
Last Seen Blogs

livinedart
Livinedart

avranches-infos
avranches infos

eciipsed
Connor is my bae

dedtek
The City is Full of Empty People

felipemagic-blog
Untitled
Text
구글앱엔진 Async Requests
텔레그램봇을 제작하는 와중에 봇에 등록된 사람들 모두에게 메시지를 전달할 방법이 필요하게 되었다. 파이썬 urllib2 를 사용하면
try: urllib2.urlopen(RQ_BASE_URL + '/sendMessage', urllib.urlencode(params)).read() except Exception as e: pass
이렇게 URL을 요청하면 응답을 받을떄까지 대기하고 있기 때문에 시간이 오래 걸리게 된다. 따라서 비동기적으로 요청하는 방식을 찾다보니 다음과 같은 문서를 찾았다. https://cloud.google.com/appengine/docs/python/urlfetch/asynchronousrequests
저 문서를 활용하여 사용한 코드이다.
for chat_id in chat_id_list: # define params ... payload = urllib.urlencode(params) rpc = urlfetch.create_rpc() rpc.callback = create_callback(rpc) urlfetch.make_fetch_call(rpc, RQ_BASE_URL+'/sendMessage', payload, urlfetch.POST) rpcs.append(rpc) for rpc in rpcs: rpc.wait()
결국 콜백을 등록하고 비동기작업이 끝날시 콜백이 호출되도록 한다.
0 notes
Text
Telegram bot api
텔레그램 메신저에 최근 Telegram Bot API 가 생겼다. 이를 사용하여 봇을 만들수 있다. 이 Telegram Bot API는 그냥 API와는 다르다. 진짜 봇을 다루기 위한 API를 제공한다. 간단하게 HTTP request로 여러가지 동작들을 요청할수 있으며 setWebHook 으로 URL을 보내어 텔레그램쪽에서 발생하는 동작들을 JSON 형태로 수신 가능하다. 즉 웹서버를 만든다음에 URL를 알려줘서 텔레그램에서 웹서버로 요청하도록 하는 것이다.
위 링크를 열어보면 문서화가 잘 되어있어서, 구글링을 통해 몇개의 예제를 보면 사용법에 대해서 감을 잡을수 있을 것이다. 특히 구글 앱 엔진 (Google App Engine)에 적용하기 매우 쉽다.
개인적으로 위와 같은 용도의 봇을 만들어보았다. 주기적으로 공시를 가져와 텔레그램에 뿌려준다. 공시는 RSS 주소를 사용하였다. 좀더 원하는데로 제어하려면 DART에서도 API를 제공하니 이걸 쓰면 될것이다.
0 notes
Text
HTML5 canvas 활용 mandelbrot set 구현하기
mandelbrot set은 간단한 구현으로 상당히 화려한 효과를 볼수 있는 것중 하나이다. 픽셀단위로 접근하여 계산집약적인 그래픽 프로그램이라 구현하고 난 뒤의 성취감도 괜찮다.

위는 HTML5의 canvas로 구현을 하여 캡쳐한 것이다. 위의 결과물을 얻기까지 상당한 시행착오가 있었는데 그 과정을 포스팅 하고자 한다.
아래 링크는 직접 구현한 것들이다. HTML canvas 가 잘 동작되는 브라우져 (크롬, 사파리) 등으로 동작시키면 되며, 마우스 왼쪽(줌인) , 마우스 오른쪽(줌아웃) 기억하고 동작시키면 된다.
http://ippoeyeslhw.github.io/works/mandelbrot_fractal.html (일반 버젼)
http://ippoeyeslhw.github.io/works/mandelbrot_worker.html (Web Worker 버젼)
http://ippoeyeslhw.github.io/works/mandelbrot_gl.html (WebGL 버젼)
“
망델브로 집합은 다음 점화식으로 정의된 수열이 발산하지 않는 성질을 갖도록 하는 복소수 c의 집합으로 정의된다.
“
위키를 뒤져보면 위와 같은 정의를 알수 있다. 하지만 저 정의만 보고서는 위의 그림이 어떻게 그려지는지 처음보면 감이 오지 않을 것이다.
(x0,y0)=(0,0)
xn+1 = xn2 - yn2 + a
yn+1 = 2 xn yn + b (단, xn,yn,a,b는 실수.)
라는데 즉 a값은 픽셀의 x좌표이고 b값은 픽셀의 y좌표라고 생각하면 된다. 실제로 픽셀의 좌표는 좌측상단 (0, 0) 부터 canvas의 크기인 (900, 600) 가로 900 세로 600으로 지정했을때 그 사이의 값이 될 것이다. 하지만 mandelbrot 집합의 좌표계는 아래와 같다.

즉 (-2, -1) (1, -1) (-2, 1) (1, 1) 점 사이의 값으로 집합이 정의된다. 따라서 각 픽셀의 좌표는 (0, 0) 부터 (900, 600) 사이의 값을 좌표변환 시켜서 mandelbrot 집합의 좌표계 크기로 변환시킨 실수 값으로 구하면 된다. 조심해야 할점은 canvas는 좌측상단에 0,0 으로 가장작은 지점이지만 아래 mandelbrot set은 좌측 하단이 가장 작은 지점이다. 따라서 둘사이의 좌표변환시 x축 대칭이동 시켜주어야 될 것이다.
위에 나왔던 점화식을 언제까지고 반복시킬수는 없다. 컴퓨팅의 한계로 인해서 적당한 limit 값을 주어야 한다. 반복된 횟수가 바로 color 이다. 적당히 256번 반복시켜서 그 값에 따라 명도를 주어도 되며 HSV Color space 로 변환하여 색깔을 부여해도 괜찮다. 하지만 원하는 색깔의 범위로 프랙탈을 생성하기 위해 Pallette 를 만들고 인덱스를 참조하여 색깔을 부여하도록 하는 것이 가장 예쁜것 같다.
그러면 일단 명도를 주는 방식으로 구현을 해보도록 한다.
var ctx = canvasElem.getContext('2d'); var width = canvasElem.width; var height = canvasElem.height; // 코드생략 function gen_practal(sx, sy, sw, sh){ // 캔버스이미지 및 픽셀배열 얻기 canvas_img = ctx.getImageData(0,0,width,height); canvas_pixels = canvas_img.data; for(var oy = 0; oy < height; oy++){ for(var ox = 0; ox < width; ox++){ // 좌표계 기준 var cx = sx + ox * (sw / width); var cy = sy + oy * (sh / height); var x = cx; var y = cy; var cnt ; // 256 단계를 계산하여 발산여부 확인 for(cnt =0; cnt < max_iter; cnt++){ var x2 = x * x; var y2 = y * y; if( x2 + y2 > 4){ break; } var nx = x2 - y2 + cx; var ny = 2*x*y + cy; x = nx; y = ny; } cnt = cnt % 256; // draw pixel var idx = 4 * (oy * width + ox); canvas_pixels[idx + 0] = cnt; canvas_pixels[idx + 1] = cnt; canvas_pixels[idx + 2] = cnt; canvas_pixels[idx + 3] = 255; } } // put practal image ctx.putImageData(canvas_img, 0, 0); }

위처럼 얻게 된다. 코드에서 cx, cy를 보면 각 픽셀위치를 변환하는것을 알수 있다. 그리고 몇번 반복에 발산하는지 확인하고 제한값이내에 발산하지 않으면 이는 만델브로트집합으로 보고 검정색(안쪽)으로 그리게 한다. 하지만 이것은 별로 그림이 예쁘지 않으므로 Coloring 에 좀더 신경을 써야하겠다. 위에서 말한대로 Pallette를 미리 만들고 반복횟수를 인덱스 삼아 컬러값을 가져오는 방식이다. 이 방식은 Mandelbrot 위키피디아에 보면 나와있다.

위 방식은 팔레트를 사용하는것과 동시에 fractal 색의 계단현상을 없애주기 위해서 interpolate 하는 과정도 들어있다.


interpolate 적용된것과의 차이점 계단현상이 없어진다.그럼 실제로 구현을 해보도록 한다.
// 그라디언트 생성 var canvas_grd = document.createElement('canvas'); canvas_grd.width = 256; canvas_grd.height= 1; var ctx_grd = canvas_grd.getContext('2d'); var grd = ctx_grd.createLinearGradient(0,0,canvas_grd.width,canvas_grd.height); grd.addColorStop(0 , 'rgb(0 ,0 ,128)'); grd.addColorStop(0.45, 'rgb(255,255,255)'); grd.addColorStop(0.85, 'rgb(255,128,0 )'); grd.addColorStop(0.9 , 'rgb(0 ,0 ,0 )'); grd.addColorStop(1 , 'rgb(0 ,0 ,128)'); ctx_grd.fillStyle = grd; ctx_grd.fillRect(0,0,canvas_grd.width,canvas_grd.height); grd_image = ctx_grd.getImageData(0,0,canvas_grd.width,canvas_grd.height); grd_data = grd_image.data; // 코드생략 // // 픽셀에 컬러 지정하는 부분 var r,g,b; if(cnt >= max_iter){ r = g = b = 0; }else{ // smooth coloring var zn = Math.sqrt(x2 + y2); var nu = Math.log(Math.log(zn) / Math.log(2.0)) / Math.log(2.0); cnt = cnt + 1.0 - nu; var grd_idx = Math.floor(cnt) % 256; r = grd_data[4 * grd_idx + 0]; g = grd_data[4 * grd_idx + 1]; b = grd_data[4 * grd_idx + 2]; grd_idx = (grd_idx+1) % 256; r1 = grd_data[4 * grd_idx + 0]; g1 = grd_data[4 * grd_idx + 1]; b1 = grd_data[4 * grd_idx + 2]; // linear interpolation var t = cnt % 1; r = (1-t)*r + t*r1; g = (1-t)*g + t*g1; b = (1-t)*b + t*b1; } var idx = 4 * (oy * width + ox); canvas_pixels[idx + 0] = r ; canvas_pixels[idx + 1] = g ; canvas_pixels[idx + 2] = b ; canvas_pixels[idx + 3] = 255;
위와 같이 된다. 보이지 않는 가상의 canvas 엘리먼트를 만들고 그라디언트 api를 이용하여 팔레트를 생성한뒤 이를 픽셀을 그릴때 사용하여 그리게 된다. 이때 interplote 까지 같이 진행하여 smooth한 그림이 나오도록 한다.
위와 같이 그림을 찍고 거기에 마우스를 클릭하면 확대가 되는 효과를 위해 좌표값들을 스택에 저장하였다가 꺼내는 방식으로 동작하도록 만들것이다. 아래와 같은 간단한 코드를 넣는다.
// 줌 사각형 크기 var zoom_width = width / 5; var zoom_height= height / 5; // 줌 히스토리 Stack var zoom_history = [{x:-2.0, y:-1.0, w:3.0, h:2.0}]; // 코드생략 // 마우스 이벤트 콜백 function mouse_move(e){ var offsetX = e.offsetX || e.pageX - canvasElem.parentNode.offsetLeft; var offsetY = e.offsetY || e.pageY - canvasElem.parentNode.offsetTop; var zoom_x = offsetX - zoom_width / 2; var zoom_y = offsetY - zoom_height / 2; ctx.putImageData(canvas_img, 0, 0); ctx.strokeStyle = "rgb(0,255,0)"; ctx.strokeRect(zoom_x, zoom_y, zoom_width, zoom_height); } function mouse_up(e){ var offsetX = e.offsetX || e.pageX - canvasElem.parentNode.offsetLeft; var offsetY = e.offsetY || e.pageY - canvasElem.parentNode.offsetTop; var zoom_x = offsetX - zoom_width / 2; var zoom_y = offsetY - zoom_height / 2; if(e.which == 1){ // left click var prev = zoom_history[zoom_history.length - 1]; var curr_w = prev.w * (1.0 * zoom_width / width ); var curr_h = prev.h * (1.0 * zoom_height / height); var curr_x = prev.x + (1.0 * zoom_x / width ) * prev.w; var curr_y = prev.y + (1.0 * zoom_y / height ) * prev.h; zoom_history.push({ x: curr_x, y: curr_y, w: curr_w, h: curr_h }); render(); }else if(e.which == 3){ // right click if(zoom_history.length > 1){ zoom_history.pop(); render(); } } } // 초기화 this.start = function (){ render(); canvasElem.addEventListener('mousemove', mouse_move, false); canvasElem.addEventListener('mouseup' , mouse_up , false); canvasElem.addEventListener('contextmenu', function(e){ e.preventDefault(); }, false); //canvasElem.addEventListener('dblclick' , mouse_dbl , false); } function render(){ var zoom = zoom_history[zoom_history.length - 1]; gen_practal(zoom.x, zoom.y, zoom.w, zoom.h); }
확대할 지점의 좌표값들이 스택에 넣어지고 꺼내지면서 확대 및 축소 기능을 추가할수 있게 된다.
위의 모든 기능이 구현된 버젼으로 아래 링크로 가서 확인할수 있다.
http://ippoeyeslhw.github.io/works/mandelbrot_fractal.html (일반 버젼)

위 예제는 순수한 자바스크립트로만 수행되며 싱글스레드로만 수행되어 반복값을 조금 증가시키거나 해상도가 증가하면 계산량이 많이 늘어나 굉장히 버겁게 된다. 따라서 웹워커를 이용하여 분산하여 처리해보도록 하겠다.
위는 웹 워커로 처리되고 있는 도중 빠르게 캡쳐한 장면이다. 즉 캔버스를 16조각으로 분할한뒤 여러개(4개)의 워커가 각 블록을 처리하며 블록을 다 처리했을시 바로 아직 처리하지 않은 블록을 맡아서 처리하도록 간단한 밸런싱을 할 것이다. 일단 워커스크립트를 하나의 블록을 그리도록 한다. 그동안 만들었던 스크립트를 조금 변형하여 만들었다.
self.onmessage = function(e){ var info = e.data; // 입력값들 // 이미지데이터 // img // // 블록처리 (canvas의 좌표) // bx, by, bw, bh // // 수학적 실제좌표 // sx, sy, sw, sh // // 캔버스 크기 // w, h // // 최대발산확인값 // max_iter // // 그라디언트배열 (크기는 256으로 ) // grd_arr // 블록별로 나눠서 처리한다. for(var oy = 0; oy < info.bh; oy++){ for(var ox = 0; ox < info.bw; ox++){ // 좌표계 기준 var cx = info.sx + (ox + info.bx) * (info.sw / info.w); var cy = info.sy + (oy + info.by) * (info.sh / info.h); var x = cx; var y = cy; var cnt ; // 256 단계를 계산하여 발산여부 확인 for(cnt =0; cnt < info.max_iter; cnt++){ var x2 = x * x; var y2 = y * y; if( x2 + y2 > 4){ break; } var nx = x2 - y2 + cx; var ny = 2*x*y + cy; x = nx; y = ny; } // 픽셀 drawing var r,g,b; var r1,g1,b1; if(cnt >= info.max_iter){ r = g = b = 0; }else{ // smooth coloring var zn = Math.sqrt(x2 + y2); var nu = Math.log(Math.log(zn) / Math.log(2.0)) / Math.log(2.0); cnt = cnt + 1.0 - nu; var grd_idx = Math.floor(cnt) % 256; r = info.grd_arr[4 * grd_idx + 0]; g = info.grd_arr[4 * grd_idx + 1]; b = info.grd_arr[4 * grd_idx + 2]; grd_idx = (grd_idx+1) % 256; r1 = info.grd_arr[4 * grd_idx + 0]; g1 = info.grd_arr[4 * grd_idx + 1]; b1 = info.grd_arr[4 * grd_idx + 2]; // linear interpolation var t = cnt % 1; r = (1-t)*r + t*r1; g = (1-t)*g + t*g1; b = (1-t)*b + t*b1; } var idx = 4 * (oy * info.bw + ox); info.img.data[idx + 0] = r; info.img.data[idx + 1] = g; info.img.data[idx + 2] = b; info.img.data[idx + 3] = 255; } } self.postMessage(info); };
워커스크립트는 onmessage 로 이벤트를 받을시 해당 스크립트를 실행하게 된다. 그리고 postMessage 로 메인스크립트와 통신한다. 자신이 계산을 끝냈으면 그렸던 블록을 메인스크립트로 전달하고 메인스크립트는 블록들을 모아서 전체 그림을 완성하는 방식이다.
// worker 지정 var num_of_worker = 4; var workers = new Array(num_of_worker); for(var i=0; i < num_of_worker; i++){ (function(i){ workers[i] = new Worker('js/mandelbrot_work.js'); workers[i].onmessage = function(e){ var info = e.data; ctx.putImageData(info.img, info.bx, info.by); // 즉각 밸런싱 balancing(i, info.sx, info.sy, info.sw, info.sh); // 작업 카운터 증가 done_cnt++; if(done_cnt >= num_of_job * num_of_job){ // 모든 작업이 끝난경우 // 캔버스이미지 및 픽셀배열 얻기 canvas_img = ctx.getImageData(0,0,width,height); canvas_pixels = canvas_img.data; } }; })(i); } // Job을 분할하여 각 워커가 분담하여 처리한다. // 실제 작업량은 num_of_job * num_of_job 개수만큼이다. // canvas 좌표로 블록을 나누어 x,y,w,h 를 지정하여 워커로 넘긴다. var num_of_job = 4; var job_cnt = 0; var done_cnt = 0; function balancing(i, sx, sy, sw, sh){ if(num_of_job * num_of_job > job_cnt){ var bx = (job_cnt % num_of_job) * (width / num_of_job); var by = parseInt(job_cnt / num_of_job) * (height / num_of_job); var bw = (width / num_of_job); var bh = (height / num_of_job); var info = { img : ctx.getImageData(bx,by,bw,bh), bx: bx, by: by, bw: bw, bh: bh, sx: sx, sy: sy, sw: sw, sh: sh, w: width, h: height, max_iter: max_iter, grd_arr: grd_data }; workers[i].postMessage(info); job_cnt++; } } function render(){ // 잡, 작업카운터 clear job_cnt = 0; done_cnt = 0; // zoom history 가져옴 Stack처럼 사용한다. var zoom = zoom_history[zoom_history.length - 1]; // 밸런싱 시작 for(var i=0; i < num_of_worker; i++){ balancing(i,zoom.x, zoom.y, zoom.w, zoom.h); } }
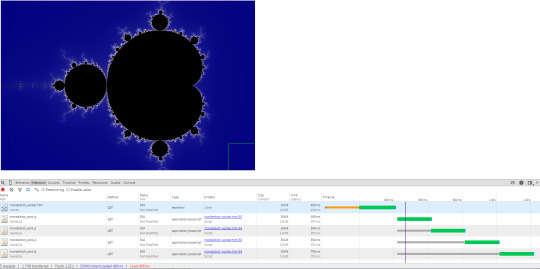
실제로 워커들이 떠서 동작하는지 개발자도구를 띄워서 확인해보면 아래처럼 순차적으로 실행됨을 알수있다.
작업을 분담했다고는 하지만 이게 순차적으로 실행되어 딱히 빠르진 않은 상황이다..
워커의 모든 기능이 구현된 버젼으로 아래 링크에 가서 확인 할 수 있다.
http://ippoeyeslhw.github.io/works/mandelbrot_worker.html (Web Worker 버젼)
드디어 WebGL을 사용할 때가 왔다. mandelbrot set을 구하는 것은 픽셀단위 연산이기도 하며 각 픽셀에 대하여 독립적으로 계산이 수행되므로 Shader를 사용하기 적합하다.
하지만 WebGL을 사용하기는 조금 복잡하다. 경험이 없으면 API사용이 굉장히 복잡해 보일것이다. 일단 셰이더까지 연결이 잘되면 그떄부터는 셰이더 코드를 간단하게 고쳐가며 사용하면 되지만 연결하기가 조금 복잡한 편이다.
gl 객체를 얻는다 (’2d’ 의 context와 비슷한 개념)
셰이더코드를 문자열로 얻어와서 컴파일시키고 프로그램에 연결, 링킹한다.
장면을 그릴 면을 만들기 위해 정점들을 attribute 값으로 넘겨줄 준비를 한다.
셰이더에서 사용한 attrib 변수의 위치를 얻어낸다.
gl 버퍼를 생성하고 바인딩한다.
bufferData로 버퍼에 데이터를 넣는다.
vertexAttribPointer를 이용 변수위치 정보및 각종 정보 세팅한다.
drawArray 로 장면을 그린다.
위는 attrib 변수에 대한 것이다. 이는 정점셰이더까지 유효하다. 모든 셰이더에 적용되는 값을 전달하려면 uniform 을 활용하면 된다. uniform 에 대한 API는 또 따로 있다...
// webgl var gl = initGL(canvasElem); // gl생성루틴 var program = initShaders(gl); // 셰이더컴파일링킹 // attributes location설정 var vertPos = gl.getAttribLocation(program, 'vertPos'); gl.enableVertexAttribArray(vertPos); var plotPos = gl.getAttribLocation(program, 'plotPos'); gl.enableVertexAttribArray(plotPos); var vertPosBuf = gl.createBuffer(); gl.bindBuffer(gl.ARRAY_BUFFER, vertPosBuf); var vertices = [ -1.0, -1.0, -1.0, 1.0, 1.0, -1.0, 1.0, 1.0, ]; gl.bufferData(gl.ARRAY_BUFFER, new Float32Array(vertices), gl.STATIC_DRAW); // {x:-2.0, y:-1.0, w:3.0, h:2.0} var plot_vertices = [ -2.0, -1.0, -2.0, 1.0, 1.0, -1.0, 1.0, 1.0 ]; function drawScene(){ // calc plot from zoom history var zoom = zoom_history[zoom_history.length-1]; plot_vertices = zoom; // webgl render gl.viewport(0,0,gl.viewportWidth, gl.viewportHeight); gl.clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT); gl.bindBuffer(gl.ARRAY_BUFFER, vertPosBuf); gl.vertexAttribPointer(vertPos, 2, gl.FLOAT, false, 0, 0); // plot var plotPosBuf = gl.createBuffer(); gl.bindBuffer(gl.ARRAY_BUFFER, plotPosBuf); gl.bufferData(gl.ARRAY_BUFFER, new Float32Array(plot_vertices), gl.STATIC_DRAW); gl.vertexAttribPointer(plotPos, 2, gl.FLOAT, false, 0, 0); gl.drawArrays(gl.TRIANGLE_STRIP, 0, 4); } drawScene();
위와 같이 세팅을 하여 WebGL로 그릴 준비를 마친다. 다음은 셰이더 코드들이다.
attribute vec2 vertPos; attribute vec2 plotPos; varying vec2 fragPos; void main() { gl_Position = vec4(vertPos, 1.0, 1.0); fragPos = plotPos; }
정점셰이더는 단지 좌표를 넘겨줄뿐이다. 이떄 fragPos 에는 픽셀을 하나하나 그릴때 interpolate된 정점의 위치가 넘어가게 된다.
precision mediump float; varying vec2 fragPos; vec3 coloring(int bailout){ float pos = 0.0; float t = 0.0; vec4 color1; vec4 color2; vec4 colorStop1 = vec4( 0.0 /255.0 , 0.0 /255.0, 100.0 /255.0, 0.0); vec4 colorStop2 = vec4(255.0 /255.0 , 255.0 /255.0, 255.0 /255.0, 0.25); vec4 colorStop3 = vec4(255.0 /255.0 , 128.0 /255.0, 0.0 /255.0, 0.5); vec4 colorStop4 = vec4( 0.0 /255.0 , 0.0 /255.0, 0.0 /255.0, 0.75); vec4 colorStop5 = vec4( 0.0 /255.0 , 0.0 /255.0, 100.0 /255.0, 1.0); vec3 color; if(bailout >= 1024){ return vec3(0.0, 0.0, 0.0); }else{ pos = mod(float(bailout), 128.0) / 128.0; if(colorStop1.a <= pos && pos < colorStop2.a){ color1 = colorStop1; color2 = colorStop2; }else if(colorStop2.a <= pos && pos < colorStop3.a){ color1 = colorStop2; color2 = colorStop3; }else if(colorStop3.a <= pos && pos < colorStop4.a){ color1 = colorStop3; color2 = colorStop4; }else{ color1 = colorStop4; color2 = colorStop5; } t = (pos - color1.a) / (color2.a - color1.a); color.r = (1.0 - t) * color1.r + t * color2.r; color.g = (1.0 - t) * color1.g + t * color2.g; color.b = (1.0 - t) * color1.b + t * color2.b; return color; } } void main(void){ float x = 0.0; float y = 0.0; float nx = 0.0; float ny = 0.0; float cx = fragPos.x; float cy = fragPos.y; float zn = 0.0; float nu = 0.0; float t = 0.0; vec3 color1; vec3 color2; x = cx; y = cy; int cnt = 1024; for(int i=0; i < 1024; i++){ if(x*x + y*y > 4.0){ cnt = i; break; } nx = x*x - y*y + cx; ny = 2.0*x*y + cy; x = nx; y = ny; } zn = sqrt(x*x + y*y); nu = log(log(zn) / log(2.0)) / log(2.0); t = 1.0 - nu; color1 = coloring(cnt); color2 = coloring(cnt+1); color1.r = (1.0 - t) * color1.r + t * color2.r; color1.g = (1.0 - t) * color1.g + t * color2.g; color1.b = (1.0 - t) * color1.b + t * color2.b; gl_FragColor = vec4(color1, 1.0); }

