
just4programmers
Just 4 Programmers
Just4Programmers can be described as a private limited company that develops softwares. Kayleigh Baxter who is the current Managing Director established it in early 1997. For several years now, Just4Programmers has been a proud Microsoft Gold Partner. This is to mean that it displays the best expertise and competence with regard to Microsoft technologies and also in relation to being an Amazon Web Services specialist.
396 posts
Don't wanna be here? Send us removal request.
Last Seen Blogs

huntawifu
Tenishi

berryjambear
v. 蝶

asktateyukishigaraki-blog-blog
The Joking Motive

ica26
jangkarmelankolis

ahenklisaclar-blog
Ahenkli Saçlar
Text
Exploring DNS with the .NET Core based Technitium DNS Server
Earlier this week I talked about how Your Computer is not a Black Box and I spent time time in TCPView and at the command line exploring open ports on my computer. I was doing this in order to debug an issue with a local DNS server I was playing with, so I thought I'd take a moment and look at that server itself.
The Technitium DNS Server is a personal local DNS server (FOSS on GitHub) written in C# and it runs on Windows, macOS, Linux, Raspberry Pi, etc. I downloaded the Portable app.
For Windows folks who aren't used to .tar.gz files, remember to "eXtract Zie Files!" with "tar -xzvf DnsServerPortable.tar.gz -C ./TechnitiumDNS/" and it's also worth reminding you all that tar.exe, curl.exe, wget.exe and more are all included in Windows 10 and have been since 2017. If that's too hard, use 7zip.
Technitium DNS is pretty cool, you just unzip/tar it and run start.sh or start.bat and it "just works." Of course, I did have a process already on port 53 - DNS - so I did a little debugging, but that was my fault.
Here's the local web UI that you can use to administer the server locally. You can forward to whatever upstream DNS server you'd like, with the added bonus that the forwarder can be DNS over HTTPS so you can use things like CloudFlare, Google, or Cloud9. Using DNS over HTTPS means your DNS lookups can be secured with DNSSEC and are far more secure and private than regular DNS over UDP/TCP.
Technitium also includes support for DNS Sinkholes (similar to how I use my Pi-Hole) and Block List URLs. It'll automatically download block lists daily and block ads.
It's also educational to try running your own DNS server and it's fun to read the code! The code for Technitium's DNS Server is up at https://github.com/TechnitiumSoftware/DnsServer and is super interesting from a networking perspective, but also from an C# perspective. It's a very interesting example of some .NET Core code at a very low level and I'm thrilled that it works on every operating system.
There's even bash scripts for setting Technitium up on your RaspberryPi or Ubuntu to make it easy. If you are using Windows and don't care about .NET Core you can use the .NET that's included with Windows and Technitum has a Tray app and Installer as well.
Some of the code isn't "idiomatic" C#/.NET Core but it's interesting to read about. The main DnsWebService.cs is pretty intense as it doesn't use any ASP.NET Core routing or primitives. It's a complete webserver written using only System.Net and its own support libraries, along with some of the lower-level Newtonsoft.Json libraries.
The main DnsServer is also quite low level and very performant. It lives in DnsServer.cs. It opens up n sockets (depending on how many ports you bind to) and starts accepting connections here. DNS Datagrams start getting parsed here, right off the stream. The supporting libraries and networking helper code lives over at https://github.com/TechnitiumSoftware/TechnitiumLibrary which is a wealth of interesting and useful code covering BitTorrent, Mail, and Firewall management. There's a ton of OO representations of networking concepts, and all the DNS records are parsed manually.
Technitium has a DNS Server, client, Mac Address Changer, and open source instant messenger. The developer is extremely prolific. They even host a version of "Get HTTPS for free" that works with Windows and makes getting Let's Encrypt certificates super easy.
Anyway, I've been enjoying exploring DNS again and reminding myself not only that it still works great (since I learned about DNS from sniffing packets in networking class) and it's been updated and improved with caches, DNSSEC, DNS over HTTP and more in the years following.
Here I've set my IPv4 DNS to 127.0.0.1 and my IPv6 DNS to ::1, then I run NSLookup and try some domain lookups.
Again, to be clear, the local DNS server took these lookups and then forwarded them upstream to another server. However, you have the choice for your upstream lookups to be done over whatever protocols you want, you can use Google, OpenDNS, Quad9 (with DNSSEC or without), and on and on.
Are you running your own DNS Server?
Sponsor: Manage GitHub Pull Requests right from the IDE with the latest JetBrains Rider. An integrated performance profiler on Windows comes to the rescue as well.
© 2018 Scott Hanselman. All rights reserved.





