
Last Seen Blogs





Text
Bowers Exploding Array Function discussion part 1: Linear and planar arrays
Well, it's been another full year without me making a post about people's attempts at formally defining Jonathan Bowers' Exploding Array Notation. This post is the first in an attempted series to discuss the rules for some subsystems of BEAF and the various ways that people have interpreted Bowers’ unformalized ideas of “array spaces.”
I begin by introducing arrays in a somewhat non-traditional way, which is similar to the description from Bowers' Spaces page (Some people have trouble loading the page so the Internet Archive link should also work: http://web.archive.org/web/20201102164403/http://www.polytope.net/hedrondude/spaces.htm). My goal is to emphasize the structure of the space the array lives in, rather than the array itself. I won't spend much time going over example calculations to give a sense of how unimaginably large the numbers get, either. There is a good explanation on Googology Wiki of how BEAF easily creates numbers that surpass Graham's number, as well as the most common large number generating functions, such as up-arrow notation and chained arrow notation: https://googology.wikia.org/wiki/Introduction_to_BEAF.
Linear arrays
To understand linear arrays, just imagine an infinite row of boxes where positive integers can be placed. The row has a beginning but no end. Each box is indexed by an integer, and for the purpose of this discussion we will say these indices start at 0. The default value for a box is 1, and all but finitely many boxes must contain the value 1. When we write an array like this: {a, b, c...}, the values in the brackets are in sequential positions starting from entry 0, and all remaining entries are 1, so the array is inside an infinite sea of 1's. In general, an array can be considered a collection of numbers at various positions inside an infinite (hyper-)dimensional space of 1's.
Bowers has a lot of terms for various entries in the array which he uses when he defines his rules.
Definitions:
Entry 0 is called the base.
Entry 1 is called the prime.
The first entry after the prime that is not 1 is called the pilot.
The entry right before the pilot is called the copilot.
The array is solved into an integer by means of applying a series of steps repeatedly until either the base rule or prime rule applies, and then a value is returned.
Rules
Let b be the base and p be the prime.
Base rule: If every entry besides the base and the prime is 1, the array evaluates to b^p.
Prime rule: If p = 1, the value b is returned.
Catastrophic rule: If neither of the above rules apply, the array is changed in the following way:
The pilot is decreased by 1.
The copilot becomes the value of the original array, but with the prime decreased by 1.
Besides the copilot, every entry before the pilot changes to b.
Planar arrays
The next step is to stack the numbers on top of each other. The array can be imagined as an infinite plane of boxes of positive integers. This time, the positions in the array can be described by two coordinates: (a, b) is the value in the a-th row and b-th column (and a and b both start from 0). 1's are still the default value, so for a valid array, all but finitely many entries are 1's.
Bowers still uses commas to separate the entries of the array, and uses the separator (1) to move to the first entry on the next row. Thus, an array such as {3, 3, 3 (1) 3, 4, 5, 6} means the following structure in space:
3 3 3 1 1 1...
3 4 5 6 1 1...
1 1 1 1 1 1...
...
Most of the rules and definitions we gave above still work. The base and prime are now the entries at positions (0, 0) and (0, 1) respectively (i.e., on the first row). The pilot may not be on the first row anymore; it may be on the second row, third row, or beyond. If the pilot is the first entry on its row, the copilot doesn't even exist.
There are two important things to understand about the definition of the pilot: "The first entry after the prime entry that is not 1." First, it requires that all the positions of space have an ordering. The ordering is just the standard top-to-bottom left-to-right reading order: (w, x) > (y, z) if w > y, or if w = y and x > z. Second, the entries must be well-ordered; that is, each non-empty set of space positions must contain one that comes first in the ordering. If the entries were not well-ordered (for example, if the second coordinate were always non-positive instead of non-negative), we would not be able to ensure that the set of entries after a certain position contains an earliest entry (for example, the position (1, 0)), and thus we could not speak of the first non-1 entry after the prime. This well-ordering requirement must apply to all extensions of BEAF and it will force the different levels of array space into a hierarchy that is unavoidable, up to isomorphism.
The only rule that needs to change is the catastrophic rule. First, we need a minor tweak to the second part of the rule in case the copilot doesn't exist:
The copilot (if it exists) becomes the value of the original array, but with the prime decreased by 1.
The third part of the rule no longer works either:
Besides the copilot, every entry before the pilot changes to b.
This is because, if the pilot is on the second row or beyond, an infinite number of entries on the first row must become b. This violates the requirement that only a finite number of entries can be non-1. Instead, Bowers decides that for all rows above the pilot, the first p entries change to b. The rest of the rows' entries (which are all 1's anyway) stay the same.
This means that if the pilot is at (y, z), a chunk of y*p + z prior entries take on the value b. Bowers calls the p entries on each row the prime block of the row. However, we can speak of the prime block of any position in array space as all of the entries that would be filled if the pilot or copilot was at that space (Bowers also calls these entries the "airplane"). Because the size of the prime block is a linear polynomial of p, the positions themselves are often expressed as polynomials, with position (y, z) described as y*X + z. The prime block itself can be represented by [y*X + z](p).
In fact, if the pilot is 2, and every other entry besides the base and prime is 1, the array evaluates into just a prime block and nothing else (besides trailing 1′s). This is how Bowers constructs many of his larger named numbers, which are usually written as {b, p (separator) 2} or as f(p) & b (where f is a function identifying a space by the size of its prime block, and & means "array of").
1 note
·
View note
Text
Pandigital minutes
In 2015, I (re?) discovered an interesting calendar curiosity: a minute that uses all 10 digits exactly once when written down as a date.
To be precise, I was looking for times when the following 10 digits were all distinct:
The last two digits of the year
The two digits of the month number, from 01 (January) to 12 (December)
The two digits of the day number, from 01 to 31
The two digits of the hour in military time, from 00 to 23
The two digits of the minute, from 00 to 59
It is easy to see that the same dates are pandigital minutes in every century. There are also the same number of pandigital minutes in each century, since the only date whose existence varies between centuries uses repeating digits (00/02/29) and cannot be part of a pandigital minute.
There have been no pandigital minutes so far this century. The digits 0, 1, and 2 must be used for the 10s places of the month, day, and hour in some order, meaning that the next occurrence cannot happen earlier the 2030s. In fact, as I write this, the next pandigital minute will be in exactly 14 years minus one day: June 27, 2034 at 6:59 PM, or 34/06/27 18:59.
The total number of pandigital minutes in each century is not too hard to calculate by hand. The trick is to keep track of all the values each digit can take and observe the one with the fewest possibilities. Let the date be 20y1y0/M1M0/d1d0 and the time be h1h0:m1m0. The digit M1 must be in the range 0..1, and similarly h1 in 0..5, d1 in 0..3, and m1 in 0..5. The other six digits can take on any value from 0 to 9 in general, but these choices can be restricted by the values of other digits.
Note: The following list contains indented sublists which do not display correctly on the Tumblr dashboard.
Let M1 = 0.
h1 must be in 1..2.
Let h1 = 1.
d1 must be in 2..3.
Let d1 = 2.
m1 must be in 3..5.
For each choice of m1, the remaining six digits can be freely assigned in any order.
This gives 6!*3 = 2160 pandigital minutes.
Otherwise, d1 = 3.
The day can be only 30 or 31, so d0 must be in 0..1.
But this is impossible because 0 and 1 have already been used.
Otherwise, h1 = 2.
The maximum hour is 23, so h0 must be in 0..3.
0 and 2 have been used, so h0 must be 1 or 3.
Let h0 = 1.
d1 must be 3.
But then d0 is in 0..1.
This is impossible because 0 and 1 have already been used.
Otherwise, h0 = 3.
d1 must be 1.
m1 must be in 4..5.
For each choice of m1, the remaining five digits can be freely assigned in any order.
This gives 5!*2 = 240 pandigital minutes.
Otherwise, M1 = 1.
M0 must be 0 or 2.
Let M0 = 0.
h1 must be 2.
h0 must be in 0..3. The only possible value for h0 is 3.
d1 must also be in 0..3, but all those digits have been taken.
Otherwise, M0 = 2.
h1 must be 0.
d1 must be 3.
But then d0 is in 0..1.
This is impossible because 0 and 1 have already been used.
This brings us to a total of 2400 pandigital minutes in each century, from 34/06/27 18:59 to 98/07/26 15:43. They happen in every decade from the 30s to the 90s, and always in the months March through September. 2160 of them happen between 14:00 and 20:00 while the other 240 happen between 23:00 and 0:00.
1 note
·
View note
Text
Updated Bowers Exploding Array Function program
In preparation for my upcoming posts where I discuss the task of formally defining Bowers Exploding Array Function, I have just made an update to my 2016 Python program displaying the steps of evaluating an array. The current version is available on my GitHub here. It is currently written in Python 2, but I plan to rewrite it in Python 3 soon.
I plan to update it a lot more in the coming weeks. As of March 26, 2020, I have made the following changes:
Updated notation for the planar arrays to match what Bowers writes (e.g. {3, 3, 3(1)2})
Added a class “Bowersarray” so the arrays are treated as their own type of object in the code, with special functions for evaluation.
Made a special function for the “canonization” step (removing 1′s from the end of rows and rows from the end of the array).
Here are some updates I have planned for the future:
Support higher dimensional arrays and beyond.
Allow the user to skip to the end of long, predictable sequences of steps.
Add code to support numbers too large for all digits to be stored, so that the program can go a little longer before freezing when encountering a number too large.
Allow the user to skip to the end of the evaluation of some intermediate array, even if they don’t understand the immensity of the resulting value, and have the program describe the next steps of the evaluation in terms of that value.
1 note
·
View note
Text
Bowers Exploding Array Function revisited
Today (November 27) is Jonathan Bowers’ 50th birthday! In 2016, I made a post about his legendary function for generating large numbers, Bowers Exploding Array Function (or BEAF for short). I wrote Python code to solve the first few steps of a 2D Bowers array, to show how the function was defined recursively. I promised updates to my code but I never delivered. However, within the next few days (or weeks, or months...) I think I will do just that.
First, I would like to present an overview of the different array structures of BEAF arrays. These are the most confusing part of BEAF; the recursive rule is quite easy to apply once the array structures are known.
Linear arrays: these are vectors of a finite number of positive integers, which can be indexed from 0 to some positive integer n.
Planar arrays: these are vectors of linear arrays, which can be of different lengths (or empty). Each entry can be indexed by a linear polynomial with non-negative coefficents, a*X + b.
Dimensional arrays: each entry can be indexed by a polynomial of arbitrary degree with non-negative coefficients, a*X^n + b*X^(n - 1) + ... + k. Polynomials are ordered by comparing the most significant coefficients that are different.
Tetrational arrays: these are indexed by “hypernomials”; the exponents are allowed to be polynomials themselves (and, recursively, they are allowed to be earlier-constructed hypernomials). After the ordering of the exponents is established, one can compare hypernomials by size. Thus, by induction, all hypernomials can be ordered. These correspond to transfinite ordinals below epsilon_0. An example is 3*X^X^(X+2)+2*X^X^X+X^(X^3+X)+X^X+X^5+3*X+4.
Pentational arrays: the idea of hypernomials is extended by allowing the height of the tower of X’s to be a hypernomial. Using ^^ for tetration, we can define X^^X, X^^(X + 1), X^^X^2, X^^X^^X, .... Unfortunately, the rules for these expressions were never formalized and it is unknown what kind of expressions come between X^^X and X^^(X + 1), for example.
Hexational arrays and beyond: these are even less obvious to work with. When fully formalized (and I do believe it will happen some day), the expressions will be things like X^^^X, {X, X, X}, {X, X (1) 2}, tetrational arrays of X’s, pentational arrays of X’s, etc.
Legion arrays and beyond: Bowers develops a new kind of recursion for legion arrays -- adding an argument to his function to denote the number of times an array is filled with X’s and used to make the space for a larger array. Unfortunately, there is no formal definition of these, despite toiling efforts of many parties on Googology Wiki. Jonathan Bowers used legion arrays to “define” his legendary number “meameamealokkapoowa oompa.”
0 notes
Text
Detailed list of attributions
When I first started this blog, I was 15 and homeschooled and had no sense of academic honesty. All I knew was that after reading books about math from big names such as John Conway and David Wells and thinking deeply about numbers, ideas came into my mind. These ideas were sometimes interesting enough that I thought it would do good to publish them, even though I didn't always remember where the thoughts came from or how much I had to read before I thought of the rest myself.
As I went on and gained more of a sense of how others would view my blog, I began to notice that there were very glaring omissions of any attribution from most of my posts. I was writing as if all my ideas were coming straight from my brain, which was true for some but not all of my posts. When I transitioned straight from homeschool into college in 2017, the most common reaction people had when hearing about my mathematical interests was "Did you come up with this yourself or find it somewhere?" I often could not answer because I had spent almost no time paying attention to where my ideas came from. Sometimes I had actually forgotten where I learned an advanced mathematical topic because I had known about it for so long, almost 10 years. Once I memorized the proof of an interesting phenomenon I saw, the conclusion seemed self-evident. Until then, as far as I was aware what I was learning was simply a refinement of my everyday thought and none of my posts needed attributions because everything that I didn't discover was assumed to be common mathematical knowledge.
Right before leaving for college I wrote the following disclaimer in my "About" page to try to demystify the origin of many of my ideas:
First, not everything I post here is one of my recent thoughts. Sometimes I decide to post an idea that I have had for up to ten years (I have 18). I don’t post every idea I have either; quite often, a post is so long that I started working on it only a few days after I finished the previous post.
As of this writing (August 17, 2017), I am not in college yet, though I will be going to New Mexico Tech in a few days, probably before anyone reads this.
Finally, I do not claim to be the first to discover any of the things I post here. (If I am though, it would be awesome.) Except where otherwise stated, the ideas in this blog were thought of by me, even though they sometimes build off of others’ ideas.
I still stand by everything I wrote. I wish I could have left it at that because it is not exactly fun for me to look up one of my "discoveries" and find that the exact same thing has been discovered by someone else in the past. But after years of hearing about the dangers of plagiarism and the importance of citing my sources, combined with the increasing popularity of my blog as I put it on my résumé to advertise my mathematical talent to potential employers, I think that it is time for a more comprehensive list of my sources of knowledge.
I'll go through my posts chronologically, recalling as best I can my knowledge for each of them.
Multiples of 37 and its sequel
To the best of my knowledge, I got the idea for this question by looking at a graph of the number of palindromes divisible by each prime, from Giovanni Resta's site Numbers Aplenty, and noticed that significantly more than 1/37 of all palindromes were divisible by 37. I knew that this was because 37*3 = 111, but to my surprise I couldn't find a single palindrome divisible by 37 but not 111 for a long time (well, a few hours or days). The first one I found was 808808838808808, which quickly led to 191191161191191. Eventually I convinced myself that 5009009009005 was the smallest, but I don't remember how rigorous my proof was. At some time in the future I will do an exhaustive computer search, unless someone else does it first, and post the result.
List of uniform honeycombs
This list is not only outdated and errored, as explained in the heading, but it contains very specific unexplained jargon. The post was written to parallel the research Jonathan Bowers was doing on higher-dimensional uniform polytopes and apply the same methods to search for 3D tesselations. The mysterious names given, such as "chon", "octet", and "squat" are nicknames invented by Jonathan Bowers to describe polytopes and tessellations, formed by contracting the full name down to its initials and adding vowels. These names are commonly called Bowers Style Acronyms and Dr. Richard Klitzing's site here gives a long list of these acronyms with their meanings.
The few exceptions are nicknames invented by me when I stumbled across configurations that were, to my knowledge, new. These nicknames are Goccoticpidsith for "Great cubicuboctahedral tomocubic prismatic disquare tiling honeycomb," Gotactictosquath for "Great tetrahedral cubic tomocubic tomosquare tiling honeycomb," and Wavaccocotsoth (I don't remember what that stood for because I already replaced the name with Wavicoca in one place). All these shapes have now been given better names by Jonathan Bowers, and the list updates are available on this hi.gher.space forum thread (my username is polychoronlover).
Cheryl's Birthday and my solution
Self-explanatory. I thought of the solution in my head and was surprised that everyone else thought it was so hard. Obviously I overestimated the average person's intelligence.
The picture of the problem on paper is from the Guardian article, which in turn got it from Kenneth Kong on Facebook. I don't know if the picture is copyrighted. (I will gladly remove it if I learn that it is.)
How to calculate exact trig values, a post about radical expressions for roots of unity with an unsuspecting title, and its sequels [1], [2]
Ooh, here goes. The first in a series of posts where I did what is in my opinion my most impressive and mysteriously learned work. If only I had given them titles describing what I was actually doing.
I have made several more interesting findings in regards to this topic since making this post, described at the bottom of this section. So, there could be no better time to explain exactly where I learned such a specific way to calculate roots of unity in the first place.
In 2012, I was well aware from my math textbook that cos(45°) = sqrt(2)/2, cos(60°) = 1/2, and cos(30°) = sqrt(3)/2. I had also recently learned that cos(36°) = (1 + sqrt(5))/4 and cos(72°) = (-1 + sqrt(5))/4 from a statement on page 146 of the Penguin Dictionary of Curious and Interesting numbers by David Wells. (The book said that -2 cos(666°) was a good approximation for the golden ratio, but I verified the equation to be accurate to 14 decimals with my calculator. I was starting to suspect the values were actually equal. Later, I proved their equality myself by measuring various lengths in a pentagram.) When I learned the identities cos(a + b) = cos(a)*cos(b) - sin(a)*sin(b) and sin(a + b) = sin(a)*cos(b) + cos(a)*sin(b) (part of a normal high school trigonometry curriculum) I was able to find radical expressions for cosines of every multiple of 6°. On some website that I can't remember, possibly this Wikipedia article, I found the identity cos(15°) = (sqrt(6) + sqrt(2))/4, which allowed me to find a radical expression for the cosine of every angle that was a multiple of 3°. Here are pictures of the paper where I recorded the results: i.imgur.com/wjjEIzP.jpg, i.imgur.com/xWNmrla.jpg.
Around the same time, I was also hearing about how Gauss had proved that the cosine of 17ths of a circle had expressions in square roots, and so did the 257ths and 65537ths of a circle. I was also starting to think less of these calculations in terms of cosines and sines and instead in terms of roots of unity (complex numbers of the form cos(2*pi/n) + i*sin(2*pi/n), in radians of course). Near the end of 2012, I heard of a method to calculate 17th roots of unity by starting with the sum of all 16 primitive roots and solving quadratic equations repeatedly to find the sum of fewer and fewer roots. I learned this method from the book The Book of Numbers by John Conway and Richard Guy. Seeing this derivation, I started to wonder if the cosine of every rational fraction of a circle was expressible using radicals.
I also heard (from the same book? Or maybe Wikipedia?) that the 7th and 9th roots of unity required cube roots when expressed in radicals, and that cos(2*pi/7), cos(4*pi/7), and cos(6*pi/7) were all roots of the same cubic equation with rational coefficients. Using a desk calculator, I found the three elementary symmetric polynomials of these three values, from which I found the coefficients of the cubic equation. Then I used the cubic formula to solve the equation. The resulting radical expression for cos(2*pi/7) matched the expression given on this Wikipedia page and indeed the expression now in my blog post, even though that expression was calculated using a different and more extensible method. I found an expression for cos(2*pi/9) the same way, and even found an expression for 2*cos(2*pi/13) (as x^1 + x^12, where x is a 13th root of unity) by solving a quadratic equation for the sum of six 13th root of unity and solving a cubic equation to break the sum into three pieces. I noticed the similarity between this method and Gauss's method to calculate 17th roots of unity. In general, it seemed that to calculate the pth roots of unity, where p was prime, I needed to start with the sum of p - 1 pth roots of unity (which was always -1). Then I needed to repeatedly break the sum into q smaller sums, where q was a prime factor of p - 1, and find their values by solving a q-th degree polynomial. The coefficients, symmetric polynomials of the sums of roots of unity, could always be expressed in terms of previous sums whose values were already determined.