위에서 익숙했던 코드 로직이 셰이더 언어로 다시 쓰여졌다. 다만 coloring 부분은 새로 작성하였는데 그라디언트 Stop값을 지정한뒤 직접 위치를 계산하여 색깔을 계산하도록 셰이더 안에 Coloring 로직을 넣었다. 이는 Fragment 셰이더까지 일정크기의 값들의 배열을 전달하기 까다롭기 때문이다. 텍스쳐를 활용하기 전에 직접 color값을 계산하도록 하였다.
위의 일반버젼이나 워커버젼과 다르게 CPU 점유율이 거의 없음에도 엄청나게 빠른속도로 렌더링 되고 있음을 느낄수 있다.
아래 링크에서 확인해볼수 있다. (크롬, 사파리)
http://ippoeyeslhw.github.io/works/mandelbrot_gl.html (WebGL 버젼)




위 작업과 똑같이 마우스 좌클릭 줌인, 오른쪽 줌아웃 기능을 추가한뒤 해상도를 3000x2000 으로 높여서 여기저기 탐색을 해보았다.
아름답다...
깔끔하고 명확하게 보이려면 해상도가 높아져야되는듯 하다. 분명 해상도를 3000*2000으로 올렸는데 텀블러에서 해상도를 낮추고 올리도록 되어있나보다...
마우스 우클릭을 줌아웃으로 해놓았기에 context menu 기능을 이벤트에서 제거했는데 다시 살리려면 아래 코드를 주석처리하면 된다. 그러면 마우스 오른쪽으로 이미지를 저장할수 있다.
canvasElem.addEventListener('contextmenu', function(e){ e.preventDefault(); }, false);

WebGL의 문제점이 있는데 바로 precision 문제가 있다. 즉 셰이더에서 사용하는 float의 정밀도가 부족하다는 점이다. single precision으로 동작하게 되는데 정밀도는 소수점 7자리 정도로서 위 예제에서는 5~6번 줌인을 하게 되면 모자이크처럼 보이게 됨을 알수 있다. 정밀도가 떨어져서 좌표계의 좌표를 구할시 소수점이 잘려 더이상 정밀하게 좌표를 구할수 없는 상태가 되는것이다.
위 그림처럼 모자이크같이 변하게 된다. 이를 해결하기 위해 WebGL의 Double-Precision으로 검색한 결과 WebGL은 double-precision을 지원하지 않는다고 한다.
다만 이를 우회하는 편법같은것이 있는데 바로 double-precision을 emulate하는 것이다. 즉 vec2 같은 것으로 직접 구현하는 것으로서 다음 링크를 읽어보면 답이 나올것 같다.
https://www.thasler.com/blog/blog/glsl-part2-emu
며칠간 위의 것들을 구현하면서 오랬만에 재미있게 개발하였다. 마치 학생때로 돌아간것 같은 느낌이다.
Mandelbrot Set 은 굉장히 마음에 든다. 그 화려함과 복잡함이 아주 간단한 수식에 의해 만들어진다는 점이 특히 그렇다. 요즘에는 3D로도 Fractal 이 나온다던데 아직까진 기본중의 기본? 인 Mandelbrot 집합에 정감이 간다.
픽셀단위 이미지처리관련 프로그래밍을 하고자 하는 사람에게 잠시나마 머리를 식힐수 있는 기회로 위 만델브로트집합 구현을 추천한다. 만들다보면 어느샌가 계속 줌인, 줌아웃 하고있는 자신을 보게될지도 모르겠다.
1 note
·
View note
Text
사이보스플러스 C# 활용
이전 포스팅에서 파이썬과 사이보스플러스를 연동한 Adapter를 만들어 보이기도 하였다. 하지만 빠르게 윈폼 계열로 간단한 아이디어를 짜는 것으로는 C# 이 괜찮다. 이번 포스팅은 간단한 프로그램을 만들어 보는 것이다.
로그인
일단 사이보스플러스에 로그인을 한다. 이렇게 되면 COM을 통하여 원하는 것을 만들어볼수 있다.

윈폼생성

참조추가

COM 추가


일단 이렇게 추가가 되었으면 이제 사용 가능하다.
간단한 프로그램
이제 간단한 프로그램을 만들어볼것이다. 비주얼 스튜디오에서 제공하는 기능만으로도 충분한 도구가 될 수 있다. 예를 들면 차트와 같은 것들인데 이미 비주얼스튜디오에 훌륭한 컴포넌트가 존재한다.
간단한 레이아웃 구성

위와 같이 구성한다. 의도는 다음과 같다 왼쪽 상단 텍스트박스에다가 종목명을 입력하면 오른쪽의 라벨에 종목코드가 입력되고 아래 차트에서 해당종목의 차트가 보이는 간단한 프로그램이다. 어떻게 할수 있을까?

위 차트 콘트롤은 닷넷 콤포넌트로 제공하고 있다. 설정을 바꾸면 캔들스틱 차트로도 바꿀수 있다.
차트속성변경
2.1 Series 속성변경


2.2 Y축 배율변경
아마 테스트 데이터를 넣어보면 알겠지만 데이터가 0부터 시작하는 바람에 데이터가 너무 밋밋하게 보일 것이다. 이를 해결하기 위해 0부터 시작하는 옵션을 꺼준다.

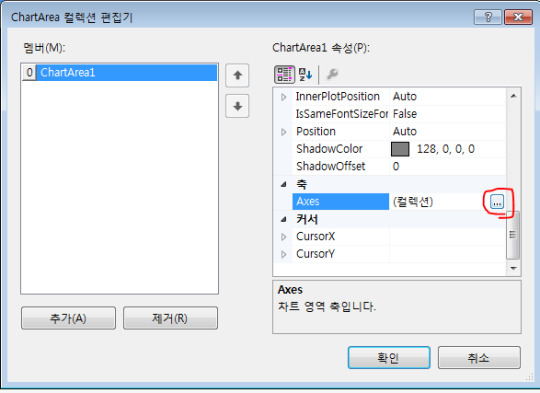

즉 Y축에 대한 속성을 잘 찾아서 설정해주면 된다. 엥간하면 거진 다 있을법한 기능이니 구글링을 열심히하여 콤포넌트 사용법을 찾아보면 될 것이다.
종목명에서 종목코드를 가져오기
사이보스플러스를 활용하기 위해서는 도움말이 절대적으로 필요하다. 처음에는 양이 많아 보이고 불친절하게 보일수도 있지만 자꾸 살펴보고 작성하다보면 모든 문서의 내용이 균일하게 같은 패턴으로 제공하고 있어서 몇가지를 응용해보면 다른것도 사용하기 굉장히 쉬워진다. 어쨋든 종목명을 가지고 종목코드를 알아내기 위해 아래와 같이 도움말에서 찾아본다.
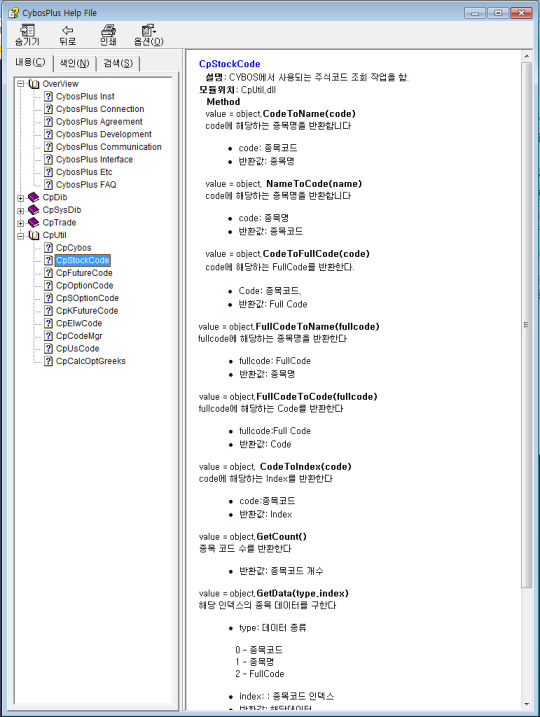
왼쪽의 트리뷰와 오른쪽의 내용을 잘 보면 된다. 즉 CpUtil 이라는 곳의 CpStockCode 에서 NameToCode 라는 메서드를 제공하는 것처럼 보인다. 그러면 실제로 아까 비주얼 스튜디오에서 참조한 COM 오브젝트를 사용하여 객체를 생성하면 된다. Visual assist 가 굉장히 강력해서 금방금방 찾을 수 있다.
일단 코드를 보자
namespace ChartTest { public partial class Form1 : Form { private CPUTILLib.CpStockCode cpstkcode; // 멤버선언 public Form1() { InitializeComponent(); } private void Form1_Load(object sender, EventArgs e) { cpstkcode = new CPUTILLib.CpStockCode(); // 인스턴스 생성 } private void textBox1_KeyPress(object sender, KeyPressEventArgs e) { if (e.KeyChar == Convert.ToChar(Keys.Enter)) { // 메서드를 사용, 라벨에 코드값 표시 label1.Text = cpstkcode.NameToCode(textBox1.Text.Trim()); } } } }
엔터키가 눌렸을때(이벤트) 해당 메서드를 통해 가져오도록 하였다. 실제로 작성해보면 VS가 자동완성으로 해주기 때문에 간단하고 빠르게 작성가능하다.
StockChart 객체사용하기
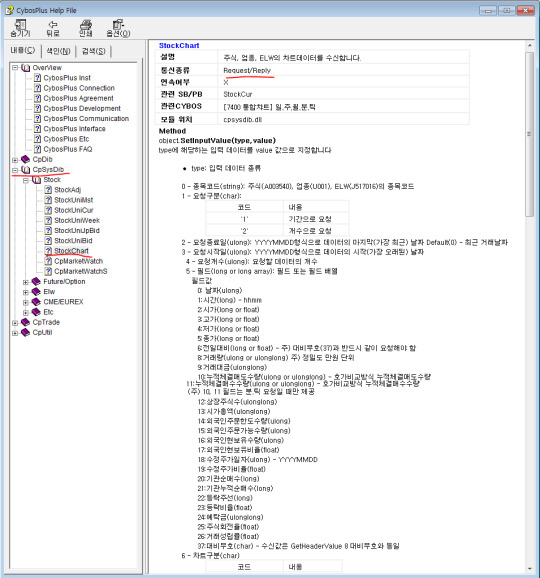
StockChart 라는 오브젝트가 있다. 이를 사용하면 차트데이터, 시계열 데이터를 가져올수 있다. 위 도움말을 살펴보자면 CpSysDib 이라는 곳에 StockChart 라는 오브젝트가 있고 이 오브젝트는 Request/Response 통신 방식을 사용한다는 것을 알수 있다.
Request/Response 방식은 주고 받는 것이다. 즉 요청을 보내면 응답을 받는 것이다. 순서는 다음과 같다.
SetInputValue를 잘 세팅하여 원하는 조건을 세팅한다.
Request 메서드를 호출하여 요청을 날린다.
해당 요청에 대한 응답을 받았을때 작성해둔 응답로직이 수행된다.
BlockRequest 방식은 느린 네트워크 시간을 감내하는 것이므로 비효율적이다. 될수있는한 Request로 작성하고 비동기적으로 수행되는 이벤트 기반 코드들이 원하는 대로 수행할수 있도록 신경써서 로직을 구성하면 된다.
위에 제시한 순서를 사용하여 최종 코드를 짜보았다. 위 코드에서 덧붙여진 코드이며 VS의 자동완성 기능도 활용하여 코드를 만들었다.
namespace ChartTest { public partial class Form1 : Form { private CPUTILLib.CpStockCode cpstkcode; // 멤버선언 private CPSYSDIBLib.StockChart stkchart; // 멤버선언 public Form1() { InitializeComponent(); } private void Form1_Load(object sender, EventArgs e) { cpstkcode = new CPUTILLib.CpStockCode(); // 인스턴스 생성 stkchart = new CPSYSDIBLib.StockChart(); // 인스턴스 생성 stkchart.Received += stkchart_Received; } void stkchart_Received() { // stkchart 인스턴스가 요청후 응답을 받을시 수행됨 chart1.Series[0].Points.Clear(); int cnt = stkchart.GetHeaderValue(3); // 수신개수 for (int i = cnt-1; i >= 0; i--) // 인덱스 감소 { int open = stkchart.GetDataValue(1, i); int high = stkchart.GetDataValue(2, i); int low = stkchart.GetDataValue(3, i); int close = stkchart.GetDataValue(4, i); chart1.Series[0].Points.AddY(high, low, open, close); } } private void textBox1_KeyPress(object sender, KeyPressEventArgs e) { if (e.KeyChar == Convert.ToChar(Keys.Enter)) { // 메서드를 사용, 라벨에 코드값 표시 label1.Text = cpstkcode.NameToCode(textBox1.Text.Trim()); // 차트데이터 요청을 위해 Request 세팅 stkchart.SetInputValue(0, label1.Text); // 종목코드 stkchart.SetInputValue(1, '2'); // 요청구분 '2': 개수 stkchart.SetInputValue(4, 100); // 요청개수 stkchart.SetInputValue(5, new int[]{0,2,3,4,5}); // 요청필드 {날짜,시가,고가,저가,종가} stkchart.SetInputValue(6, 'D'); // 차트구분 'D': 일 stkchart.Request(); // !!요청!! } } } }
위 코드를 적용하여 완성된 프로그램을 실행시켰을때 모습이다.