0 notes
Text
Top Tips For PCB Design Layout
Are you thinking about designing a printed circuit board? PCBs are quite complicated, and you need to make sure that the layout that you choose is going to operate as well as you want it to. For this reason, we have put together some top tips for PCB design layout. Keep reading if you would like to find out more about this.
Leave Enough Space
One of the most important design tips for PCB layout is that you need to make sure that you are leaving enough space between the components. While many people might think that packing components closely is the best route to take, this can cause problems further down the line. This is why we suggest leaving extra space for the wires that will spread. This way, you’ll have the perfect PCB design layout.
Print Out Your Layout
Struggling to find out if your components sizes match? Our next tip is to print out your layout and compare the printed version to your actual components. Datasheets can sometimes come with errors, so it doesn’t hurt to double check the sizes in real life. If you take some time to do this, you can be sure that the sizes will match.
Think About Width Of Line
When you are deciding the width of the lines in your PCB design, you should make sure that you are choosing this based on the current. If you have a larger current flowing through the lines, then you should make sure to adapt your design to suit this. There are some online calculators that you can use to help make this decision.
Talk To Your Manufacturer
If you spend a long time working on your PCB design project before you have spoken to a manufacturer then you might find that you come across some problems. You need to find out about any specifications that they might have that could affect the design of your project. Use their guidelines to create your design and you’ll find things a lot simpler further down the line.
Compare Your Schematic
Our final tip for those who want to improve their PCB design layout is to compare the layout to the original schematic. You have spent time working on your schematic for a reason so make sure to utilise the tools that allow you to directly compare these. This way, you can be sure that your layout matches what you need for this particular project.
Final Verdict
If you are going to be working on PCB design project in the near future, make sure to take on board all of the tips that we have given you in this article. Think about leaving enough space between your components and considering the width of your lines. You should also make sure to talk with your manufacturer about their specifications before going ahead with the project. This way you’ll have a successful design that will help to create a working PCB.
The post Top Tips For PCB Design Layout appeared first on The Crazy Programmer.
0 notes
Text
8 Things Every Design Student Needs To Know To Succeed
Are you an artistic designer but a little lost in your creative processes?
Don’t worry as it happens to all of us so that’s why I decided to write this blog.
If you are just starting out on your design career path or just curious for some extra tips then this should give you some needed help.
Organize Yourself
This is something that all design students should learn to master and take control of their own calendar. If you can prioritize your projects and manage all the different deadlines then this will help in the long run. You will be able to concentrate on being creative and not miss targets later on.
There are many great ways to keep track from getting a simple calendar and marking projects and deadlines on it or downloading an app with reminders straight to your phone. Also, a great tip I picked up at Uni was completing boring writing assignments that were getting in the way of my creative time. EssayPro is an essay writing service that I used to finish off my work and left me more free time to concentrate on more important design projects.
Be the King of Estimation
The biggest skill I learned to develop would be overestimating time frames for projects. The more successful design assignments completed the better at this you will become. Every project requires a different amount of time to complete so being able to allow yourself enough time is vital. If you have more time left over you can always start something new or try to improve the project. This will help you later on with your design career when your boss piles on the workload and being able to manage it effectively.
Find your Niche
There are a lot of good designers out there but you should find your special talent or market that you enjoy doing and appealing to. Throughout your career especially at the start, you will have to undertake more mainstream tasks. This is great, I even still do this sometimes when the price is right. It is important to find your inner strength and what work really makes you happy. Also, stay good friends and network with other designers in different fields. You never know when they can help out with a project or to find new work. Either way, keep connections from University and in the future try to make new ones also.
Make a Portfolio to Impress
This is basically your resume for future work. So as soon as possible you should start adding different projects that show off your talents. Depending on which area of design you specialize in will depend on how it will look, for example, a graphic design student portfolio will look different to a senior art director’s portfolio but still vital. I would recommend having an online copy and also a printed physical copy to take to interviews as it can give that ‘wow’ factor if done well. I got some nice tips from Canva on how to put a portfolio together that can turn some heads. Always try to pursue work that interests you as I think this is really important, but if a job is not what you had hoped do not be scared to leave it. This is all experience that you can use and also put in your portfolio.
Stay Motivated
While studying there will be times you will become frustrated and unmotivated to carry on. So it is important to be passionate in your work and find ways to stay motivated. Remember passion fuels creativity, which is so fundamental to design. I used to ask myself what I love doing in design and then remind myself in difficult times. This will help you complete your studies successfully and happily.
Keep the Creativity Going
There will be times that your creativity will start drop, but there are ways in which you can maintain and improve it. Don’t be scared to come up with new ideas to gain more inspiration. If they are not welcome don’t get disheartened, just keep what you learned and move onto the next project. They are all skills that can come in useful later on.
Make Friends with Criticism
You are a design student to learn, and there will be lots of times a teacher or peer will not agree with your point of view and give negative critique on your creations. All criticism should be met with an open mind and take it on board to improve your work in the future. This is something that is very difficult to do at first, I used to get very defensive about my work. Later on, you will be able to discuss things through and realize you can learn a lot from other people.
Keep up with New Trends
This also may depend on which area of design you are involved in, but the idea is the same. If you are a painter then maybe change the style or technique to what’s popular at the time. This makes sure you will be popular and remain successful. Also trying to predict holiday trends can help stay on top of your game even for senior graphic designers. Keep your self-development ongoing by attending courses related to your design area this will make sure you are not ‘out of touch’ with your clients. The world of visual design is always changing so its important to keep up to date with it.
Most Importantly: Don’t forget to Believe in yourself!
I hope these tips helped you out and you succeed in your chosen path. Hard work will always lead you to success. I would be interested to see what tips you picked up, so leave something in the comments section below even if you just want to say hi. Good luck!
The post 8 Things Every Design Student Needs To Know To Succeed appeared first on The Crazy Programmer.
0 notes
Text
R vs Python for Machine Learning
There are so many things to learn before to choose which language is good for Machine Learning. We will discuss each and everything about R as well as Python and the situation or problem in which situation we have to use which language. Let’s start
Python and R are the two most Commonly used Programming Languages for Machine Learning and because of the popularity of both the languages Novice or you can say fresher are getting confused, whether they should choose R or Python language to commence their career in the Machine learning domain. Don’t worry guys through this article we will discuss R vs Python for Machine Learning. So, without exaggerating this article let’s get started.
We will start it from the very Basics things or definitions.
R vs Python for Machine Learning
Introduction
R is a programming language made by statisticians and data miners for statistical analysis and graphics supported by R foundation for statistical computing. R also provides high-quality graphics and it also has some popular libraries which help in analytical parts such as R Markdown and shiny.
On the other hand, Python is a simple, easy, fully-fledged and object-oriented high programming language which is used for web development or Software Development made by the very good programmers and the developers’ for the use of general purpose programming. Python is far-flung used in GUI based application’s such of them are games, graphics design, Web applications.
So, guys we can say that R programming language functionality is developed by statisticians’ mind, by thereby give us an advantage in a specific field. While python is often praised for being a general-purpose language with an easy-to-understand.
Speed
Let us start from the very first factor, that is the speed of the language.
When it comes to the speed, python is faster than R only till 1000 iterations but after the 1000 iterations, R starts using the lapply function which increases its speed, in that situation R becomes faster than python. So, both have their own advantages with their limits. let move to the next point i.e code and syntax.
Code and Syntax
In this point, we will discuss the data variables declarations, Data handling capacity with the scatterplot visualization and the clusPlot graphics.
Starting with variable declaration. Let’s take the case of string here. As R uses the similar implementation to that of the S programming language, which uses arrow sign in order to initialize the variables which were also present in case of S programming. These arrows can be used from right to left or left to right indicating whom to assign the variables whereas, python uses an assignment operator to initialize the variables.
So, Basically, R developers thought that it would be better to tell the direction of the assignment rather than just using an assignment operator, which could actually confuse any new programmer about which variable is assigned. next thing data handling capability, here we will discuss the case of Scatterplots’, by which you will see the visualizations in R and Python.
These are the piece of codes in R and Python and after running these codes, you will get the very similar plot results in both the cases, if you check the code here, then this shows that how R data science ecosystem has many smaller packages like GGally, which basically is a package that helps ggplot2 and also it is the most-used R plotting package whereas, In Python, matplotlib is the primary plotting package, and seaborn is widely used layer over the matplotlib. So, these are plots result we were talking about. Graph results of R and Python are both similar, but the only difference is their visualization. So, based on the graph results we can conclude that R has Many packages supporting different method of doing things whereas there is usually one way to do something in python. Moving to the next thing that is graphics.
So, guys here we will discuss the case plots, we already discussed that R was basically built for statistically analysis, so it has many specific libraries for plotting as well. This is the reasons R come up with beautiful graphs and charts whereas python’s main agenda, not for statistical analysis. So, in the early stages of the python packages for data analysis was an issue, but it has improved a lot.
Deep Learning
As you all know almost the majority of the companies are working on Artificial Intelligence (AI), and Deep Learning is the main part of artificial intelligence. So, when it comes to Deep Learning, Python is more versatile then R as it provides more features to deep learning whereas R is new to Deep Learning.
R has newly added APIs like Keras and KerasR which are written in Python. So, guys somewhere in your mind, this question might be floating why Keras? Actually, Keras in Python has the capabilities to run over pythons’ strong APIs like tensorflow or Theano or Microsoft’s CNTK we can say that python has the greater advantage here. Till now we learn both are useful in their own areas or terms.
Percentage Switching
In the past years of Research, the percentage of switching people R to Python are more as compared to Python to R. Let’s say if 10% people are switching from Python to R then, 20% are switching from R to Python which is double as compared to the before scenario. Next point this about trend community support and jobs.
Trends
So, guys lets talk about trend according to the google in last 5 years. The R was more in use but after that, we can see Python is in trend because of its popularity it has overall good support of general purpose programming. If we talk about community support:
Python and R support are quite similar to each other because python supports Mailing list, User-contributed code documentation, and Stack-overflow. So, basically it has more adoption from developers and programmers whereas R language support as also found at Mailing list, User-contributed documentation, and Active Stack-overflow members So, basically R has more adoption for researchers, DataScientist and Statisticians.
Job Trend
Now, lets talk about the job trend.
This is the google graph of the job trend of Python and R. So, guys this Job Posting of R and Python in past 5 years worldwide whereas Python is asked more in comparison to R. How it is possible? because of its popularity and easy to understand feature. Since python is a very versatile programming language which can be used for majority of the purpose such as web-development, game development, artificial intelligence, data science, statistical analysis, etc, whereas R language used among statisticians and Data miners for developing statistical software and Data analysis which clear us that’s why more job for python than R.
In the end, I would like to say both the programming languages are important with their uses. But as we discussed in the previous section python is booming over the years.
The post R vs Python for Machine Learning appeared first on The Crazy Programmer.
0 notes
Text
Your computer is not a black box - Understanding Processes and Ports on Windows by exploring
I did a blog post many years ago reminding folks that The Internet is not a Black Box. Virtually nothing is hidden from you. The same is true for your computer, whether it runs Linux, Mac, or Windows.
Here's something that happened today at lunch. I was testing a local DNS Server (more on this on Thursday) and I started it up...and it didn't work.
In order to test a DNS server on Windows, you can go to the command line and run "nslookup" then use the command "server 1.1.1.1" where 1.1.1.1 is the DNS server you'd like to try out. Go ahead and try it now. Run cmd.exe or powershell.exe and then run "nslookup" and then type any domain name. You should get an IP address.
Given that I was trying to run a DNS Server on localhost:53 (Port 53 is where DNS usually hangs out, just like Port 80 is where Web Servers (HTTP) hang out and 443 is where Secured Web Servers (HTTPS) usually are) I should be able to do this. I'm trying to send DNS requests to localhost:53
C:\Users\scott> nslookup
Default Server: pihole
Address: 192.168.151.6
> server 127.0.0.1
Default Server: localhost
Address: 127.0.0.1
> hanselman.com
Server: localhost
Address: 127.0.0.1
*** localhost can't find hanselman.com: No response from server
> hanselman.com
Weird, that didn't work. Let me try a DNS Server I know works like Google's 8.8.8.8 public DNS
> server 8.8.8.8
Default Server: google-public-dns-a.google.com
Address: 8.8.8.8
> hanselman.com
Server: google-public-dns-a.google.com
Address: 8.8.8.8
Non-authoritative answer:
Name: hanselman.com
Address: 206.72.120.92
Ok, it seems my local DNS isn't listening on point 53. Checking the logs of the Technitium local DNS server shows this:
[2019-04-15 23:26:31 UTC] [0.0.0.0:53] [UDP] System.Net.Sockets.SocketException (10048): Only one usage of each socket address (protocol/network address/port) is normally permitted
at System.Net.Sockets.Socket.UpdateStatusAfterSocketErrorAndThrowException(SocketError error, String callerName)
at System.Net.Sockets.Socket.DoBind(EndPoint endPointSnapshot, SocketAddress socketAddress)
at System.Net.Sockets.Socket.Bind(EndPoint localEP)
at DnsServerCore.DnsServer.Start() in Z:\Technitium\Projects\DnsServer\DnsServerCore\DnsServer.cs:line 1234
[2019-04-15 23:26:31 UTC] [0.0.0.0:53] [TCP] DNS Server was bound successfully.
[2019-04-15 23:26:31 UTC] [[::]:53] [UDP] DNS Server was bound successfully.
[2019-04-15 23:26:31 UTC] [[::]:53] [TCP] DNS Server was bound successfully.
The DNS Server's process is trying to bind to TCP:53 and UDP:53 using IPv4 (expressed as localhost with 0.0.0.0:53) and then TCP:53 and UDP:53 using IPv6 (expressed as localhost using [::]:53) but it seems like the UDP binding to port 53 on IPv4 failed. Weird.
Someone else is listening in on Port 53 localhost via IPv4.
That's weird. How can we find out what ports are open locally?
I can run "netstat" and ask Windows for a list of all TCP/IP connections and the processes that are listening on which ports. I'll also PIPE the results to "clip" which will put it in the clipboard automatically. Then I can look at it in a text editor (or I could pipe it through find or findstr).
You can run netstat --help to get the right arguments. I've asked it to tell me the process IDs and all the details it can.
Active Connections
Proto Local Address State PID
TCP 0.0.0.0:53 LISTENING 27456
[dotnet.exe]
UDP 0.0.0.0:53 LISTENING 11128
[svchost.exe]
TCP [::]:53 *:* 27456
[dotnet.exe]
UDP [::]:53 *:* 27456
[dotnet.exe]
Hm, a service is already listening on port 53. I'm running Windows 10, not a Server so it's odd there's already a DNS listener on port 53.
I wonder what service is it?
I can check the Services Tab of the Task Manager and sort by PID. Or can I run "tasklist" and ask directly.
C:\WINDOWS\system32>tasklist /svc /fi "pid eq 11128"
Image Name PID Services
========================= ======== ============================================
svchost.exe 11128 SharedAccess
That's Internet Connection Sharing, and it's used by Docker and other apps for NAT translation and routing. I can shut it down with the sc (service control) or with "net stop."
C:\WINDOWS\system32>net stop sharedaccess
The Internet Connection Sharing (ICS) service is stopping.
The Internet Connection Sharing (ICS) service was stopped successfully.
Now I can start my DNS Server again (it's written in .NET Core) and I can see with tcpview.exe that it's listening on all appropriate ports.
In conclusion, it's a good reminder to refresh yourself on the basics of IPv4, IPv6, how processes talk to/allocate ports, what Process IDs (PIDs) are, and their relationships. Much of this is taught in computer science university courses but if you're self taught or not doing low level work every day it's easy to forget.
Virtually nothing on your computer is hidden from you!
Sponsor: Manage GitHub Pull Requests right from the IDE with the latest JetBrains Rider. An integrated performance profiler on Windows comes to the rescue as well.
© 2018 Scott Hanselman. All rights reserved.





