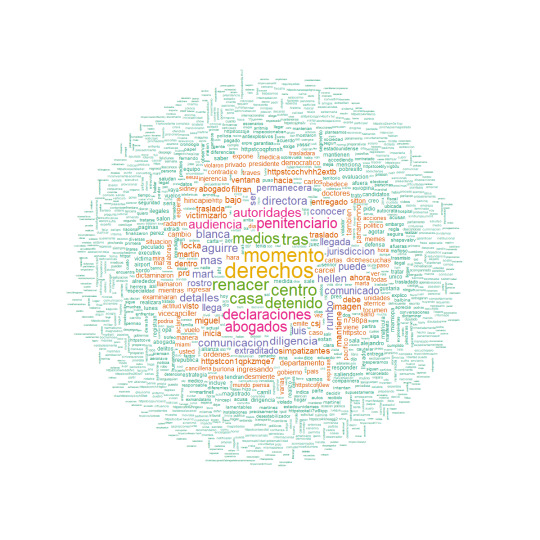
Las palabras más relevantes se presentan en la siguiente nube de palabras:

Eliminando las más frecuentes:
Los temas más mencionados son:
Las Declaraciones de Hellen Aguirre, directora de medios de la Casa Blanca; sobre la extradición del expresidente.
La imagen del rostro del expresidente al conocer el sitio en que permanecería detenido.
Diversas menciones a la Corte Suprema de Justicia.
Filtración de imágenes de Martinelli en el avión.
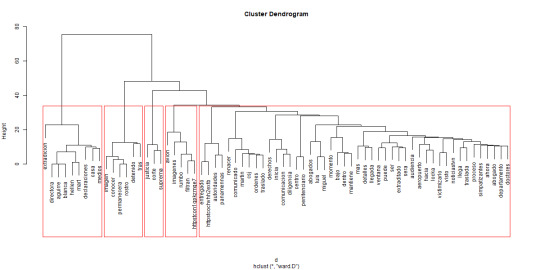
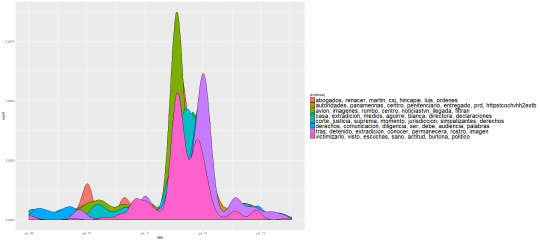
Los tópicos más relevantes en linea de tiempo son (las horas son UTM):
Por cuenta, los tweets se concentran en pocas personas.
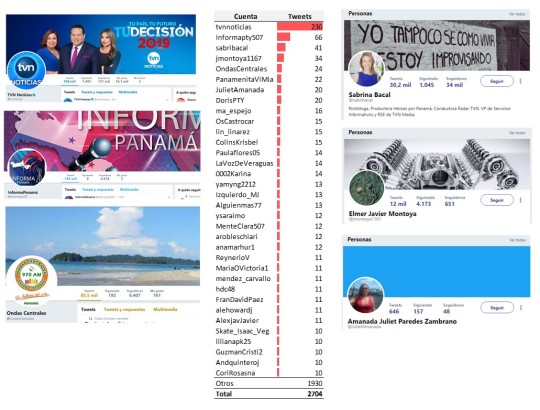
Los datos se obtuvieron y el procesamiento se realizó con R y se complementó con Excel.
0 notes
Text
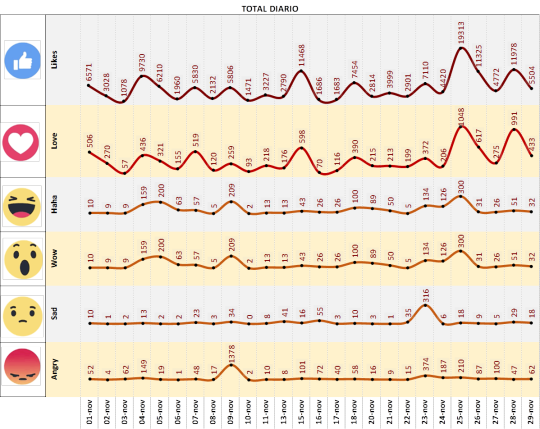
Las reacciones en el Facebook de los candidatos presidenciales que lideran las encuestas en Costa Rica
En noviembre, Juan Diego Castro muestra un mejor desempeño en Facebook que su contrincante Antonio Alvarez Desanti.