주의점
Request/Response 방식의 오브젝트들은 요청제한이 있다. 도움말의 Overview - Cybosplus interface 에 보면 시세오브젝트는 15초에 60건, 주문오브젝트는 15초에 20건의 제한사항이 나온다. 즉 평균적으로 0.25초 동안 지속적으로 요청을 하든지 한번에 60건을 쏟아붓고 나머지 시간을 쿨타임으로 놓든지 간에 요청개수 및 시간관리도 관리해야될 자원이라는 것이다.
위 프로그램은 사이보스플러스를 접속시켜놓은 상태에서 수행했기 때문에 정상동작하는 것이다. 접속중이 아니었다면 객체생성이라든지 오브젝트 메서드를 호출하는 과정에서 미정의 오류가 날 가능성이 있다. 가장 좋은 방법은 접속여부를 판단하는 것, 도움말에서 Cputil Cpcybos 오브젝트를 찾아서 사용하면 된다.
닷넷 Chart 콤포넌트에 시계열에 캔들스틱 차트에 봉을 추가할시 가격의 순서는 특이하게도 고가,저가,시가,종가 순이다. 위 코드를 잘 살펴보면 된다.
1 note
·
View note
Text
요즘 읽은 책들

신호와 소음
유명하다고 하여 본 책이다. 책 페이지는 650페이지가 가뿐히 넘어간다. 요즘 쏟아지는 빅데이터 관련한 주제로는 꽤 괜찮은 내용을 담고 있으나 실용적이지는 않고 그냥 교양적인 마음가짐으로 읽으면 된다. 결국 이책은 "베이즈주의 짱!" 으로 끝난다. 솔직히 글쓴이가 유명한지는 잘 모르겠지만.. 금융,경제에 대한 시각은 주류에 대해 예측가능성에 대해 비판적이며, 정치, 날씨, 지진, 체스 주제로는 나름대로의 시각을 그리고 야구통계에 대해서는 우호적이다. 역학과 체스 그리고 허리케인에 대한 내용을 재미있게 읽었다.
메트릭 스튜디오
저자는 문병로 교수이다. 전공이 컴공이라 굉장히 반가웠다. 학부시절 Introduction To Algorithms 책을 넘겨가며 봐도 번역자 이름을 새기긴 어렵겠지만 이 책 번역 후에 연달아서 나온 책인 쉽게 배우는 알고리즘, 쉽게 배우는 유전 알고리즘 까지 집에 다 가지고 있으니 반가움은 당연하다. 이 책은 "기하평균 짱!" 이 핵심이자 전부이다. 책의 모든 챕터는 기하평균을 위해 씌어졌고 다양한 의문에 대해 기하평균을 적용하여 실증적으로.. 계량적으로 적용하여 결론을 낸다. 이 책의 유용성은 책의 내용보다. 문병로 교수님이 사용하는 접근법이 훨씬 더 유용하다. 모든 주관을 제거하고 데이터를 이용하여 상승/하락 확률, 산술평균/기하평균 등등 데이터를 뽑고 해석을 해서 결론을 얻는 일련의 방법론말이다. 이는 책의 시작부터 끝까지 반복되니 충분한 공부가 된다.
커넥톰 뇌의 지도
이 책은 대충 훑어보니 예전에 재미있게 읽었던 "생각하는 뇌, 생각하는 기계" 가 떠올라 그냥 바로 돈주고 집어온 책이다. 읽다보니 저자 이름이 한국이름이길래 놀랐다. 이 책은 위의 생각하는 기계 책보다는 재미없다. 좀 내용이 어려운데 신경의학쪽에서 사용하는 용어들과 실험에 관련된 내용이 잔뜩 나오기 때문이다. 굉장히 세세한 책이다. 책을 읽다보면 '내가 지금 생각하고 있는 것은 단지 신호가 계속 회돌이 하는건가?' 하는 생각이 들며 허무해지고 힘이 빠진다. 책 읽는 시간은 주로 퇴근시간 버스에서 30~40분 정도 읽는데 이 책을 읽을 때는 4페이지 읽으면 어느샌가 자고있고 그래서 꽤 힘들었다.
전략적 사고 트레이닝 그것이 최선인가?
이 책은 게임이론에 관한 책이다. 딱히 좋은 책은 아닌것 같다. 나는 내가 잘 모르는 분야는 오히려 사례를 보고 어떻게 적용되었는지 역으로 보는 방법이 이해하기 쉬워 더 좋아한다. 그래서 책을 골랐으나 뭔가 내용이 부실한 느낌이다. 게임이론에 관한 책 몇개만 더 읽으면 책의 수준이 나올것 같다. 이 책을 읽으면 읽을수록 궁금한 점은 '사람이 이렇게 냉정하고 아무 감정없이 자기에게 최대 유리한 선택만 할까?' 라는 것이였다. 나는 오히려 사람이 감정폭풍에 휘말려 말도 안되는 짓거리를 하는 동기를 찾는게 꿈인데 게임이론에서 등장하는 세계는 이와는 정반대이다.
위 네개의 책은 약 3~4개월 동안 틈틈히 읽어서 겨우겨우 읽었다. 나이를 먹을수록 읽는 속도가 떨어지고 둔해지는 것 같아서 경각심이 든다.
0 notes
Text
Python에서 Cybosplus 사용하기 일반화
일전에 python에서 Cybosplus를 쓰는 방법과 대략적인 구조를 살펴보았는데 좀더 연구하여 더 예쁘게(?) 사용하는 방법에 관한 포스팅이다.
이를 토이프로젝트로 Github에 올려놓았고 https://github.com/ippoeyeslhw/cppy 요새 유행한다는 CEP의 구조를 본따서 구조를 만들었다. 이 포스팅에서 나오는 유사 디자인 패턴은 3가지로서 엄격하게 구현한것은 아니고 느슨하다.
Adaptor 패턴 : 사이보스 플러스에서 가져온 데이터를 변환
Decorator 패턴 (Python syntax sugar) : Adaptor 객체 생성시 COM 객체를 쉽게 연결
Observer 패턴 : 이벤트 발생시 연결된 콜백수행
아래는 CEP의 개괄도이다. (상용엔진 Apama)

cppy 토이프로젝트는 아래 그림에서 부가 툴 부분 없이 핵심부분만(Adaptor, EventProccessor) 구현한거라고 보면 된다.
클래스데코레이터 사용하기
파이썬은 데코레이터를 지원하는데 대개 Wrapper를 만드는데 쓴다. 나는 클래스의 데코레이터를 생성, COM객체를 쉽게 만들수 있는 목적에서 설계하였다. 예를 들면 아래와 같다.
from cppy.adaptor import CpRqRpClass, CpSubPubClass # 주식 현재가 @CpSubPubClass('dscbo1.StockCur') class StkCur(object): def __init__(self, itm_cod='A122630'): self.itm_cod = itm_cod def subscribe(self, com_obj): com_obj.Unsubscribe() com_obj.SetInputValue(0, self.itm_cod) com_obj.Subscribe() def publish(self, com_obj): nowpr = com_obj.GetHeaderValue(13) # 현재가 sellbuy = com_obj.GetHeaderValue(14) # 매수매도구분(체결시) clsqty = com_obj.GetHeaderValue(17) # 순간체결수량 # 이벤트처리기에 전달 evntproc.push('cls_%s'%(self.itm_cod),(nowpr, chr(sellbuy), clsqty))
즉 데코레이터로 클래스를 꾸며준다. 이때 COM 문자열을 지정하면 해당 COM객체랑 연결되어 앞으로 클래스가 사이보스플러스 데이터를 받도록 되는 것이다. 위 예에서는 @CpSubPubClass('dscbo1.StockCur') 처럼 사용하였으니 'dscbo1.StockCur' 의 COM객체가 연결되었다.
데코레이터의 장점은 제공하는 측에서 좀더 상세히 제어를 할수 있다. 여기서는 subscribe, publish 메소드를 만들지 않으면 아예 프로그램이 수행되지 않도록 했다. 이런식으로 특정 메소드를 구현하도록 하게 할 수 있고 클래스 단위로 작업을 분리해서 할 수 있고 프로그램 설계가 쉬워지게 된다.
이벤트 처리기 사용하기
이벤트 처리기는 순전히 옵저버패턴의 구현이다. 이때 옵저버 매니저객체에 전달되는 데이터들은 어뎁터들에서 생산된 데이터들이다. 이 데이터는 어뎁터에서 Key를 배정받았으며 이 Key를 가지고 이벤트를 처리하게 된다. 이벤트 처리기는 이 데이터들을 처리하면서 미리 등록된 옵저버 프로그램들(Callable obj)을 수행하고 시계열로 데이터를 저장한다.
# 체결시 출력 def cls_echo(serieses, key, dat): print 'key:%s, dat:%s'%(key,dat) # 호가변경시 출력 def ord_echo(serieses, key, dat): print 'key:%s, dat:%s'%(key, dat) # 이벤트 처리기 세팅 evntproc = EventProcessor() evntproc.add_observer(['cls_*'], cls_echo) evntproc.add_observer(['ord_*'], ord_echo) evntproc.start()
add_observer 메소드를 사용할때면 키의 패턴의 배열을 지정하고 callable 객체를 인자로 넘겨준다. 그러면 나중에 해당 패턴에 매칭되는 데이터가 들어왔을시 그때서야 등록된 콜백이 실행이 된다. 위 예에서는 evntproc.add_observer(['cls_*'], cls_echo) 일때 cls_로 시작하는 키를 가진 데이터가 들어올때마다 cls_echo(serieses, key, dat)이 실행된다.
serieses 인자는 시계열의 집합으로서 key를 통해 해당 시계열에 접근할수 있다. 내부적으로 시계열은 deque 으로 구현되었으며 각 데이터는 timestamp (유닉스시간, time.time()) 을 지니고 있어 시간도 알수 있다. 이후 Iterator 몇개를 더 추가하여 제공할 계획이다. 위와 같은 것들을 사용하여 다양한 프로그램을 만들수 있다. 예를 들면 아래와 같은 것들을 만들수 있다.
특정시간까지만 읽기: 적어도 80% 이상 종목에 대해 5초 이내에 순간적으로 체결이 강하게 발생한 경우를 감지
데이터에 대한 보조지표계산: 꼭 현재가가 아니더라도 호가잔량과 같은 데이터에 대해서도 이동평균, 가중평균, 회긔, 패턴검색, 상따시 상한가 잔량 감시 등등
트리거링 포인트: 특수한 상황이 발생했을때 key와 data 를 발급하여 다시 이벤트 처리기에 push 함, 즉 매수/매도 주문을 집행한다던가 할 경우
Frame Work
지금까지는 어댑터를 제공하고 이벤트처리기를 제공하는 라이브러리의 역할을 했으나 이제 이것들을 엮어서 의도한대로 프로그램을 작성하도록 뼈대를 구축할 필요가 있다. 위 github 에서 소스를 보면 publish_test.py 라는 예제에 얼추 설계된 뼈대가 있다.
# coding=utf-8 from cppy.adaptor import CpRqRpClass, CpSubPubClass from cppy.processor import EventProcessor # 이벤트 처리기, 이 모듈이 실행될시 할당됨 evntproc = None ################################################### # Adaptors : 발생한 이벤트를 처리기에 전달하는 역할 # ################################################### # 주식 현재가 @CpSubPubClass('dscbo1.StockCur') class StkCur(object): def __init__(self, itm_cod='A122630'): self.itm_cod = itm_cod def subscribe(self, com_obj): com_obj.Unsubscribe() com_obj.SetInputValue(0, self.itm_cod) com_obj.Subscribe() def publish(self, com_obj): nowpr = com_obj.GetHeaderValue(13) # 현재가 sellbuy = com_obj.GetHeaderValue(14) # 매수매도구분(체결시) clsqty = com_obj.GetHeaderValue(17) # 순간체결수량 # 이벤트처리기에 전달 evntproc.push('cls_%s'%(self.itm_cod),(nowpr, chr(sellbuy), clsqty)) # 주식 호가잔량 @CpSubPubClass('dscbo1.StockJpBid') class StkBid(object): def __init__(self, itm_cod='A122630'): self.itm_cod = itm_cod def subscribe(self, com_obj): com_obj.Unsubscribe() com_obj.SetInputValue(0, self.itm_cod) com_obj.Subscribe() def publish(self, com_obj): tlist = [] for i in xrange(3,23,4): itm = ( com_obj.GetHeaderValue(i+0), com_obj.GetHeaderValue(i+1), com_obj.GetHeaderValue(i+2), com_obj.GetHeaderValue(i+3) ) tlist.append(itm) # 이벤트 처리기에 전달 evntproc.push('ord_%s'%self.itm_cod, tlist) ################################################### # Observers : 자신의 키 패턴에 매칭되는 이벤트를 처리함 # ################################################### # 체결시 출력 def cls_echo(serieses, key, dat): print 'key:%s, dat:%s'%(key,dat) # 호가변경시 출력 def ord_echo(serieses, key, dat): print 'key:%s, dat:%s'%(key, dat) ################################################### # main : 어뎁터들과 옵저버들을 등록하고 서비스를 기동한다. # ################################################### if __name__ == "__main__": # 이벤트 처리기 세팅 evntproc = EventProcessor() evntproc.add_observer(['cls_*'], cls_echo) evntproc.add_observer(['ord_*'], ord_echo) evntproc.start() # 현재가, 매수매도구분, 순간체결량을 생산 stkcur1 = StkCur('A122630') stkcur1.subscribe() stkcur2 = StkCur('A114800') stkcur2.subscribe() # 호가잔량 생산 stkbid1 = StkBid('A122630') stkbid1.subscribe() stkbid2 = StkBid('A114800') stkbid2.subscribe() ############################################## # WinCOM32 이벤트 생성, # sleep time으로 메세지를 펌핑시키므로 비효율적이다. # 따라서 이벤트 처리기는 자식 프로세스에서 동작 ############################################## import pythoncom, time while True: pythoncom.PumpWaitingMessages() time.sleep(0.001) # 최소시간간격 (실질환경은 0.015초에 가까울것)
매우 간단한 구조로 되어있다. Toy 프로젝트이기 때문에.. 앞으로 이러한 구조로 만들도록 할것이다.
지금까지는 실시간 이벤트 처리를 위한 구조로 만들기 위해 base를 만드는 작업을 하였다. 이제는 정말 주식분석툴 혹은 시스템트레이딩 툴로서 부가적인 Utility 를 만들차례다. 예를 들면 계좌를 만든다던지, 주문을 만든다던지, 가상체결 시스템을 만든다던지 아니면 위 사진대로 모니터링 툴이나 설계툴까지 말이다.
0 notes
Text
Bitbucket 을 Github for Window으로 사용하기

방법을 알고나서 너무 쉬워서 뒷골이 땡겨왔다. 너무나도 직관적이다.
clone 누르면 저장소 URL이 나오는데 https://.. 부터 마지막까지 쭉 선택한뒤에... 그걸 그대로 Drag해서 github for window 위에다가 Drop 하면 된다.