0 notes
Text
Blocking ads before they enter your house at the DNS level with pi-hole and a cheap Raspberry Pi
Lots of folks ask me about Raspberry Pis. How many I have, what I use them for. At last count there's at least 22 Raspberry Pis in use in our house.
One runs our dakboard family dashboard that we built in a weekend but use every day.
We have at 3 that are set up for retrogaming - one in a 3d printed Gameboy (A pi-grrl, in fact), one in a X-Arcade Tankstick, one in a tiny laser-cut arcade case for the desktop.
I have a Raspberry Pi that runs one of my 3D Printers running Octoprint. This one also has as camera and does time-lapse videos of my 3D prints.
We have another 3 that run little robots my sons and I have built
6 are running in a local Kubernetes Cluster
These 6 Pis are my personal cloud, so maybe there's 16 Pis in the house and one Pi Cloud/Cluster.
One is an internet radio in the 13 year old's room running PiMusicBox.
One is a touchscreen tablet the 11 year old uses for Scratch. Imagine a Linux iPad.
One runs Kodi as an entertainment center in the kids' play room.
One lives in a CrowPi that we use for experiments and .NET Core remote debugging.
Another three are Raspbery Pi Zero Ws for various experiments with one Pi Zero W acting as as backup Open Source Artificial Pancreas.
and most recently one is a Pi-hole. A Black hole that eats tracking cookies, advertising, and other bad stuff. See also "shut your pie hole." AKA that place you put pie.
A Pi-hole is a Raspbery Pi appliance that takes the form of an DNS blocker at the network level. You image a Pi, set up your network to use that Pi as a DNS server and maybe white-list a few sites when things don't work.
I was initially skeptical, but I'm giving it a try. It doesn't process all network traffic, it's a DNS hop on the way out that intercepts DNS requests for known problematic sites and serves back nothing.
Installation is trivial if you just run unread and untrusted code from the 'net ;)
curl -sSL https://install.pi-hole.net | bash
Otherwise, follow their instructions and download the installer, study it, and run it.
I put my pi-hole installation on the metal, but there's also a very nice Docker Pi-hole setup if you prefer that. You can even go further, if, like me, you have Synology NAS which can also run Docker, which can in turn run a Pi-hole.
Within the admin interface you can tail the logs for the entire network, which is also amazing to see. You think you know what's talking to the internet from your house - you don't. Everything is logged and listed. After installing the Pi-hole roughly 18% of the DNS queries heading out of my house were blocked. At one point over 23% were blocked. Oy.
NOTE: If you're using an Amplifi HD or any "clever" router, you'll want to change the setting "Bypass DNS cache" otherwise the Amplifi will still remain the DNS lookup of choice on your network. This setting will also confuse the Pi-hole and you'll end up with just one "client" of the Pi-hole - the router itself.
For me it's less about advertising - especially on small blogs or news sites I want to support - it's about just obnoxious tracking cookies and JavaScript. I'm going to keep using Pi-hole for a few months and see how it goes. Do be aware that some things WILL break. Could be a kid's iPhone free-to-play game that won't work unless it can download an add, could be your company's VPN. You'll need to log into http://pi.hole/admin (make sure you save your password when you first install, and you can only change it at the SSH command line with "pihole -a -p") and sometimes disable it for a few minutes to test, then whitelist certain domains. I suspect after a few weeks I'll have it nicely dialed in.
Sponsor: Seq delivers the diagnostics, dashboarding, and alerting capabilities needed by modern development teams - all on your infrastructure. Download at https://datalust.co/seq.
© 2018 Scott Hanselman. All rights reserved.