This method did not suffice to calculate the 11th roots of unity. I would have to solve a quintic equation, because 5 is a factor of 10, but I knew that there was no general quintic formula by the Abel-Ruffini theorem. I knew there was a radical expression for the 11th roots of unity because by then I had read somewhere that roots of unity could always be expressed in radicals. After thinking for a few weeks or months, in early 2013 I came up with a new way, based on the discrete Fourier transform of the roots. This method gave me a new way to find the 7th and 13th roots, and also allowed me to find the 11th roots by avoiding the problem of having to solve a quintic equation. This is the method I describe in my blog posts.
In January 2013, before I knew how to compute expressions for the 11th roots of unity, I found an expression for cos(2*pi/11) on a website called Literka. I was unable to compute the values myself for a long time even after I learned the method described in my posts, because the calculations were too intense (they involved taking a ten-term expression to the fifth power), although I made several close calls. In 2017 I learned enough shortcuts and perserverance skills to compute the values and promptly wrote a post about it, and I am happy to see that the values I found, with the -979, 275, and 220, match the values given on Literka.
But now all these advancements in my knowledge have been outdated by my recent research on the matter. Now I have:
A Python program that finds root-of-unity expressions using the same method that I used,
A "refinement" of this method that gave shorter expressions for the 11th roots of unity,
Another Python program that finds expressions using the refined method,
Lots more root-of-unity expressions, some very long, that are numerically verified to be accurate,
A formula to approximate the average "length" of a root-of-unity expression before I calculate it.
The Python programs can, in theory and assuming arbitrary precision floating point values, calculate the radical expression for the p-th roots of unity where p is any prime. In reality, they tend to falter for most cases past 60th roots; the expressions become impressively long. The lengths vary a lot between consecutive primes, sometimes by orders of magnitude.
I can't wait to make another post presenting all these things!
Unusual number bases
The bases described in this post are base 37, centered nonary, double-digit base 120, base ϕ, definite length base 10, and a "base" based on the prime factors of a number.
Base 37 is a base that I haven't seen anyone else but me take an interest in. It is quite an arbitrarily chosen base, and I chose it just because 37 is my favorite number.
I think I got the idea for centered nonary from a post about centered ternary on the XKCD forums (or was it the hi.gher.space forums?). I probably chose base 9 just because 9 was close to 10. Unfortunately, I can't find the post.
I first heard of base 120 from this page of the metrologist and polytopist Wendy Krieger, who uses it extensively on her website. I discovered her website from my interest in higher-dimensional geometry. She calls the base "twelfty." Much of what I posted about base 120 came from her website, with some notation changed, most notably to use commas to group digits into pairs of super-digits.
Base ϕ is rather well-known. It is mentioned on Wikipedia, Ron Knott's site, and this hi.gher.space post, for example. I first heard of it when I was playing with the cellular automata simulator Golly written by Andrew Trevorrow and Tomas Rokicki. There was a pattern called "alien counter" and the description said that Adam P. Goucher (also known as Calcyman, the creator of apgsearch and Catagolue) thought the simulation was counting in base ϕ but no one was really sure. I didn't actually learn how base ϕ worked for several more years.
I haven't heard of definite-length bases anywhere else, although I'm sure someone else has come up with them. I first thought of the idea when I was young and wanted to use base 26 to assign each word in English a unique number. I numbered A-Z as 1-26, then realized that base 26 would require them to be 0-25. But to my surprise, my numbering scheme still assigned each string of letters to a unique positive integer. Definite-length base n, made from powers of n and the digits 1-n rather than 0-(n - 1), was born.
Even though I independently discovered the prime-factor "base" representation of numbers, the same system appears in OEIS entry A054841 and was called "Exponential Prime Power Representation" by Walter Nissen. The idea of representing a number in terms of its prime factors is very old. In fact, Gödel encoding is a way to map strings of characters to integers in much the same way as exponential prime power representation. Each character position gets assigned a unique prime number and each character gets assigned a unique exponent of that number. Unlike definite-length bases described above, Gödel encoding works for a language with an infinite set of characters.
The Starter Constant Mystery saga: [0], [1], [2], [3]
These are the posts that I feel the most personal connection to. They involve my findings about the following triangle of numbers:
1
0 1
0 1 2
0 1 6 6
0 1 14 36 24
0 1 30 150 240 120
...
These numbers are generated from the nth powers x^n in a way that I now know is called the inverse binomial transform. My posts call them the starter constants. The OEIS calls them numbers of the form k!*Stirling2(n, k).
These numbers have been studied before. They appear in many entries on the OEIS, under many different descriptions: [0], [1], [2], [3], [4]
In my posts I prove two main things about these numbers: that they can be generated by an inductive formula similar to Pascal's triangle (idea 1), and that they relate to the number of strings of given length using every type of character from a given set (idea 2). All the proofs are my own, and I felt greatly accomplished when I made them. The same proofs may have been found by other people, but they are the pride of my mathematical life right now. The major things I found from outside sources are attributed in the posts. Notably, idea 2 described above came from the description of OEIS post [4]. I was amazed when I read that description, when I had only known the starter constants as relating to powers. Rather than looking at the post to see a proof, I felt challenged to prove the connection myself, which I did and detailed in my first post.
When does n have the same digits as 2n?
In this post I describe an algorithm for finding numbers n that are anagrams of their doubles, 2*n, in base 10. The algorithm was developed by me around May 2015. I was inspired to do it after finding, and skimming, but not reading, this post: https://blog.plover.com/math/dd.html, which I found from the OEIS entry for the sequence: A023086. In fact, my own technique of finding cycles of digits is very similar to what the post describes, and the post goes into more detail on the constraints of the digits.
As you probably can tell, I had a tendency when I was younger to find interesting mathematical facts online, attempt to prove them myself rather than looking at someone else's proof, and post them to my blog without attribution if successful.
Unnamed post about the coordination numbers of hyperbolic tilings and its sequel
In these posts, I discuss regular hyperbolic order-3 p-gonal tilings and the sequences arising when counting the number of polygons a given number of steps from a center polygon.
This sequence is called the tiling's coordination sequence, even though I didn't use that term until nearly the end of the second post. I was inspired to study coordination sequences after seeing a post on Adam P. Goucher's blog that said that the coordination sequence for the heptagonal tiling was 7 times alternate Fibonacci numbers. As usual, I skimmed Goucher's post without trying to find a proof of this phenomenon and proved it myself in my post.
There is also the issue of how I created the images for my posts. The images were created using Paint.NET and the font used for the layer numbers was Frente H1, which I downloaded from a site called Font Squirrel. If I remember correctly, Times New Roman was used for the colored numbers in the first post and Arial was used for the colored numbers in the second post.
The post contains two types of images of tilings. One type gives the entire tiling in red and the other gives each layer in a successive rainbow color. For the first type, I used these public domain images [1] [2] by Tom Ruen and Anton Sherwood, which were widely used on Wikipedia until they were replaced by SVGs. The second type of image was created by hand, although I sometimes used the two images given above to trace the edges on them. It also deserves mentioning that the rainbow palette that I used to color successive layers in my images was inspired by the image in Goucher's post.
Here is a link to the OEIS entry for the coordination sequence of the order-3 heptagonal tiling (listed by them as the coordination sequence for the vertices of the dual tiling): A001354.
Last digits of powers and its sequel
In these posts, I prove various theorems about patterns in the last digits of the decimal expansions of perfect powers. As far as I can remember, I thought up the proofs myself, using nothing more than algebraic manipulation and Fermat's little theorem. Although I played with powers a lot as a kid, all of the results I derive are well-known and I only use basic methods from number theory to prove them. For example, see this brilliant.org post about last digits of powers.
The first post is about how x^n = x^(n + 4) (mod 10) when n ≥ 1 and the second is about how x^n = x^(n + 20) (mod 100) when n ≥ 2. I was going to make more posts about the equivalences of powers mod 1000, higher powers of 10, and eventually mod other bases, but I lost interest.
The "wonderful" theorem I mention in the second post says that if numbers a and b are coprime, then pairs of values (x mod a, x mod b) will only be the same for two different values of x when those two values are separated by a multiple of a*b. This is equivalent to saying that when a and b are coprime, a*b = LCM(a,b). This is simply another basic result of number theory.
Irrational primes!
This post was an April Fool's joke announcing a "mathematical breakthrough": the discovery of irrational numbers that are prime! Obviously, this is absurd as all prime numbers are integers by definition. At the same time, I also intended to present an actual mathematical curiosity I had rediscovered: a set of real numbers containing all primes, no other integers, and infinitely many (probably irrational) non-integers.
The idea is that Wilson's theorem, a common test for prime numbers named after John Wilson, says that an integer x is prime if and only if ((x - 1)! + 1)/x is an integer. Using the Gamma function, factorials can be defined for every positive real number, allowing for integer values of ((x - 1)! + 1)/x to exist for non-integer values of x. For the sake of a joke I called these numbers "irrational" despite not knowing that for sure.
In fact, the curiosity of non-integer solutions of Wilson's congruence has been noticed by several people before, such as in this college math test from 1999.
Lychrel numbers and its sequel
In these posts, I discuss Lychrel numbers, numbers that never reach a palindrome when iterating the process of reversing the digits and adding to the original number: why we think they exist, why we haven't proved they exist in base 10 although we have proved they exist in base 2, and a heuristic argument suggesting there are infinitely many Lychrel numbers in every base. The first post is the first one that I can remember where I only talk about things other people have discovered instead of presenting my own findings, even if they are rediscoveries or trivial corollaries of others' discoveries. The binary Lychrel number mentioned in the second post I found on Wikipedia. The only insights that were my own were the heuristic argument and the connection to cellular automata.
Unnamed post with a proof about geometry
In this post, I prove that removing four non-adjacent vertices of a cube results in the vertices of a regular tetrahedron. This fact may be useful in chemistry as an aid to drawing molecules with tetrahedral structure, such as methane. In fact, as I mention in the post, I got the idea after watching a chemistry video on Khan Academy with a proof of the same fact. I think the video was this one: https://www.khanacademy.org/science/organic-chemistry/gen-chem-review/hybrid-orbitals-jay/v/tetrahedral-bond-angle-proof.
Even though I was quite proud of it at the time, I now think that my proof was trivial and was presented in an overly long fashion. I don't actually know why I needed to mention the coordinates of a cube (let alone one rotated 45 degrees from the standard coordinate-parallel orientation!). I should have just said that choosing alternate vertices produced four vertices such that every pair lay on opposite ends of a square, and thus the distances between all pairs of vertices was equal, and it followed that the vertices produced four equilateral triangles which were the faces of a regular tetrahedron.
Jonathan Bowers' birthday, plus a program
This post discusses more of the work of Jonathan Bowers, the same guy whose shape names I used back in my "List of Uniform Honeycombs" post. In particular, it talks about Bowers Exploding Array Function (BEAF for short, also called Array Notation), a notation that represents enormous numbers as multidimensional arrays (and beyond) of positive integers. This post may be the most interesting to readers of the blog because BEAF has gained a cult following around the Internet, and is an inspiration for many modern large number notations found on the Googology Wiki, such as Bird's array notation, Hyp Cos's Strong array notation, and Sbiis Saibian's Hyper-Extended Cascading-E Notation.
In my post, I present a Python program that I wrote to "evaluate" Bowers arrays into large numbers, one step at a time. In reality, the program usually either ends up repeatedly decrementing a number larger than one million, but still small enough to be expressible directly as a binary integer inside the computer's memory, until the maximum recursion depth is reached, or otherwise ends up crashing trying to evaluate an expression with such a number in the exponent. This was deliberate; as the post states, the results of evaluating most Bowers arrays are numbers too large to fit in the universe! Even an array as small as {3, 3, 3} evaluates to a number equal to 3^3^3...^3^3, with 7,625,597,484,987 threes. This number couldn't fit in the observable universe if written out in full, and its number of digits couldn't fit, and the number of digits in its number of digits couldn't fit... in fact, you could take the number of digits over seven trillion times and the resulting number would still be too large to write out in full! I mostly wrote the program to showcase the fact that BEAF is a recursive function, and thus computable. Even though BEAF produces numbers so large they have no uses outside of pure mathematics, the arrays can be evaluated step-by-step with a computer. In fact, a computer with infinite memory and time could evaluate any Bowers array all the way down to the final mind-boggling result!
Unfortunately, I abandoned work on the program soon and never got beyond implementing the rules for 2-dimensional arrays. However, I may update it when Bowers' 50th birthday arrives later this November.
I first learned of Bowers Exploding Array Function in 2011 after discovering Bowers' work with polytopes. I learned about linear arrays through Bowers's own web page describing his notation, and I learned about multidimensional arrays from a post on qntm.org and its sequel on everything2.com. But Bowers' notation goes way beyond multidimensional arrays, into super-dimensional arrays (don't ask) and tetrational arrays. I slowly learned how these worked through immersion and from Googology Wiki; it became easier after I learned that each level of tetrational space corresponds to an ordinal number below ε0. Bowers' notation goes even further, into pentational arrays, hexational arrays and beyond. In 2014, I learned that no one understood how these worked, besides possibly Bowers; his webpage never accurately defined them. However, much work has been done on the Googology Wiki about proposing various formal definitions for the various array structures beyond tetrational arrays, a topic that relates to the wild world of ordinals beyond ε0. I will probably discuss these formalizations in a future post some day. In fact, earlier in 2019 Bowers announced that he was planning to make a video series about higher level array structures, so we can still look forward to an official definition of BEAF.
Unnamed post about 2D lattices of points
This post is about 2D lattices of points generated by a pair of basis vectors, where the basis vectors have integer coordinates. In it, I proved that the fraction of all points in Z^2 that are in the lattice is 1/|D|, where D is the determinant of the matrix whose columns are the basis vectors. In the proof, I use the well-known fact from vector calculus that the area of a parallelogram in 3-space is equal to the absolute value of the cross product of its edge vectors (although I mistakenly leave out the absolute value sign). I also write an overly long alternate proof that every point in Z^2 is in the lattice if and only if |D| = 1. Interestingly, I had never taken linear algebra when I made this post (I only knew about determinants and matrix inverses through Khan Academy videos), and I ended up rediscovering by myself the fact that the determinant is a scaling factor of the transformation.
In this post, I use an image that I created with the Khan Academy Processing.js programming tool: https://www.khanacademy.org/computer-programming/new/pjs. The image of the matrix equation was made using Microsoft's Math Input Panel for Windows 8 (however, most equations in later posts were made using latex2png.com).
Higher-dimensional Pascal's Triangle and its sequel
In these posts, I consider how the trinomial coefficients, quadrinomial coefficients, and beyond can be arranged into higher-dimensional generalizations of Pascal's triangle, which are called Pascal's simplices (plural of simplex). I investigate several properties of the simplices, including:
How the numbers can be derived from counting combinations of objects into multiple groups
How each layer of a simplex can be obtained by adding numbers in the layer above, similar to the rows of Pascal's triangle
How the entries on each row of the n-dimensional simplex sum to a power of n
How each entry in the (n + 1)st row of a simplex counts the number of vertices of a uniform n-polytope with simplectic symmetry
How the entries on the interior of each layer sum to one of the starter constants!
I rediscovered all of these properties by myself because I didn't want to be disappointed if I learned that Pascal's simplices had already been investigated. As it turns out, this was in fact the case. Almost every property I mention is described in two Wikipedia articles, Pascal's pyramid and Pascal's simplex. The article "Pascal's pyramid" has references to the object going back to the 1970s. The earliest known publication of Pascal's pyramid seems to be this paper by John and Larry Staib, who appear to be father and son. Even they believe, like I did, that the triangle is so elegant and easy to construct that it must have been discovered before.
The posts mention higher-dimensional simplices, hypercubic tessellations, simplectic tessellations, and partition numbers. I learned about all these topics on Wikipedia (except for partition numbers, which I learned about in The Book of Numbers by John Conway and Richard Guy, rather than being rediscovered by me. The "advanced polytope terminology" in the second post, such as "Biexipetirhombated dodecadakon," is Jonathan Bowers' nomenclature for kaleidoscopical convex uniform polytopes, described on these pages of Bowers and Richard Klitzing: [0], [1]. The textual representation of a Coxeter-Dynkin diagram (o3o3x3o3x3o3o3o3x3x3o) was also developed by Klitzing.
I created some of the illustrations in my post using the Khan Academy Processing.js programming tool and used paint.net to screenshotted and cropped (and in one case modify) them. The code to generate these illustrations is available here: [0], [1], [2]. The other images were created by cropping screenshots of Notepad.
Cyclotomic polynomials and repeating decimals
This post came out of a lifelong interest in using repeating decimals to represent rational numbers. I was interested in this subject ever since my dad showed me how the decimal expansions of different multiples of 1/7 consisted of the same cyclic permutation of 6 digits.
In the post, I mention that in order for an integer p to be the period length of the base-b expansion of 1/a, a must divide b^p - 1. I made this connection myself as a child by studying the repeating decimals of 1/7. I also found out that if a is prime and not a factor of b, the period p must be a factor of a - 1 by considering the possible different cycles that can occur when taking different multiples of 1/a. All of these facts are well-known, and are mentioned on the Wikipedia article for repeating decimals.
I also mention that the primes a with period p are all factors of cb(p), the bth cyclotomic polynomial evaluated at x = p. I learned this after investigating this page from Studio Kamada, which gives the known prime factors of cb(10) for every value of b up to 300000 (!). I discovered the page when studying the factorization of repunits (for which there is a similar page on the same site) and trying to isolate the factors of (10^p - 1)/9 that had period length p rather than some proper divisor of p.
In the post, I mention Artin's Constant and the related conjecture involving full-reptend primes in base b. I learned about these topics from The Book of Numbers by Conway and Guy. The images were created using latex2png.com.
1 note
·
View note
Text
LCM of binomial coefficients
A few months ago, when I was doodling in math class, I stumbled across a surprising formula for the least common multiple (LCM) of all terms in a row of Pascal's triangle.
I wasn't even looking for such a formula. I was just experimenting with numbers of the form LCM(1, 2, ..., n). The formula for the LCM of all terms on the nth row of Pascal's triangle (i.e. the one that starts 1, n...) is: LCM(1, 2, ..., n + 1)/(n + 1).
Researching online, I found that this identity was proven in 2009 by Bakir Fahri (see [1]). The OEIS entry (A002944) links the proof, which is based on finding the p-adic valuations (exponent on the prime p in the prime factorization) of the left and right side of the identity for all primes p. However, the proof I found was quite different and I am not sure whether it has been found before.
First consider the harmonic triangle. The harmonic triangle, developed by Gottfried Leibniz, is like the reciprocal of Pascal's triangle, except each term on the nth row is divided by n + 1:

Because the formula for the rth term on the nth row of Pascal's triangle is nCr = n!/(r!(n - r)!), the rth term on the nth row of the harmonic triangle has the formula 1/((n + 1)(nCr)) = r!(n - r)!/(n + 1)!. Let us denote this value by F(n, r).
We know that each term in Pascal's triangle is the sum of the two terms above it: nCr + nC(r + 1) = (n + 1)C(r + 1). Similarly, the following relation holds for the terms in the harmonic triangle: F(n, r) + F(n, r + 1) = (r!(n - r)! + (r + 1)!(n - r - 1)!)/(n + 1)! = r!(n - r - 1)!(n + 1)/(n + 1)! = r!(n - r - 1)!/n! = F(n - 1, r).
In other words, each term in the harmonic triangle is the sum of the two terms below it.
Now, consider the nth row for a particular value of n. To make the reasoning easier to understand, I will choose n = 7, but the logic is the same for all rows.
1/8, 1/56, 1/168, 1/280, 1/280, 1/168, 1/56, 1/8
What is the smallest value that we can multiply by all these terms to produce integers? Note that the reciprocals of the terms are just (n + 1) nCr. Thus, the question is the same as asking for the least common multiple of (n + 1) nCr for r from 0 to n. By factoring out n + 1, we see that this value is equal to m = (n + 1) LCM(nC0, nC1, ..., nCn). In our example, m = 840. Let's try multiplying every term by m:
105, 15, 5, 3, 3, 5, 15, 105
Because each term is the sum of the two below it, we can build 840 times the entire first eight rows of the triangle by adding from below and all the terms will be integers:
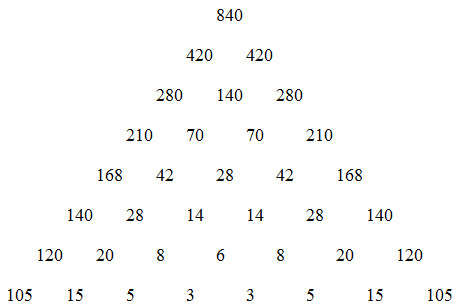
In general, if all the terms in a row are integers, all terms in the rows above will also be integers. Furthermore, because we multiplied by the least common multiple of the denominators, the numbers in the bottom row have 1 as their greatest common factor.
In fact, because the third of any three numbers in an upward pointing triangle can be determined from the other two, the left and right diagonal of the triangle also have 1 as their greatest common factor. If they didn't and had some common factor of f > 1, all numbers in the first n + 1 rows of the triangle would have the same factor f. This is because the entire triangle can be constructed by subtracting adjacent terms in the left diagonal to form the next diagonal over, and then repeating for each subsequent diagonal. Then a smaller common multiple of all the numbers in the triangle would be m/f. But m is the least common multiple by definition, which is a contradiction.
In fact, the numbers down either outer diagonal are m, m/2, m/3, ..., m/(n + 1). In our example, these are 840, 420, 280, 210, 168, 140, 120, 105. In trying to identify m, we see that it must be divisible by 1, 2, ..., n + 1. Furthermore, if m were not the least common multiple of 1 through n + 1, then some factor m/k would be. Then m, m/2, ..., m/(n + 1) would all be divisible by k, but we have just established that their greatest common divisor is 1. In conclusion, we must have m = (n + 1) LCM(nC0, nC1, ..., nCn) = LCM(1, 2, ..., n + 1). Therefore, LCM(nC0, nC1, ..., nCn) = LCM(1, 2, ..., n + 1)/(n + 1). QED.
An interesting consequence of this theorem is that the LCM of one row of Pascal's triangle is usually less than the LCM of the previous row. This is because LCM(1, 2, ..., k) = LCM(1, 2, ..., k - 1) whenever k is not a prime power. However, the increases in the value of LCM(1, 2, ..., k)/k that occur with increasing rarity, whenever k is a prime power, make up for the slight decreases caused by increasing k whenever k is not a prime power, and the sequence increases overall.
Here are the first few terms of the sequence, from n = 0 to n = 21:
1, 1, 2, 3, 12, 10, 60, 105, 280, 252, 2520, 2310, 27720, 25740, 24024, 45045, 720720, 680680, 12252240, 11639628, 11085360, 10581480
And here are the quotients when the terms in each row of Pascal's triangle are divided into the corresponding multiple:
1
1, 1
2, 1, 2
3, 1, 1, 3
12, 3, 2, 3, 12
10, 2, 1, 1, 2, 10
60, 10, 4, 3, 4, 10, 60
105, 15, 5, 3, 3, 5, 15, 105
280, 35, 10, 5, 4, 5, 10, 35, 280
252, 28, 7, 3, 2, 2, 3, 7, 28, 252
2520, 252, 56, 21, 12, 10, 12, 21, 56, 252, 2520
2310, 210, 42, 14, 7, 5, 5, 7, 14, 42, 210, 2310
27720, 2310, 420, 126, 56, 35, 30, 35, 56, 126, 420, 2310, 27720
25740, 1980, 330, 90, 36, 20, 15, 15, 20, 36, 90, 330, 1980, 25740
24024, 1716, 264, 66, 24, 12, 8, 7, 8, 12, 24, 66, 264, 1716, 24024
45045, 3003, 429, 99, 33, 15, 9, 7, 7, 9, 15, 33, 99, 429, 3003, 45045
720720, 45045, 6006, 1287, 396, 165, 90, 63, 56, 63, 90, 165, 396, 1287, 6006, 45045, 720720
680680, 40040, 5005, 1001, 286, 110, 55, 35, 28, 28, 35, 55, 110, 286, 1001, 5005, 40040, 680680
12252240, 680680, 80080, 15015, 4004, 1430, 660, 385, 280, 252, 280, 385, 660, 1430, 4004, 15015, 80080, 680680, 12252240
11639628, 612612, 68068, 12012, 3003, 1001, 429, 231, 154, 126, 126, 154, 231, 429, 1001, 3003, 12012, 68068, 612612, 11639628
11085360, 554268, 58344, 9724, 2288, 715, 286, 143, 88, 66, 60, 66, 88, 143, 286, 715, 2288, 9724, 58344, 554268, 11085360
10581480, 503880, 50388, 7956, 1768, 520, 195, 91, 52, 36, 30, 30, 36, 52, 91, 195, 520, 1768, 7956, 50388, 503880, 10581480
References
Bakir Farhi, An identity involving the least common multiple of binomial coefficients and its application, arXiv:0906.2295
A002944 - Online Encyclopedia of Integer Sequences
1 note
·
View note
Text
Updates to blog layout and math expressions
I just made some updates to my blog CSS to ensure that the HTML subscripts and superscripts are formatted properly. This is one of a number of steps I plan to take to ensure that my inline math expressions are easily readable.
I constantly strive to integrate beautifully formatted expressions into my page and in my last post I took a big step in this direction by embedding my formulae as images created from LaTeX expressions, which I made using the site latex2png.com. Sometime in the future, I will be using a tool such as MathJax to embed this type of expression into posts more neatly. In the nearer future, however, I plan to create CSS for my own custom "math class", mimicking LaTeX, to enclose simpler expressions while still using latex2png for multi-line or non-linear ones, such as those including fractions or sigma notation. By the time you read this, I may have already edited my last post to use this class for all the textual formulae. If will be used to prettify inline expressions ℒ(i)·k̂ + etħis.
(If the words "LaTeX" and "like this" above appear large and in a fancy Roman font, it means that the new math class is now up and working properly.
It should also be noted that I have had a less than pleasant experience trying to get my documents formatted properly on Tumblr. Considering Tumblr's default settings are to not show subscripts and superscripts in HTML, this is not very surprising. As an example, there is no way to put an image inline without directly editing the code of a post, and switching back and forth between different text editors often butchers the code of a post, removing blockquotes and botching italicized characters that are next to non-italicized ones. For this reason, I may eventually abandon Tumblr entirely and move my blog to Wordpress or, more ideally, my own site.
0 notes
Text
Cyclotomic polynomials and repeating decimals
Ever since I was a small child I have been fascinated with repeating decimals, decimal expansions that end up repeating a sequence of digits indefinitely. For example:

, which repeats the four digits 2970 again and again. In this particular example, the digit string 2970 is called the reptend, and the decimal is said to have period length 4. Over the years, my intent shifted specifically to studying decimals between 0 and 1 whose digits started repeating right after the decimal point, and I started seeing the repeating digits more as their own separate entity with addition and multiplication rules that just happened to be isomorphic to the addition and multiplication of repeating decimals. In this post, I will attempt to explain some of the many discoveries and surprises I found when studying these numbers.
Rationality of Repeating Decimals
One of the first obvious things to notice about repeating decimals is that the numbers they describe are always rational. The proof of this fact is simple, and many readers have probably already seen it. It amounts to showing that each repeating decimal number x can be expressed as an infinite geometric series (1):
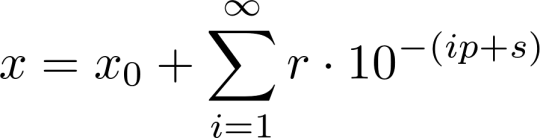
In this series, x0 is the part of the decimal before the repeating digits, r is the reptend as an integer, p is the period length, and s is the number of digits after the decimal point before the reptend. Summing the series reveals that
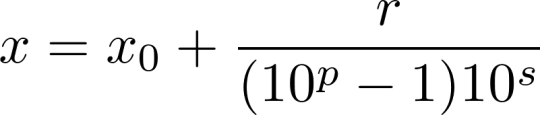
. Because x0 is rational (as it is a terminating decimal) and the numerator and denominator of the fraction are integers, it follows that the sum of the two is also rational. Based on the fact that the decimal expansion for x0 terminates after s digits, we can rewrite this expression as (2)
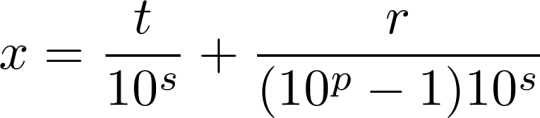
In this expression, t is the integer formed from digits of the decimal before the beginning of the reptend. The numerator and denominator of each fraction are integers, so we have just expressed x as the sum of two rational numbers, which it itself a rational number. This shows that every repeating decimal is a rational number.
It is slightly harder to prove that every rational number is a repeating decimal. Let x be rational. It follows that

for some integers a and b. Now, consider the sequence of reals s defined by (3):


Let n be any positive integer. As s1 is rational and sn consists of an integer subtracted from an integer multiple of sn - 1, it follows by induction that sn is rational. Similarly, it follows by induction that b·sn is an integer, and because each sn is calculated by taking the fractional part of a real number, it follows that 0 ≤ sn < 1.
Thus sn must be equal to
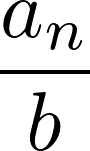
for some integer an between 0 and b - 1. Since each term is calculated solely from the previous term, then if sn = sn + p for some positive integer p, it follows that sk = sk + p for all integers k greater than n. Because sn can take on only a finite number of values, a duplicate term in the sequence like this must happen eventually. This reasoning suffices to show that the terms in s eventually enter into a cycle.
Now, it can be shown inductively that

for n > 1. Because the formula for the nth digit in the decimal expansion of x is

, the decimal expansion of x must also enter into a cycle. Thus, all rational numbers have repeating decimal expansions.
Unit fractions
Now, consider the decimal expansion of a number of the form

, where a is an integer. For this value of x,
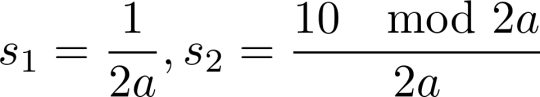
, and in all following terms of the sequence, the numerator is made by multiplying the previous numerator by 10 and taking the result mod 2a. Thus, all terms after s1 have even numerators, so s1 does not appear again in the sequence and the first digit in the decimal expansion of x is not part of the reptend. The same logic holds for numbers of the form
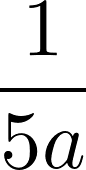
, so it can be deduced that all unit fractions whose denominator is a multiple of 2 or 5 have non-repeating digits at the beginning of their repeating decimal expansions.
What about when the denominator is not a multiple of 2 or 5? As it turns out, in this case the reptend will always repeat from the beginning, regardless of the value of the numerator. However, to simplify our calculations, we will only prove this for unit fractions.
To see this, consider equation (2). If our fraction is

, where a is not divisible by 2 or 5, then the right side of equation (2) can be rewritten as a single fraction with integers as its numerator and denominator:
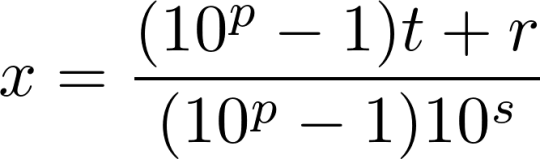
. Rearranging, we get
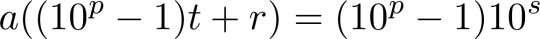
. Because a, not being divisible by 2 or 5, has no factors in common with 10s, then (10p - 1)t + r must be divisible by 10s, and thus 10s can be factored out of both the numerator and denominator. Therefore, x can be rewritten as
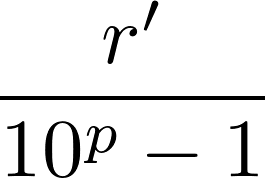
, where r' is an integer less than 10p - 1. This suffices to show that the reptend in the decimal expansion of x starts at the beginning.
An interesting consequence of this observation is that 10p - 1 is a multiple of a. Furthermore, we see that the quotient of these two values, r', is just the reptend of x. This gives a theorem:
Theorem 1a
For every a not divisible by 2 or 5, there exists a value p, equal to the length of the reptend of 1/a, such that a divides 10p - 1. The value (10p - 1)/a is the reptend of 1/a.
Because 10p - 1 divides 10kp - 1 for all k > 1, r divides 10kp - 1 as well. But r does not divide 10n - 1 for any n not divisible by p. If it did, formula (2) with s = t = 0 could be used to show that 1/a repeated after n digits, contradicting our assumption that p did not divide n.
Theorem 1b
For every a not divisible by 2 or 5, there exists a value p, equal to the length of the reptend of 1/a, such that for every integer n, a divides 10n - 1 if and only if p divides n.
As an example, take a = 31:

In this case, the bar over the digits mean that the digits repeat; that is, they make up the reptend. The period length p is 15, and indeed, we see that

. We also can check that 9, 99, 999, 9999... 99999999999999 are not divisible by 31.
Generalization to arbitrary bases
All the logic so far in this post can be generalized straightforwardly from base 10 to any other (integer) base greater than 1; each repeating base-b expansion of digits corresponds to a rational number and vice versa. Unit fractions whose denominators a are coprime to b (not divisible by any prime factor of b; such as indivisibility by 2 or 5 in base 10) are precisely those unit fractions whose base-b expansions have no digits before the reptend begins, and it is those values of a that divide bp - 1 for some value of p, and only multiples of that value, which is what Theorems 1a and 1b have already stated for b = 10:
Theorem 2
For every positive integer a coprime to a base b > 2, there exists a value p, equal to the length of the reptend in the base-b expansion of 1/a, such that for every integer n, a divides bn - 1 if and only if p divides n. The value (bp - 1)/a is the reptend of 1/a.
In the interest of abstraction, the rest of this post will generally speak of base b instead of base 10.
How to find the value of p?
It is an interesting problem to find the value of p corresponding to given a and b. The least trivial case happens when a is prime. From Fermat's little theorem, it is known that when a is prime and coprime to b, a divides ba - 1 - 1. Therefore, p must divide a - 1.
When p = a - 1 for some prime a, a is called a long prime or full reptend prime to base b. The fraction of primes which are long primes to a base is not known, but for most bases it is thought to be equal to Artin's constant, about 0.373956.... When b is a perfect square, no odd prime can be a long prime to base b because for any odd prime a = 2q + 1, bq - 1 = (√b)a - 1 - 1 is divisible by a. In general, there is no way to see what the period length of 1/a will be without checking it.
Given p and b, how do we find a?
Continuing to talk of prime values of a, how would we find all the primes whose reciprocals had a given period length in a given base? Or, given p and b, how do we find a?
For p to be the period length, it is necessary that a divide bp - 1. The simplest way to find these values is to check every prime factor of bp - 1 as a possible value of a. We can check these contenders by defining a sequence tn (4):

The resulting values are just a·sn + 1, where sn is defined as in (3) except the inductive step involves multiplication by b instead of 10. The index of the second occurrence of 1 is the length of the repeat, and we need to check that this index value is p.
Let's use this method for an example where p = 8 and b = 31. We have bp - 1 = 852891037440, which is 28·3·5·13·37·409·1129. Checking each of these prime factors x, we get the sequences:
2: 1, 1, 1, 1, 1, 1, 1, 1, 1...
3: 1, 1, 1, 1, 1, 1, 1, 1, 1...
5: 1, 1, 1, 1, 1, 1, 1, 1, 1...
13: 1, 5, 12, 8, 1, 5, 12, 8, 1...
37: 1, 31, 36, 6, 1, 31, 36, 6, 1...
409: 1, 31, 143, 343, 408, 378, 266, 66, 1...
1129: 1, 31, 961, 437, 1128, 1098, 68, 692, 1...
We need to check the location of the first 1 in each sequence after the initial term. If the initial term is considered the 0th, only two numbers' sequences have the second 1 at the 8th place, which is required for p to be 8. Only x = 409 and x = 1129 satisfy this property, so the only possible values of a are 409 and 1129.
Note that because the terms of t are formed by repeatedly multiplying by b mod x,

. Since x divides bp - 1, tp = 1 for each sequence t, but this is not always the first occurrence of 1 after t0. Equivalently, the base-p expansion of 1/x always repeats after p digits, but it is not always the minimum repeat length.
We see many problems with this method. For one thing, it involves factoring a number whose length is proportional to the value of p. For another, we already showed that p must divide a - 1. This eliminates all values of x except 409 and 1129.
Let y be any factor of p other than p. As all primes whose reciprocals have period length y are factors of by - 1, all primes whose reciprocals have period length p are factors of the quotient (bp - 1)/(by - 1). If we could divide bp - 1 by the product of by - 1 for all factors y of p, the resulting number would still have all possible values of a in its prime factors.
Cyclotomic polynomials
Define a sequence of polynomials as follows (5):
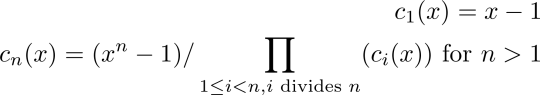
The resulting polynomials will be:

We will now prove that each term of this sequence is a polynomial. Note that the zeroes of xn - 1 are the nth roots of unity, n complex numbers all having 1 as their nth power. Based on the formula for these numbers as the exponential function of imaginary numbers, we can define a set of binomials Bn the product of whose members equals xn - 1:

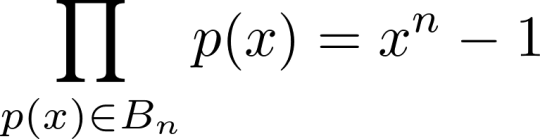
We can define another set of binomials Sn as follows:

We claim that: (6)
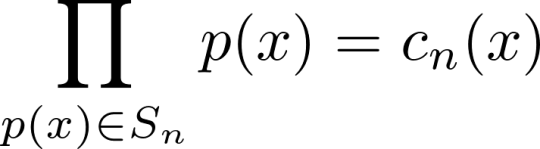
This is trivially true for n = 1. Now assume that it is true for all n < k. In particular, it holds true for all factors of k less than k, which we will call f1, f2.... The expression for each member p(x) of the set Bk contains a fraction k'/k (in the exponent of the constant term) where k' is a non-negative integer less than k. If GCD(k', k) ≠ 1, then this fraction can be reduced to fz'/fz, where fz is some factor of k less than k. As the fraction has been reduced to lowest terms, GCD(fz', fz) = 1. Thus, p(x) is a member of Sfz. In this way, every member of Bk where GCD(k', k) ≠ 1 belongs to a unique set Sfz for some factor fz of k. Also, every member of one of the aforementioned sets also belongs to Bk, as can be seen by multiplying the numerator and denominator of the member's fraction by the factor required to make the denominator k. Thus, there is a one-to-one correspondence between Bk and the other sets.
The remaining members of Bk are those where GCD(k', k) = 1, and their product is equal to