그러면 위처럼 표시되면서 bitbucket에 로그인하라고 한다.
혼자서 개인적으로 가볍게 관리할 프로젝트 같은경우 github 으로 하긴 공개적으로 부담스럽다. 이럴때 bitbucket으로 하면 좋을 것이다.
1 note
·
View note
Text
Rolling Window
Rolling 혹은 Sliding Window 와 같은 자료구조가 필요할 때가 있을것이다. 따라서 python 으로 해당 내용을 검색하였으나 StackOverflow 에 있는 내용이 검색되는 정도일뿐 딱히 공식적인 내용은 없어보인다. 따라서 Custom 으로 만들기로 했다.
요구되는 기능은 다음과 같다.
Rolling이 될때 사용하기 쉽도록 iterator 를 사용 원소 순회를 효율적으로 하도록 한다.
미리 Window 크기를 지정한후 Full 이 났을때는 가장 먼저 저장한 원소를 빼고 거기다가 저장한다. 즉 일정 크기를 유지하며 회전한다.
데이터로 표현을 하면 다음과 같은 예를 들 수 있다.
[] [11] [11,12] [11,12,13] [11,12,13,14] [12,13,14,15] [13,14,15,16]
11부터 시작하여 연속되는 숫자를 계속 집어 넣는다. Window 크기는 4이다. 즉 일정크기까지는 순차적으로 채워지다가 다 채워지면 회전이 되는 것이다.
이를 최대한 성능이 떨어지지 않도록 구현한다. 최대한 객체의 생성이 되지 않도록 하기 위해 미리 크기만큼 할당을 하고 시작인덱스와 크기 윈도우 크기 만을 이용해 iterator 를 구현한다.
class RollingWindow: def __init__(self, max): self.s_idx = 0 self.max = max self.size = 0 self.data = range(max) # alloc def put(self, data): # append if self.size < self.max: self.size += 1 else: self.s_idx += 1 if self.s_idx >= self.max: self.s_idx = 0 # assign self.data[(self.s_idx + (self.size - 1)) % self.max] = data def pop(self): if 0 < self.size: self.size -= 1 ret = self.data[self.s_idx] self.s_idx += 1 if self.s_idx >= self.max: self.s_idx = 0 return ret else: return None def __iter__(self): self.c = 0 return self def next(self): # inc if self.c < self.size: self.c += 1 return self.data[(self.s_idx + (self.c - 1)) % self.max] else: raise StopIteration def __len__(self): return self.size def __str__(self): arr = [ str(self.data[(self.s_idx + i) % self.max ]) for i in xrange(self.size)] return '[' + ','.join(arr) + ']'
아래는 위 코드를 이용한 예제이다.
rw = RollingWindow(4) print rw for i in xrange(11,17): rw.put(i) print rw for k in rw: print '"%s",'%k, print ' ;' while rw.pop(): print rw
결과
[] [11] [11,12] [11,12,13] [11,12,13,14] [12,13,14,15] [13,14,15,16] "13", "14", "15", "16", ; [14,15,16] [15,16] [16] []
코드를 보면 put 이든 pop 이든 항상 시작 인덱스는 오른쪽으로 증가한다. 그런데 증가하다가 max범위를 넘어가면 다시 0으로 지정하여 회전한다. 또한 원소를 put 할때도 똑같이 오른쪽으로 증가하는데 max범위를 넘어가면 0으로 지정하여 회전한다. 이 경우에는 시작인덱스를 증가시켜 가장 먼저들어간 원소가 자연스럽게 제거되도록 한다. Iterator 는 크기만큼 순회한다. 이는 시작인덱스와 크기를 이용하면 쉽게 구현할수 있다.
이렇게 간단한 Rolling 구조를 만들었는데 이는 deque을 사용한 방식과는 좀 다르다. 원소를 pop put 하는 작업없이 바로 iterator 로 순회 가능하면서도 Rolling 이 되고 그리고 Full이 되면 딱히 예외를 받지 않고 알아서 Circular Queue처럼 pop 하면서 push 가 되는데 이는 인덱스의 이동으로만 처리하므로 오버헤드가 적다.
0 notes
Text
베팅게임
베팅이 연속적으로 일어나는 상황에서 손실이 발생하더라도 베팅을 이어갈수 있으면서 만회도 할수 있는 전략을 찾기위해 조사하였다.
이러한 문제의 접근은 $ x_0 = 자본금 $ 에서부터 시작하여 $ x_1 = R_{win} \times x_0 , x_1 = R_{loss} \times x_0 $ 와 같은 케이스를 나눈뒤에 $ x_n $ 인 경우까지 논의를 확장시킨다. 그뒤 최대지점을 찾기 위해 편미분을 하게 된다.
예는 다음과 같다.
동전을 던져 앞면이 나오면 수익율에 의해 수익을 얻는다. 뒷면이 나오면 베팅금액을 잃는다. $r = 수익률$ 이고 $ 0 \leqq \alpha \leqq 1$ 를 베팅비율이라 한다. 앞면이 되어 수익을 얻는다고 하면 베팅하여 수익을 얻은 금액과 현금으로 가지고 있던 금액이 존재하고 뒷면이 되어서 베팅금액을 잃는다고 하면 현금으로 가지고 있던 금액만 남게 되므로 $$ x_1 = \cases{ r \alpha x_0 + (1-\alpha) x_0 = (1 + (r-1)\alpha)x_0 & \text{win} \cr (1-\alpha) x_0 & \text{loss} } $$ 으로 표현할수 있다. 이를 N번의 플레이로 확장을 한다고 하면 동전의 앞뒤면이 공정한 확률로 나타난다 했을때 win 혹은 loss 는 $ \frac N 2 $ 번씩 나타난다. $$ x_N = (R_{win})^{\frac N 2} (R_{loss})^{\frac N 2} = (1 + (r-1)\alpha)^{\frac N 2} (1-\alpha)^{\frac N 2} x_0$$ 라고 식을 세울수 있다. 다음엔 자본금 증식을 최대화 하는 $\alpha$ 값을 계산하기 위해 미분을 한다. $ x_N을 \alpha$로 미분하여 0이 되는 지점을 찾는다. $$ N(1-\alpha)^{\frac N 2 - 1}(\alpha(r-1)+1)^{\frac N 2 - 1} [(-\frac 1 2) (2\alpha(r-1)-r+2)] $$
미분과정은 복잡하므로 울프램알파나 sympy 같은것으로 계산해보면 쉽게 할수 있다.
위 가정은 틀리면 모든 베팅금액을 잃으므로 가혹하다. 만일 손실시 비율만큼 돌려받는 게임을 한다고 가정한다. 이기면 2배를 받고 지면 절반을 잃는 게임이다.
다음을 보자 $$ \cases{ R_{win} = ( 1 - a ) + 2 a = (1 + a) \cr R_{loss} = ( 1 - a ) + \frac 1 2 a = ( 1 - \frac 1 2 a ) } $$ 따라서 아까와 마찬가지로 N 에 대해서 확장을 한다. $$ x_N = (R_{win})^{\frac N 2}(R_{loss})^{\frac N 2} x_0 = (1+a)^{\frac N 2}(1 - \frac 1 2 a)^{\frac N 2} x_0$$ 똑같이 편미분을 하고 0이 되는 지점을 찾는다. $$ N (1+a)^{\frac N 2 - 1}(1 - \frac 1 2 a)^{\frac N 2 - 1} [\frac 1 4 - \frac 1 2 a] x_0 = 0 $$
이러한 형태로 베팅비율을 확인하고 실제로 베팅을 했을때 몇배의 비율로 증가함을 기대할수 있는지 계산할 수 있다.
0 notes
Text
Cybosplus 랑 Python 사용 일반화
cybosplus 은 대신증권 api 로 COM 방식으로 동작한다. 이는 C#으로 연결하면 아주 쉽게 되어 그동안 C#으로 작업해 왔는데 python 으로도 연결하는 방법이 있는 모양이다.
win32com 모듈설치
COM을 다루기 위해서 pywin32 를 설치한다. http://sourceforge.net/projects/pywin32/ 여기서 받아서 설치할때 주의할 점은 cybosplus 는 32비트에서 동작해야 한다는 점, 괜히 64비트 어쩌고 받아서 설치해서 알수 없는 오류에 빠지지 말아야겠다.
win32com사용법
# COM객체 생성 com_obj = win32com.client.Dispatch("dscbo1.StockMst") # 이벤트 class CpEventHandler: def OnReceived(self): pass win32com.client.WithEvents(com_obj, CpEventHandler) # 비동기식 이벤트를 의도할때 (not BlockRequest) # 아래와 같이 사용하여 해당 스레드에서 대기하는 메시지를 Pump한다. while True: pythoncom.PumpWaitingMessages() time.sleep(0.01)
기본적으로 Dispatch 메소드를 이용해서 COM객체랑 연결하고 사용하는듯 하다. 그리고 이벤트를 사용하려면 withevents 를 이용하여 이벤트를 서로 연결해준다.
일반화시키기
솔직히 cybosplus api 가 제공하는 COM 모듈이 엄청 많고 이를 일일히 Event 클래스를 만들어서 이벤트를 연결해줘야하는데 문제는 인스턴스로 찍어낼수 없다는 사실이다. 또 이벤트핸들러 클래스와 com_obj가 분리되어 있어 OnReceived 이벤트 메소드 수행할시 com_obj를 접근가능하도록 사전작업을 해놓아야 한다. 이는 필연적으로 지저분해질수 밖에 없는 구조이다. 따라서 클래스를 찍어내는 클래스를 만들것이다. 마치 팩토리 패턴처럼 말이다. 다만 객체를 찍어내는게 아니라 클래스를 찍어낸다.
class CpClass: cnt = 0 @classmethod def Bind(self, usr_obj): handler = new.classobj('CpClass_%s'%CpClass.cnt, (CpClass,),{}) handler.idx = CpClass.cnt handler.com_obj = win32com.client.Dispatch(usr_obj.com_str) handler.usr_obj = usr_obj win32com.client.WithEvents(handler.com_obj, handler) CpClass.cnt = CpClass.cnt + 1 return handler @classmethod def Request(self): self.usr_obj.request(self.com_obj) def OnReceived(self): self.usr_obj.response(self.com_obj)
Bind 메소드가 핵심인데 COM객체를 얻어오는 작업, COM연결을 위한 이벤트핸들러 클래스 연결하는 작업 등등을 일반화 시켜놓았다. 따라서 usr_obj 즉 사용자가 정의한 객체만 인자로 넘겨주면 이와 연결된 '클래스'가 생성된다.
그래서 사용자는 Bind로 얻어낸 클래스를 가지고 Request 메소드를 사용할수 있다. 이는 사용자 객체의 request를 대신 호출해주는 Wrapper일 뿐이다. 비동기 호출이였다면 OnReceived 이벤트가 발생하게 될 것이다. 이때 사용자객체의 response메소드를 대신 호출해준다.
CpClass 사용방법
새로운 방식으로 사용하도록 만들었으니 실제로 어떻게 사용해야하는것인지 예를 들어본다.
class StkMst: def __init__(self): # COM 연결하는데 필요한 문자열 self.com_str = "dscbo1.StockMst" # request 메소드와 첫번째 인자로 com_obj가 필요 def request(self, com_obj): com_obj.SetInputValue(0, "A000660") com_obj.Request() print 'rq [%s]'%self.__class__.__name__ # 이벤트 발생시 첫번쨰 인자로 com_obj가 필요 def response(self, com_obj): print 'rp [%s]'%self.__class__.__name__ print com_obj.GetHeaderValue(1) # CpClass 에 사용자가 정의한 객체를 Binding cpchart = CpClass.Bind(CpChart()) cpchart.Request() while True: pythoncom.PumpWaitingMessages() time.sleep(0.01)
사용자가 사용할 클래스는 반드시 com_str 을 멤버변수로 가져야 하며 request 메소드와 response 메소드를 생성해야 한다. 이들 메소드의 첫번째 인자는 com_obj로 지정하여 COM객체에 접근하여 사용할수 있도록 하였다.
이렇게 사용자 클래스를 만들었으면 CpClass.Bind(인스턴스) 처럼 사용하여 '클래스' 를 얻어낸다. 그러면 된 것이다. 클래스메소드인 Request를 호출하여 비동기 요청을 하면 알아서 통신한다. 사용자가 정의한 request 메소드를 호출하여 com_obj를 이용한 '요청' 을 할수 있고 증권사에서 '응답'을 받아 처리 가능하다.
응용 및 결과
위 간단한 CpClass 를 응용하는 예제 풀소스와 실행결과를 보임으로 포스팅을 마친다. 지금까지는 Request/Response 통신과 관련된 예만 보였지만 Subscribe/Publish 통신 방식을 제공하는 COM객체도 똑같이 사용할수 있다.
풀소스
# coding: utf-8 import win32com import win32com.client import pythoncom import new import threading import time class CpClass: cnt = 0 @classmethod def Bind(self, usr_obj): handler = new.classobj('CpClass_%s'%CpClass.cnt, (CpClass,),{}) handler.idx = CpClass.cnt handler.com_obj = win32com.client.Dispatch(usr_obj.com_str) handler.usr_obj = usr_obj win32com.client.WithEvents(handler.com_obj, handler) CpClass.cnt = CpClass.cnt + 1 return handler @classmethod def Request(self): self.usr_obj.request(self.com_obj) def OnReceived(self): self.usr_obj.response(self.com_obj) # --------------------------- # user classes # --------------------------- class StkMst: def __init__(self): # COM 연결하는데 필요한 문자열 self.com_str = "dscbo1.StockMst" # request 메소드와 첫번째 인자로 com_obj가 필요 def request(self, com_obj): com_obj.SetInputValue(0, "A000660") com_obj.Request() print 'rq [%s]'%self.__class__.__name__ # 이벤트 발생시 첫번쨰 인자로 com_obj가 필요 def response(self, com_obj): print 'rp [%s]'%self.__class__.__name__ print com_obj.GetHeaderValue(1) class CpChart: def __init__(self): self.com_str = "CpSysDib.StockChart" def request(self, com_obj): com_obj.SetInputValue(0, "A003540") com_obj.SetInputValue(1, '2') com_obj.SetInputValue(4, 10) com_obj.SetInputValue(5, 5) com_obj.SetInputValue(6, ord('D')) com_obj.Request() print 'rq [%s]'%self.__class__.__name__ def response(self, com_obj): print 'rp [%s]'%self.__class__.__name__ print '받아온개수: [%s]'%com_obj.GetHeaderValue(3) stkmst = CpClass.Bind(StkMst()) stkmst.Request() cpchart = CpClass.Bind(CpChart()) cpchart.Request() while True: pythoncom.PumpWaitingMessages() time.sleep(0.01)
실행결과
C:\Python27\python.exe C:/Users/lhw/PycharmProjects/mytest/mytest.py rq [StkMst] rq [CpChart] rp [StkMst] SK하이닉스 rp [CpChart] 받아온개수: [10] Process finished with exit code -1
0 notes
Text
scrap_page
크롬 확장을 개인적으로 자주 만들어 사용하는데 이때 어떤 url 의 페이지를 읽어들이고 싶을때가 있다. 이때 ajax 스타일로 scrap 하는 스니펫 코드를 만들었다.
function scrap_page(url, callback){ var xhr = new XMLHttpRequest(); xhr.onreadystatechange = function(){ if(xhr.readyState == 4){ // 응답 // 콜백 처리 callback(xhr.responseText); } } xhr.open('GET', url, true); xhr.send(null); }
위와 같이 만들었을때 사용하는 방법은 다음과 같다.
scrap_page('day-think.tumblr.com', function(txt){ console.log(txt); });
이를 크롬 개발자 도구로 실행시켜보면 다음과 같다.