0 notes
Text
Accessibility Insights for the Web and Windows makes accessibility even easier
I recently stumbled upon https://accessibilityinsights.io. There's both a Chrome/Edge extension and a Windows app, both designed to make it easier to find and fix accessibility issues in your websites and apps.
The GitHub for the Accessibility Insights extension for the web is at https://github.com/Microsoft/accessibility-insights-web and they have three trains you can get on:
Canary (released continuously)
Insider (on feature completion)
Production (after validation in Insider)
It builds on top of the Deque Axe core engine with a really fresh UI. The "FastPass" found these issues with my podcast site in seconds - which kind of makes me feel bad, but at least I know what's wrong!
However, the most impressive visualization in my opinion was the Tab Stop test! See below how it draws clear numbered line segments as you Tab from element. This is a brilliant way to understand exactly how someone without a mouse would move through your site.
I can easily see what elements are interactive and what's totally inaccessible with a keynote! I can also see if the the tab order is inconsistent with the logical order that's communicated visually.
After the FastPass and Tab Visualizations, there's an extensive guided assessment that walks you through 22 deeper accessibility areas, each with several sub issues you might run into. As you move through each area, most have Visual Helpers to help you find elements that may have issues.
After you're done you and export your results as a self-contained HTML file you can check in and then compare with future test results.
There is also an Accessibility Insights for Windows if I wanted to check, for example, the accessibility of the now open-source Windows Calculator https://github.com/Microsoft/calculator.
It also supports Tab Stop visualization and is a lot like Spy++ - if you remember that classic developer app. There were no Accessibility issues with Calculator - which makes sense since it ships with Windows and a lot of people worked to make it Accessible.
Instead I tried to test Notepad2. Here you can see it found two elements that can have keybook focus but have no names. Even cooler, you can click "New Bug" and it will create a new accessibility bug for you in Azure DevOps.
The Windows app is also open source and up at https://github.com/Microsoft/accessibility-insights-windows for you to explore and file issues! There's also excellent developer docs to get you up to speed on the organization of the codebase and how each class and project works.
You can download both of these free open source Accessibility Tools at https://accessibilityinsights.io and start testing your websites and apps. I have some work to do!
Sponsor: Seq delivers the diagnostics, dashboarding, and alerting capabilities needed by modern development teams - all on your infrastructure. Download at https://datalust.co/seq.
© 2018 Scott Hanselman. All rights reserved.





0 notes
Text
Coders: Context Switching is hard for both computers and relationships
Clive Thompson is a longtime contributing writer for the New York Times Magazine and a columnist for Wired and now has a new book out called "Coders."
"Along the way, Coders thoughtfully ponders the morality and politics of code, including its implications for civic life and the economy. Programmers shape our everyday behavior: When they make something easy to do, we do more of it. When they make it hard or impossible, we do less of it."
I'm quoted in the book and I talk about how I've struggled with context-switching.
Here is TechTarget's decent definition of Context Switching:
A context switch is a procedure that a computer's CPU (central processing unit) follows to change from one task (or process) to another while ensuring that the tasks do not conflict. Effective context switching is critical if a computer is to provide user-friendly multitasking.
However, human context switching is the procedure we all have to go through to switch from "I am at work" mode to "I am at home" mode. This can be really challenging for everyone, no matter their job or background, but I propose for certain personalities and certain focused jobs like programming it can be even worse.
Quoting Clive from an ArsTechnica article where he mentions my troubles, emphasis mine:
One of the things that really leapt out is the almost aesthetic delight in efficiency and optimization that you find among software developers. They really like taking something that's being done ponderously, or that's repetitive, and optimizing it. Almost all engineering has focused on making things run more efficiently. Saving labor, consolidating steps, making something easier to do, amplifying human abilities. But it also can be almost impossible to turn off. Scott Hanselman talks about coding all day long and coming down to dinner. The rest of the family is cooking dinner and he immediately starts critiquing the inefficient ways they're doing it: "I've moved into code review of dinner."
Ordinarily a good rule of thumb on the internet is "don't read the comments." But we do. Here's a few from that ArsTechnica thread that are somewhat heartening. It sucks to "suffer" but there's a kind of camaraderie in shared suffering.
With reference to "Scott Hanselman talks about coding all day long and coming down to dinner. The rest of the family is cooking dinner and he immediately starts critiquing the inefficient ways they're doing it: "I've moved into code review of dinner.""
Wow, that rings incredibly true.
That's good to hear. I'm not alone!
I am not this person. I have never been this person.
Then again, I'm more of a hack than hacker, so maybe that's why. I'm one of those people who enjoys programming, but I've never been obsessed with elegance or efficiency. Does it work? Awesome, let's move on.
That's amazing that you have this ability. For some it's not just hard to turn off, it's impossible and it can ruin relationships.
When you find yourself making "TODO" and "FIXME" comments out loud, it's time to take a break. Don't ask me how I know this.
It me.
Yep, here too 2x--both my wife and I are always arguing over the most efficient way to drive somewhere. It's actually caused some serious arguments! And neither one of us are programmers or in that field. (Although I think each of us could have been.)
From the day I was conscious I've been into bin packing and shortest path algorithms--putting all the groceries up in the freezer even though we bought too much--bin packing. Going to that grocery store and back in peak traffic--shortest path. I use these so often and find such sheer joy in them that it's ridiculous, but hey, whatever keeps me happy.
This is definitely a thing that isn't programmer-specific. Learning to let go and to accept that your partner in life would be OK without you is an important stuff. My spouse is super competent and I'm sure could reboot the router without me and even drive from Point A to Point B without my nagging. ;)
However we forget these things and we tend to try and "be helpful" and hyper-optimize things that just don't need optimizing. Let it go. Let people just butter their damn bread the way they like. Let them drive a mile out of the way, you'll still get there. We tend to be ruder to our partners than we would be to a stranger.
That’s part of the reason why I’m now making all dinners for my family ;-)
LOL, this is also a common solution. Oh, you got opinions? Here's the spatula!
What do YOU think? How do you context switch and turn work off and try to be present for your family?
Sponsor: Manage GitHub Pull Requests right from the IDE with the latest JetBrains Rider. An integrated performance profiler on Windows comes to the rescue as well.
© 2018 Scott Hanselman. All rights reserved.





