
optimaldata
Optimal.io
the quest for optimal data
32 posts
Don't wanna be here? Send us removal request.
Last Seen Blogs

saturnsmai
shimo

dnsfdz
sin vergüenza

freedomemotions
Freedom

james-sewell
James Sewell

naynaynomix
just a space hoe
Text
Introduction to Bayesian analysis
The key ingredients to a Bayesian analysis are the likelihood function, which reflects information about the parameters contained in the data, and the prior distribution, which quantifies what is known about the
parameters before observing data.
The prior distribution and likelihood can be easily combined to form the posterior distribution, which represents total knowledge about the parameters after the data have been observed.
Fundamentals of a Bayesian Analysis
A typical Bayesian analysis can be outlined in the following steps :
Formulate a probability model for the data.
Decide on a prior distribution, which quantifi es the uncertainty in the values of the unknown model parameters before the data are observed.
Observe the data, and construct the likelihood function ) based on the data and the probability model formulated in step 1. The likelihood is then combined with the prior distribution from step 2 to determine the posterior distribution, which quantifies the uncertainty in the values of the unknown model parameters after the data are observed.
Summarize important features of the posterior distribution, or calculate quantities of interest based on the posterior distribution. These quantities constitute statistical outputs, such as point estimates and intervals.
10 notes
·
View notes
Text
Introduction to Decision Trees
A decision tree is a classic and natural model of learning. It can be applied to many machine learning problems. The best way to introduce this would be with an example using binary classification.
Suppose that your goal is to predict whether some unknown passenger in will enjoy some unknown future flight he/she is going to take. You have to simply predict with an answer of “yes”
or “no.”
In order to make a guess, your’re allowed to ask binary
questions about the passenger under consideration.
For example:
Machine: Are you going on vacation ?
You: Yes
Machine: Is the flight early morning ?
You: Yes
Machine: Is the Flight more than 2 hours?
You: Yes
Machine: I predict this passenger will not enjoy the flight.
The goal in learning is to figure out what questions to ask, in what
order to ask them, and what answer to predict once you have asked
enough questions.
The decision tree is so-called because we can write our set of questions and guesses in a tree format. Usually the answers would decide how to navigate the tree.
Diagramatically, the questions are usually written in the internal nodes (rectangles) and the guesses are written in the leaves (ovals). Each non-terminal node has two children: the left child specifies what to do if the answer to the question is “no” and the right child specifies what to do if
it is “yes.”
More learning at Optimal.io
1 note
·
View note
Text
4 Typical inductive learning problems
Regression: trying to predict a real value. For instance, predict the
value of a stock tomorrow given its past performance. Or predict
your score on the data science final exam based on your
homework scores.
Binary Classification: trying to predict a simple yes/no response.
For instance, predict whether you will enjoy this material or not.
Or predict whether a user review of the newest Google product is
positive or negative about the product.
Multiclass Classification: trying to put an example into one of a number of classes. For instance, predict whether a news story is about
entertainment, sports, politics, religion, etc. Or predict whether a
CS course is Systems, Theory, AI or Other.
Ranking: trying to put a set of objects in order of relevance. For instance, predicting what order to put web pages in, in response to a
user query. Or predict Alice’s ranked preferences over courses she
hasn’t taken.
More learning @ Optimal.io
1 note
·
View note
Text
Sharding in MongoDB
Sharding, can also be called horizontal scaling. The scaling approach divides the data set and distributes the data over multiple servers. Each of this server can be called a shard. Each shard is an independent database, and collectively, the shards make up a single logical database.
What other components are required for MongoDB sharding ?
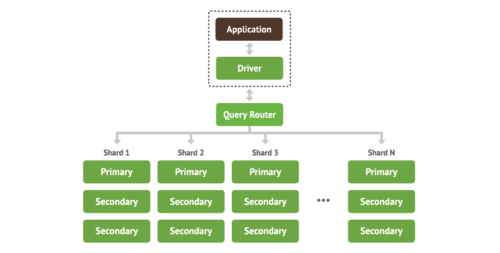
Like mentioned above, the Shards stores the data. For ensuring that shards are highly available, you need to have replica sets . We will go into more details later around replica sets, but for now the easiest way to explain this is - you could have a primary shard which you can write to and a second shard which is paired with the primary shard hosting the same data which you can read from.