0 notes
Text
R언어 Vector
Vectors
가장 기초적인 데이터타입중 하나이다. C 계열의 언어와는 다르게 Scalar로 불리는 독립적인 숫자 타입이 없다. 단지 특수한 벡터의 형태로 나타난다. Matrices 는 벡터의 특별한 케이스이다. 다음과 같이 몇가지 주요한 용어가 있다.
Recycling : 자동으로 벡터의 길이조정을 한다.
Filtering : 벡터의 서브셋을 추출한다.
Vectorization : 함수를 벡터의 각요소에 적용시킨다.
Scalar, Vectors, Arrays and Matrices
몇번이나 강조하고 있지만 R에서 number는 사실은 one-element vectors 라고 한다. 벡터타입인데 원소가 한개짜리라는 것이다. R에서 변수타입을 부르는 명칭은 mode 이다. 그리고 벡터에서 모든 Elements는 같은 mode를 지난다. integer, numeric(floating-point number), character(string), logical, complex 등등… 만약 변수 x의 타입을 검사하고 싶다면 typeof(x) 이라고 쓰면 된다.
벡터는 원소를 insert 하거나 delete 할수 없다. 벡터의 크기는 생성될때 결정되며 당신이 추가하거나 삭제하고 싶다면 reassign 해라
x <- c(88, 5, 12, 13) x <- c(x[1:3], 168, x[4]) x
## [1] 88 5 12 168 13
vector는 length() 함수를 사용할수 있다.
length(x)
## [1] 5
# loop 에 응용하여 1이 나올때까지의 벡터의 길이를 구하는 예제를 생각하자 first_1 <- function(x){ for(i in 1:length(x)){ if(x[i] == 1) break; # break out of loop } return (i) }
for (n in x) print(n)
## [1] 88 ## [1] 5 ## [1] 12 ## [1] 168 ## [1] 13
위와 같이 in 키워드를 이용하여 각 원소자체에 대해 접근하면 index를 알수 없으므로 1:length(x) 와 같은 방식으로 리스트를 구한 것이다.
그리고 length(x) 가 0이 되는 것을 조심하여야 한다.
x <- c() x
## NULL
length(x)
## [1] 0
1:length(x) # 1 에서 0까지 숫자1개 차이로
## [1] 1 0
위와 같은 문제는 : 같은 표현식이 1씩 차이나도록 원소를 강제로 생성하기 때문이다. 그래서 이를 해결하기 위해 R 함수에 seq라는 함수를 새로 만들었다.
x <- c(2, 4, 8) x
## [1] 2 4 8
seq(x)
## [1] 1 2 3
x <- NULL x
## NULL
seq(x)
## integer(0)
결국 seq(x) 는 1:length(x) 와 똑같은 결과를 가져온다. 다만 x가 NULL일때는 주의
반복을 하기 위해서는 rep(x, times)를 쓴다.
x <- rep(8, 4) x
## [1] 8 8 8 8
rep(1:5, 5)
## [1] 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
rep(c(5, 12, 99), each = 3)
## [1] 5 5 5 12 12 12 99 99 99
each라고 named 파라미터를 주게되면 원소에대해 반복한다.
all() and any()
이 함수들은 TRUE 혹은 FALSE를 리턴하는 함수들이다. 예제를 보면 다음과 같다.
x <- 1:10 x > 8 # 모든 원소에 대해서 결과가 각각 적용됨 Vectorization
## [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE
any(x > 8) # 어떤 value값이 TRUE이면 TRUE
## [1] TRUE
all(x > 8) # 모든 value값이 TRUE이면 TRUE
## [1] FALSE
이를 이용하�� 0 과 1로 이루어진 수열 x에서 k개 만큼 1이 연속으로 나타나는 부분 수열의 위치를 찾는 함수를 만들어 보자
find_consecutive <- function(x, k) { n <- length(x) runs <- NULL for (i in 1:(n - k + 1)) { if (all(x[i:(i + k - 1)] == 1)) runs <- c(runs, i) } return(runs) } y <- c(1, 0, 0, 1, 1, 1, 0, 1, 1) find_consecutive(y, 3) # 1이 세번 연속되는 부분수열 위치
## [1] 4
find_consecutive(y, 2) # 1이 두번 연속되는 부분수열 위치
## [1] 4 5 8
find_consecutive(y, 1) # 1이 한번 연속되는 부분수열 위치
## [1] 1 4 5 6 8 9
Predicting Discrete-Valued Time Series
0과 1의 이산적인 데이터가 존재하는 시계열이 있다. 매일발생하는 날씨 데이터를 가정해본다. 1이 비가 내리는 것을 표현하고 0이 비가 안오는것을 표현하는 시계열을 생각해볼수 있는것이다.
우리가 내일 비가내릴수 있는지 예측하기 위해
최근 비가 왔는지 안왔는지에 따라 결정된다는 가정을 세우자.
직전 k 번중 1의 개수가 k/2 이상이면 다음 값을 1로 예측한다.
k를 어떻게 선택할 것인가? 값이 너무 작으면 예측을 하기 위한 샘플이 너무 작다. 그렇다고 너무 값이 크면 너무 과거의 데이터에도 의존을 하게 된다.
이미 알고 있는 데이터에 대해 이러한 문제를 해결하기 위한 일반적인 방식은 k의 값을 다양하게 하여 데이터를 살펴보는 training set 이라고도 불리는 방법이다. k값을 3으로 두고 “예측"을 수행한다. 500일에 이르는 데이터에 대해서 한번 수행하고 나면 우리는 k=3일 경우의 error rate 를 알게 된다. 이를 k=1, k=2, k=4 일때 등등 각각 수행하여 적당한 k값에 이를때까지 반복한다. 예측변수값으로서 가장 적당한 k값을 선택할수 있을 것이다.
preda <- function(x, k) { n <- length(x) k2 <- k/2 # vector의 크기를 잡는다. pred <- vector(length = n - k) # 예측을 수행함 for (i in 1:(n - k)) { if (sum(x[i:(i + (k - 1))]) >= k2) pred[i] <- 1 else pred[i] <- 0 } # 에러율을 구함 return(mean(abs(pred - x[(k + 1):n]))) } preda(c(0, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1), 3)
## [1] 0.5385
pred 는 n-k 만큼 즉 첫째원소부터 샘플개수를 제외한 나머지 크기에 대한 데이터의 예측을 담는다. 이 예측치는 k+1번째에 기록하므로 결국 에러율을 구하려면 k+1 번째부터 n개 까지의 원소와 빼어 차이가 얼마나 나는지 보면 된다. 이 데이터는 이산적임을 가정하므로 만일 맞췄다면 0이지만 틀렸으면 1 혹은 -1 이므로 절대값을 구하면 결국 에러의 벡터가 된다. 에러의 벡터 자체도 0과 1로만 이루어져 있어 이들의 평균을 구하면 1이 가지는 비율이 나오게 되고 이게 바로 에러율이다. 일반적으로 쓰이는 R의 Trick 이란다….
mypreda <- function(x) { return(preda(c(0, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1), x)) } sapply(1:10, mypreda)
## [1] 0.4643 0.5185 0.5385 0.5200 0.5833 0.6087 0.5455 0.4762 0.5000 0.5263
임의의 series를 작성하고 k값을 1부터 10까지 대입하여 값들을 알아보았다. 웃기게도 k값이 1일때 좀 낫다 즉 '전날 비가 왔으니까 낼도 오겠지' , '전날 비가 안왔으니 내일도 안옴 ㅋㅋ' 인 것이다.
위 예제를 이 책에서 보여주는 이유는 적용방법에 대한것이라기 보다는 cumsum() 함수를 알려주기 위함인것 같다. ( cumulative sum ) 위 로직은 직관적이지만 sum함수를 사용할시 잘 생각해보면 k값에 의해 이미 sum값이 계산된 상황에서 또다시 계산하는 비효율적인 면을 보여주고 있다. k값이 3 과 같이 작다면야 아무상관 없지만 늘어나면 늘어날수록 필요없는 계산량이 많아진다. 따라서 cumsum() 함수를 사용한다.
preda <- function(x, k) { n <- length(x) k2 <- k/2 # vector의 크기를 잡는다. pred <- vector(length = n - k) csx <- c(0, cumsum(x)) # 예측을 수행함 for (i in 1:(n - k)) { if (csx[i + k] - csx[i] >= k2) pred[i] <- 1 else pred[i] <- 0 } # 에러율을 구함 return(mean(abs(pred - x[(k + 1):n]))) }
i+k 까지의 누적값에서 i까지의 누적값을 빼면 결국은 i에서부터 k개 사이의 합을 구하는 것이므로 마찬가지 효과가 발생한다. 누적값은 O(n) 에 계산되리라 예상할수 있으니 계산량이 상당히 줄게 되었다.
Vectorized Operations
vector의 모든 엘레먼트에 적용시키면서 매우 빠르게 동작할수 있게 하는 방법이다.
operator를 생각해보자. + 혹은 - 아니면 > 가 이전에 나왔었던 예제이다.
u <- c(5, 2, 8) v <- c(1, 3, 9) u > v
## [1] TRUE FALSE FALSE
포인트는 R의 함수들은 vectorized operations을 사용한다는 것이다. 연산자 자체부터가 각 원소에 적용되므로 함수도 vectorized된다. 그리고 이건 성능을 향상시킨다.
w <- function(x) { return(x + 1) } w(u)
## [1] 6 3 9
대표적인 초월함수들 square root, logs, trig functions 등등을 예로 들어보자
sqrt(1:9)
## [1] 1.000 1.414 1.732 2.000 2.236 2.449 2.646 2.828 3.000
rounding 도 해보자
y <- c(1.2, 3.14, 0.7) z <- round(y) z
## [1] 1 3 1
y <- c(12, 5, 13) y + 4
## [1] 16 9 17
그렇다면 두개의 벡터를 인자로 받는 함수안에서 operation을 하면 어떻게 될까
f <- function(x, c) return((x + c)^2) f(1:3, 1) # 길이가 1인 벡터를 Scalar 취급한다.
## [1] 4 9 16
f(1:3, 1:3) # 같은 길이의 벡터끼리 연산
## [1] 4 16 36
Vector In, Matrix Out
벡터를 input 하여 Matrix 를 뽑아내어 보자 z12() 라는 함수를 새로 정의한다.
z12 <- function(z) return(c(z, z^2)) x <- 1:8 z12(x)
## [1] 1 2 3 4 5 6 7 8 1 4 9 16 25 36 49 64
이렇게 하면 두개의 벡터를 연결하여 한줄로 길게 늘여버린다. 따라서 보기 좋게 하기위해 matrix() 함수를 이용해본다.
matrix(z12(x), ncol = 2)
## [,1] [,2] ## [1,] 1 1 ## [2,] 2 4 ## [3,] 3 9 ## [4,] 4 16 ## [5,] 5 25 ## [6,] 6 36 ## [7,] 7 49 ## [8,] 8 64
이를 간소화하기 위해 sapply(x, f) 라는 함수를 이용한다. 이는 function f를 x벡터의 각 요소에 적용하여 결과를 matrix 로 뽑아낸다.
z12 <- function(z) return(c(z, z^2)) sapply(1:8, z12)
## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] ## [1,] 1 2 3 4 5 6 7 8 ## [2,] 1 4 9 16 25 36 49 64
이는 위와는 다르게 8 by 2 matrix 가 된다.
NA and NULL values
python 하면 None 이라는 값이 있고, 자바스크립트 같은 경우 undefined 라는 값이 있을것이다. R에서는 두가지의 값을 가지고 있는데 NA 와 NULL 이다. 통계 데이터에서 NA는 missing data (적절한 한국말 뭐지) 이지만 NULL은 존재하지 않음을 나타낸다. NA는 존재할수 있는 값이지만 알지 못하는 값이다.
R의 많은 통계함수들이 NA값을 Skip 하도록 지정할수 있게 되어 있다.
x <- c(88, NA, 12, 168, 13) # NA일 경우 x
## [1] 88 NA 12 168 13
mean(x)
## [1] NA
mean(x, na.rm = T)
## [1] 70.25
x <- c(88, NULL, 12, 168, 13) # NULL일경우 mean(x)
## [1] 70.25
u <- NULL length(u)
## [1] 0
v <- NA length(v)
## [1] 1
NULL은 mode 가 없는 특수한 R의 오브젝트이다.
Filtering
R언어에서 함수형언어 패러다임을 반영하고 있는것 중에 하나는 filtering 이다. 특정한 조건을 만족하는 원소들만 추출할수 있다는 뜻이다. 통계분석은 흥미가 있는 조건을 만족하는 데이터에 초점을 두기 때문에 Filtering 은 R언어에서 가장 자주 쓰이는 것중에 하나이다.
z <- c(5, 2, -3, 8) w <- z[z * z > 8] w
## [1] 5 -3 8
위 예제를 보면 python의 list comprehension이 떠오른다. 형태가 좀 비슷하다.
위 예의 원리를 좀더 자세히 알아보면 다음과 같다.
z <- c(5, 2, -3, 8) z
## [1] 5 2 -3 8
z * z > 8
## [1] TRUE FALSE TRUE TRUE
표현식인 z*z > 8 은 Boolean Vector의 결과를 내준다. 모든것은 벡터와 벡터연산자임을 기억하면
z가 벡터라면 z * z도 같은 길이를 지닌 벡터일것이다.
recycling 때문에 number 8 (길이가 1인 벡터) 은 (8,8,8,8) 과 같은 벡터로 될것이다.
연산자인 > 이것은 + 와 마찬가지로 실제로는 함수
(2 > 1) #
## [1] TRUE
(2 > 5) #
## [1] FALSE
(z * z > 8) # 실제로는 이렇게 호출되는것과 마찬가지
## [1] TRUE FALSE TRUE TRUE
z[c(TRUE, FALSE, TRUE, TRUE)]
## [1] 5 -3 8
또다른 예제를 알아보자
x <- c(1, 3, 8, 2, 20) x[x > 3] <- 0 x
## [1] 1 3 0 2 0
subset() 함수를 이용하면 NA 값을 제외시킬수 있다.
x <- c(6, 13, 1:5, NA, 12) x[x > 5] # x[8] is unknown, so it's also unknown whether its square is greater than 5
## [1] 6 13 NA 12
subset(x, x > 5)
## [1] 6 13 12
어쩌면 특정조건을 만족하는 원소의 위치(which??ㅋ)가 궁금할수 있을수도 있다. 이럴때는 which() 함수를 이용한다.
x <- c(6, 13, 1:5, NA, 12) which(x * x > 8)
## [1] 1 2 5 6 7 9
Vectorized if-then-else The ifelse() function
Vectorized된 버젼의 if-else가 함수 로 존재한다.
if(b,u,v)
로서 b 는 boolean, u와 v는 벡터이다.
x <- 1:10 y <- ifelse(x%%2 == 0, 5, 12) y
## [1] 12 5 12 5 12 5 12 5 12 5
if-then-else 보다 vectorized된 ifelse()함수가 훨씬 빠르다고 한다.
Testing Vector Equality
naive한 방식으로는 == 를 사용하는 방식이 있다.
x <- 1:3 y <- c(1, 3, 4) x == y
## [1] TRUE FALSE FALSE
== 도 vectorized function 이다. 그래서 각 원소끼리만 비교하기만 하니 Equality 한지 확인이 안된다. 그렇다면 앞서 알아본 all() 함수를 이용할수 있다.
x <- 1:3 y <- c(1, 3, 4) all(x == y)
## [1] FALSE
이와 똑같은 역할을 하는 함수로 identical() 함수가 있다.
x <- 1:3 y <- c(1, 3, 4) identical(x, y)
## [1] FALSE
x <- 1:2 y <- c(1, 2) x
## [1] 1 2
y
## [1] 1 2
identical(x, y) # 조심해야한다.
## [1] FALSE
typeof(x) # 타입이 다름
## [1] "integer"
typeof(y) # 타입이 다름
## [1] "double"
Vector element에 이름 붙이기
x <- c(1, 2, 4) names(x)
## NULL
names(x) <- c("f", "s", "t") names(x)
## [1] "f" "s" "t"
x
## f s t ## 1 2 4
x["s"] # 이름으로
## s ## 2
0 notes
Text
R overview
The Art of R Programming
The Art of 스리즈 중 R언어에 대한 내용인것 같다. R Cookbook 한글판 책을 샀지만 언어 자체를 연구하려는 나에게는 이 책이 더 나은듯 싶다.
따라서 조금씩 조금씩 예제를 직접 따라하면서 생기는 궁금증과 이를 해소하면서 적어두는 메모 같은 형식으로 이 문서를 작성하고자 한다.
Assignment
대입연산자는 어떤 프로그래밍 언어에서도 중요한 기초중의 기초이다. R 에서는 <- 을 쓴다. 이를 Standard assignment Operator 라고 부른다.
이책에서는 = 이것도 쓸수 있지만 타입이 변경되는 문제 때문에 별로 추천하지는 않는다고 되어 있다.
x <- c(1, 2, 3) q <- c(x, x, 8) print(q)
## [1] 1 2 3 1 2 3 8
위 예제에서 나오는 c() 함수는 Concatenate 라고 한다. concat 의 이름으로 여러 프로그래밍 언어에서 String 과 관련하여 문자열 연결하는 함수로 많이 쓰이는데 R에서는 Vector 를 연결해 같다 붙이는 용도로 쓰는것 같다.
Index
첨자 혹은 인덱스는 대부분의 프로그래밍 언어가 지원하는 배열에 접근하는 방식과 유사하다.
print(x[3])
## [1] 3
print(q[4:7])
## [1] 1 2 3 8
아 참고로 ALGOL계열 프로그래밍 언어와는 다르게 인덱스가 1에서부터 시작한다. (0이 아님..) 그래서 슈도코드를 옮기기 편하겠다는 생각이 들었다. 어쨋든 3:7 이런식으로 3번째에서 7번째까지 엘레먼트를 가진 subvector 인 것이다. 이부분은 Python 의 List에서 개념을 많이 따온것이 아닐까 생각했다.
내장데이터셋
R에서는 기본 내장 데이터셋을 지원한다고 한다. 책에서 보여주는 예제가 있다.
summary(Nile)
## Min. 1st Qu. Median Mean 3rd Qu. Max. ## 456 798 894 919 1030 1370
hist(Nile)
mean(Nile) #평균
## [1] 919.4
sd(Nile) # Standard deviation 표준편차
## [1] 169.2
Nile 이란것은 데이터셋인 것이다. 위 예제에서 재밌는 기능은 hist 이다. 바로 Histogram 으로 데이터를 보여준다.
function 정의
functional한 부분을 지원하는 언어가 세련된 것처럼 여겨지는 요즘 R언어에서 당연히 Lambda개념과 객체취급을 하는것 같다. function 이라는 키워드를 써주어야 하는 것은 Javascript 언어와 비슷하다.
evencount <- function(x) { k <- 0 # assign init value for (n in x) { if (n%%2 == 0) { k <- k + 1 } } return(k) } print(evencount(c(0, 2, 4, 5, 6, 7, 8)))
## [1] 5
그리고 Default Arguments 도 된다. 예를 들면 다음과 같다
g <- function(x, y = 2, z = 3) { return(x + y + z) } print(g(5)) # 위치로 지정
## [1] 10
print(g(x = 5, z = 2)) # 이름으로 지정
## [1] 9
인자가 들어가지 않았을 경우 기본값으로 지정하는 기능이다. 특히 이름을 명시하고 값을 넣는다면 위치랑 상관없이 넣을수 있다. y 가 먼저 옴에도 불구하고 z를 명시하여 호출한 예제를 보면 알수 있다.
Data Structures
통계를 위해 쓰이는 R언어와 같은 특수목적용 언어들은 자체 내장하는 어떠한 자료구조들이 있는 경우가 있다. R에서는 여러가지 자료구조들을 지닌다.
Vector
벡터타입은 R언어에서 가장 중요하다가 책에서 강조한다. 벡터의 Elements 들은 반드시 같은 모드 혹은 같은 데이터타입이여야 한다
Scalar 값은 R언어에서는 없고.. 단지 1개의 원소를 지니는 벡터로 해석된다.
x <- 8 print(x)
## [1] 8
특히 interactive shell 에서 보이는 [1] 과 같은 것들은 row of number 이다. 즉 인덱스이다. 위에서 살펴봤듯이 1에서부터 시작하기 때문에 [1]이라고 적혀있는 것이다.
character Strings
문자열은 사실 한개의 원소를 지닌 캐릭터모드의 벡터이다.
x <- c(5, 12, 13) print(x)
## [1] 5 12 13
mode(x)
## [1] "numeric"
length(x)
## [1] 3
y <- "abcdefg" print(y)
## [1] "abcdefg"
mode(y)
## [1] "character"
length(y)
## [1] 1
R언어에서는 통계를 위한 언어와 패키지를 지니고 있으므로 다른 언어들에 비해 문자열을 가지고 노는 부분이 많이 딸린다고 한다. 하지만 분명 문자열을 다뤄야할 부분이 생기기 때문에 우선 문자열을 다루는 간단한 함수 몇개를 보자
s <- paste("show", "me", "the", "money") print(s)
## [1] "show me the money"
v <- strsplit(s, " ") # 분리할 문자열 분리기준문자(공백) print(v)
## [[1]] ## [1] "show" "me" "the" "money"
위 예제에서 보면 [[1]]이런식으로 보이는데 잘 생각해보면 분리한 문자열들의 나열인 벡터를 여러개를 지니는 벡터 즉 벡터를 감싸는 벡터인 뜻인것 같다.
Matrices
R의 Matrix는 기술적으로 벡터이다. 두개의 부가적인 속성이 더해진다. The number of rows , the number of columns 이다. 여기에 몇개 Matrix 샘플코드가 있다.
m <- rbind(c(1, 4), c(2, 2)) print(m)
## [,1] [,2] ## [1,] 1 4 ## [2,] 2 2
print(m %*% c(1, 1))
## [,1] ## [1,] 5 ## [2,] 4
m[1, ] # row 1
## [1] 1 4
m[, 2] # col 2
## [1] 4 2
Lists
R의 Vector와 비슷하지만 Lists는 다른타입의 아이템들도 포함시킬수 있다. 엘레멘트에 Access 하려면 $ 기호를 이용한다.
x <- list(u = 2, v = "abc") x$u
## [1] 2
x$v
## [1] "abc"
print(x$u)
## [1] 2
hn <- hist(Nile) # 값을 반환한다.
str(hn) # str 을 이용하여 출력
## List of 7 ## $ breaks : num [1:11] 400 500 600 700 800 900 1000 1100 1200 1300 ... ## $ counts : int [1:10] 1 0 5 20 25 19 12 11 6 1 ## $ intensities: num [1:10] 0.0001 0 0.0005 0.002 0.0025 0.0019 0.0012 0.0011 0.0006 0.0001 ## $ density : num [1:10] 0.0001 0 0.0005 0.002 0.0025 0.0019 0.0012 0.0011 0.0006 0.0001 ## $ mids : num [1:10] 450 550 650 750 850 950 1050 1150 1250 1350 ## $ xname : chr "Nile" ## $ equidist : logi TRUE ## - attr(*, "class")= chr "histogram"
List의 일반적인 사용은 function의 리턴값으로 상이한 타입의 값을 보낼때 사용한다.
Data Frames
matrix 처럼 사용하지만 타입을 섞어서 사용하려 할때 사용한다.
d <- data.frame(list(kids = c("Lhw", "Hjy"), ages = c(30, 30))) d
## kids ages ## 1 Lhw 30 ## 2 Hjy 30
리스트로 data frame 을 생성하였으므로 해당 열을 사용하려면 리스트 첨자연산으로 하면 된다.
도움말 및 예제
도움말이 함수로 내장되어 있어서 편리하다.
help(seq) # 도움말 보기 `?`(seq # 단축키 ) # 몇개 단어들은 쌍따옴표로 적도록 예약되어 있다. `?`("<") `?`("for")
더 대박인 기능은 바로 example() 함수이다. 예제를 보여주어 사용하는 법을 알려준다.
example(seq)
## ## seq> seq(0, 1, length.out = 11) ## [1] 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 ## ## seq> seq(stats::rnorm(20)) # effectively 'along' ## [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ## ## seq> seq(1, 9, by = 2) # matches 'end' ## [1] 1 3 5 7 9 ## ## seq> seq(1, 9, by = pi) # stays below 'end' ## [1] 1.000 4.142 7.283 ## ## seq> seq(1, 6, by = 3) ## [1] 1 4 ## ## seq> seq(1.575, 5.125, by = 0.05) ## [1] 1.575 1.625 1.675 1.725 1.775 1.825 1.875 1.925 1.975 2.025 2.075 ## [12] 2.125 2.175 2.225 2.275 2.325 2.375 2.425 2.475 2.525 2.575 2.625 ## [23] 2.675 2.725 2.775 2.825 2.875 2.925 2.975 3.025 3.075 3.125 3.175 ## [34] 3.225 3.275 3.325 3.375 3.425 3.475 3.525 3.575 3.625 3.675 3.725 ## [45] 3.775 3.825 3.875 3.925 3.975 4.025 4.075 4.125 4.175 4.225 4.275 ## [56] 4.325 4.375 4.425 4.475 4.525 4.575 4.625 4.675 4.725 4.775 4.825 ## [67] 4.875 4.925 4.975 5.025 5.075 5.125 ## ## seq> seq(17) # same as 1:17, or even better seq_len(17) ## [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
0 notes
Text
카톡봇과 멀티스레딩
카카오톡 프로토콜을 분석한 대단하신 분들이 있고 이를 파이썬으로 라이브러리 화 하여 제공되고 있다. 실생활에 유용하게 혹은 재미를 위해 쓰일수도 있을테지만 악의적 목적으로도 쓰일 가능성이 다분하기도 해 조심스럽다. 이 포스팅은 해당 라이브러리 사용하는 법보다는 봇 설계시 구축한 멀티스레드 모델에 관한 포스팅에 더 가깝다.
파이썬은 GIL때문인지 뭔진 잘 모르겠지만 I/O Bound 작업이 아닌이상 Thread를 잘 사용하지 않는 경향인것 같다. 카톡 라이브러리에서는 소켓을 블로킹 모드로 사용하므로 이러한 경우에 아주 적합한 것 같다.
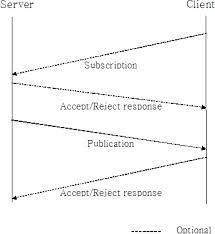
라이브러리 전부를 뜯어본건 아니지만 이를 활용해서 프로그램을 만든다면 구조는 메시지가 들어오면 그에대한 응답을 하고 다시 대기하는 구조가 될것이다. 이러한 흐름을 보일것이다?
하지만 카톡수신 대기하면서 동시에 웹 크롤링을 해서 정보를 알려주거나 정해진 시간이 되면 특정채팅방의 통계를 낸다던가 하는 작업도 하면 유용할 것이다. 이러한 멀티스레딩 작업을 구조화시키면 이후 여러 기능이 추가되더라도 편하게 작업할 수 있을 것 같아 따른 모델은 생산자-소비자 모델이다.
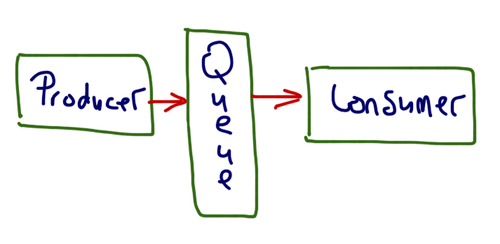