0 notes
Text
Agile Software Development Mistakes to Avoid
According to a survey taken of the Scrum Alliance, approximately 70 percent of all groups handling Agile software development believe there are issues present between various internal departments within the company.
The fact is, Agile groups work at a much faster pace. In order to mark progress, they use various markets, and in some cases, this puts staff members in direct conflict with each other.
The disjunction described above among Agile groups, as well as their peers, is a common mistake in the realm of Agile software development. However, there are a number of other reasons that some Agile projects are unsuccessful as well.
You can learn about some of these issues here, and if you have some problems not listed in the article, you can check out DaniWeb software development forum. Knowing what these mistakes are can help you avoid them.
Not Using Customer Input
There is a large number of groups that don’t pay attention to or use the information that is gathered from their customers when creating project designs. It’s smart to use feedback from customers so that you aren’t creating something that’s completely irrelevant.
Improper Training of the Agile Team
According to the Agile Alliance, up to 30 percent of the people who responded to the study mentioned above stated that they were not provided with sufficient training. Some even claimed that they received minimal training on the methodologies used by the company.
Not Being in Sync with Other Departments
Are you in sync with other departments? If you aren’t, you are going to find it virtually impossible to meet the job approximation objectives. This is especially true if the other departments in question are integral to the success of the job or if they are focused on a timeline that isn’t associated with the development group.
Subpar Estimates
Quickness and velocity are essential when it comes to receiving the proper estimates. As a result, you need to be mindful when you are providing your group with practice time. It’s essential to provide accurate estimates before you give any type of compliance promises.
Inadequate Engagement
The majority of members of a group may be working in a remote location from time to time. This makes it much more challenging to have important conversations about important parts of the project that is going on. With that being said, most remote workers are only going to highlight the things that would still be an issue if everyone was working in the same building – inadequate engagement.
The Inability to Conduct the Retrospectives
If you bypass the retrospective step in the Agile software development methodology, you are not providing your bigger group with the opportunity to assess and to enhance their own productivity. This can lead to negative consequences for the entire group.
Minimal Group Effort and Excessive Orders
You should not work with a top-down methodology. Modern Agile leaders are encouraged to work and lead their group members toward a solution, rather than try to make them complete separate jobs on an individual basis.
The Agile Development isn’t Being Supported by the Company Culture
There are far too many companies that have a conflicting culture to the Agile methodology. This is going to result in subpar results for the entire team.
If you want a successful Agile development process, then it is absolutely imperative that you know about the most common mistakes that are made. When you know what these mistakes are, you can take steps to ensure they don’t occur. In the long run, this is going to lead to a much higher rate of success.
The post Agile Software Development Mistakes to Avoid appeared first on The Crazy Programmer.
0 notes
Text
Difference between Primary Key and Foreign Key
A “key” is one of the most basic and important concepts of the Database Management System (DBMS); the keys helps us work easily with the records and the tables in our database by providing us with the ease of accessing and retrieving the data from the table. A primary key is the first key to be understood as it uniquely identifies the particular record of any table. The primary key and foreign key however, must not be confused with each other as they have a completely different definition as well as usage. Here are the differences between the two.
Image Source
Difference between Primary Key and Foreign Key
S.no. Primary key Foreign key 1 The primary key of a particular table is the attribute which uniquely identifies every record and does not contain any null value. The foreign key of a particular table is simply the primary key of some other table which is used as a reference key in the second table. 2 A primary key attribute in a table can never contain a null value. A foreign key attribute may have null values as well. 3 Not more than one primary key is permitted in a table. A table can have one or more than one foreign key for referential purposes. 4 Duplicity is strictly prohibited in the primary key; there cannot be any duplicate values. Duplicity is permitted in the foreign key attribute, hence duplicate values are permitted. 5 Example:
Consider the table student, which keeps record of students in a class:
Here, Id is the primary key which uniquely identifies each record in the table “student”
ID NAME Address 101 ABC x 102 DEF y 103 GHI z 104 JKL w
Now, let us consider the table teacher, which records the teachers in the school:
Here Tid or teacher id is the unique primary key, for each record in the table. This table uses the “ID” attribute which is the primary key of the “student” table as its reference key or foreign key to refer to the student the particular teacher teaches, :
TID NAME TAddress ID 1 Priya P 101 2 Riya R 102 3 Sam S 102 4 Tom T 103
Since one student is taught by more than one teachers, the ID attribute (which is the foreign key in this table), contains duplicate values.
The foreign key of one table although is derived from the primary key of the other table, holds completely different characteristics and these differences are crucial which should be taken care of to avoid any errors.
Comment below if you have queries related to primary key vs foreign key.
The post Difference between Primary Key and Foreign Key appeared first on The Crazy Programmer.
0 notes
Text
The Transitive Property of Friendship - and the importance of the Warm Intro
Per Wikipedia, "In mathematics, a binary relation ... is transitive if ... element a is related to an element b and b is related to an element c then a is also related to c."
Per Me, if I am cool with you, and you are cool with your friend, then I'm cool with your friend. I've decided this is The Transitive Property of Friendship.
As I try to mentor more and more people and help folks Level Up in tech, I'm realizing how important it is to #BeTheLuck for someone else. This is something that YOU can do - volunteer at local schools, forward that resume for your neighbor, give a Warm Intro to a friend of a friend.
A lot of one's success can be traced back to hard work and being prepared for opportunities to present themselves, but also to Warm Intros. Often you'll hear about someone who worked hard in school, studied, did well, but then got a job because "their parent knew a person who worked at x." That's something that is hard to replicate. For under-represented folks trying to break into tech, for example, it's the difference between your resume sitting in a giant queue somewhere vs. sitting on the desk of the hiring manager. Some people inherit a personal network and a resume can jump to the top of a stack with a single phone call, while others send CV after CV with nary a callback.
This is why The Warm Intro is so important. LinkedIn has tried to replicate this by allowing you to "build your professional network" but honestly, you can't tell if I'm cool with someone on LinkedIn just because they're connected to me. Even Facebook "friends" have changed the definition of friend. It certainly has for me. Now I'm mentally creating friend categories like work colleague, lowercase f friend, Uppercase F Friend, etc.
Here's where it gets hard. You can't help everyone. You also have to protect yourself and your own emotional well-being. This is where cultivating a true network of genuine friends and work colleagues comes in. If your First Ring of Friends are reliable, kind, and professional, then it's safer to assume that anyone they bring into your world has a similar mindset. Thus, The Transitive Property of Friendship - also know as "Any friend of Scott's is a friend of mine." The real personal network isn't determined by Facebook or LinkedIn, it's determined by your gut, your experiences, and your good judgment. If you get burned, you'll be less likely to recommend someone in the future.
I've been using this general rule to determine where and when to spend my time while still trying to Lend my Privilege to as many people as possible. It's important also to not be a "transactional networker." Be thoughtful if you're emailing someone cold (me or otherwise). Don't act like an episode of Billions on Showtime. We aren't keeping score, tracking favors, or asking for kickbacks. This isn't about Amazon Referral Money or Finder's Fees. When a new friend comes into your life via another and you feel you can help, give of your network and time freely. Crack the door open for them, and then let them kick it open and hopefully be successful.
All of this starts by you - we - building up warm, genuine professional relationships with a broad group of people. Then using that network not just for yourself, but to lift the voices and careers of those that come after you.
What are YOUR tips and thoughts on building a warm and genuine personal and professional network of folks?
Sponsor: Manage GitHub Pull Requests right from the IDE with the latest JetBrains Rider. An integrated performance profiler on Windows comes to the rescue as well.
© 2018 Scott Hanselman. All rights reserved.