When you do sharding, you would need to know which shard to get the data from. This is done by the Query Router. The Query Router direct requests to the appropriate shard or shards. It processes and targets operations to shards and then returns results to the clients.
The next question is - how does the query router know which shard to get the data from ? . This information is stored in Config servers. They store the cluster’s metadata. This data contains a mapping of the cluster’s data set to the shards. The query router uses this data to route requests to the right shards.
0 notes
Text
How to find the schema of a collection in MongoDB
The last two commands are equivalent to the SQL command Describe <Table>
MongoDB shell version: 2.4.5
> show dbs
local 0.078125GB
todo 0.453125GB
> use todo
switched to db todo
> show collections
system.indexes
tasks
> var schematodo = db.tasks.findOne();
> for (var key in schematodo) { print (key) ; }
_id
label
content
0 notes
Text
NoSQL vs SQL Comparison Summary
Types
SQL : One type (SQL database) with minor variations
NOSQL : Many different types including key-value stores, document databases, wide-column stores, and graph databases
Schemas
SQL: Structure and data types are fixed in advance. To store information about a new data item, the entire database must be altered, during which time the database must be taken offline.
NOSQL: Typically dynamic. Records can add new information on the fly, and unlike SQL table rows, dissimilar data can be stored together as necessary. For some databases (e.g., wide-column stores), it is somewhat more challenging to add new fields dynamically.
1 note
·
View note
Text
How to install MongoDB on Mac OS X
A guide to show you how to install MongoDB on Mac OS X.
MongoDB 2.2.3
Mac OS X 10.8.2
1. Download MongoDB
Download MongoDB from official website. Create a mongodb folder as described below
$ cd ~/Download $ tar xzf mongodb-osx-x86_64-2.2.3.tgz $ sudo mv mongodb-osx-x86_64-2.2.3 /usr/local/mongodb
2. MongoDB Data
By default, MongoDB write/store data into the /data/db folder, you need to create this folder manually and assign proper permission.
$ sudo mkdir -p /data/db $ whoami asurendran $ sudo chown asurendran /data/db
3. Add mongodb/bin to $PATH
Create a ~/.bash_profile file and assign /usr/local/mongodb/bin to $PATH environment variable, so that you can access Mongo’s commands easily.
$ cd ~ $ pwd /Users/asurendran $ touch .bash_profile $ vim .bash_profile export MONGO_PATH=/usr/local/mongodb export PATH=$PATH:$MONGO_PATH/bin ##restart terminal $ mongo -version MongoDB shell version: 2.2.3
4. Start MongoDB
Start MongoDB with mongod and make a simple mongo connection with mongo.
Terminal 1
$ mongod MongoDB starting : pid=34022 port=27017 dbpath=/data/db/ 64-bit host=mkyong.local //... waiting for connections on port 27017
Terminal 2
$ mongo MongoDB shell version: 2.2.3 connecting to: test > show dbs local (empty)
Note
If you don’t like the default /data/db folder, just specify an alternate path with --dbpath
$ mongod --dbpath /any-directory
5. Auto Start MongoDB (this is optional, I start MongoDB manually)
To auto start mongoDB, create a launchd job on Mac.
$ sudo vim /Library/LaunchDaemons/mongodb.plist
Puts following content :
/Library/LaunchDaemons/mongodb.plist
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd"> <plist version="1.0"> <dict> <key>Label</key> <string>mongodb</string> <key>ProgramArguments</key> <array> <string>/usr/local/mongodb/bin/mongod</string> </array> <key>RunAtLoad</key> <true/> <key>KeepAlive</key> <true/> <key>WorkingDirectory</key> <string>/usr/local/mongodb</string> <key>StandardErrorPath</key> <string>/var/log/mongodb/error.log</string> <key>StandardOutPath</key> <string>/var/log/mongodb/output.log</string> </dict> </plist>
Load above job.
$ sudo launchctl load /Library/LaunchDaemons/mongodb.plist $ ps -ef | grep mongo 0 71 1 0 1:50PM ?? 0:22.26 /usr/local/mongodb/bin/mongod 501 542 435 0 2:23PM ttys000 0:00.00 grep mongo
Try restart your Mac, MongoDB will be started automatically.
0 notes
Text
4 use cases of using MongoDB and Hadoop together
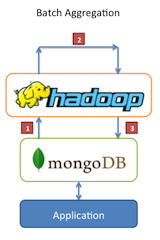
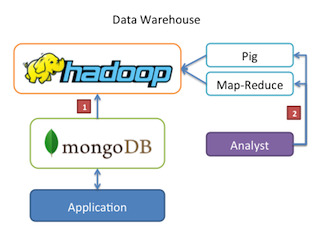
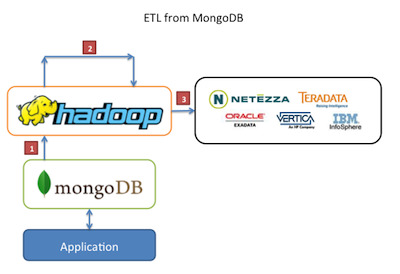
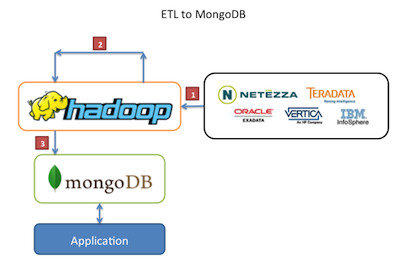
You can read about the use cases here at MongoDB.
0 notes
Text
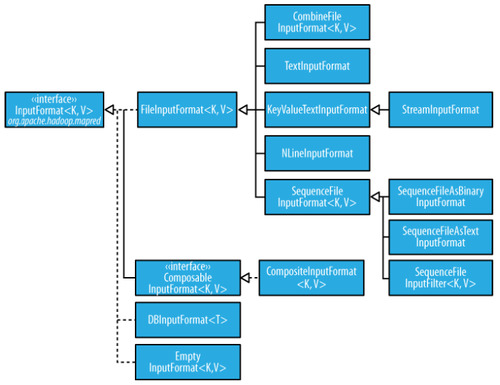
Hadoop Data Types
Here is a high level overview of Writable and InputFormat Data types which are used in Hadoop