생산자-소비자 모델을 설명하는 그림을 검색하면 아주 많이 나온다.
대략적으로 그림만 봐도 어떤 개념인지 알것 같다. 그러면 파이썬 코드를 보면 다음과 같다.
import threading import Queue queue = Queue.Queue() class Producer(threading.Thread): def run(self): global queue # loop while True: # gen product product = 'product' queue.put(dat) #time interval class Consumer(threading.Thread): def run(self): global queue # loop while True: product = queue.get() # do anything #time interval producer = Producer() consumer = Consumer() producer.start() consumer.start()
만일 위를 카톡봇에 적용시킨다면 어떻게 될까? Producer는 카톡으로부터 수신을 기다리는 스레드가 될것이고 Consumer는 카톡으로 어떤 action을 취하는 스레드가 될것이다. 저기에 또다른 Producer가 만들어져서 웹 스크래핑을 한다던가 타임스케줄러 같이 정해진 시간을 체크한다던가 하는 작업을 하게 하면 될것이다.
실제 봇 코드는 위 구조를 충실히 따르고 있다.
class KakaoWriter(threading.Thread): def run(self): global kakao global queue logging.info('===== Start Writer =====') # FSM style loop while is_run.is_set(): try: if queue.empty() == True: pass else: # got data logging.info('[writer] --- got from queue ---') dat = queue.get() # 로직 시작 self.bot1(dat) self.bot2(dat) self.bot3(dat) time.sleep(.1) except Exception, e: logging.info('[writer] unexpected error') logging.info('[writer] %s'%repr(e)) logging.info('===== END Writer =====')
Consumer 역할을 하는 스레드객체이다.
class KakaoReader(threading.Thread): def run(self): global kakao global queue if kakao.login(): logging.info('===== Start Reader =====') # Read Message Loop while is_run.is_set(): # 패킷수신 if not packet: # 소켓이 lib안에서 닫힘 # 처리 continue # 메세지 도착시 if packet['command'] == 'MSG': logging.info('got message..') dat = KakaoData( packet['body']['chatLog']['chatId' ], packet['body']['chatLog']['msgId' ], packet['body']['chatLog']['sendAt' ], packet['body']['chatLog']['logId' ], packet['body']['chatLog']['authorId'], packet['body']['authorNickname'], packet['body']['chatLog']['message' ], 'CHAT') queue.put(dat) # Queue 에 넣는다. self.insertDB(dat)# DB에 기록한다. logging.info('===== End Reader =====')
위 객체는 Producer 중에 카톡 메시지 데이터를 수신하는 스레드인 것이다. 여기에 시간 스케줄러 혹은 웹 크롤링 등도 넣으면 될것 같다.
threading 모듈은 스레드를 객체지향적으로 다룰수 있다는 점에서 좋다. 구조화된 모양으로 컨셉을 유지하면서 로직을 계속 늘려갈수 있는 구조를 쉽게 만들어 낼수 있는것 같다.
위 사항을 구현하면서 여러가지 문제에 부딪치고 해결하는 과정에서 있을 법한 내용이 몇개가 있다.
카카오톡 수신스레드가 수신하고 있는 도중에 다른 스레드가 카카오톡 write 메서드를 사용할시 에러
키보드 인터럽트로 모든 스레드 종료시킬시 소켓을 블로킹으로 열었던 수신스레드 대기 문제
소켓 수신시 타임아웃 문제 (새벽)
위 문제들은 쉽게 생각하면 바로 해결되는 것 같다. 1번은 적어도 라이브러리를 까봐야 안다.

위 사항을 구현하여 만든 카톡봇 기능 일부중 재촉하는 기능을 보이며 마친다.
2 notes
·
View notes
Text
들로네 삼각화
들로네 삼각형은 평면위의 점들을 삼각형으로 분할했을때 모든 내각의 합이 최소가 되도록 하는 분할을 말한다. 이에 대한 응용은 여러가지가 있을 것이다. 이는 들로네삼각형를 참조하면 응용에 대해서 자세히 나온다.
이를 자바스크립트로 구현하고자 한다. 참고한 알고리즘은 O(n^2)로 동작하는 알고리즘으로서 세점의 외접원을 이용하는 알고리즘이다. 실제로는 O(n log n) 시간복잡도인 알고리즘도 나와있지만 incremental 방식의 한 종류로서 시각화하기 적당한 알고리즘으로 선택하였다.
간단하게 알고리즘을 기술하면
임의의 점을 기준으로 최소 길이를 지닌 Edge 하나를 찾는다.
선택한 Edge를 CE(후보Edge집합)에 넣는다.
CE에서 Edge 하나를 꺼내 선택한다. 비어있다면 알고리즘 종료
CCW(시계반대방향조건) 만족하는 점 하나를 선택하여 임의의 삼각형을 만든다.
삼각형의 외접원을 구한다.
CCW를 만족하는 다른 점이 원 속에 포함되는지 검사한다. 포함된다면 4번으로 돌아간다.
마지막으로 선택된 점과 선택된Edge의 두점을 잇는 새로운 네개의 Edge가 있다 (시계방향, 시계반대방향)
시계방향의 Edge들은 CE에 넣고 시계반대방향의 Edge들은 DE(완료Edge집합)에 넣는다. 그리고 선택한 Edge도 DE에 넣는다.
선택된 점이 없다면 3번으로 돌아간다.
즉 외접원이 핵심인데 어떠한 점도 외접원안에 포함되지 않는다면 그것이 바로 내각이 최소화 되는 모양일 것이다. DE(완료Edge집합) 가 완성된 들로네 삼각화 그래프이다. 아래는 완성된 모습이다. HTML5 의 canvas tag를 이용하여 만들었다. 보이지 않는다면 크롬 브라우져로 보면 된다. 모든소스는 직접 작성하였으며 풀소스가 궁금하면 소스보기로 보면된다. 라이센스는 따로 표시되어 있지 않으나 MIT License
var dcanvas1 = document.querySelector('#delaunay'); dcanvas1.style.backgroundColor = '#272822'; function AssaDelaunayN2(canvasElem, width, height){ this.canvas = canvasElem || document.createElement('canvas'); this.canvas.width = width || 600; this.canvas.height= height || 480; var ctx = this.canvas.getContext('2d'); var width = this.canvas.width; var height = this.canvas.height; // 반시계방향 테스트 // ccw > 0 : counter clockwise // ccw < 0 : clockwise // ccw = 0 : on the line function ccwTest(x1,y1,x2,y2,x3,y3){ return (x1*y2 + x2*y3 + x3*y1) - (y1*x2 + y2*x3 + y3*x1); } // 세점을 지나는 원구하기 // 1. 두 변을 기준으로 중점을 구한다. // 2. 해당변과 수직인 기울기를 구한다. // 3. 중점과 기울기를 이용 두 직선을 구한뒤 교점을 구한다. var _cx, _cy, _cr; // output!, for performance function get3PointCircle(x1,y1,x2,y2,x3,y3){ _cx = _cy = _cr = 0.0; var mx1 = (x2 + x1) / 2; // mid of x1~x2 var my1 = (y2 + y1) / 2; // mid of y1~y2 var mx2 = (x2 + x3) / 2; var my2 = (y2 + y3) / 2; var deltay_e1 = y2 - y1; var deltay_e2 = y2 - y3; var d1, d2, yy; if(deltay_e1 != 0){ d1 = (x1 - x2) / deltay_e1; yy = my1 - d1 * mx1; if(deltay_e2 != 0){ d2 = (x3 - x2) / deltay_e2; if( d1 != d2 ){ _cx = (yy - (my2 - d2 * mx2)) / (d2 - d1); }else{ return ; // exception } } else if(x3 - x2 == 0){ return ; // exception } else { _cx = mx2; } }else if(deltay_e2 != 0 && x1 - x2 != 0){ d1 = (x3 - x2) / deltay_e2; yy = my2 - d1 * mx2; _cx = mx2; }else{ return ; // exception } _cy = d1 * _cx + yy; _cr = Math.sqrt((x1-_cx)*(x1-_cx) + (y1-_cy)*(y1-_cy)); } this._draw3PointsCircle = function(x1,y1,x2,y2,x3,y3){ get3PointCircle(x1,y1,x2,y2,x3,y3); drawCircle(_cx, _cy, _cr, '#ffa0a0'); drawPoint(x1,y1,3); drawPoint(x2,y2,3); drawPoint(x3,y3,3); }; // 원안에 점이 존재하는지 테스트 // 의존성 get3PointCircle 이 선행 function inCircleTest(p){ var lenx = p.x - _cx; var leny = p.y - _cy; return (lenx*lenx + leny*leny) < _cr*_cr; } function getLen(x1, y1, x2, y2){ var dx = x1 - x2; var dy = y1 - y2; return Math.sqrt(dx*dx + dy*dy); } // sets this.points = []; this.edges = []; // 점 객체 function Point(x, y){ this.x = x || 0; this.y = y || 0; this.edges = []; this.selected = false; } // 간선객체 (방향성) function Edge(p1, p2){ this.sp = p1 || new Point(0,0); // start point this.ep = p2 || new Point(width, height); // end point } this.genRandomPoints = function(n){ this.points = []; for(var i=0; i < n; i++){ this.points.push( new Point(width * Math.random(), height * Math.random()) ); } } this._drawPoints = function(){ for(var i=0; i < this.points.length; i++){ var p = this.points[i]; drawPoint(p.x, p.y, 3); } } this._draw_ccw_test = function(n1, n2){ var o1 = this.points[n1]; var o2 = this.points[n2]; drawLine(o1.x, o1.y, o2.x, o2.y); for(var i=0; i < this.points.length; i++){ var p = this.points[i]; if(i == n1 || i == n2) { drawPoint(p.x, p.y, 3, '#ffa0a0'); continue; }else{ if(ccwTest(o1.x, o1.y, o2.x, o2.y, p.x, p.y) > 0){ drawPoint(p.x, p.y, 3, '#87ceeb'); } } } } // draw functions function drawLine(x1,y1,x2,y2, color){ ctx.beginPath(); ctx.moveTo(x1, y1); ctx.lineTo(x2, y2); ctx.strokeStyle = color || '#fff'; ctx.stroke(); ctx.closePath(); } function drawPoint(x,y,r,color){ ctx.beginPath(); ctx.arc(x,y,r,0,2*Math.PI, false); ctx.fillStyle = color || '#fff'; ctx.fill(); ctx.closePath(); } function drawCircle(x,y,r,color){ ctx.beginPath(); ctx.arc(x,y,r,0,2*Math.PI, false); ctx.strokeStyle = color || '#fff'; ctx.stroke(); ctx.closePath(); } this.drawEdges = function(color){ for(var i=0; i < this.edges.length; i++){ var edge = this.edges[i]; drawLine( edge.sp.x , edge.sp.y , edge.ep.x , edge.ep.y , color || 'rgba(127,127,127,0.3)' ); } } // #98fb98 : green 계열 // #87ceeb : blue계열 // #ffa0a0 : red 계열 // #f0e68c : yellow 계열 // delaunay algorithm O(n^2) this.getDelaunay = function(){ var candEdges = []; var selfEdges = this.edges; function isExistEdge(sp, ep){ var ret = false; for(var i=0; i < selfEdges.length; i++){ var edge = selfEdges[i]; if(edge.sp.x == sp.x && edge.sp.y == sp.y && edge.ep.x == ep.x && edge.ep.y == ep.y){ ret = true; } } return ret; } // 1. 임의의 점을 기준으로 최소의 길이를 지니는 Edge를 찾아낸다. O(n) var minLen = getLen(this.points[0].x, this.points[0].y , this.points[1].x, this.points[1].y); var sPointIdx = 0; var ePointIdx = 1; for(var i=2; i < this.points.length; i++){ var len = getLen(this.points[sPointIdx].x, this.points[sPointIdx].y, this.points[i].x, this.points[i].y); if(minLen > len){ ePointIdx = i; minLen = len; } } // 첫 Edge는 양방향 candEdges.push(new Edge( this.points[sPointIdx], this.points[ePointIdx] )); candEdges.push(new Edge( this.points[ePointIdx], this.points[sPointIdx] )); // 2. 후보 Edge 집합이 전부 소모될때까지 수행 while(candEdges.length != 0){ var peeked_edge = candEdges.shift(); // queue 처럼 사용 var selected_point = null; // 외접원이 있을때 내부에 다른점이 포함되지 않는 점을 구한다. for(var i=0; i < this.points.length; i++){ var p = this.points[i]; if(p.x != peeked_edge.sp.x && p.y != peeked_edge.sp.y && p.y != peeked_edge.ep.x && p.y != peeked_edge.ep.y){ // pass }else{ continue; } if(ccwTest(peeked_edge.sp.x , peeked_edge.sp.y , peeked_edge.ep.x , peeked_edge.ep.y , p.x , p.y ) > 0){ // 시계반대방향의 점을 대상으로 // 점을 선택한다. if(selected_point == null){ selected_point = p; }else if(inCircleTest(p)){ // 외접원안에 있다면 해당점을 선택하고 진행한다. selected_point = p; }else{ continue; } // 외접원을 구한다. get3PointCircle( peeked_edge.sp.x , peeked_edge.sp.y , peeked_edge.ep.x , peeked_edge.ep.y , selected_point.x , selected_point.y ); } } if(selected_point != null){ if(isExistEdge(selected_point, peeked_edge.ep) == false){ candEdges.push(new Edge( selected_point , peeked_edge.ep )); } if(isExistEdge(peeked_edge.sp, selected_point) == false){ candEdges.push(new Edge( peeked_edge.sp , selected_point )); } if(isExistEdge(peeked_edge.ep, selected_point) == false){ this.edges.push(new Edge( peeked_edge.ep , selected_point )); } if(isExistEdge(selected_point, peeked_edge.sp) == false){ this.edges.push(new Edge( selected_point , peeked_edge.sp )); } } if(isExistEdge(peeked_edge.sp, peeked_edge.ep) == false){ this.edges.push(peeked_edge); } //break; } // while } // getDelaunay method // for animation this.state = 'START'; // FSM 형식으로 표현 this.delay = 5; this.candEdges = []; this.start = function(n){ // 1. 랜덤한 점들을 생성한다. this.genRandomPoints(n); this.candEdges = []; var drawAllPoints = this._drawPoints; var selfPoints = this.points; var selfCandEdges = this.candEdges; var selfState = this.state; var selfEdges = this.edges; var selfPeekEdge = null; var selfIdx = 0; var selfSelectedPoint = null; var selfGenRandomPoints = this.genRandomPoints; var cnt = 0; var selfDelay = this.delay; this._intId = setInterval(function(){ if(cnt < selfDelay){ cnt++; return; }else{ cnt = 0; } // clear ctx.clearRect(0,0,width, height); // drawing all points for(var i=0; i < selfPoints.length; i++){ var p = selfPoints[i]; drawPoint(p.x, p.y, 3); } for(var i=0; i < selfEdges.length;i++){ var edge = selfEdges[i]; drawLine(edge.sp.x, edge.sp.y, edge.ep.x, edge.ep.y, '#98fb98'); } // FSM switch(selfState){ case 'START': // 1. 임의의 점을 기준으로 최소의 길이를 지니는 Edge를 찾아낸다. O(n) var minLen = getLen(selfPoints[0].x, selfPoints[0].y , selfPoints[1].x, selfPoints[1].y); var sPointIdx = 0; var ePointIdx = 1; for(var i=2; i < selfPoints.length; i++){ var len = getLen(selfPoints[sPointIdx].x, selfPoints[sPointIdx].y, selfPoints[i].x, selfPoints[i].y); if(minLen > len){ ePointIdx = i; minLen = len; } } // 첫 Edge는 양방향 selfCandEdges.push(new Edge( selfPoints[sPointIdx], selfPoints[ePointIdx] )); selfCandEdges.push(new Edge( selfPoints[ePointIdx], selfPoints[sPointIdx] )); selfState = 'ENTRY'; break; case 'ENTRY': if(selfCandEdges.length == 0){ selfState = 'EXIT'; return ; } var peeked_edge = selfCandEdges.shift(); // queue 처럼 사용 var selected_point = null; // drawing peeked edge drawLine( peeked_edge.sp.x ,peeked_edge.sp.y ,peeked_edge.ep.x ,peeked_edge.ep.y , '#ffa0a0' ); selfState = 'FIND_POINT'; selfPeekEdge = peeked_edge; selfIdx = 0; // 인덱스를 0으로 만든다. selfSelectedPoint = null; break; case 'FIND_POINT': // drawing peeked edge drawLine( selfPeekEdge.sp.x ,selfPeekEdge.sp.y ,selfPeekEdge.ep.x ,selfPeekEdge.ep.y , '#ffa0a0' ); drawPoint( selfPeekEdge.sp.x ,selfPeekEdge.sp.y ,3 , '#ffa0a0' ); drawPoint( selfPeekEdge.ep.x ,selfPeekEdge.ep.y ,3 , '#ffa0a0' ); for(var i=selfIdx; i < selfPoints.length; i++){ var p = selfPoints[i]; if(p.x != selfPeekEdge.sp.x && p.y != selfPeekEdge.sp.y && p.y != selfPeekEdge.ep.x && p.y != selfPeekEdge.ep.y){ // pass }else{ continue; } if(ccwTest(selfPeekEdge.sp.x , selfPeekEdge.sp.y , selfPeekEdge.ep.x , selfPeekEdge.ep.y , p.x , p.y ) > 0){ // 시계반대방향의 점을 대상으로 // 점을 선택한다. if(selfSelectedPoint == null){ selfSelectedPoint = p; }else if(inCircleTest(p)){ // 외접원안에 있다면 해당점을 선택하고 진행한다. selfSelectedPoint = p; }else{ //continue; } // 외접원을 구한다. get3PointCircle( selfPeekEdge.sp.x , selfPeekEdge.sp.y , selfPeekEdge.ep.x , selfPeekEdge.ep.y , selfSelectedPoint.x , selfSelectedPoint.y ); // drawing circle drawCircle(_cx, _cy, _cr, '#ffa0a0'); drawPoint(p.x, p.y,3, '#ffa0a0'); selfIdx = i+1; return; } } selfState = 'ADD_EDGE'; console.log break; case 'ADD_EDGE': function isExistEdge(sp, ep){ var ret = false; for(var i=0; i < selfEdges.length; i++){ var edge = selfEdges[i]; if(edge.sp.x == sp.x && edge.sp.y == sp.y && edge.ep.x == ep.x && edge.ep.y == ep.y){ ret = true; } } return ret; } if(selfSelectedPoint != null){ if(isExistEdge(selfSelectedPoint, selfPeekEdge.ep) == false){ selfCandEdges.push(new Edge( selfSelectedPoint , selfPeekEdge.ep )); } if(isExistEdge(selfPeekEdge.sp, selfSelectedPoint) == false){ selfCandEdges.push(new Edge( selfPeekEdge.sp , selfSelectedPoint )); } if(isExistEdge(selfPeekEdge.ep, selfSelectedPoint) == false){ selfEdges.push(new Edge( selfPeekEdge.ep , selfSelectedPoint )); } if(isExistEdge(selfSelectedPoint, selfPeekEdge.sp) == false){ selfEdges.push(new Edge( selfSelectedPoint , selfPeekEdge.sp )); } } if(isExistEdge(selfPeekEdge.sp, selfPeekEdge.ep) == false){ selfEdges.push(selfPeekEdge); } selfState = 'ENTRY'; break; case 'EXIT': console.log('STATE: Exit'); selfPoints = []; selfEdges = []; selfCandEdges = []; for(var i=0; i < n; i++){ selfPoints.push( new Point(width * Math.random(), height * Math.random()) ); } selfState = 'START'; break; } }, 1000/60); } this.stop = function(){ clearInterval(this._intId); } } // instance var delaunay1 = new AssaDelaunayN2(dcanvas1); delaunay1.genRandomPoints(30); delaunay1.getDelaunay(); delaunay1.drawEdges(); delaunay1._drawPoints();
위 알고리즘은 항상 Convex 하게 만드려고 하기 때문에 바깥쪽에 존재하는 삼각형들은 모양이 길쭉해지는 경향이 있다. 실제 이 알고리즘을 자바스크립트로 작성한 이유는 시각화에 있다. 이 알고리즘은 논문으로만 보면 이해하기 어려운 면이 있으나 애니메이션으로 보면 큰 그림을 이해하는데 좋을 것이다.
var dcanvas2 = document.querySelector('#delaunay1'); dcanvas2.style.backgroundColor = '#272822'; var delaunay2 = new AssaDelaunayN2(dcanvas2); delaunay2.start(20);
위 알고리즘은 Edge 하나를 기준으로 다른 어떤점도 포함되지 않는 외접원을 구하는게 목표이다. 이를 모든 Edge에 대해 수행하면 된다. 알고리즘을 보면 큰 원이 점차 점이 바뀌며 작은 원으로 변하다가 결국 점하나를 찾으면서 Edge를 늘려나가는 식으로 동작하는 것을 알수 있다.
위 알고리즘을 구현하기 위해서는 CCW를 체크하는 것과 외접원을 구할 필요가 있다.
// 반시계방향 테스트 // ccw > 0 : counter clockwise // ccw < 0 : clockwise // ccw = 0 : on the line function ccwTest(x1,y1,x2,y2,x3,y3){ return (x1*y2 + x2*y3 + x3*y1) - (y1*x2 + y2*x3 + y3*x1); } // 세점을 지나는 원구하기 // 1. 두 변을 기준으로 중점을 구한다. // 2. 해당변과 수직인 기울기를 구한다. // 3. 중점과 기울기를 이용 두 직선을 구한뒤 교점을 구한다. var _cx, _cy, _cr; // output!, for performance function get3PointCircle(x1,y1,x2,y2,x3,y3){ _cx = _cy = _cr = 0.0; var mx1 = (x2 + x1) / 2; // mid of x1~x2 var my1 = (y2 + y1) / 2; // mid of y1~y2 var mx2 = (x2 + x3) / 2; var my2 = (y2 + y3) / 2; var deltay_e1 = y2 - y1; var deltay_e2 = y2 - y3; var d1, d2, yy; if(deltay_e1 != 0){ d1 = (x1 - x2) / deltay_e1; yy = my1 - d1 * mx1; if(deltay_e2 != 0){ d2 = (x3 - x2) / deltay_e2; if( d1 != d2 ){ _cx = (yy - (my2 - d2 * mx2)) / (d2 - d1); }else{ return ; // exception } } else if(x3 - x2 == 0){ return ; // exception } else { _cx = mx2; } }else if(deltay_e2 != 0 && x1 - x2 != 0){ d1 = (x3 - x2) / deltay_e2; yy = my2 - d1 * mx2; _cx = mx2; }else{ return ; // exception } _cy = d1 * _cx + yy; _cr = Math.sqrt((x1-_cx)*(x1-_cx) + (y1-_cy)*(y1-_cy)); }
CCW 를 체크하는 것에서 알수 있듯이 만들어진 들로네 삼각형 그래프는 DAG(방향성그래프)로서 거의 완성이 된것처럼 보여도 계속 알고리즘이 동작하는 것처럼 보이는 이유이다. 한개의 Edge처럼 보여도 두개의 방향성을 지니고 있어 두개의 Edge라고 해석된다.
실은 이것을 만든 이유는 또다른 알고리즘을 시각화 하기 위해 어떻게 하면 그래프를 적당하고 보기 좋게 모양을 잡을까 연구하다가 찾고 연구한뒤 ��현한 것이다. 위 들로네 삼각형은 보로노이 다이어그램과 Dual 관계에 있으므로 이를 구현하면 보로노이 다이어그램은 자연스럽게 따라오게 된다. 이는 나중 연구로 미루며 포스팅 종료
0 notes
Text
성대사랑 크롬확장 플러그인 개발기
크롬 확장(Chrome extension)은 상당히 개발하기 간단한 편인데 로직을 담당하는 Javascript 와 HTML을 섞어서 빠르게 개발할 수 있다. 여기서는 내가 자주 들러서 눈팅을 하는 일반적인 게시판 형식의 웹사이트인 성대사랑을 대상으로 여러가지 기능을 짜고 크롬앱 개발을 만들게 되었다. 소스코드는 성대사랑크롬확장개발 여기에 있다.
크롬앱 구조