0 notes
Text
Displaying your realtime Blood Glucose from NightScout on an AdaFruit PyPortal
AdaFruit makes an adorable tiny little Circuit Python IoT device called the PyPortal that's just about perfect for the kids - and me. It a little dakBoard, if you will - a tiny totally programmable display with Wi-Fi and lots of possibilities and sensors. Even better, you can just plug it in over USB and edit the code.py file directly on the drive that will appear. When you save code.py the device soft reboots and runs your code.
I've been using Visual Studio Code to program Circuit Python and it's become my most favorite IoT experience so far because it's just so easy. The "Developer's Inner Loop" of code, deploy, debug is so fast.
As you may know, I use a Dexcom CGM (Continuous Glucose Meter) to manage my Type 1 Diabetes. I feed the data every 5 minutes into an instance of the Nightscout Open Source software hosted in Azure. That gives me a REST API to my own body.
I use that REST API to make "glanceable displays" where I - or my family - can see my blood sugar quickly and easily.
I put my blood sugar in places like:
my git prompt
the color of my keyboard keys
Siri and Alexa
DakBoard family wall mounted dashboards
And today, on a tiny PyPortal device. The code is simple, noting that I don't speak Python, so Pull Requests are always appreciated.
import time
import board
from adafruit_pyportal import PyPortal
# Set up where we'll be fetching data from
DATA_SOURCE = "https://NIGHTSCOUTWEBSITE/api/v1/entries.json?count=1"
BG_VALUE = [0, 'sgv']
BG_DIRECTION = [0, 'direction']
RED = 0xFF0000;
ORANGE = 0xFFA500;
YELLOW = 0xFFFF00;
GREEN = 0x00FF00;
def get_bg_color(val):
if val > 200:
return RED
elif val > 150:
return YELLOW
elif val < 60:
return RED
elif val < 80:
return ORANGE
return GREEN
def text_transform_bg(val):
return str(val) + ' mg/dl'
def text_transform_direction(val):
if val == "Flat":
return "→"
if val == "SingleUp":
return "↑"
if val == "DoubleUp":
return "↑↑"
if val == "DoubleDown":
return "↓↓"
if val == "SingleDown":
return "↓"
if val == "FortyFiveDown":
return "→↓"
if val == "FortyFiveUp":
return "→↑"
return val
# the current working directory (where this file is)
cwd = ("/"+__file__).rsplit('/', 1)[0]
pyportal = PyPortal(url=DATA_SOURCE,
json_path=(BG_VALUE, BG_DIRECTION),
status_neopixel=board.NEOPIXEL,
default_bg=0xFFFFFF,
text_font=cwd+"/fonts/Arial-Bold-24-Complete.bdf",
text_position=((90, 120), # VALUE location
(140, 160)), # DIRECTION location
text_color=(0x000000, # sugar text color
0x000000), # direction text color
text_wrap=(35, # characters to wrap for sugar
0), # no wrap for direction
text_maxlen=(180, 30), # max text size for sugar & direction
text_transform=(text_transform_bg,text_transform_direction),
)
# speed up projects with lots of text by preloading the font!
pyportal.preload_font(b'mg/dl012345789');
pyportal.preload_font((0x2191, 0x2192, 0x2193))
#pyportal.preload_font()
while True:
try:
value = pyportal.fetch()
pyportal.set_background(get_bg_color(value[0]))
print("Response is", value)
except RuntimeError as e:
print("Some error occured, retrying! -", e)
time.sleep(180)
I've put the code up at https://github.com/shanselman/NightscoutPyPortal. I want to get (make a custom?) a larger BDF (Bitmap Font) that is about twice the size AND includes 45 degree arrows ↗ and ↘ as the font I have is just 24 point and only includes arrows at 90 degrees. Still, great fun and took just an hour!
NOTE: I used the Chortkeh BDF Font viewer to look at the Bitmap Fonts on Windows. I still need to find a larger 48+ PT Arial.
What information would YOU display on a PyPortal?
Sponsor: Manage GitHub Pull Requests right from the IDE with the latest JetBrains Rider. An integrated performance profiler on Windows comes to the rescue as well.
© 2018 Scott Hanselman. All rights reserved.





0 notes
Text
F7 is the greatest PowerShell hotkey that no one uses any more. We must fix this.
Thousands of years ago your ancestors, and myself, were using DOS (or CMD) pressing F7 to get this amazing little ASCII box to pop up to pick commands they'd typed before.
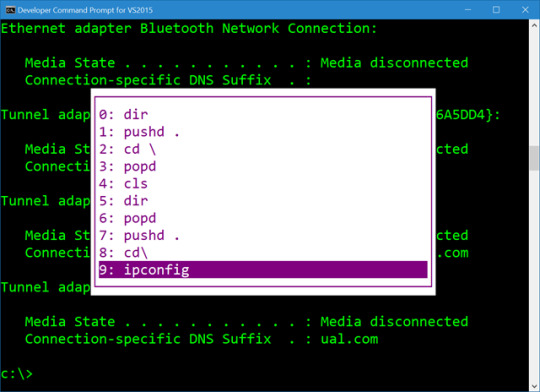
When I find myself in cmd.exe I use F7 a lot. Yes, I also speak *nix and Yes, Ctrl-R is amazing and lovely and you're awesome for knowing it and Yes, it works in PowerShell.
Here's the tragedy. Ctrl-R for a reverse command search works in PowerShell because of a module called PSReadLine. PSReadLine is basically a part of PowerShell now and does dozens of countless little command line editing improvements. It also - not sure why and I'm still learning - unknowingly blocks the glorious F7 hotkey.
If you remove PSReadLine (you can do this safely, it'll just apply to the current session)
Remove-Module -Name PSReadLine
Why, then you get F7 history with a magical ASCII box back in PowerShell. And as we all know, 4k 3D VR be damned, impress me with ASCII if you want a developer's heart.
There is a StackOverflow Answer with a little PowerShell snippet that will popup - wait for it - a graphical list with your command history by calling
Set-PSReadlineKeyHandler -Key F7
And basically rebinding the PSReadlineKeyHandler for F7. PSReadline is brilliant, but I what I really want to do is to tell it to "chill" on F7. I don't want to bind or unbind F7 (it's not bound by default) I just want it passed through.
Until that day, I, and you, can just press Ctrl-R for our reverse history search, or get this sad shadow of an ASCII box by pressing "h." Yes, h is already aliased on your machine to Get-History.
PS C:\Users\scott> h
Id CommandLine
-- -----------
1 dir
2 Remove-Module -Name PSReadLine
Then you can even type "r 1" to "invoke-history" on item 1.
But I will still mourn my lovely ASCII (High ASCII? ANSI? VT100?) history box.
Sponsor: Manage GitHub Pull Requests right from the IDE with the latest JetBrains Rider. An integrated performance profiler on Windows comes to the rescue as well.
© 2018 Scott Hanselman. All rights reserved.