. By our assumption of (6), the denominator is equal to the product of cf(x) for each given value of f. Thus, the product of the members of Sk can be written:

. By definition, this is equal to ck(x). We have just verified (6) for n = k. By induction, (6) holds for all positive integer values of n. Furthermore, (6) defines cn(x) as a polynomial while (5) shows, via polynomial long division, that the coefficients of cn(x) are integers.
We have just proved that each cn(x) is a polynomial with integer coefficients. Because the zeroes of this polynomial are roots of unity, which when plotted on the complex plane appear as points on the unit circle, the polynomials cn(x) are known as cyclotomic polynomials.
Cyclotomic polynomials and repeating decimals
Let's say we find the value of cp(x) at the point x = b. If b is an integer, then cp(b) is also an integer. Let P be the multiset of all prime factors of bp - 1, let Qn be the multiset of prime factors of cn(b). Let f1, f2, f3... be the proper divisors of p. Due to the factorization of bp - 1, the multiset P can be partitioned into the multisets Qf1, Qf2 ... Qp.
Now let f be a proper divisor of p. Because cf(b) is a factor of bf - 1, any prime a from Qf is a prime factor of bf - 1 and hence is not a valid value of a corresponding to the given p and b. The only valid values of a must be in P but not in any Qf. Therefore, they must be in Qp, or equivalently factors of cp(b).
This gives us an easy way to narrow down the possible values of a. The value cp(b) often has fewer than half the number of digits of the value bp - 1. However, we still don't know if every prime factor of cp(b) is a possible value of a. In particular, the only possible values of a are one more than multiples of p.
Let us assume that a divides cp, and a = m·p + 1 for some integer m. Then a divides bp - 1. If 1/a does not have a period length of p and instead has a period length that is some proper divisor k of p, then a divides bk - 1. Since the factorization of bp - 1 into cyclotomic numbers includes every cyclotomic number in the factorization of bk - 1 in addition to cp, we conclude that cp divides