크롬앱 구조를 가장 잘 나타내는 그림을 구글링을 하다가 찾아냈다.
Background script 는 앞단에 노출되지 않으면서 해당 크롬앱의 생명주기를 같이하는 핵심적인 부분이다. 즉 브라우저가 실행되면 크롬앱이 로드되면서 background script 가 수행된다. 여기서는 주로 contents script 나 browser action , page action 그리고 위 그림에는 나와있지 않지만 app 이라 불리는 부분까지 모든 부분에서 이 background 와 통신을 주고받는 구조로 앱을 설계할수 있다 (그렇게 개발하도록 의도하였다)
manifest.json 은 이 모든 구성요소들을 묶어서 하나의 크롬앱으로 구성하는 역할을 한다. 크롬앱의 구성을 지시하고 각각의 스크립트를 엮어준다. 가장 중요한 부분이다. 이 manifest.json 을 도대체 어떻게 옵션을 주고 설정을 해야하는지 참으로 찾기가 힘든데.. 크롬개발페이지는 너무 불편하다. 그냥 전체 설정 이쪽으로 가서 역으로 찾아가는게 훨씬 편하다. 개발페이지에서 ManifestV2 라는 탭을 눌러봐도 뭐 별거 없다는 사실을 알게 될것이다.
Content script 는 실제 주소를 이용하여 띄운 웹사이트 단에서 DOM 조작과 같은 작업을 할수 있도록 스크립트를 끼워넣은 것이다. 아예 DOM이 로드되기 전에 스크립트를 끼워넣을수도 있고 DOM만 로드된 상태에서 끼워넣을수도 있고 아니면 모두 로드된뒤에 마지막에 스크립트를 끼워넣을수도 있다. 만일 게시판 형식의 웹사이트에서 어떤 유저의 글을 차단하고 싶다면 DOM이 로드된 이후 게시판의 구조를 탐색하여 저장된 유저의 엘리먼트를 숨기거나 없애버리면 되는것이다. 이것이 여러사이트에서 사용하는 차단 스크립트이다.
app 은 위 그림에는 나와있지 않지만 크롬앱이 실행될때 새탭이 뜨면서 새로운 페이지를 띄우며 사용하는 크롬앱이 바로 app 이라고 할수 있다. 이는 HTML 파일로 만든다.
그외 나머지 부분에 대한 설명은 개발페이지 를 참조하도록 한다. 개발한 크롬앱에서는 사용하지 않는다.
Content Script 로 건드려보기
자신이 사용하는 웹사이트랑 가장 직접적으로 연동되는 부분이라 간단한 구현만으로도 빠른 효과를 볼수 있을 것이다.
manifest.json 설정
위에서 말한 Manifest.json 설정하는 개발자 페이지를 가서 content_script 에 대한 내용을 찾아보면 다음과 같다.
"content_scripts": [ { "matches": ["http://www.google.com/*"], "css": ["mystyles.css"], "js": ["jquery.js", "myscript.js"], "run_at" : "document_end" } ]
직관적으로 이해하기 쉽기 때문에 별다른 설명이 필요없을 것이다. 이렇게 설정된 스크립트가 실행되는 시점이 중요한데 url 이 match가 될때 원하는 js 파일이 run_at 설정에 따라 실행이 되는것이다. 즉 브라우저를 켜서 해당주소가 열리면 스크립트가 끼워넣어져 바로 실행이 되며 해당 DOM 엘리먼트 및 원래 페이지에 있는 js 의 객체들.. 등등 다 접근 가능하다.
로그인기능