0 notes
Text
Getting Started with .NET Core and Docker and the Microsoft Container Registry
It's super easy to get started with .NET Core and/or ASP.NET Core with Docker. If you have Docker installed you don't need to install anything to try out .NET Core, of course.
To run a little .NET Core console app:
docker run --rm mcr.microsoft.com/dotnet/core/samples:dotnetapp
And the result:
latest: Pulling from dotnet/core/samples
Hello from .NET Core!
...SNIP...
**Environment**
Platform: .NET Core
OS: Linux 4.9.125-linuxkit #1 SMP Fri Sep 7 08:20:28 UTC 2018
To run a quick little ASP.NET Core website just:
docker run -it --rm -p 8000:80 --name aspnetcore_sample mcr.microsoft.com/dotnet/core/samples:aspnetapp
And here it is running on localhost:8000
You can also host ASP.NET Core Images with Docker over HTTPS to with this image, or run ASP.NET Core apps in Windows Containers.
Note that Microsoft teams are now publishing container images to the MCR (Microsoft Container Registry) so they can use the Azure CDN and pull faster when they are closer to you globally. The images start at MCR and then can be syndicated to other container registries.
The new repos follow:
.NET Core Runtime dependencies (just the stuff .NET Core needs, but not .NET Core itself - useful if you want to distribute your own copy and still want a small container image size)
.NET Core Runtime (Just what's needed to run a .NET Core app)
.NET Core SDK (includes the compilers, everything)
ASP.NET Core runtime (everything you need to RUN your ASP.NET Core web app)
When you "docker pull" you can use tag strings for .NET Core and it works across any supported .NET Core version
SDK: docker pull mcr.microsoft.com/dotnet/core/sdk:2.1
ASP.NET Core Runtime: docker pull mcr.microsoft.com/dotnet/core/aspnet:2.1
.NET Core Runtime: docker pull mcr.microsoft.com/dotnet/core/runtime:2.1
.NET Core Runtime Dependencies: docker pull mcr.microsoft.com/dotnet/core/runtime-deps:2.1
For example, I can run the .NET Core 3.0 SDK and mess around with it like this:
docker run -it mcr.microsoft.com/dotnet/core/sdk:3.0
I've been using Docker to run my unit tests on my podcast site within a container locally. Then I volume mount and dump the test results out in a local folder and inspect them with Visual Studio
docker build --pull --target testrunner -t podcast:test .
docker run --rm -v c:\github\hanselminutes-core\TestResults:/app/hanselminutes.core.tests/TestResults podcast:test
I can then either host the Docker container in Azure App Service for Containers, or as little one-off per-second billed instances with Azure Container Instances (ACI).
Have you been using .NET Core in Docker? How has it been going for you?
Sponsor: Manage GitHub Pull Requests right from the IDE with the latest JetBrains Rider. An integrated performance profiler on Windows comes to the rescue as well.
© 2018 Scott Hanselman. All rights reserved.





0 notes
Text
What is Blazor and what is Razor Components?
I've blogged a little about Blazor, showing examples like Compiling C# to WASM with Mono and Blazor then Debugging .NET Source with Remote Debugging in Chrome DevTools as well as very early on asking questions like .NET and WebAssembly - Is this the future of the front-end?
Let's back up and level-set.
What is Blazor?
Blazor is a single-page app framework for building interactive client-side Web apps with .NET. Blazor uses open web standards without plugins or code transpilation. Blazor works in all modern web browsers, including mobile browsers.
You write C# in case of JavaScript, and you can use most of the .NET ecosystem of open source libraries. For the most part, if it's .NET Standard, it'll run in the browser. (Of course if you called a Windows API or a Linux specific API and it didn't exist in the client-side browser S world, it's not gonna work, but you get the idea).
The .NET code runs inside the context of WebAssembly. You're running "a .NET" inside your browser on the client-side with no plugins, no Silverlight, Java, Flash, just open web standards.
WebAssembly is a compact bytecode format optimized for fast download and maximum execution speed.
Here's a great diagram from the Blazor docs.
Here's where it could get a little confusing. Blazor is the client-side hosting model for Razor Components. I can write Razor Components. I can host them on the server or host them on the client with Blazor.
You may have written Razor in the past in .cshtml files, or more recently in .razor files. You can create and share components using Razor - which is a mix of standard C# and standard HTML, and you can host these Razor Components on either the client or the server.
In this diagram from the docs you can see that the Razor Components are running on the Server and SignalR (over Web Sockets, etc) is remoting them and updating the DOM on the client. This doesn't require Web Assembly on the client, the .NET code runs in the .NET Core CLR (Common Language Runtime) and has full compatibility - you can do anything you'd like as you are not longer limited by the browser's sandbox.
Per the docs:
Razor Components decouples component rendering logic from how UI updates are applied. ASP.NET Core Razor Components in .NET Core 3.0 adds support for hosting Razor Components on the server in an ASP.NET Core app. UI updates are handled over a SignalR connection.
Here's the canonical "click a button update some HTML" example.
@page "/counter"
<h1>Counter</h1>
<p>Current count: @currentCount</p>
<button class="btn btn-primary" onclick="@IncrementCount">Click me</button>
@functions {
int currentCount = 0;
void IncrementCount()
{
currentCount++;
}
}
You can see this running entirely in the browser, with the C# .NET code running on the client side. .NET DLLs (assemblies) are downloaded and executed by the CLR that's been compiled into WASM and running entirely in the context of the browser.
Note also that I'm stopped at a BREAKPOINT in C# code, except the code is running in the browser and mapped back into JS/WASM world.
But if I host my app on the server as hosted Razor Components, the C# code runs entirely on the Server-side and the client-side DOM is updated over a SignalR link. Here I've clicked the button on the client side and hit the breakpoint on the server-side in Visual Studio. No there's no POST and no POST-back. This isn't WebForms - It's Razor Components. It's a SPA app written in C#, not JavaScript, and I can change the locations of the running logic, while the UI remains always standard HTML and CSS.
Looking at how Razor Components and now Phoenix LiveView are offering a new way to manage JavaScript-free stateful server-rendered apps has me realizing it’s the best parts of WebForms where the postback is now a persistent websockets tunnel to the backend and only diffs are sent
— Scott Hanselman (@shanselman) March 16, 2019
It's a pretty exciting time on the open web. There's a lot of great work happening in this space and I'm very interesting to see how frameworks like Razor Components/Blazor and Phoenix LiveView change (or don't) how we write apps for the web.
Sponsor: Manage GitHub Pull Requests right from the IDE with the latest JetBrains Rider. An integrated performance profiler on Windows comes to the rescue as well.
© 2018 Scott Hanselman. All rights reserved.