. Since each of the p/k terms on the right hand side is congruent to 1 mod a, a must divide p/k. But a = m·p + 1. This creates a contradiction, whereby a is both greater than and not greater than p. We conclude that the period length of 1/a being a proper divisor of p is impossible.
Theorem 3
The primes a such that 1/a has period length p in base b are precisely the factors of cb one more than mutliples of p.
0 notes
Text
This is a follow-up to my previous post about higher-dimensional analogs of Pascal’s triangle. Here I will discuss more properties of this extension.
Connection to the binomial theorem
It is well known that the n-th row of Pascal’s triangle gives the coefficients for (x + y)^n. In fact, the term A(r, n - r) is the coefficient for the term x^r*y^(n - r).
This works because each term in the expansion of (x + y)^n is computed by taking the product of the members an ordered list of n x’s and y’s formed by selecting one term (either x or y) from each factor (x + y). This leads the creation of all 2^n possible lists of n x’s and y’s, leading to 2^n terms in total. However, many of these terms are the same due to multiplication being commutative. More specifically, two lists will have the same product if and only if they have the same number of x’s and y’s in them. For example, in the expansion of (x + y)^7, three of the 128 terms encountered will be x*x*x*x*y*y*y, x*y*x*y*x*y*x, and y*y*y*x*x*x*x. These all have the same value of x^4*y^3.
When expanding (x + y)^n, each term will be of the form x^r*y^(n - r) for some nonnegative integer r, r ≤ n. The number of copies of this term encountered, in terms of r, is equal to A(r, n - r) due to each copy coming from a list of r x’s and (n - r) y’s. This explains why the coefficient of each term (which is equal to the number of copies of that term in the expansion) is A(r, n - r) AKA the r-th member of the n-th row of Pascal’s triangle.
From this, it is easy to extend the idea to trinomials; expressions of the form (x + y + z)^n. In the expansion of this expression, each term is of the form x^r*y^s*z^(n - r - s) for some nonnegative integers r and s, r + s ≤ n. Before addition of alike terms, there is one term for each list of n x’s, y’s, and z’s, which get multiplied together. So, similar to the binomial theorem, the coefficient of x^r*y^s*z^(n - r - s) is the number of lists of r x’s, s y’s, and n - r - s z’s, equal to A(r, s, n - r - s). This number is the r-th number from the beginning, and the s-th number from the end, on the (n - r - s)-th row of the n-th layer of Pascal’s tetrahedron. Notice that r, s, and (n - r - s) are both the coordinates of the number and the exponents x, y, and z in the term. Also notice that the values r, s, and (n - r - s) can be permuted in any way and the value will be the same; this follows from the commutativity of the A function, but also can be easily derived by the fact that the expression (x + y + z)^n has symmetry between x, y, and z so permuting the exponents keeps the coefficient the same.
Of course, this also works in higher dimensions. In the expansion of (x0 + x1 + x2 ... + xd)^n, the coefficient x0^r0*x1^r1*x2^r2*...*xd^rd = A(r0, r1, r2 ... rd). The values r0 + r1 + r2 ... + rd need to add to n, of course, meaning that this value occurs on the nth layer of Pascal’s simplex.
In summary, the coefficients of the nth power of a polynomial with d terms are the numbers from the nth layer of Pascal’s d-dimensional simplex!
Factors of factorials
or
how many distinct numbers can be on each layer?
You might have noticed that a formula for A(r, s, t...) is (r + s + t...)!/(r!*s!*t!...). That is, it is the factorial of the sum of the coordinates divided by the factorial of each of the coordinates themselves. What if we set the sum to a constant value? It is clear that on the nth layer, every number will be a factor of n!. This means that as we progress up the dimensions, from triangle to tetrahedron to pentachoron, etc., the values on the nth layer will never be higher than n! no matter what the dimension is. (More on this later.)
Which are the possible terms on the nth layer, for various values of n?
For n = 0 it’s trivial::
0! = 1
For n = 1 it’s still trivial:
1!/(1!) = 1
For n = 2 we have:
2!/(1!*1!) = 2
2!/(2!) = 1
For n = 3 there is:
3!/(1!*1!*1!) = 6
3!/(2!*1!) = 3
3!/(3!) = 1
For n = 4:
4!/(1!*1!*1!*1!) = 24
4!/(2!*1!*1!) = 12
4!/(2!*2!) = 6
4!/(3!*1!) = 4
4!/(4!) = 1
For n = 5:
5/(1!*1!*1!*1!*1!) = 120
5!/(2!*1!*1!*1!) = 60
5!/(3!*1!*1!) = 20
5!/(2!*2!*1!) = 30
5!/(4!*1!) = 5
5!/(3!*2!) = 10
5!/(5!) = 1
In general, these numbers can be found by dividing n! by the product of factorials of numbers that add up to n. This sequence is A036038 in the OEIS, and its name, “triangle of multinomial coefficients”, emphasizes the property we just found. For each n, there is one distinct term for each set of positive integers that adds up to n. This term is located at all the places whose coordinates are permutation of this set of numbers, plus an optional number of zeroes. For example, 2 + 3 + 5 = 10, and so the partition of 10 into 2, 3, and 5 produces the terms A(2, 3, 5), A(2, 5, 3), A(5, 3, 2), A(0, 3, 5, 2), A(0, 0, 5, 0, 2, 3, 0) and more, all on the tenth layer of various dimensional simplexes. In fact, all take places in the layer that are equivalent under symmetry. The number of nonzero numbers in this partition is the smallest dimension of simplex in which the term occurs. The total number of distinct terms that can appear on the nth layer is the nth partition number.
Since a limit exists to the number of distinct terms that appear on a single layer, regardless of dimension, there must be some dimension at which new terms just stop appearing. For example, the 5th layer of Pascal’s triangle contains 1, 5, and 10. Pascal’s tetrahedron adds 20 and 30. Pascal’s pentachoron (4-dimensional simplex) adds 60 to the list, and Pascal’s hexateron (5-dimensional simplex) adds 120. But after that, each new dimension adds no new terms to the 5th layer. In fact, as different copies of the same term are equivalent under symmetry, the only terms added to the 5th layer after 5 dimensions (4 dimensions for the layer itself) are symmetric transformations of the terms on one facet!
To see how this works, think about how the shape of each layer gets built when dimensions are added. The 5th layer of Pascal’s tetrahedron is a triangle, and each side of the triangle is just the 5th row of Pascal’s triangle. The 5th layer of Pascal’s pentachoron is a tetrahedron, and each of its four triangular faces is the 5th layer of Pascal’s tetrahedron. In general, in n dimensions, each layer is an (n - 1)D cross section of the figure itself. The shape of the layer is an (n - 1)-dimensional simplex, and it has n copies of the same layer one dimension lower as its (n - 2)-dimensional facets. Each term from one of these facets is only symmetric to terms on other facets, not on the simplex’s interior. But after n = 5 dimensions, all of the terms on its 5th layer are equivalent, meaning symmetric, to the terms on one of its facets. So they all appear on facets, which means that past 5 dimensions, every term on the 5th layer of Pascal’s simplex occurs on the outside. This property is independent of the numbers in the simplex and is still interesting when considering the geometry alone.
And this happens sooner or later for every layer. Which means that if you start with a long line of objects, build it into a triangle with the original line as the base, make that into the base of a pyramid, make that pyramid into the base of a 4D pyramid, make that pyramid into the base of a 5D pyramid... past some dimension, all of the objects added to pyramid will appear on the outside, on the pyramid’s facets.
In fact, it’s pretty easy to tell when this will happen. Remember, the number of nonzero coordinates is the minimum dimension of the simplex the term appears in. For layer n, the maximum minimum dimension for a term--in other words, the largest dimension containing a term not in previous dimensions--occurs when n is partitioned into the most parts. This happens when n is partitioned into n copies of 1. The coordinates for the term are A(1, 1, ...1, 1), with n 1s. This means that it occurs when Pascal’s simplex is n-dimensional. Also, since all the coordinates are identical, it is equidistant from each of its layer’s facets, meaning it is in the center of the nth layer. (It can also be proven to be in the center by the fact that it has no symmetric equivalents in the same dimension, again because the coordinates are identical.) This term is equal to n!.
New theorem:
Going up the dimensions, the nth layer of Pascal’s triangle stops getting new distinct terms after n dimensions, and every term in the layer thereafter is on the hypersurface. The final distinct term occurs in n dimensions (layers are (n - 1)-dimensional). It is in the center of the layer and equals n!.
Now you might be thinking, “Wait, are the values of all these terms actually different? You’ve been referring to them as ‘distinct terms’ when their coordinates come from different partitions of the layer number, but what’s to say no two distinct terms on the same layer have the same value?” This actually does happen. In fact, it happens every time n!/(r0!*s0!...z0!) = n!/(r1!*s1!...z1!); that is, when a number can be written in two different ways as a product of factorials of numbers that sum to the same value. In fact, even if they don’t sum to the same value, one of the them can be padded with 1′s until they do. So any two products of factorials with the same value will suffice.
The smallest such identity is 3!*5! = 1!*1!*6!, which leads to A(3, 5) = A(1, 1, 6) = 56. Thus, on the 8th layer of Pascal’s Tetrahedron, the number 56 appears on coordinates that are permutations of both (1, 1, 6) and (0, 3, 5). From this identity, both sides can be multiplied by any factorial product, leading to the following equivalences:
A(1, 3, 5) = A(1, 1, 1, 6) = 504
A(2, 3, 5) = A(1, 1, 2, 6) = 2520
A(1, 1, 3, 5) = A(1, 1, 1, 1, 6) = 5040
A(3, 3, 5) = A(1, 1, 3, 6) = 9240
A(1, 1, 1, 3, 5) = A(1, 1, 1, 1, 1, 6) = 55440
...
The number of distinct terms on each layer in n or more dimensions (or equivalently, on all dimensions taken together) is given by OEIS sequence A070289.
--
There are several other remarkable properties. Remember how I said that for each term A(r, s, t, ... z), the terms given by permutations of (r, s, t, ... z) are located at symmetrical positions under the layer’s simplectic symmetry? The number of these terms, since the layer has the shape and symmetries of a simplex, is just the number of ways to reflect or rotate a point to make distinct points using the symmetries of that simplex. But wait! This number is just the number of permutations of the coordinate--and what is a function that finds the number of permutations of a list of numbers? We have spent this entire blog post playing with one!
All that is needed to do is to express the number of occurrences of each distinct coordinate in the coordinate list. Let’s say that the first coordinate occurs a times in total, the second distinct coordinate occurs b times, the third occurs c times, etc. Then the total number of permutations is A(a, b, c, ... k), where the list has k distinct terms. Since the original coordinate list had d terms, the number of permutations is a term on the dth layer of a new Pascal’s simplex.
This doesn’t just work for integer coordinates either. In fact, it works for any list of d coordinates that can be mapped to a point in (d - 1)-dimensional space. Remember, the space is made of all the points in the d-dimensional space whose coordinates add to n, making a cross section through the d-dimensional space.
Each way to permute a list of coordinates in this space, when applied to the points, produces one of the transformations that make the symmetry group of the (d - 1)-dimensional simplex. The possible values of A(a, b, ... k) (the number of coordinate permutations) are the number of distinct points a single point can be mapped to under these transformations. Remember this, because it will be important.
Higher-dimensional kaleidoscopes
What really is a “line of symmetry”? Think about it. A symmetry is a set of transformations under which a set of points is invariant. For example, when an object has bilateral symmetry, it means that the position of each point can be reversed and it will match up to another point. If this reversal transformation is done to every point in 2D space, there will be a set of points that map to themselves. These points lie along a line, They are called the fixed points of the transformation, and the line they lie along is commonly called the “line” of symmetry of the aforementioned object.
Now let’s go back to our (d - 1)-dimensional space. Each point has d coordinates, leading to d! different permutations of coordinates and therefore d! different transformations of the points. It is easy to see that these transformations are one-to-one and onto, and therefore invertible. Furthermore, the fixed points under any transformation (besides the identity one) must all have some repeating numbers in their list of coordinates, as this is the only way that a non-trivial permutation of a list can output the same list. Conversely, each point with repeating numbers in its coordinates is a fixed point under some non-trivial transform.
Loosely speaking, the simplest-looking type of transform other than the identity transform is one that exchanges two coordinates while leaving the others the same. There are d*(d - 1)/2 of these. Each one can be described by starting with the d-by-d identity matrix and swapping two rows. This matrix acts as a linear transformation on R^d, and since it is a permutation matrix whose determinant is -1, it acts to reverse R^d; the fixed points make a subspace of dimension d - 1. The nth cross-section of R^d also gets reversed; the fixed points are the (d - 2)-dimensional intersection of the cross section and the subspace.
When d > 3, this intersection cannot be called a “line” of symmetry, as it is more than one dimension. Instead, let’s call it a hyperplane of symmetry. The d*(d - 1)/2 hyperplanes of symmetry together act like mirrors in space of d - 1 dimensions, and these transformations form a basis for the entire symmetric group. That is, any of the d! transformation of a single point can be formed by reflecting it through a combination of hyperplanar mirrors, like a kind of higher-dimensional kaleidoscope. Together, these mirrors cut the space into d! regions of points, these points together making up the set of all points not lying on any mirror.
Now, you might want to avoid the next part if you aren’t an expert on higher-dimensional geometry, as it contains a lot of advanced polytope terminology.
Each A(d - 1) polytope is a convex uniform polytope formed by a Wythoffian operation on a (d - 1)-dimensional simplex. As it is uniform, it must be vertex-transitive, which means that any two vertices can be mapped onto each other using symmetric transforms. We have already seen what the transforms making up (d - 1)-simplectic symmetry are. The number of possible vertices of such a polytope must be a number of distinct vertices that are produced by a single vertex after each transformation. Thus, the number of possible vertices of any Ad - 1; polytope must be of the form A(p, q, ... z) where p, q, ... add to d. For example, the tetrahedron (o3o3x in Coxeter diagram) has A(3, 1) = 4 vertices, the truncated pentachoron (o3o3x3x) has A(3, 1, 1) = 20 vertices, and the biexipetirhombated dodecadakon (now there’s a shape you don’t think about every day) (o3o3x3o3x3o3o3o3x3x3o) has A(3, 2, 4, 1, 2) = 69300 vertices.
A sequence that appears everywhere
I want to finish this article as soon as possible, but there is one last property of the A function and the multidimensional Pascal’s “corner” that I just have to mention. As I mentioned in the previous post, the nth layer of the d-dimensional structure has terms that sum to d^n. But what if we sum just the terms on the inside of the nth layer; that is, every term whose coordinates are all positive?
What does this mean in terms of the A function? Remember, the A function gives the number of ways to order a sequence made of copies of distinct numbers, each number of copies corresponding to one of its arguments. If there are d terms--call them p, q, r, ... z--, none of which are 0, the value of the function describes the number of runs of a sequence of p 0s, q 1s, r 2s ... z (n - 1)’s. Summing these values up for all possible positive integer values of p, q, r, ... z (that sum to n of course), we find the total number of n-digit strings that use every digit from 0 to d - 1, and only digits in that range.
If you remember one of my previous posts, you should be getting an epiphany right about now. If not, here is a quote straight from my “Starter constants and mysteries” post:
The A-th starter constant of the B-th powers is really the number of A-digit strings (I’m not calling them numbers, because the first digit can be 0 and it is still considered to have A digits), that use every digit from 0 to B - 1.
Yup, that’s right! It’s the starter constants! The sum of all A(p, q, r, ... z) for each set of d nonzero terms p...z that sum to n, is equal to SC(n, d)!
0 notes
Text
Higher-dimensional Pascal’s Triangle
Most readers of this blog are probably familiar with Pascal’s Triangle. If not, it consists of rows of integers where the spaces between numbers in one row are directly above numbers in the next row down. The first row is made of two infinitely long strings of 0s separated by a 1. Each number on a subsequent row is derived by summing two adjacent numbers on the previous row, so each row contains one more nonzero term than the previous one. The zeroes aren’t written in the finished diagram, so it looks like the top of an infinitely large triangle:
It is well known that the rth number (using zero-based indexing) on the nth row (also using zero-based indexing) is the value nCr, read as “n choose r”, a function which computes the number of ways to choose r objects from a set of n, where the order of the chosen objects doesn’t matter. However, there are other ways to think of this operation. One of those ways is to consider a string of n objects consisting of r copies of one object and n - r copies of another object. Then nCr is the number of permutations of the string.
It is also helpful to stop thinking of it as a function of the total length of the string and the number of permutations. Instead, it should be thought of in terms of the number of objects of each type. If r objects are of type 0 and s objects are of type 1, then there are (r + s)Cr ways to order the string. Let’s call this value A(r, s).
Also, from now on in my examples, the “type 0″ objects will all be the number 0, and the “type 1″ objects will be the number 1, so as to match the index of the functional argument determining the number of copies of that object. Now the strings of objects can be considered lists of numbers.
One of the benefits of this new understanding is that the identity nCr = nC(n-r) can now be expressed as A(r, s) = A(s, r). Under the visualization, all this means is that the number of lists of r zeroes and s ones is the same of the number of lists of r ones and s zeroes. Another benefit is that the cases where nCr = 0 (where the value lay “outside” of the triangle) now become the cases where one of r or s is negative but r + s ≥ 0. The values that form the triangle itself come from the cases where r and s that are both nonnegative.
Now we can create a grid of all possible values of A for nonnegative values of r and s by plotting the value A(r, s) onto the point (r, s) in R^2:
This is Pascal’s triangle as seen from a different angle, In fact, it now looks more like the corner of a square, and this visualization as a quadrant of a plane will be useful when we extend the concept to higher dimensions. In Pascal’s triangle, the nth row of the triangle was the set of terms such that r + s = n. This line cuts a cross section through the grid perpendicular to the line r = s.
Three dimensions
Now that we have constructed Pascal’s triangle with a function that gives the number of orderings of zeroes and ones in various amounts, one might wonder what we can construct similarly from a function computing the number of orderings of three numbers. Let’s call this function A(r, s, t), where there are r, s, and t objects of each type. It will be understood as the number of ways that r zeroes, s ones, and t twos can be put into a list. Obviously the value of A(r, s, t) remains the same however r, s, and t are permuted.