크롤러를 만들거나 혹은 자동으로 스크랩하는 봇을 만든다면 많이 익숙할 로그인 기능인데 이는 크롬앱을 이용하면 훨씬 간단해진다. 세션을 관리하는 부분은 이미 크롬에서 해결되므로 단지 로그인폼을 찾아서 POST 요청을 하면 끝나버린다.
위 사진은 디시인사이드의 로그인폼을 크롬 소스보기를 이용하여 찾아본 예이다. 여기서는 submit 이 자바스크립트에서 리턴을 받도록 되어있으므로 자바스크립트 함수를 찾아서 어떻게 구성을 하는지를 확인해야 한다. action 은 대개 서버에서 로그인 아이디와 비번을 체크하는 post 요청을 받는 페이지의 주소를 넣는다.
form 태그 안에 대개 input 두개가 있다. ID와 Password.. 이 form 들은 name 속성을 이용하는 경우가 많은데 이는 post 전송때문이다. 이런경우 크롤러나 로그인기능을 구현하는 입장에서 참 편해진다. 바로 이름으로 접근 가능하기 때문이다.
var login_form = document.forms['FORMNAME']; login_form.id_input_name.value = 'USERID'; login_form.pw_input_name.value = 'PASSWORD'; // login url login_form.action = 'LOGINURL'; login_form.submit();
간략화하면 위 코드와 같다. Form 을 찾고 id 를 입력하는 input에 ID 입력하고 비번입력하는 input 에 비번 입력하고 action 속성에 url을 지정해준뒤 submit 하면 끝난다. 이 과정은 웹페이지에서 사람이 직접 입력하고 나서 버튼을 눌러 로그인 하는 것과 하등 차이가 없다.
특정유저 글 숨기기 기능
게시판과 같은 형태에서는 똑같은 템플릿으로 단지 제목과 작성자만 바뀌면서 반복되는 형태가 나타날 것이다. 이것을 찾아내고 어떻게 하면 쉽게 분리해낼까 고민을 하면 된다. 예를 들면 성대사랑의 예에서는 이렇게 구현했다.
function hide_list(blist){ for(var i=0; i < blist.length; i++){ (function(i){ var _name = blist[i].querySelector('a[href="javascript:;"]'); if(_name){ var id = String(_name.getAttribute('onclick')).split(',')[1].split("'")[1]; //console.log(id); if(response.list[id]){ //blist[i].style.visibility = 'hidden'; blist[i].style.display = 'none'; } } })(i); } } hide_list(document.querySelectorAll('.bg0')); hide_list(document.querySelectorAll("#commentContents > table"));
jQuery 를 쓰지 않는다면 document.querySelector 가 좋다. html 구조를 살피고 규칙을 찾아서 최대한 각각의 단위로 쪼개지도록 DOM 수준에서 걸러내는것이 더 쉽다. 특히 예전스타일의 웹 게시판은 table 이 심하게 중첩되어 있고 style 이 css 분리되어 있지 않아 업데이트에 robust 하다. (태그 구조가 잘 바뀌지 않는다) 위 코드에서는 querySelector('.bg0') 'bg0' 라는 정체모를 class로 잘라낸것들은 그닥 좋은 방법이라고는 볼수 없다. 아래에 #commentContents > table 은 괜찮다. 중간에 태그구조가 바뀌더라도 비슷한 템플릿으로 변할 가능성이 보이고 구조적으로 정리되어 보이기 때문이다.
그리고 정규식을 잘쓰면 정말 좋지만 속도가 느리더라도 경험상 DOM으로 뽑아내는게 더 낫다. 정규식은 정말 잘짜야된다.. 가능할수 있는 모든 케이스를 검토하여 문제가 없어야 잘 동작하게 된다.
페이지 캡쳐 기능
페이지 캡쳐기능을 생각한 이유는 글쓴이가 질먹튀를 해서 좋은 내용이 허무하게 사라지거나 말을 교모하게 바꿔서 시차를 두고 상대방을 비난하는 사람들 때문에 만들었다. 적어도 좋은 내용이라도 건졌으면 하는 마음이다.
용량의 문제
이 기능은 성대사랑 게시판 글을 탐색을 하면 해당 시점의 글이 기록되는 것이다. 그렇다고 다 저장해버리면 용량이 너무 커지니 URL한개당 세개의 최근 시간대 캡쳐를 할 수 있게 하였다. 여기서 고려해야 할 점은 용량이다. 데이터를 저장시켜 브라우저가 재시작되어도 다시 가져올수 있는 저장소를 사용해야 한다. localStorage 는 정말 편하지만 용량은 5MB 정도로서 작다. 페이지 캡쳐에 사용되면 금방 차게 될 것이다. 따라서 내부적으로 Sqlite 를 사용하는 WebSQL database 를 사용하였다. 데스크탑에선 설정하기 나름이지만 이 성대사랑 크롬앱에서는 512MB 의 용량을 사용할수 있도록 설정하였다.
테이블 생성루틴
// create db (sqlite) 512 MBytes var db = openDatabase('sl_plugin', '1.0', 'sl_plugin', 512 * 1024 * 1024); db.transaction(function(tx){ tx.executeSql( 'CREATE TABLE IF NOT EXISTS sl_hist' + '(url TEXT ,' + ' sno INTEGER ,' + ' ts TEXT, ' + ' content TEXT,' + ' PRIMARY KEY(url, sno));' ); console.log('create table'); }, function(err, commited, snapshot){ console.log(err); });
대개 프로그래밍 언어에서 RDBMS 랑 연결하고 수행하는 과정은 지저분하고 복잡한데 여기서는 매우 깔끔하게 할 수 있다. openDatabase 은 db 객체를 얻어오기 위한 과정인데 이는 background.js 에 구현되어 있으므로 브라우저가 재시작 되면 계속 호출되는 부분이다. 따라서 openDatabase에서 고민할 부분은 여러분 호출될때마다 새로운 db를 생성하는가? 의 여부이다. 아직은 잘 모르겠지만 시험해본 결과 아무것도 없을때 한번 생성하고 그 뒤로는 계속 연결이 잘 되었다.
그리고 transaction 과 executeSql 을 보면 정말 직관적으로 잘 짜여져 있는것 같다. 이렇게 되면 많은 코드가 생략된채 SQL에 집중 할수 있게 되는것 같다. 브라우저를 재시작할때마다 테이블을 생성할 수 없으니 IF NOT EXISTS 를 붙여서 SQL 테이블 생성 쿼리를 돌린다.
항상 3개만 유지하기
db.transaction(function(tx){ tx.executeSql( 'INSERT INTO sl_hist (url, sno, ts, content)' + 'VALUES (?, ' + '(select ifnull(max(sno),0)+1 from sl_hist where url=?),' + '?,?);' , [request.url, request.url,request.timestamp, request.contents] ); // 3개까지 기억한다. tx.executeSql( 'DELETE FROM sl_hist WHERE url=? ' + 'AND sno = (select ifnull(max(sno),0)-3 from sl_hist where url=?)' , [request.url, request.url] ); }, function(err, commited, snapshot){ console.log(err); });
Oracle 의 NVL과 대응되는 것은 Sqlite 에서 ifnull 이다. 쿼리에서 ? 부분에 바인딩 하기 위해 array 를 사용하여 값을 넣어준다. 그리고 항상 3개만을 유지하기 위해 insert 시에는 항시 3번째전 일련번호를 delete 하고 이를 한 트랙잭션 내에서 처리하면 될 것이다.
SELECT 절의 결과 콜백과 비동기수행
바로 해당 웹페이지라면 바로 거기다가 디비를 생성해서 가져다 쓰면 되지만 크롬앱을 엮을 때는 background.js 를 사용하기 때문에 문제가 된다. 왜냐하면 background.js 에서 chrome.runtime.onResponse 로 계속 요청을 LISTEN하는 구조를 만들었을때 요청에 대한 콜백을 재호출 하는 과정에서는 요청과 동일시점에 응답이 이루어져야 한다는 크롬의 제약이 있는 것 같다.
// background.js 의 서비스 응답구조 chrome.runtime.onMessage.addListener( function(request, sender, sendResponse){ if(request.serv == 'SERVICE_NAME'){ // service 구현 } if(request.serv == 'history'){ if(request.cmd == 'contents'){ // ... } } } );
background.js 에서 기본적인 구조를 저렇게 작성하였다. 즉 마치 서버의 기능과 유사하게 어떠한 요청이 왔을때 그에 해당되는 응답을 하도록 구성하는 것이다. sendResponse 를 호출하면 request 날린 곳에서 같이 전달한 callback 을 실행하게 된다. 그런데 chrome.runtime 에 제약이 있다. 바로 동일한 런타임 수준에서 바로 콜백을 날려야 되는 것이다.
if(request.cmd == 'contents'){ db.transaction(function(tx){ tx.executeSql( 'SELECT ts, content FROM sl_hist WHERE url=? ORDER BY sno DESC', [request.url], function(tx, results){ var res = []; for(var i=0; i < results.rows.length; i++){ res[i] = results.rows.item(i); } // 이부분은 SELECT 절의 콜백이므로 // onMessage 와 동일한 런타임에 실행되지 않는다. // 따라서 여기서 onMessage 콜백을 호출할수없다. // sendResponse({'list': res}); // ERROR!!! fetched = res; fetch_on = false; } ); }, function(err, commited, snapshot){ console.log(err); }); fetch_on = true; sendResponse(parseInt(Math.random()*100000)); }
sendMessage 로 요청을 하면 SELECT 절만 Sqlite 에 요청만 하고 다시 자기할일을 수행한다. SELECT 절 결과는 나중에 콜백으로 받는다. 즉 비동기적으로 동작하는 것이다. 이러한 문제를 해결하기 위해 결국은 요청하는 측에서 두번 호출을 하는 식으로 구성한다.
쿼리요청 (특히 Select 절)
결과요청 (fetch 결과 )
fetch_on 이라는 상태를 만들어서 쿼리 결과가 나올때까지 순서를 보장하게 만든다.
if(request.cmd == 'fetched'){ if(fetch_on == true){ sendResponse({list: null, fetch_on: true}); }else { sendResponse({list: fetched, fetch_on: false}); } }
background 에서 위와같이 fetch 결과를 가져오는 서비스를 만들고 상태에 따라서 콜백 호출을 다르게 해준다.
function fetch(){ chrome.runtime.sendMessage({ 'serv' : 'history', 'cmd' : 'fetched' }, function(response){ //console.log(response); // waiting... if(response.fetch_on == true) { setTimeout(function(){ fetch(); }, 1); return ; }; // fetch done // ... }); } fetch();
실제로 서비스요청을 날리는 측에서는 select 절을 사용하는 서비스를 우선 날리고 그 콜백 안에서 위 코드와 같이 fetch 서비스를 요청한다. 만약 SELECT 절 수행이 오래걸릴 가능성이 있으므로 결과를 다 받을때까지 타이머 이벤트로 지속적으로 결과를 기다리며 waiting 하면 되는 것이다.
NodeJS 를 해보면 알겠지만 이벤트 기반 비동기 프로그래밍은 중첩이 많이 일어나며 의존성이 생길경우 실행순서를 정하는 것이 꽤 까다롭다.. 그래도 멀티스레드 동기화보단 낫지 않을까 생각해본다.
추가하지 못한 Diff 기능
Diff 는 이전 텍스트와 나중 텍스트를 비교하여 어떤 부분이 달라졌는지 확인 하는 도구이다. LCS(Longest Common Subsequence)알고리즘을 충실하게 구현한다. 대개 삭제된 부분을 빨간색으로 추가된 부분을 초록색으로 표기하는게 일반적인것 같다. 여기서 이 기능을 추가하기 어려운 이유는 캡쳐된 페이지 자체는 HTML 태그로 구성되어 있기 때문이다.
두가지 방안을 생각했는데
DOM 트리 자체를 Diff 비교하는 알고리즘을 javascript 버젼으로 자체구현한다. - 모든 케이스에도 적용가능, LCS(Longest Common Subtree) 비교이기 때문에 엄청 까다롭다.
기존 Text기반 Diff 알고리즘을 약간 변형하여 사용한다.
TAG들을 전부 찾아내 리스트에 저장한다.
TAG를 아주특수한 문자열 키로 만들어 치환
기존 Text 기반 diff 알고리즘을 수행한다.
결과물을 만들때 문자열 키를 리스트에 저장된 tag로 순서대로 치환
정말 특수한 문자열 키어야 하는데 만일 일반 TEXT상에 해당 문자열키가 있었다면(일부분이라도) 위 알고리즘은 오작동
두가지 모두 구현하기 너무 번거롭고 귀찮아서 포기하였다.
결론
크롬 확장은 웹을 자주 쓰는 사람에게 유용한것 같다. 자신에게 맞는 간단한 프로그램을 빠르게 만드는데 좋다. 하지만 제약이 많고 개발과 관련된 사항을 검색하기도 힘들어 익숙하지 않다면 시행착오가 많고 스트레스를 많이 받을 것 같다.
0 notes
Text
기하브라운 주가모형
저번에 가우시안 랜덤 예제를 통해서 랜덤값이 정규분포를 이루도록 뽑는 방법에 대해 알아보았다. 이를 이용하여 위너과정 추세성분과 무위험수익률 성분을 더한 주가움직임을 표현할수가 있다.
var ASSA_Chart2 = { themes : { //DONE 'background' : '#000000', 'up' : 'rgba(255,220,220,0.3)', 'down' : 'rgba(220,220,255,0.3)', 'up-shadow' : 'rgba(255,0,0,1.0)', 'down-shadow' : 'rgba(0,0,255,1.0)', 'grid-line' : 'rgba(255,255,255,0.8)' }, series : { grid : { highest: 0, lowest : 0, multiply: 1, base_dt: new Array(2000) }, // 정규 스케일(0.0 ~ 1.0) 변환된 시계열 캔들가격 데이터 // EX) // { // lx: 0.7123, // x coord // rx: 0.7123, // x coord // oy: 0.1123, // y coord (open price) // hy: 0.1123, // y coord (high price) // ly: 0.1123, // y coord (low price) // cy: 0.1123, // y coord (close price) // } price: new Array(2000), // 거래량 레벨 volume: new Array(2000), // 그외 용도에 따라 }, // 레이아웃 지정 layouts : [], // 초기화하면서 캔버스엘리먼트를 반환한다 init : function(elem, width, height){ this._canvas = elem || document.createElement('canvas'); this._canvas.width = width || 960; this._canvas.height = height || 480; // 캔들 차트 영역 if(this.layouts.length > 0){ // pass }else{ this.layouts.push({ x: this._canvas.width * 0.1, y: this._canvas.height * 0.1, w: this._canvas.width * 0.8, h: this._canvas.height * 0.8 }); } return this._canvas; }, // 차트 렌더링 render : function(dat, s, e){ // s : start index, e : end index // 데이터 로드 프로그램 실행 for(var i=0; i < this.load_programs.length; i++){ var program = this.load_programs[i]; program(this.series, s, e, dat); // run program } var ctx = this._canvas.getContext('2d'); // 차트 클리어 //this._canvas.width = this._canvas.width; ctx.fillStyle = this.themes['background']; ctx.fillRect(0,0,this._canvas.width, this._canvas.height); // 렌더 프로그램 실행 for(var i=0; i < this.render_programs.length; i++){ var program = this.render_programs[i]; program( this.series, s, e, this.themes, this.layouts, ctx); } }, // 데이터를 로드하는 프로그램 등록 순차적으로 실행된다. load_programs: [ // 그리드 로더 function(serieses, s, e, dat){ //console.log('assa_chart2 [LOAD] : grid'); // 데이터중에서 가장 높은 가격, 낮은가격을 찾는다. var highest = -999999999999999; var lowest = 999999999999999; for(var i=s; i < dat.length && i < e ; i++){ if(highest < dat[i].high){ highest = dat[i].high; } if(lowest > dat[i].low){ lowest = dat[i].low; } } // 가능한 정배율의 간격으로 최대 최소 값을 재조정 var r_highest = highest, r_lowest = lowest, r_multiply, multiply = 1; while(parseInt((highest - lowest) / 5)){ r_highest = highest; r_lowest = lowest ; highest = parseInt(highest / 10); lowest = parseInt(lowest / 10); r_multiply = multiply; multiply *= 10; } highest = (r_highest + 1) * r_multiply; lowest = (r_lowest ) * r_multiply; multiply = r_multiply; // 기록 serieses.grid.highest = highest; serieses.grid.lowest = lowest; serieses.grid.multiply= multiply; // 각달의 첫째날을 구해온다 for(var i=s; i < dat.length-1 && i <= e-1; i++){ var curr_dt = dat[i].date; var prev_dt = dat[i+1].date; if(curr_dt.substr(4,2) != prev_dt.substr(4,2)){ serieses.grid.base_dt[i] = { date: curr_dt.substr(0,4)+'.'+curr_dt.substr(4,2)+'.'+curr_dt.substr(6,2), x: (1.0 / (e - s + 1))*(i-s) }; }else{ serieses.grid.base_dt[i] = null; } } }, // 캔들가격 로더 function(serieses, s, e, dat){ //console.log('assa_chart2 [LOAD] : candle prices'); var highest = serieses.grid.highest; var lowest = serieses.grid.lowest ; var wrate = 0.6; for(var i=s; i < dat.length && i <= e; i++){ // 캔들 가격 정규화 serieses.price[i] = { lx : (1.0 / (e - s + 1))*((i-s) + (1.0 - wrate)*0.5), rx : (1.0 / (e - s + 1))*((i-s) + (1.0 + wrate)*0.5), oy: (dat[i].open - lowest) / (highest - lowest), hy: (dat[i].high - lowest) / (highest - lowest), ly: (dat[i].low - lowest) / (highest - lowest), cy: (dat[i].close - lowest) / (highest - lowest) }; } }, // 거래량 로더 function(serieses, s, e, dat ){ //console.log('assa_chart2 [LOAD] : volumes'); var avg_vol = 0; var low_vol = 999999999999; // 가장 작은 거래량과 평균거래량을 구한다 for(var i=s; i < dat.length && i <= e; i++){ if(low_vol > dat[i].vol){ low_vol = dat[i].vol; } avg_vol += dat[i].vol / ( e -s + 1); } // 가장 작은 거래량을 1로 평균을 3으로 var m_vol = (avg_vol - low_vol) / 3; for(var i=s; i < dat.length && i <= e; i++){ serieses.volume[i] = parseInt((dat[i].vol-low_vol) / m_vol)+1; } } ], // 그리는 프로그램 들 render_programs : [ // 그리드 렌더 function(serieses, s, e, themes, layouts, ctx){ //console.log('assa_chart2 [RENDER] : grid'); // 가로선 긋기 var floor = parseInt(serieses.grid.lowest /serieses.grid.multiply); var cap = parseInt(serieses.grid.highest/serieses.grid.multiply); var step = Math.round((cap - floor) / 5); var hv = floor; while(hv < cap){ var ax = 1.0 * layouts[0].w + layouts[0].x; var bx = 0.0 * layouts[0].w + layouts[0].x; var ay = (1.0 - ((hv - floor) / (cap - floor))) * layouts[0].h + layouts[0].y ctx.beginPath(); ctx.moveTo(ax, ay); ctx.lineTo(bx, ay); ctx.lineWidth = 0.8; if(ctx.setLineDash) ctx.setLineDash([1,2]); ctx.strokeStyle = themes['grid-line']; ctx.stroke(); if(ctx.setLineDash) ctx.setLineDash([1,0]); var txt = '' + hv * serieses.grid.multiply; ctx.beginPath(); ctx.textAlign = 'left'; ctx.textBaseline = 'middle'; ctx.fillStyle = themes['grid-line']; ctx.fillText(txt, ax+12, ay); hv += step; } // 세로선 긋기 (날짜 date 20130609) for(var i=s; i < serieses.price.length-1 && i <= e-1; i++){ if(serieses.grid.base_dt[i] != null){ var ay = 0.0 * layouts[0].h + layouts[0].y; var by = 1.0 * layouts[0].h + layouts[0].y; var ax = (1.0 - serieses.grid.base_dt[i].x) * layouts[0].w + layouts[0].x; ctx.beginPath(); ctx.moveTo(ax, ay); ctx.lineTo(ax, by); ctx.lineWidth = 0.8; if(ctx.setLineDash) ctx.setLineDash([1,2]); ctx.strokeStyle = themes['grid-line']; ctx.stroke(); if(ctx.setLineDash) ctx.setLineDash([1,0]); ctx.textBaseline = 'top'; ctx.textAlign = 'center'; ctx.fillStyle = themes['grid-line']; ctx.fillText(serieses.grid.base_dt[i].date, ax, by+12); } } }, // 캔들 렌더 function(serieses, s, e, themes, layouts, ctx){ //console.log('assa_chart2 [RENDER] : candle chart '); // x coord transform // (1.0 - x) => mirror // * layout.w => scale // + layout.x => translation var arr = serieses.price; var vol = serieses.volume; for(var i=s; i < arr.length && i <= e; i++){ // 하나의 캔들 그리기 var candle = arr[i]; var level = (vol[i]) * (Math.random() + 0.3)+2; // 색깔지정 var color = (candle.oy <= candle.cy) ? themes['up'] : themes['down']; var scolor= (candle.oy <= candle.cy) ? themes['up-shadow'] : themes['down-shadow']; // 좌표 변환 var lx = (1.0 - candle.lx) * layouts[0].w + layouts[0].x; var rx = (1.0 - candle.rx) * layouts[0].w + layouts[0].x; var oy = (1.0 - candle.oy) * layouts[0].h + layouts[0].y; var hy = (1.0 - candle.hy) * layouts[0].h + layouts[0].y; var ly = (1.0 - candle.ly) * layouts[0].h + layouts[0].y; var cy = (1.0 - candle.cy) * layouts[0].h + layouts[0].y; // 고가-저가의 선을 그린다 var mx = (lx + rx) * 0.5; ctx.beginPath(); ctx.moveTo(mx, ly); ctx.lineTo(mx, (oy > cy) ? oy : cy); ctx.strokeStyle = color; ctx.shadowBlur = 0; // 밝기 레벨에 따라서 강조 for(var j=0; j < level; j++){ ctx.stroke(); } ctx.beginPath(); ctx.moveTo(mx, hy); ctx.lineTo(mx, (cy > oy) ? oy : cy); ctx.strokeStyle = color; // 밝기 레벨에 따라서 강조 for(var j=0; j < level; j++){ ctx.stroke(); } // 몸통을 그린다 ctx.beginPath(); ctx.rect( (lx>rx)?rx:lx , (oy>cy)?cy:oy , Math.abs(lx - rx) , Math.abs(oy - cy) ); ctx.shadowColor = scolor; ctx.shadowBlur = parseInt(Math.abs(lx - rx) *3); ctx.fillStyle = color; // 밝기 레벨에 따라서 강조 for(var j=0; j < level; j++){ ctx.fill(); } ctx.strokeStyle = color; ctx.stroke(); ctx.closePath(); } } ] }; // custom // moving average 5 ASSA_Chart2.load_programs.push(function(serieses, s, e, dat){ serieses['ma5'] = new Array(); for(var i=s; i < dat.length-5 && i <= e-5; i++){ serieses.ma5[i] = { x: (1.0 / (e - s + 1)) * (i-s), y: ( serieses.price[i+0].cy +serieses.price[i+1].cy +serieses.price[i+2].cy +serieses.price[i+3].cy +serieses.price[i+4].cy ) /5 }; } }); ASSA_Chart2.render_programs.push(function(serieses, s, e, themes, layouts, ctx){ for(var i=s; i < serieses.price.length-6 && i <= e-6; i++){ var ax = (1.0 - serieses.ma5[i].x) * layouts[0].w + layouts[0].x; var ay = (1.0 - serieses.ma5[i].y) * layouts[0].h + layouts[0].y; var bx = (1.0 - serieses.ma5[i+1].x) * layouts[0].w + layouts[0].x; var by = (1.0 - serieses.ma5[i+1].y) * layouts[0].h + layouts[0].y; ctx.beginPath(); ctx.moveTo(ax, ay); ctx.lineTo(bx, by); ctx.strokeStyle = 'rgba(255,255,0,0.6)'; ctx.lineWidth = 2; ctx.stroke(); } }); // function stock_process(s, mu, vol, t, n){ this.s = s || 100.0; this.mu = mu|| 0.1; this.vol = vol || 0.3; this.t = t || 1.0; this.n = n || 365; this.date = new Date(); function clip_data(dat){ if(dat > 0.15) return 0.15; else if (dat < -0.15) return -0.15; else return dat; } this.randRate = function(){ // box-muller method /* var x1, x2, w; do{ x1 = 2 * Math.random() - 1; x2 = 2 * Math.random() - 1; w = x1 * x1 + x2 * x2; }while( w >= 1 || w == 0); w = Math.sqrt((-2.0 * Math.log(w)) / w); var u1 = 1.0 * x1 * w; */ var x1 = Math.random(); var x2 = Math.random(); var u1 = Math.sqrt(-2 * Math.log(x1)) * Math.cos(2 * Math.PI * x2); var u2 = Math.sqrt(-2 * Math.log(x1)) * Math.sin(2 * Math.PI * x2); var dt = this.t / this.n; return clip_data(this.mu * dt + this.vol * u1 * Math.sqrt(dt)); } this._prevS = 0; this.init = function(){ this._prevS = this.s; } this.getPrice = function(){ var arr = []; for(var i=0; i < 3; i++){ //console.log('randr' + randRate()); arr[i] = this._prevS + this._prevS * this.randRate(); } var close = arr[0]; arr.sort(); var ret = { vol : parseInt(Math.random()*10000), open : this._prevS, high : arr[2], low : arr[0], close: close, date: "20130921" }; this._prevS = this._prevS + this._prevS * this.randRate(); return ret; } this.getPricePath = function(){ var ret = new Array(this.n); for(var i=0; i < this.n; i++){ ret[i] = this.getPrice(); } return ret; } } var stock_path = document.getElementById('stock_path'); ASSA_Chart2.init(stock_path, 660, 420); var sp = new stock_process(5000); sp.init(); var ppath = sp.getPricePath().reverse(); setInterval(function(){ ASSA_Chart2.render(ppath, 300, 364); }, 1000/6);
위차트는..
봉차트는 예전에 만들어둔 ASSA_Chart를 사용하였다. ASSA_Chart 설계시 의도한 바는 시계열 데이터를 로드시 좌표변환 혹은 최대값 최소값 을 찾는 작업을 미리 정해진 순서대로 실행하는 load_programs 들을 생각했다. 이러한 프로그램들은 배열에 function 으로 담겨서 순차적으로 실행되며 데이터를 로드하는 과정을 거치게 된다. 그리고 render_programs 는 차트를 그리는 함수들이며 순차적으로 그려지게 된다. 만약 자기가 원하는 자신만의 지표가 있을때 데이터를 새로 조작해야 한다면 로드프로그램에 function 을 등록하고 원하는 방식으로 차트에 지표를 그리도록 render program을 작성하여 function을 등록하면 되는것이다. 하지만 아직은 그렇게 깔끔한 설계는 아니라고 생각하여 더 개선할 예정이다.
반짝반짝 빛이나는 것은 그냥 나는것이 아니고 거래량이 많은 순간에 더 활발하게 거래가 되었음을 시각적으로 보이기 위해 강약을 추가한것이다. 좀더 빛을 강렬하게 표현하는 법을 연구하여 적용할 계획이다.
주가모형에 대해
위 차트의 가격데이터는 랜덤으로 만들어진 데이터일뿐 실제 주식과는 아무 상관이 없다. 다만 이 기하브라운 주가모형으로 생성되는 주가경로는 실제 주가의 양상이랑 다른경우가 많은것 같다 (체감적으로) 이 주가모형은 한 봉의 가격의 움직임은 전봉이랑 전혀 상관이 없으나(독립) 실제 주식세상에서는 가격 그 자체가 시장참여자들에게 중대한 의미를 주기도 하며 어느정도 경향성을 준다. 고로 이 모형은 그렇게 쓸데가 있어보이진 않지만 변동성이 얼마나 중요한가에 대한 의미는 있는것 같다.
원래 주가모형은 종가만을 생성하므로 위 차트에 맞게 시고저종의 데이터를 생성할 필요가 있다. 이는 간단하게 해결했는데 상하한가 +-15% 이내의 범위에서 세개의 가격을 구한뒤 종가를 미리 지정하고 정렬하여 고가, 저가를 정해주면 시고저종을 만들수 있다.
function stock_process(s, mu, vol, t, n){ this.s = s || 100.0; this.mu = mu|| 0.1; this.vol = vol || 0.3; this.t = t || 1.0; this.n = n || 365; this.date = new Date(); function clip_data(dat){ if(dat > 0.15) return 0.15; else if (dat < -0.15) return -0.15; else return dat; } this.randRate = function(){ var x1 = Math.random(); var x2 = Math.random(); var u1 = Math.sqrt(-2 * Math.log(x1)) * Math.cos(2 * Math.PI * x2); var u2 = Math.sqrt(-2 * Math.log(x1)) * Math.sin(2 * Math.PI * x2); var dt = this.t / this.n; return clip_data(this.mu * dt + this.vol * u1 * Math.sqrt(dt)); } this._prevS = 0; this.init = function(){ this._prevS = this.s; } this.getPrice = function(){ var arr = []; for(var i=0; i < 3; i++){ //console.log('randr' + randRate()); arr[i] = this._prevS + this._prevS * this.randRate(); } var close = arr[0]; arr.sort(); var ret = { vol : parseInt(Math.random()*10000), open : this._prevS, high : arr[2], low : arr[0], close: close, date: "20130921" }; this._prevS = this._prevS + this._prevS * this.randRate(); return ret; } this.getPricePath = function(){ var ret = new Array(this.n); for(var i=0; i < this.n; i++){ ret[i] = this.getPrice(); } return ret; } }
0 notes