0 notes
Text
Python Web Scraping Tutorial
In this tutorial, we are going to talk about web scraping using python.
Firstly, we have to discuss about what is web scraping technique? Whenever we need the data (it can be text, images, links and videos) from web to our database. Lets discuss where we should need the web scraping in real world.
Nowadays, we have so many competitors in each and every field for surpassing them we need their data from the website or Blogs to know about products, customers and their facilities.
And Some Admin of Particular website, blogs and youtube channel want the reviews of their customers in database and want to update with this In, this condition they use web scraping
There are many other areas where we need web scraping, we discussed two points for precise this article for readers.
Prerequisites:
You just have basic knowledge of python nothing else so, get ready for learning web scraping.
Which technology we should use to achieve web scraping?
We can do this with JavaScript and python but according to me and most of the peoples, we can do it with python easily just you should know the basic knowledge of python nothing else rest of the things we will learn in this article.
Python Web Scraping Tutorial
1. Retrieving Links and Text from Website and Youtube Channel through Web Scraping
In this first point, we will learn how to get the text and the links of any webpage with some methods and classes.
We are going to do this beautiful soup method.
1. Install BS4 and Install lxml parser
To install BS4 in windows open your command prompt or windows shell and type: pip install bs4
To install lxml in windows open your command prompt or windows shell and type: pip install lxml
Note: “pip is not recognized” if this error occurs, take help from any reference.
To install BS4 in ubuntu open your terminal:
If you are using python version 2 type: pip install bs4
If you are using python version 3 type: pip3 install bs4
To install lxml in ubuntu open your terminal
If you are using python version 2 type: pip install lxml
If you are using python version 3 type: pip3 install lxml
2. Open Pycharm and Import Modules
Import useful modules:
import bs4
import requests
Then take url of particular website for example www.thecrazyprogrammer.com
url= "https://www.thecrazyprogrammer.com/" data=requests.get(url) soup=bs4.BeautifulSoup(data.text,'htm.parser') print(soup.prettify())
And now you will get the html script with the help of these lines of code of particular link you provided to the program. This is the same data which is in the page source of the website webpage you can check it also.
Now we talk about find function() with the help of find function we can get the text, links and many more things from our webpage. We can achieve this thing through the python code which is written below of this line:
We just take one loop in our program and comment the previous line.
for para in soup.find('p') print(para)
And we will get the first para of our webpage, you can see the output in the below image. See, this is the original website view and see the output of python code in the below image.
Pycharm Output
Now, if you want all the paragraph of this webpage you just need to do some changes in this code i.e.
Here, we should use find_all function() instead find function. Let’s do it practically
You will get all paragraphs of web page.
Now, one problem will occur that is the “<p>” tag will print with the text data for removing the <p> tag we have to again do changes in the code like this:
We just add “.text” in the print function with para. This will give us only text without any tags. Now see the output there <p> tag has removed with this code.
With the last line we have completed our first point i.e. how we can get the data (text) and the html script of our webpage. In the second point we will learn how we get the hyperlinks from webpage.
2. How to Get All the Links Of Webpage Through Web Scraping
Introduction:
In this, we will learn how we can get the links of the webpage and the youtube channels also or any other web page you want.
All the import modules will be same some changes are there only that changes are:
Take one for loop with the condition of anchor tag ‘a’ and get all the links using href tag and assign them to the object (you can see in the below image) which taken under the for loop and then print the object. Now, you will get all the links of webpage. Practical work:
You will get all the links with the extra stuff (like “../” and “#” in the starting of the link)
There is only some valid links in this console screen rest of them are also link but because of some extra stuff are not treating like links for removing this bug we have to do change in our python code.
We need if and else condition and we will do slicing using python also, “../” if we replace it with our url (you can see the url above images) i.e. https://www.thecrazyprogrammer.com/, we will get the valid links of the page in output console let see practically in below image.
In the above image we take the if condition where the link or you can say that the string start with the “../” start with 3 position of the string using slice method and the extra stuff like “#” which is unuseful for us that’s why we don’t include it in our output and we used the len() function also for printing the string to the last and with the prefix of our webpage url are also adding for producing the link.
In your case you can use your own condition according to your output.
Now you can see we get more than one link using if condition. We get so many links but there is also one problem that is we are not getting the links which are starting with “/” for getting these links also we have to do more changes in our code lets see what should we do.
So, we have to add the condition elif also with the condition of “/” and here also we should give “#” condition also otherwise we will get extra stuff again in below image we have done this.
After putting this if and elif condition in our program to finding all the links in our particular webpage We have got the links without any error you can see in below image how we increased our links numbers since the program without the if and elif condition.
In this way we can get all the links the text of our particular page or website you can find the links in same manner of youtube channel also.
Note: If you have any problem to getting the links change the conditions in program as I have done with my problem you can use as your requirement.
So we have done how we can get the links of any webpage or youtube channel page.
3. Log In Facebook Through Web Scraping
Introduction
In this method we can login any account of facebook using Scraping.
Conditions: How we can use this scarping into facebook because the security of Facebook we are unable to do it directly.
So, we can’t login facebook directly we should do change in url of facebook like we should use m.facebook.com or mbasic.facebook.com url instead of www.facebook.com because facebook has high security level we can’t scrap data directly.
Let’s start scrapping.
This Is Webpage Of m.facebook.com URL
Let’s start with python. So first import all these modules:
import http.cookiejar
import urllib.request
import requests
import bs4
Then create one object and use cookiejar method which provides you the cookie into your python browser.
Create another object known as opener and assign the request method to it.
Note: do all the things on your risk don’t hack someone id or else.
Cj=http.cookiejar.Cookiejar() Opener=urllib.request.build_opener(urllib.request.HTTPcookieProcessor) Urllib.request.install_opener(opener) Authentication_url=""
After this code, you have to find the link of particular login id through inspecting the page of m.facebook.com and then put the link into under commas and remove all the text after the login word and add “.php” with login word now type further code.
payload= { 'email':"[email protected]", 'pass':"(enter the password of id)" }
After this use get function give one cookie to it.
Data=urllib.parse.urlencode(payload).encode('utf-8') Req=urllib.request.Request(authentication_url,data) Resp=urllib.request.urlopen(req) Contents=resp.read() Print(contents)
With this code we will login into facebook and the important thing I have written above also do it all things on your risk and don’t hack someone.
We can’t learn full concept of web scraping through this article only but still I hope you learned the basics of python web scrapping.
The post Python Web Scraping Tutorial appeared first on The Crazy Programmer.
0 notes
Text
Tips for Secure Programming and Coding
While security has always been a concern for individuals and companies online, today this is more true now than ever. Hacks and data breaches are skyrocketing and hundreds of millions of people are being compromised every year. While this happens to big businesses, it can also happen to small entities or even individuals as well.
As a result, it is more important to ensure the code you or your company is writing remains secure. While it is impossible to avoid every potential attack, hack or data breach, you can try your best to prepare. While things such as testing frequently and using passwords can help, they are far from the only ways to secure your code. With that in mind, this article is going to look at a few tips for secure programming and coding.
Utilize Log Management
Whether you have programmed an app or a piece of software, it is important to monitor it going forward after the initial coding is done. Without any sort of monitoring, you may not be any the wiser if someone hacks you. As a result, using a service or tool like log management and monitoring is important. Logs are a time-stamped documentation of events that are related to a particular system.
Log management allows you to analyze and store these logs and show you trends or events in the system. So if something unexpected occurs within your code or piece of software, you will be able to figure out where that occurred and what happened. As you could imagine, this is very helpful when it comes to both security and compliance.
There are many different log management platforms, tools, and services out there, so be sure to do some research to find the right one. Sites like DNSstuff offer reviews of different tools, so you can decide which is the right one for your needs.
Restrict Access
While being liberal with handing out access can help ensure no roadblocks are encountered in the future, security is more important. Unfortunately, the more people that have access to your code, the higher the chance that something becomes compromised. This is because most data breaches are actually a result of human error, so be careful with how much access you provide to employees.
Only those who are actively working on the code should have access to it. Give people the smallest amount of access they need to do the job. There are a number of different ways you can control or restrict access. This gives data owners and businesses a lot of flexibility for choosing who they want to provide access to.
Consider Adding Delays to Code
While many people think of a hack or data breach involving a single individual trying to “crack the code,” this isn’t often the case. Oftentimes, these criminals will rely on powerful computers to relentlessly try and access your code, systems or files. They can do this either by continuously posing as a user trying to access or by trying billions of different password combinations.
One thing you can do to combat these efforts is to add some delays to your code. This delay will help slow these bots down to a half, without affecting the experience of actual humans. There are different ways you can do this, such as adding slight delay with each incorrect log-in attempt.
Hopefully, this article has been able to help you learn how to program and code in a more secure manner. Protecting your code and making sure it works and is secure is paramount to being successful in the space.
The post Tips for Secure Programming and Coding appeared first on The Crazy Programmer.
0 notes