Here is a Detailed class diagram for these two data types. Thanks to Xu Fei

0 notes
Text
3 Differences between a MapReduce Combiner and Reducer ?
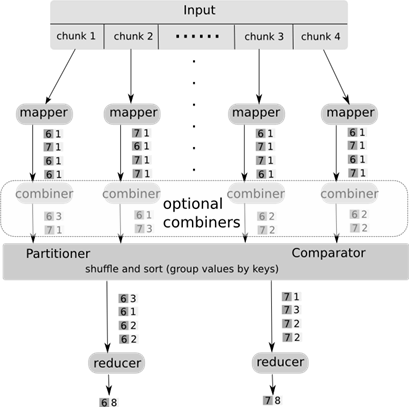
Think of a Combiner as a function of your map output. This you can primarily use for decreasing the amount of data needed to be processed by Reducers. In some cases, because of the nature of the algorithm you implement, this function can be the same as the Reducer. But in some other cases this function can of course be different.
A combiner will still be implementing the Reducer interface. Combiners can only be used in specific cases which are going to be job dependent.
Difference # 1
One constraint that a Combiner will have, unlike a Reducer, is that the input/output key and value types must match the output types of your Mapper.
Difference #2
Combiners can only be used on the functions that are commutative(a.b = b.a) and associative {a.(b.c) = (a.b).c} . This also means that combiners may operate only on a subset of your keys and values or may not execute at all, still you want the output of the program to remain same.
Difference #3
Reducers can get data from multiple Mappers as part of the partitioning process. Combiners can only get its input from one Mapper.
3 notes
·
View notes
Photo

4 Types of Data Scientist related Roles
0 notes
Text
What is Binning?
Binning is a way to group a number of more or less continuous values into a smaller number of "bins". For example, if you have data about a group of people, you might want to arrange their ages into a smaller number of age intervals.
In the example below, we have data about temperature in a region ordered based on the date of the month. It is hard to visualize what the range of temperature was for that region was.