If we plot the values A(r, s, t) on the points in 3-space (r, s, t) for nonnegative r, s, t, we get what looks like the corner of a cube. What happens when we set r + s + t, the total number of items to order, to a constant? Will we get a layer from a 3D version of Pascal’s triangle?
The points (r, s, t) in R^3 such that r + s + t is a constant integer form a plane perpendicular to the line r = s = t. The subset of this plane for positive r, s, t forms an equilateral triangle, whose vertices are on the r, s, and t axes. The points in this triangle such that r, s, and t are integers are arranged like the vertices of a triangular tiling, and each point is sqrt(2) away from its neighbors.
Under this geometric interpretation, this is the structure analogous to the nth row of Pascal’s triangle. It forms a triangle of points, n + 1 along each outer edge, and each point is associated with a trio of coordinates (r, s, t) from the original lattice and a corresponding value A(r, s, t) of the function.
Here is what the first 6 layers look like:
For each triangle, the left, right, and bottom edges contain the points where r, s, and t are 0 respectively. (Actually, the edges could be chosen in any order for this.) The lines of points through the triangle, parallel to one of these edges and x neighbors away from it, are the points whose coordinate corresponding to the direction of the edge (left, right, or bottom) has the value x. Of course, only two coordinates are required to label every point uniquely, but using three coordinates emphasizes the symmetry between the three values in the function; in fact, each permutation of r, s, and t maps points to other points and transforms the triangle onto itself! This is a beautiful way to demonstrate that the group of all permutations of three elements is the same as the symmetry group of an equilateral triangle!
So how do you compute these numbers anyway?
The formula for A(r, s, t) is A(r, s)*A(r + s, t). Of course, it is also A(r, t)*A(r + t, s), and A(s, t)*A(s + t, r). Intuitively, A(r + s, t) represents the number of lists that can be made from t twos and r + s blanks to be filled in with 0 and 1, and A(r, s) represents the number of ways the blanks in each list can be filled by r zeroes and s ones.
In practice, the nth layer can get computed from the first n + 1 layers in Pascal’s triangle. First un-flatten the square corner as seen above back into a triangle corner with 60-degree angles, and then multiply each member of the xth layer (where x goes from 0 to n) by A(n - x, x) = nCx. This is fun to do, as it doesn’t make the S3 symmetry of the resulting arrangement of numbers obvious until you actually try it.
Each layer can be constructed from the previous layer
There is also another way to construct each layer. In Pascal’s triangle, each row below the zeroth can be constructed by summing pairs of adjacent numbers on the previous row. Specifically, A(s, t) = A(s - 1, t) + A(s, t - 1). Even the 1s on the outside are created by summing 1s on the previous row with invisible zeroes neighboring them. (A(s, t) = 0 when s or t is negative.)
In the 3D version, triples of adjacent terms are of two types. One type, with coordinates (r - 1, s - 1, t), (r - 1, s, t - 1), (r, s - 1, t - 1), forms the vertices of a triangle pointing down. The other type, with coordinates (r - 1, s, t), (r, s - 1, t), (r, s, t - 1), forms the vertices of a triangle pointing up.
If the next layer gets made by summing both types of triples, it will have twice the density of numbers as the previous layer:
But if we sum only the triples pointing up, the ones with coordinates (r - 1, s, t), (r, s - 1, t), (r, s, t - 1) and put the results in the middles of the triangles, then the result will be the next layer, and the numbers will have coordinates (r, s, t) for all values of r, s, and t that sum to the layer number.
The fact that A(r - 1, s, t) + A(r, s - 1, t) + A(r, s, t - 1) = A(r, s, t) is obvious when we consider the fact that A(r, s, t) represents the number of strings of r 0s, s 1s, and t 2s and these consist of:
A(r - 1, s, t) strings where a 0 is followed by r - 1 0s, s 1s, and t 2s
A(r, s - 1, t) strings where a 1 is followed by r 0s, s - 1 1s, and t 2s
A(r, s, t - 1) strings where a 2 is followed by r 0s, s 1s, and t - 1 2s.
Sum of each layer
In Pascal’s triangle, the numbers in the nth row sum to the value 2^n. This can be explained by the fact that there are 2^n strings of length n made of only 0s and 1s. Similarly, as there are 3^n strings of length n made of only 0s, 1s, and 2s, each layer of Pascal’s tetrahedron sums to a power of 3.
Higher dimensions
The function A(r, s, t) can be generalized to any number of arguments. Really, it can be thought of as taking in a tuple, of any length, of integers as arguments. For integers r, s, t, ... z, it can be defined as A(r, s, t, ... y, z) = A(r, s, ... y) * A(r + s + ... + y, z), and for two arguments, A(r, s) is defined as (r + s)Cr. The nth layer of the structure can be found by taking the set of points (r, s, ... z) whose coordinates that sum to n, and associating to each point with tuple T of coordinates the value A(T), which will be positive if no coordinate is negative and 0 if at least one of them is negative but the sum is still positive.
Just as the layers of the 3D Pascal’s triangle are shaped like equilateral triangles, the layers of the higher dimensional analogs will also be shaped like a regular simplex, a shape which is just a pyramid of a regular simplex from the previous dimension, where all edges are the same length. For example, the 3D simplex is a tetrahedron, and the 4D simplex is a pentachoron.
In d dimensions, the lattice of points (r0, r1, r2, r3, ... r(d - 1)) where each r-value is an integer, forms the vertices of a d-hypercubic tessellation of edge length 1. The subset of points where the coordinates are required to sum to an integer n form the vertices of a (d - 1)-simpletic tessellation of edge length √2. The points on this layer with nonnegative coordinates form a subset of this lattice in the shape of a (d - 1)-dimensional simplex. From now on, these points will be what I mean when I refer to a “layer” of the figure.
The points in the nth layer of the d-dimensional lattice (which itself is (d - 1)-dimensional, of course) can be decomposed into a stack of n + 1 (d - 2)-dimensional sub-layers of points in the shape of (d - 2)-dimensional simplices, ranging from n + 1 points per edge down to 1 point per edge (at 1 point per edge, there is also only one point in the entire sub-layer; this is the tip of the layer). This stack constructs the (d - 1)-dimensional simplex as a pyramid of a (d - 2)-dimensional simplex.
How to find the numbers in each layer
The same method mentioned above, of constructing the nth layer of 3D Pascal’s pyramid from the first n + 1 layers of Pascal’s triangle, also works for higher dimensions. For the nth layer of the d-dimensional pyramid, stack the first n + 1 layers of the (d - 1)-dimensional pyramid (the 0th to the nth layer), and multiply each number on the x-th layer by A(n - x, x) which is just equal to nCx.
For example, here are the first 5 layers of 3D Pascal’s triangle:
And here are the cross-sections of layer 4 in 4D Pascal’s triangle:
Except this does not work exactly from a geometrical standpoint, because in the first n layers of Pascal’s pyramid, adjacent points in neighboring layers are only 1 unit apart, instead of the √2-unit distance between adjacent points from the same layer. Instead of a regular simplex for each layer, this method simply produces a cut-off corner of a hypercube! To fix this problem, all that is needed is to “stretch” the pyramid by increasing the distance between neighboring layers (now “sub-layers” as part of a layer themselves) until all adjacent points have the same distance of √2 between them.
Each layer can also be constructed by adding terms from the previous layer.
To understand how this would work, you have to realize that in (d + 1)-dimensional Pascal’s triangle, there are d different types of “gaps” between points. The x-th type is found by taking the coordinates of a point x layers ahead and finding all possible ways to subtract 1 from x of those coordinates. For example, in 4D Pascal’s triangle, a gap of type 2 would be made of these points: (r - 1, s - 1, t, u), (r - 1, s, t - 1, u), (r - 1, s, t, u - 1), (r, s - 1, t - 1, u), (r, s - 1, t, u - 1), (r, s, t - 1, u - 1) - there is one gap for each possible set of values of r, s, t, and u.
Gaps of type 1 form the vertices of a simplex, flipped relative to the orientation of the layer itself. The numbers from these points get added to form the number in the next layer, at the center of the gap. Each point belongs to exactly d+1 of these gaps, so the sum of the terms from the (n + 1)st layer is (d + 1) times the sum of the terms from the nth layer. The initial layer sums to 1 (as 1 is the only nonzero term in that layer), and therefore the nth layer sums to the value (d + 1)^n (again, the initial layer must be counted as the 0th, not the 1st).
Also, not all these gaps are the same shape. Some form the vertices of a simplex, some the vertices of a rectified or birectified simplex, etc. In fact, these gaps are the shapes of the facets of the simpletic tessellation whose vertices are the points in a single layer.
So, to review:
(d + 1)-dimensional Pascal’s triangle is a collection of points in (d + 1)-dimensional space with coordinates (r, s, t, ... y, z) where each coordinate is a positive integer.
Each point is associated with a value A(r, s, t, ... y, z), where A(r, s) = (r + s)Cr = (r + s)!/(r!*s!) and A(r, s, ... y, z) = A(r + s + ... + y, z).
The nth layer of this triangle is the set of points for which r + s + ... y + z is a constant.
The points in a single layer are the vertices of a d-dimensional simplectic tessellation (d-honeycomb) of edge length √2 -- the 2D simplectic tessellation is the triangular tiling and the 3D simplectic tessellation is the tetrahedral-octahedral honeycomb.
The value of the point (r, s, ... y, z) can be found by summing the values of the points (r - 1, s, ... y, z), (r, s - 1, ... y, z) ... (r, s, ... y - 1, z), (r, s, ... y, z - 1).
Nice! Soon we’ll look at more properties of this triangle, like which numbers can appear where.
1 note
·
View note
Text
How to calculate exact trig values, part 3
11th roots of unity
This is my third post about calculating exact trigonometrical values based on roots of unity. I am giving the examples for prime roots of unity.
My previous post showed that the 7th roots of unity had square roots and cube roots in their formulas, because 7 - 1 = 2*3. Since 11 - 1 = 2*5, the 11th roots of unity will have square roots and 5th roots in their expression, namely, a sum of 4 fifth roots, each of formulas involving the fifth roots of unity.
Before we start, I want to make a correction to something I said earlier. In my last post I stated that a1 + a2 + a3 + r1*(a1 + r1*a2 + r2*a3) + r2*(a1 + r2*a2 + r1*a3) = 3*r1, and a1 + a2 + a3 + r2*(a1 + r1*a2 + r2*a3) + r1*(a1 + r2*a2 + r1*a3) = 3*r2. In fact, the first left-hand expression equals 3*r2 and the second equals 3*r1. This is the corrected expression for the 7th root of unity:
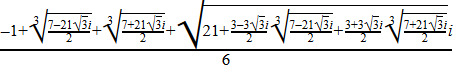
Now on to the current calculation.
Here are the 11th roots of unity:
1, x1, x2, x3, x4, x5, x6, x7, x8, x9, x10
Let’s try to find a power cycle that goes through each 11th root of unity once, except for 1, starting with x1.
Let’s try squaring each term. Since x(n) is just x1^n, and x1^11 = 1, then x(a)*x(b) = x((a + b) mod 11). This is axiom 2 from the first post.
x1, x2, x4, x8, x5, x10, x9, x7, x3, x6, x1...
This gives us a cycle of 10, like we wanted. Now to find each root of unity, we are going to be solving a quadratic equation and a quintic equation. Let’s first find the roots of the equation by summing together every fifth term of the cycle, starting from the first, second, third, and fourth, and fifth terms:
x1 + x10 = a1
x2 + x9 = a2
x4 + x7 = a3
x8 + x3 = a4
x5 + x6 = a5
To find each of these values, we will need to find the following values, where r1, r2, r3, and r4 are the four 5th roots of unity not equal to 1, r1 has a polar angle of 2*pi/5, and r(n) = r1^n:
a1 + a2 + a3 + a4 + a5 = s0
a1 + r1*a2 + r2*a3 + r3*a4 + r4*a5 = s1
a1 + r2*a2 + r4*a3 + r1*a4 + r3*a5 = s2
a1 + r3*a2 + r1*a3 + r4*a4 + r2*a5 = s3
a1 + r4*a2 + r3*a3 + r2*a4 + r1*a5 = s4.
Then we can find the five roots by taking the inverse Fourier transform:
s0 + s1 + s2 + s3 + s4 = 5*a1
s0 + r4*s1 + r3*s2 + r2*s3 + r1*s4 = 5*a2
s0 + r3*s1 + r1*s2 + r4*s3 + r2*s4 = 5*a3
s0 + r2*s1 + r4*s2 + r1*s3 + r3*s4 = 5*a4
s0 + r1*s1 + r2*s2 + r3*s3 + r4*s4 = 5*a5
We already know that s0 = x1 + x10 + x2 + x9 + x4 + x7 + x8 + x3 + x5 + x6 = -1, by axiom 1, but s1, s2, s3, and s4 must be calculated via their fifth powers as sums of 5th roots of unity.
The algebra required to solve for s1^5 is so long-winded that it took 2 whole years since I started writing this post before I finally managed to concentrate on it long enough to solve it. There are 3125 values, of 70 different types, to sum in the expanded expression. Each term consists of a product of 5 values of the form a(n), multiplied by a 5th root of unity, each of which need to be expanded into a pair of x(n) values. Here is the result:
(a1 + r1*a2 + r2*a3 + r3*a4 + r4*a5)^5 = -196 - 130*r1 + 255*r2 - 20*r3 + 90*r4.
After substituting into this expression the respective values for r1, r2, r3, and r4 that we calculated way back in the first post, it becomes:
s1 = -979 - 275*√5 - 220i*√(10 - 2√5) + 275i*√(10 + 2√5)
Amazing! I always get a feeling of wonder when I see such large and arbitrary-looking numbers in a formula for such an easy to define value. The only patterns I can see in these numbers are that -979, -275, -220, and 275 are all multiples of 11 - the degree of the roots we are calculating - and that -275, -220, and 275 are all multiples of 5 as well. The divisibility by 5 occurs because all the terms containing a value r(n) could have their a(n) values cyclically permuted to make 5 different terms having the same value, forcing the total number of r(n)-containing terms to be a multiple of 5 for each value of n.
The expressions for s2^5, s3^5, and s4^5 can be found by substituting out powers of r1 for the corresponding powers of r2, r3, and r4 respectively. Their values are:
s2^5 = -979 + 275*√5 - 220i*√(10 + 2√5) - 275i*√(10 - 2√5)
s3^5 = -979 + 275*√5 + 220i*√(10 + 2√5) + 275i*√(10 - 2√5)
s4^5 = -979 - 275*√5 + 220i*√(10 - 2√5) - 275i*√(10 + 2√5)
Now we need to take 5th roots of each of these expressions. The trouble here is in finding out which 5th root to use. As I said in my first post on roots of unity, I am defining c^(1/n) to be the value x having a polar angle equal to 1/n that of c, such that x^n = c, and therefore x has an angle between 0 and 2*pi/n radians. For the other nth roots of c, it needs to be multiplied by one of the nth roots of unity. But we don’t know what s1's polar angle is, so we don’t know if it’s 1, r1, r2, r3, or r4 times (s1^5)^(1/5).
I haven’t found any pattern in which 5th root to choose when, but a calculator can check that:
s1 = r1*(-979 - 275*√5 - 220i*√(10 - 2√5) + 275i*√(10 + 2√5))^(1/5)
s2 = r1*(-979 + 275*√5 - 220i*√(10 + 2√5) - 275i*√(10 - 2√5))^(1/5)
s3 = r4*(-979 + 275*√5 + 220i*√(10 + 2√5) + 275i*√(10 - 2√5))^(1/5)
s4 = r4*(-979 - 275*√5 + 220i*√(10 - 2√5) - 275i*√(10 + 2√5)^(1/5)
Now we can calculate our a(n) values:
a1 = (-1 + r1*(-979 - 275*√5 - 220i*√(10 - 2√5) + 275i*√(10 + 2√5))^(1/5) + r1*(-979 + 275*√5 - 220i*√(10 + 2√5) - 275i*√(10 - 2√5))^(1/5) + r4*(-979 + 275*√5 + 220i*√(10 + 2√5) + 275i*√(10 - 2√5))^(1/5) + r4*(-979 - 275*√5 + 220i*√(10 - 2√5) - 275i*√(10 + 2√5)^(1/5))/5
a2 = (-1 + (-979 - 275*√5 - 220i*√(10 - 2√5) + 275i*√(10 + 2√5))^(1/5) + r4*(-979 + 275*√5 - 220i*√(10 + 2√5) - 275i*√(10 - 2√5))^(1/5) + r1*(-979 + 275*√5 + 220i*√(10 + 2√5) + 275i*√(10 - 2√5))^(1/5) + (-979 - 275*√5 + 220i*√(10 - 2√5) - 275i*√(10 + 2√5)^(1/5))/5
a3 = (-1 + r4*(-979 - 275*√5 - 220i*√(10 - 2√5) + 275i*√(10 + 2√5))^(1/5) + r2*(-979 + 275*√5 - 220i*√(10 + 2√5) - 275i*√(10 - 2√5))^(1/5) + r3*(-979 + 275*√5 + 220i*√(10 + 2√5) + 275i*√(10 - 2√5))^(1/5) + r1*(-979 - 275*√5 + 220i*√(10 - 2√5) - 275i*√(10 + 2√5)^(1/5))/5
a4 = (-1 + r3*(-979 - 275*√5 - 220i*√(10 - 2√5) + 275i*√(10 + 2√5))^(1/5) + (-979 + 275*√5 - 220i*√(10 + 2√5) - 275i*√(10 - 2√5))^(1/5) + (-979 + 275*√5 + 220i*√(10 + 2√5) + 275i*√(10 - 2√5))^(1/5) + r2*(-979 - 275*√5 + 220i*√(10 - 2√5) - 275i*√(10 + 2√5)^(1/5))/5
a5 = (-1 + r2*(-979 - 275*√5 - 220i*√(10 - 2√5) + 275i*√(10 + 2√5))^(1/5) + r3*(-979 + 275*√5 - 220i*√(10 + 2√5) - 275i*√(10 - 2√5))^(1/5) + r2*(-979 + 275*√5 + 220i*√(10 + 2√5) + 275i*√(10 - 2√5))^(1/5) + r3*(-979 - 275*√5 + 220i*√(10 - 2√5) - 275i*√(10 + 2√5)^(1/5))/5
Unfortunately, since Unicode lacks a fifth root symbol (that I am aware of), I had to write the 5th root of x as x^(1/5).
Anyway, we now know the values of x1 + x10, x2 + x9, x3 + x8, x4 + x7, and x5 + x6.
Since x1 and x10 are complex conjugates, (x1 + x10)/2 is the real part of x1. This is the same value as cos(2*pi/11), and it is just a1/2.
Here is an image of what the expression for cos(2*pi/11) actually looks like when written out (with fifth-root symbols in place of x^(1/5)), just to show you how long it gets.
To figure out the value of, say, x1, we will be needing both x1 + x10 and x1 - x10. We already know the x1 + x10 = a1. Let’s call x1 - x10 = t1.
t1^2 = (x1 - x10)^2 = x2 + x9 - 2 = a2 - 2
So, t1 = √(a2 - 2). And just like a1 = 2*cos(2*pi/11), t1 = 2i*sin(2*pi/11).
So:
sin(2*pi/11) = √(2 - a2)/2 = √(55 - 5*(s1^5)^(1/5) - 5*r4*(s2^5)^(1/5) - 5*r1*(s3^5)^(1/5) - 5*(s4^5)^(1/5))/10.
If written out in full, this expression would look similar to the one given above except that:
the numerator is under a square-root sign
it starts with 55 instead of -1 and then subtracts the 5th roots instead of adding them
All of the 5th roots are multiplied by 5
The 1st and 4th ones don’t get multiplied by r(n) values.
The sines and cosines of 4*pi/11, 8*pi/11, 6*pi/11, and 10*pi/11 can be found by doing operations on a1, a2, a3, and a4 respectively.
--------------------------------------
Whew! That was way more complex than the formula for the 7th roots of unity. Next up is the 13th roots of unity, and I don’t think they will be nearly as hard.
0 notes
Text
Imagine we have an infinite lattice of points, each one having coordinates F(s, t) = [x, y] = [a*s + b*t, c*s + d*t] for some real values {a, b, c, d} where s and t can equal any integers.
For example, here is a picture of the lattice with a = 3, b = 1, c = -2, d = 4:
Points with integer coordinates are shown in the background. The red lines are s = n, the green lines are t = n. Blue points are in the lattice.
As we can see, 1/12 of all the points with integer coordinates are in the lattice. Given a set of a, b, c, d values, how can we tell what fraction of the points will be in the lattice?
We can start by seeing that drawing lines for the set of all points where s = n or where t = n, for all integer values of n, divides the plane into a tiling of parallelograms, as in the image above. There is a direct correspondence between the parallelograms and points in the lattice; each point is the lower-left corner of a parallelogram, and each parallelogram has a lattice point in its lower-left corner. Therefore, the area of a parallelogram is the same as one over the fraction of all integer-coordinate points that are in the lattice.
Now, one could calculate the area of this parallelogram by taking the area of the (a + b) by (c + d) rectangle that it’s embedded in and subtracting the areas of the b by c rectangles and the a by c and b by d right-angled triangles... but it just so happens that the area of a parallelogram embedded in 3-space can be found by taking the magnitude of the cross product of the two vectors formed by going from one point to its two neighbors. In this case, those vectors are [a, c, 0] and [b, d, 0]. Their cross product is [0, 0, a*d - b*c], and its magnitude is a*d - b*c.
This value, a*d - b*c, is the factor by which the area of any 2D shape before the transformation changes when the transformations is applied, as any shape can be approximated by a large number of parallelograms.
The transformations can also be written:

and as you might have noticed, the scaling factor a*d - b*c is the determinant of this matrix. This means that the determinant of any matrix is how much it “stretches” a plane when multiplied by all points on the plane.
What this means is that if and only if the value a*d - b*c = ±1, the lattice points cover every point with integer coordinates. But there is another way to find out whether all integer-coordinate points are reached. Simply find the values s0, s1, t0, t1, such that F(s0, t0) and F(s1, t1) equal [1, 0] and [0, 1] respectively. If these s and t values are integers, then every point [m, n] can be reached by setting s = s0*m + s1*n and t = t0*m + t1*n.
So what are the values of s0, s1, t0, and t1 in terms of a, b, c, and d? The equations to solve are:
a*s0 + b*t0 = 1
c*s0 + d*t0 = 0
a*s1 + b*t1 = 0
c*s1 + d*t1 = 1
s0 = d/(a*d - b*c)
t0 = c/(b*c - a*d)
s1 = b/(b*c - a*d)
t1 = a/(a*d - b*c)
If the scaling factor, a*d - b*c, is called D, these can be written as d/D, -c/D, -b/D, a/D. Since all of them need to be integers, the value D must be a factor of a, b, c, and d.
Let’s say that a, b, c, and d are equal to D*i, D*j, D*k, and D*l, which is true for some integers i, j, k, and l. Substituting these into the formula for D, we get that D = D^2*(i*l - j*k). Since a, b, c, and d are factors of D, they must also be factors of D^2. Similarly, since they are factors of D^2, they must be factors of D^4. In fact, they need to be factors of D to every positive power.
Since a, b, c, and d can only have a finite number of factors, the number of distinct powers of D must be finite. Therefore, D can only be 0, 1, or -1. Clearly letting D = 0 leads to undefined values of s0, t0, s1, and t1. Therefore, the only possible values of a*d - b*c are ±1. Of course, this restriction is not only necessary but sufficient to insure integer values of s0, t0, s1, and t1 and therefore a covering of every integer point in the lattice.
0 notes
Text
Last digits of powers, continued
In my last post on this subject, I proved that for integers {n, x} and x ≥ 2, not only do n^(x + 4) and n^x always have the same last digit (they are congruent mod 10) but n^(x + 20) and n^x always have the same last two digits (they are congruent mod 100)!
Let’s look at the last three digits. First we will look at them in base 5 -- that is, look at the whole number modulo 5^3. We already know that mod 5^2, n^(x + 20) ≡ n^x (except in special cases), so the last two digits repeat with period 20. From here, it is just a small step to prove that the last 3 digits repeat with period 100.
The special cases I mentioned above happen when n is divisible by 5 and x is less than 2. So for now we will assume that n is not divisible by 5.
Say that n^x = p and n^20 = 25*q + 1, which is true for some integer q unless n is divisible by 5. Now, n^(x + 20) is equal to 25*p*q+p, which is congruent to p mod 25, as expected. n^(x + 40) is n^(x + 20 + 20) = 25*q*(25*p*q + p) + (25*p*q + p) which is congruent to 50*p*q + p mod 125. In fact, mod 125, n^(x + 20*k) ≡ k*25*p*q + p for all k. This also means that n^(x + 100) ≡ 125*p*q + p, and therefore is also congruent to p, which equals n^x. Since n^(x + 100) ≡ n^x mod 125, the last 3 digits of the powers of n repeat with period 100.
This holds true for all n and x such that p is an integer, so this pattern works all the way back to n^0.
In the other cases, where n is divisible by 5, n^3 and all higher powers of n are 0 mod 125. So, still speaking in base 5, the last three digits of these powers will repeat with period 1.
This means that, for integers {n, x} and x ≥ 3, n^(x + 100) ≡ n^x mod 125, and thus the sequence formed from the last 3 digits in base 5 of a(x) = n^x always repeats in (a factor of) 100 steps.
Now we need to look at the last digits of n^x mod 8. Remember, for coprime a and b, if a number’s values mod a and mod b are known, its value mod a*b can always be calculated. This means that if the values of n^x repeat with period 100 when taken both mod 8 and mod 125, they also repeat with period 100 when taken mod 1000.
The easiest way here is to realize that if n is odd, n^2 ≡ 1 mod 8. This means that for even x, n^x ≡ 1 (because all even powers are squares) and therefore for odd x, n^x ≡ n. Since n^(x + 2) ≡ n^x, n^(x + 100) ≡ n^x, for odd n and positive x. For even n, n^x is divisible by 8, and so n^x ≡ 0, whenever x ≥ 3.
This means that for integers {n, x} and x ≥ 3, n^(x + 100) ≡ n^x when taken mod 8 or mod 125. It follows that n^(x + 100) ≡ n^x mod 1000. This means that in base 10, the last 3 digits of powers of n should have settled into a cycle of 100 terms by the time n^3 is reached. Compare this to previous results about the last 2 digits and 1 digit, written in formal logic:
∀n,x ∈ ℤ:((x ≥ 3) → (n^(x + 100) ≡ n^x mod 1000)
∀n,x ∈ ℤ:((x ≥ 2) → (n^(x + 20) ≡n^x mod 100)
∀n,x ∈ ℤ:((x ≥ 1) → (n^(x + 4) ≡ n^x mod 10)
At this point, the pattern seems obvious. If we take the number mod 10^p, all we need to do to make the statement true is to make the repeat length 4*5^(p - 1) and say the pattern always works when x ≥ n.
And indeed, looking at the last 4 digits of powers of n, it is seen that they always repeat after 500 terms! Mod 5^4, they repeat every 500 terms for a reason similar to the proof in the second paragraph; and taken mod 2^4, the period is 4, which is also a factor of 500. And for some values of n, 4 terms are needed for the powers to acquire all the factors of 2 or 5 for their last 4 digits to be repeated 500 terms later. So for this pattern to work for all n, the exponent must be at least 4.
But when we get to 5 digits, the pattern seems to break down. One would expect the last 5 digits of n^x to repeat in 2500 terms. Mod 5^5, they all do repeat with period 2500 (or a factor thereof), but mod 2^5, some of them repeat with period 8! For example, 5^6 ≡ 9 and 5^14 ≡ 9, but 5^10 ≡ 25. Since 2500 is not divisible by 8, 5^n and 5^(n + 2500) are not congruent.
It turns out that for general values of n, 5000 terms are needed for powers of n to repeat mod 10^5, and therefore for the last 5 digits of these powers to repeat.
So, what’s the actual formula? Well, unsurprisingly, the repeat length of n^x mod 2^(p + 1) is based on that of n^x mod 2^p. Fortunately, the proof is simpler than for 5^p.
Let’s guess that n^x mod 2^p has a repeat length of 2^(p - 2) (or a factor thereof) when p ≥ 3. After all, this is what we saw for p = 3, 4, and 5. To prove this, we will prove that adding 1 to the value of p doubles the repeat length. Given an odd value k such that k^x mod 2^p has the full repeat length (i.e. it repeats in 2^(p - 2), but no factor thereof, steps), k^0 ≡ k^(2^(p - 2)) ≡ 1, but k^(2^(p - 3)) ≢ 1. If we can prove that k^(2^(p - 2)) mod 2^(p + 1) ≢ 1, the proof will be complete because k^(2^(p - 2)) will be congruent to 2^p + 1 mod 2^(p + 1) and k^(2^(p - 1)) will be congruent to 1, giving k^x a repeat length of 2^(p - 1) mod 2^(p + 1). If we furthermore assume that k^(2^(p - 3)) ≡ 1 mod 2^(p - 1), k^(2^(p - 3)) mod 2^p can only be 1 or 2^(p - 1) + 1. So its square, k^(2^(p - 2)), must be congruent to 1. However, we assumed by induction that k^(2^(p - 3)) mod 2^(p - 1) ≢ 1, and 1 and 2^(p - 1) + 1 are the only values mod 2^p whose square is congruent to 1. So k^(2^(p - 2)) cannot be 1 mod 2^(p + 1) and therefore k^x has a repeat length of 2^(p - 1) mod 2^(p + 1).
This means that 4 terms are needed for powers of n to repeat mod 2^4, 8 terms are needed for powers of n to repeat mod 2^5, and so on. 2^(p - 2) terms are needed for powers of n to repeat mod 2^p, and 5^(p - 1) terms are needed for them to repeat mod 5^p. So for p > 3, 10^(p - 1)/2 terms are needed for x^n to repeat mod p.
0 notes
Text
Jonathan Bowers‘ birthday, plus a program
Today (November 27) is the 47th birthday of a really great mathematician named Jonathan Bowers. He is a mathematician who specializes in studying large numbers and higher dimensional polytopes. Among his many achievements in the study of polytopes were discovering the majority of the known uniform polychora (4-dimensional polytopes) and an even higher percentage of the known uniform higher-dimensional polytopes. He also investigates facet-transitive polytopes and curved objects known as polytwisters. His website can be found here: http://polytope.net/hedrondude/home.htm
He also invented a notation for describing very large numbers, called “infinity scrapers”. This notation, called Bowers Exploding Array Function, takes the form of a linear or multidimensional array (or even above multidimensional and into more abstract spaces, which collapse down to a number of dimensions determined by a value in an intermediate stage in an array’s evaluation). Its rules are as follows:
The first entry is called the base.
The second entry is called the prime entry.
Ones are the default (and smallest) array entry, and each array can be thought of as lying in a multidimensional space each of whose unspecified entries is a 1. For example,
{3, 3, 3} = {3, 3, 3, 1, 1, 1, 1} =
{3, 3, 3, 1, 1, 1, 1...
{1, 1, 1, 1, 1...
{1, 1, 1, 1...
{1...
...
If the prime entry is 1, the entire array evaluates to the base.
The first entry after the prime entry that is not 1 is called the pilot.
The entry right before the pilot is called, if it exists, the copilot.
In each step, the copilot (if it exists) gets replaced by the value of the original array, except with the prime entry decremented.
Also in each step, the pilot of the original array gets decremented.
Every entry before the pilot gets replaced by the base value.
If there are any rows/ spaces before the pilot, they get filled w/th a hypercube of the same dimension of edge length equal to the prime entry, w/th one corner at the first entry of the space.
This continues until the original array consists of just a base and a prime entry. The final value is the base to the power of the prime entry.
I am writing a Python program (currently in development) to “evaluate” an array, except that most of their values are too big to even express in this universe! Here is the link to the code: https://github.com/ericbinnendyk/bowersarray
0 notes
Text
I know so much about polytopes I’m surprised I didn’t talk about them more on this blog. I know that it would probably take about 100 medium-sized posts to do justice to everything I know about them, but one of these days I still plan to delve into the subject from the beginning and explore what I know about it in a neat fashion.
Anyway, a few days ago I was watching a chemistry video on Khan Academy. It involved a geometric proof that the hydrogen atoms in a methane molecule always met the carbon atom at an angle of about 109°. They started by constructing a tetrahedron in such a way that it would be easy to find the angle between two vertices and the center.
In the video, four points were plotted in a 3-dimensional graph: (√(2), 1, 0), (-√(2), 1, 0), (0, -1, √(2)), and (0, -1, -√(2)), and the video was going to explain that those were the vertices of a regular tetrahedron.
Of course, the most obvious way to prove it was to find the squares of the distances between the x-, y-, and z-coordinates of each pair of points, add them together, and determine that the final result was the same in all 6 cases. By the 3D extension to the Pythagorean theorem, these results were the squares of the distances between pairs of points, and thus verifying their equality was equivalent to proving that all the points are equidistant from each other. Knowing that four points are equidistant from each other is sufficient for proving that they are the vertices of a regular tetrahedron.
But my grandiose knowledge of polytopes caused me to notice a more beautiful geometric proof, which hinged on the fact that those four points were just alternate vertices of a cube.
I immediately paused the video and wrote this proof down. Here is what I wrote:
If you start with a cube with coordinates (±√(2), ±1, 0) where the two plus-and-minuses are independent of each other, for four of its vertices, and (0, ±1, ±√(2)) again where the two plus-and-minuses are independent, for the other four; you can remove four of the vertices that aren't adjacent in the cube, and the four remaining vertices will be (√(2), 1, 0), (-√(2), 1, 0), (0, -1, √(2)), and (0, -1, -√(2)).
And I can prove that if you remove four vertices from a cube in such a fashion, the other four will form a regular tetrahedron. In fact, the ones you removed will also form such a tetrahedron.
First of all, let's prove that it actually is a cube that we start with. The eight coordinates I gave above expand out to be:
(√(2), 1, 0), (√(2), -1, 0), (-√(2), 1, 0), (-√(2), -1, 0), (0, 1, √(2)), (0, -1, √(2)), (0, 1, -√(2)), (0, -1, -√(2)).
Now, four of those points (those being (√(2), 1, 0), (-√(2), 1, 0), (0, 1, √(2)), (0, 1, -√(2))) form a square with edge length 2. (This is pretty easy to verify for yourself, especially if you take out the middle coordinates.)
The other four points are just the same, except where the y-coordinate is -1 instead of 1. So each of these points are two units directly below the other points. This means the figure formed is a right prism with height length 2, of a square with edge length 2. Such a prism has to be a cube.
Okay, now it's time for the interesting part of the proof. First, as I said, the four vertices at (√(2), 1, 0), (-√(2), 1, 0), (0, -1, √(2)), and (0, -1, -√(2)) were taken such that no two of them are adjacent to each other. As it turns out, choosing four vertices of a cube in such a way forces the four vertices to be vertices of a regular tetrahedron. This is because the distance between each vertex and the other three is the distance across the diagonal of a square in the original cube, making it √(2) times the edge length of the cube.
This, in turn, is because when the vertices are chosen in this way, a pair of them will be on every square of the cube, directly opposite each other. Each of those pairs will be connected by a line segment which is the diagonal of its square, so therefore its length must be √(2) times the edge length of the square. As there are six squares in the cube and one diagonal for each, this accounts for all six possible pairs of the 4 vertices chosen and determines that they are all the same distance apart.
Lastly, why must the resulting shape be a regular tetrahedron? Start with three points. If these three points are equidistant from each other, they must form an equilateral triangle. Now, if a fourth point is added outside the plane of these three points, a tetrahedron must be formed, in that four sets of three points can be chosen, each of which acts as a triangular face. Finally, since each of these sets of three points must be equidistant, they must form equilateral triangles. Since the shape has equilateral triangles as faces, it must be a regular tetrahedron.
0 notes
Text
Lychrel numbers, part 2
This is a follow-up to my earlier post about Lychrel numbers.
It seems very likely that the reverse-and-add process will never reach a palindrome when starting with 196. This is because when a number is on the order of 10^(2*n), the probably of it resolving into a palindrome in the next iteration is very roughly 1 in 2^n. Since the number multiplies by about sqrt(10) after each iteration, the probability of it reaching a palindrome gets decreases exponentially for each iteration, by a factor of about 2^(1/4). For those with a background in cellular automata, the process can be liked to running a pattern in a very barely exploding rule, like B368/S1278, where the probability of eventual stabilization decreases exponentially with the number of unstabilized cells.
However, like the normality of pi or e, or whether any patterns in the aforementioned rule explode, this has not been proven, because the process is an adequate pseudo-random number generator.
On the other hand, in binary it can be proven that some numbers will never reach a palindrome this way, the smallest being 10110.
This comes from the fact that when a binary number is of the form 10[1]n-101[0]n (where [b]n is the digit b repeated n times), the next four steps of the process will give 11[0]n-110[1]n-201, 10[1]n01[0]n, and 10[1]n01[0]n+1. None of these forms are palindromes, and the fourth is just the first with n replaced by n+1. So whenever a number can be written as 10[1]n-101[0]n for some value of n, by induction it will never produce a palindrome. 10110 becomes 1010100 after two steps and thus, it is proven that it is a binary Lychrel number.
0 notes
Text
Lychrel numbers
One year ago, on July 16, 2015, I got the laptop on which I am writing this now.
First of all, the day July 16 should be familiar to anyone who read my Cheryl’s Birthday post. And when I got my laptop, I wanted to name it after this math problem. At first I thought of naming my laptop Cheryl. But then, I remembered the Lychrel numbers: a set of numbers that was named as a “rough anagram” of the name Cheryl. To make my computer’s name more unique, I decided to name it Lychrel as well, a name that related to two math concepts.
But what are the Lychrel numbers?
Pick a number, like 73. Now add it to its reverse. Keep doing this until the result is a palindrome. In the case of 73, we add 73 + 37 = 110, 110 + 011 = 121, which is a palindrome.
Now, some numbers take a few steps to become a palindrome, like 56. Some take several steps (89 takes 24). And there is strong evidence that some of them never become palindromes.
Numbers that never produce palindromes from this process are called Lychrel numbers. The first Lychrel number is (conjectured to be) 196.
The interesting thing is, though, that no number has been proven to be a Lychrel number in base 10.
Here is a site where a number can be tested for 300 iterations (just replace the 196 in the URL: http://jasondoucette.com/pal/196)
0 notes