Juan Diego Castro, fue mucho más activo en noviembre y casi duplica las publicaciones de Antonio Alvarez, de igual forma, las reacciones positivas de sus seguidores son mucho mayores que las de su contrincante
Reacciones a las publicaciones de Juan Diego Castro:
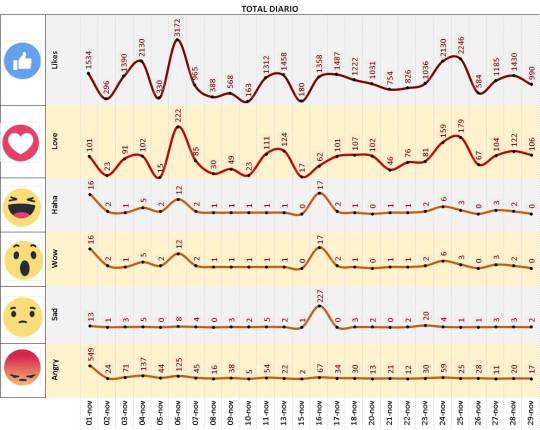
Reacciones a las publicaciones de Antonio Alvarez:
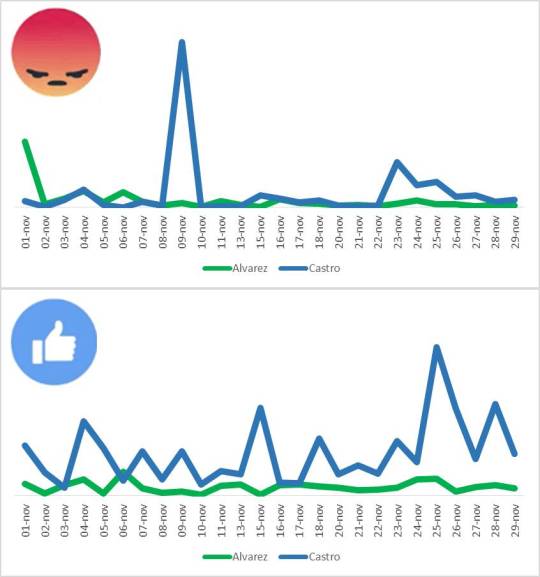
Comparación de Me Gusta y Me Enoja:
0 notes
Video
Crear mapas con Excel.
Iremos publicando los pasos necesarios.
En este ejemplo colocamos sobre el mapa varios parques o plazas del centro de San José, Costa Rica. Y graficamos el número de visitantes (datos ficticios)
1 note
·
View note
Text
R: mapeo de temblores en una región y periodo.
El paquete ggmap de R mediante la función get_map(), permite extraer mapas de diversas fuentes web (entre ellos Google Maps y Stamen Maps). Los mapas se pueden extraer para un país o una región específica (latitud y longitud).
Además, la función download.file() permite extraer datos de un sitio web. En este caso, se extraen los datos del U.S. Geological Survey (https://earthquake.usgs.gov),. Para conocer la parametrización que utiliza el API de este sitio, se puede revisar la sección de API Documentation - Earthquake Catalog (https://earthquake.usgs.gov/fdsnws/event/1/). El USGS permite extraer información histórica de cualquier región del mundo, en los periodos que se desee.
Desarrollamos dos ejemplos sencillos para observar la funcionalidad.
Ejemplo 1. Temblores en las cercanías de Costa Rica, desde enero del 2015 hasta septiembre del 2017.

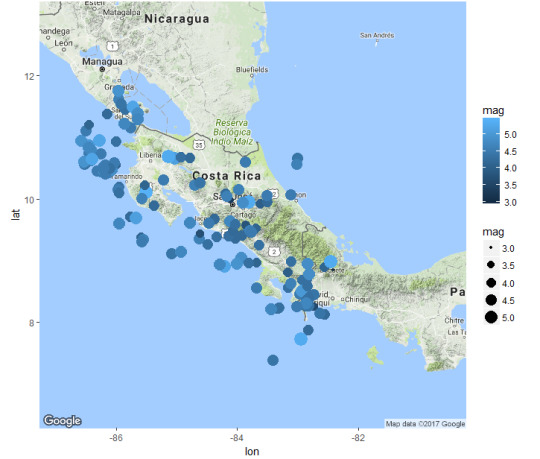
En este periodo en Costa Rica, la mayoría de los temblores presentan magnitudes cercanas a las 4,5 grados. Y se presentan mayoritariamente en la costa del Pacífico.
Ejemplo 2: Temblores en el sur de México durante septiembre del 2017
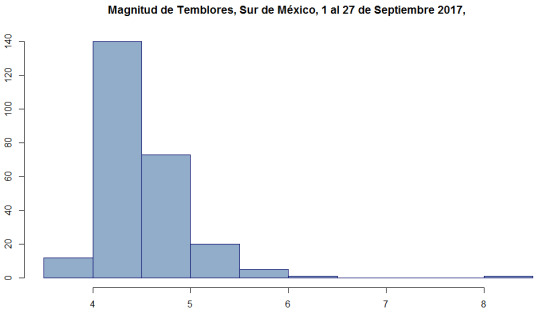
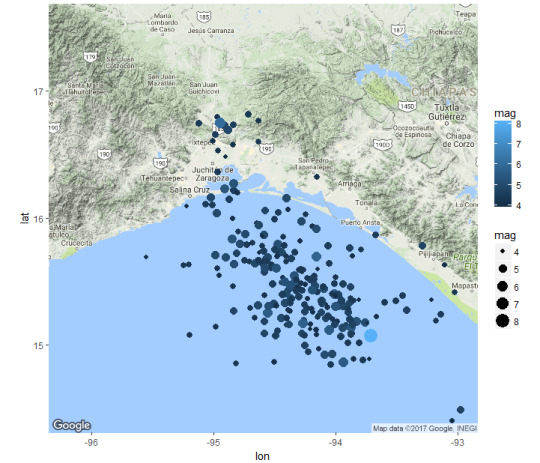
En el caso de México, se utilizó una región centrada en la latitud 16° Norte y longitud 94,6 Oeste, y un radio de 300 kilómetros. en Esta zona en septiembre predominaron los temblores con magnitudes entre 4 y 5 grados. También observamos los dos temblores entre 7 y 8 grados, tanto en el histograma como en el mapa.
0 notes