Binning helps in visualizing these values. The first step is to find the occurences of the temperature. The table below shows occurences of a temperature range.

0 notes
Text
What is an ElasticSearch Facet ?

LinkedIn uses facets to refine their search query.
In ElasticSearch, Facets are additional data which you can attach to a query. This helps with returning aggregate statistics alongside regular query results. The aggregate statistics are a core part of elasticsearch, and are exposed through the Search API.
An example would be to consider searching for your ex-colleagues who worked with you. The best example from the above screenshot is when you want to find colleagues whose "Past Company" was "ABC Company".
Facets are highly configurable. In addition to counting distinct field values, facets can count by more complex groupings, such as spans of time, nest filters, and even include full, nested, elasticsearch queries.
Here is an example of a Geo Distance Facet which is included as part of an ElasticSearch Query.

Image courtesy of Karmi.
0 notes
Text
Big Data Search using ElasticSearch
ElasticSearch built on top of Lucene has come up with an elegant search engine which can solve the Big Data Search problem.
Its basically a solution built from the ground up to be distributed. It also can be used by any other programming language easily, which basically means JSON over HTTP.
It's a Java based solution. ElasticSearch has been architected in such a way that it can easily either start embedded or remote to the Java process, both in distributed mode or in a single node mode.
Another important and fundamental piece of ElasticSearch which has helped solved the scalability problem is by running a “local” index (a shard) on each node, and do map reduce when you execute a search, and routing when you index.
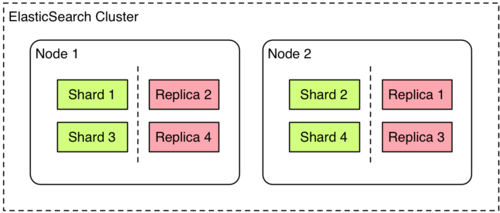
*Image courtesy of François Terrier @ Liip.
A shard is a single Lucene instance. It is a low-level “worker” unit which is managed automatically by elasticsearch. An index is a logical namespace which points to primary and replica shards.
Other than defining the number of primary and replica shards that an index should have, developers never need to refer to shards directly which maintains the vision of really making search easy. Instead, their code only needs to refer to an index. We usually index our searches based on a variation of following parameters : Business Function/ Application Name and Time (Month / Week). Our current volume is too low to put in the actual day as part of the index even though internally Elasticsearch has all that information.
Elasticsearch distributes shards amongst all nodes in the cluster, and can move shards automatically from one node to another in the case of node failure, or the addition of new nodes.
0 notes
Text
Machine Data and Big Data
Business applications, Sensors in Factories and Large equipment and their supporting systems are a rich source of data. Every technical component in a functioning system produces logging information. Business application logs are detailed logs and can contain every transaction the customer or user has executed on that application. It doesn't matter if the transaction was successful or whether it failed - there are insights you can get from Your Log files.
System or maching logs have variety, a large number of data sources and formats which are unique based on the application / system which is generating that.
Its fast moving, a typical enterprise creates log files for every second
volume of data, data is recorded for events and for time periods.
A business transaction will fan out and create 100’s of log and audit table entries.
To get a big picture of your operations environment, this rich and complex technical information needs to be analyzed. You need to be able to get data which is relevant to you and this in turn presents a challenge for the software performance engineer or the Operations team. The Operations team is managing a larger and large number of real and virtual environments and the business is asking for more frequent functionality packed releases into the product.
Some typical log files which an enterprise deals with are :
• Network packet flow information from routers and switches
• Storage subsystem metrics
• Database metrics
• Application servers from Log4j messages
• Microsoft WMI
• Web Server information from Apache
• Operating system information from AIX, Linux, and VMWare
• End User experience.
0 notes
Text
What is Hive ?
It is a Data Warehouse system layer built on Hadoop.
Allows you to define a structure for your unstructured Big data.
Simplifies queries using a SQL syntax call HQL.
0 notes